1.本发明涉及数据挖掘技术领域,尤其是指一种基于概率加权过采样的社区矫正率预测系统及方法。
背景技术:
2.随着城镇化程度的不断提升,城市社区的人员结构也越来越复杂这就造成了各地区矫正率逐年增加,。为此相关部门迫切需要对社会矫正数据进行分析,并预测出特定地区的潜在矫正率,从而加强对该地区的管理。
3.目前,数据挖掘方法已经被用到了社区矫正率预测中。有些社区的矫正率较高,这类社区我们称为主要矫正社区,有些社区的矫正率较低,这类社区我们称为次要矫正社区。在日常生活中,反映出来的现象是主要矫正社区较少,次要矫正社区较多,这属于一种数据分布不平衡问题。在数据不平衡的条件下,经典的学习模型对社区矫正检测率往往较低。一种可行的解决方案是让两类数据的数据量达到平衡。过采样方法就是能让数据平衡的一类方法。在现有的过采样方法中,smote(synthetic minority oversamplingtechnique)是最为经典的过采样方法之一。该方法通过在少数类样本与其同类近邻样本之间进行线性插值,从而生成新的样本点,然而,smote存在对噪音样本点和无用样本点进行过采样,以及采用的线性插值方式使得其生成的样本点缺乏多样性的问题,导致生成的样本点仍为噪音样本点,从而降低分类性能或者生成的样本点对分类性能无影响。borderline-smote是对 smote的一种变体,它识别了噪音、边界以及安全样本点,能够解决smote 中噪音样本点生成和无用样本点生成问题,但是该方法采用smote的生成方式,使得新生成的样本点缺乏多样性以及其未能对每个边界样本点的重要性进行衡量,可能仍然会造成生成的样本重合问题。因此,如何选择哪些样本点参与过采样的过程以及如何选择样本点的生成方式是过采样方法中值得研究的问题。
技术实现要素:
4.为此,本发明所要解决的技术问题在于克服现有技术存在的问题,提出一种基于概率加权过采样的社区矫正率预测系统及方法,其能够达到数据样本数量的平衡,克服了现有技术因数据样本数量不平衡而导致的对社区矫正率检测率较低的问题。
5.为解决上述技术问题,本发明提供一种基于概率加权过采样的社区矫正率预测系统,包括:
6.数据输入模块,所述数据输入模块用于输入社区矫正原始数据集合,其中所述社区矫正原始数据集合包括次要矫正社区原始数据集合和主要矫正社区原始数据集合;
7.过采样模块,所述过采样模块用于剔除所述主要矫正社区原始数据集合中的噪音样本点,获得剔除噪音样本点后的主要矫正社区数据集合,基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合,计算所述主要矫正社区边界样本集合中的样本的选择概率,并根据所述选择概率生成主要社区矫正样本点集合;
8.数据训练模块,所述数据训练模块用于将生成的主要社区矫正样本点集合和社区矫正原始数据集合进行求和,获得最终的社区矫正数据集合,利用最终的社区矫正数据集合对神经网络模型进行训练,得到社区矫正率预测模型;
9.社区矫正率预测模块,所述社区矫正率预测模块用于接收待预测的社区矫正样本,并将其输入至所述社区矫正率预测模型,输出所述社区矫正样本的预测结果,判断该社区矫正样本是否为主要矫正社区。
10.在本发明的一个实施例中,所述过采样模块包括:
11.噪音样本点剔除子模块,所述噪音样本点剔除子模块用于计算所述主要矫正社区原始数据集合中的样本点的均值以及标准差,并基于所述样本点的均值和标准差判断所述样本点是否为噪音样本点,得到剔除噪音样本点后的主要矫正社区数据集合;
12.边界样本确定子模块,所述边界样本确定子模块用于基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合;
13.选择概率计算子模块,所述选择概率计算子模块用于计算所述主要矫正社区边界样本集合中的边界样本的选择概率;
14.样本生成子模块,所述样本生成子模块用于基于所述选择概率随机生成新的样本点,得到主要社区矫正样本点集合。
15.在本发明的一个实施例中,所述边界样本确定子模块包括:
16.一次寻找近邻样本单元,所述一次寻找近邻样本单元用于寻找主要矫正社区数据集合中的每个样本在次要矫正社区原始数据集合中的近邻样本,并将近邻样本组成多数类边界样本集合;
17.二次寻找近邻样本单元,所述二次寻找近邻样本单元用于寻找多数类边界样本集合中的每个边界样本在所述主要矫正社区数据集合中的近邻样本,并将近邻样本组成主要矫正社区边界样本集合。
18.在本发明的一个实施例中,所述选择概率计算子模块包括:
19.局部密度计算单元,所述局部密度计算单元用于计算所述主要矫正社区边界样本集合中的边界样本在其同类和异类样本点的局部密度;
20.相对密度计算单元,所述相对密度计算单元用于根据所述局部密度计算边界样本在整个样本空间中的相对密度;
21.权重计算单元,所述权重计算单元用于根据所述相对密度计算所述边界样本的权重值;
22.选择概率确定单元,所述选择概率确定单元用于对所述权重值进行归一化操作,得到所述主要矫正社区边界样本集合中的边界样本的选择概率。
23.在本发明的一个实施例中,所述样本生成子模块包括:
24.少数类边界样本选择单元,所述少数类边界样本选择单元用于根据选择概率在主要矫正社区边界样本集合中选择少数类边界样本;
25.欧氏距离计算单元,所述欧氏距离计算单元用于计算所述少数类边界样本与其多数类边界样本之间的欧氏距离;
26.样本点生成单元,所述样本点生成单元用于将少数类边界样本作为超球体的中心点,以欧氏距离为半径,在所述超球体中随机生成新的样本点;
27.主要社区矫正样本点集合获得单元,所述主要社区矫正样本点集合获得单元用于对少数类边界样本中的所有样本点,重复样本点生成的步骤,直到得到样本点数量满足要求的主要社区矫正样本点集合。
28.此外,本发明还提供一种基于概率加权过采样的社区矫正率预测方法,包括:
29.输入社区矫正原始数据集合,其中所述社区矫正原始数据集合包括次要矫正社区原始数据集合和主要矫正社区原始数据集合;
30.剔除所述主要矫正社区原始数据集合中的噪音样本点,获得剔除噪音样本点后的主要矫正社区数据集合,基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合,计算所述主要矫正社区边界样本集合中的样本的选择概率,并根据所述选择概率生成主要社区矫正样本点集合;
31.将生成的主要社区矫正样本点集合和社区矫正原始数据集合进行求和,获得最终的社区矫正数据集合,利用最终的社区矫正数据集合对神经网络模型进行训练,得到社区矫正率预测模型;
32.接收待预测的社区矫正样本,并将其输入至所述社区矫正率预测模型,输出所述社区矫正样本的预测结果,判断该社区矫正样本是否为主要矫正社区。
33.在本发明的一个实施例中,剔除所述主要矫正社区原始数据集合中的噪音样本点,获得剔除噪音样本点后的主要矫正社区数据集合,包括:
34.计算所述主要矫正社区原始数据集合中的样本点的均值以及标准差,并基于所述样本点的均值和标准差判断所述样本点是否为噪音样本点,得到剔除噪音样本点后的主要矫正社区数据集合。
35.在本发明的一个实施例中,基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合,包括:
36.寻找主要矫正社区数据集合中的每个样本在次要矫正社区原始数据集合中的近邻样本,并将近邻样本组成多数类边界样本集合;
37.寻找多数类边界样本集合中的每个边界样本在所述主要矫正社区数据集合中的近邻样本,并将近邻样本组成主要矫正社区边界样本集合。
38.在本发明的一个实施例中,计算所述主要矫正社区边界样本集合中的样本的选择概率,包括:
39.计算所述主要矫正社区边界样本集合中的边界样本在其同类和异类样本点的局部密度;
40.根据所述局部密度计算边界样本在整个样本空间中的相对密度;
41.根据所述相对密度计算所述边界样本的权重值;
42.对所述权重值进行归一化操作,得到所述主要矫正社区边界样本集合中的边界样本的选择概率。
43.在本发明的一个实施例中,根据所述选择概率生成主要社区矫正样本点集合,包括:
44.根据选择概率在主要矫正社区边界样本集合中选择少数类边界样本;
45.计算所述少数类边界样本与其多数类边界样本之间的欧氏距离;
46.将少数类边界样本作为超球体的中心点,以欧氏距离为半径,在所述超球体中随
机生成新的样本点;
47.对少数类边界样本中的所有样本点,重复样本点生成的步骤,直到得到样本点数量满足要求的主要社区矫正样本点集合。
48.本发明的上述技术方案相比现有技术具有以下优点:
49.本发明提出了基于概率加权过采样的社区矫正率预测系统及方法,其首先对主要矫正社区的样本点数据进行去噪,然后筛选出主要矫正社区的边界样本点并计算这些边界样本点被选取作为样本生成点的选择概率,最后依次根据选择概率选择样本生成点,并在其次要矫正社区类的邻域内生成新的主要矫正社区样本点,从而达到数据样本数量的平衡,克服了现有技术因数据样本数量不平衡而导致的对社区矫正率检测率较低的问题。
附图说明
50.为了使本发明的内容更容易被清楚的理解,下面根据本发明的具体实施例并结合附图,对本发明作进一步详细的说明。
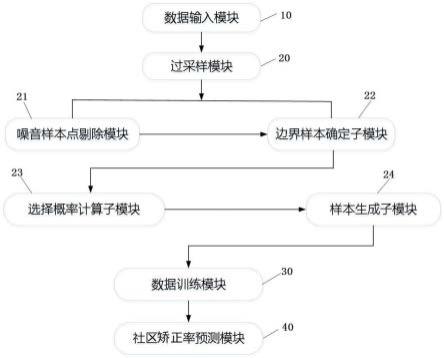
51.图1是本发明基于概率加权过采样的社区矫正率预测系统的硬件结构示意图。
52.图2是本发明基于概率加权过采样的社区矫正率预测方法的流程示意图。
53.其中,附图标记说明如下:10、数据输入模块;20、过采样模块;21、噪音样本点剔除子模块;22、边界样本确定子模块;23、选择概率计算子模块;24、样本生成子模块;30、数据训练模块;40、社区矫正率预测模块。
具体实施方式
54.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
55.请参阅图1所示,本发明实施例提供一种基于概率加权过采样的社区矫正率预测系统,包括:
56.数据输入模块10,所述数据输入模块10用于输入社区矫正原始数据集合,其中所述社区矫正原始数据集合包括次要矫正社区原始数据集合和主要矫正社区原始数据集合;
57.过采样模块20,所述过采样模块20用于剔除所述主要矫正社区原始数据集合中的噪音样本点,获得剔除噪音样本点后的主要矫正社区数据集合,基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合,计算所述主要矫正社区边界样本集合中的样本的选择概率,并根据所述选择概率生成主要社区矫正样本点集合;
58.数据训练模块30,所述数据训练模块30用于将生成的主要社区矫正样本点集合和社区矫正原始数据集合进行求和,获得最终的社区矫正数据集合,利用最终的社区矫正数据集合对神经网络模型进行训练,得到社区矫正率预测模型;
59.社区矫正率预测模块40,所述社区矫正率预测模块40用于接收待预测的社区矫正样本,并将其输入至所述社区矫正率预测模型,输出所述社区矫正样本的预测结果,判断该社区矫正样本是否为主要矫正社区。
60.在本实施例公开的一种基于概率加权过采样的社区矫正率预测系统中,所述过采样模块20包括:
61.噪音样本点剔除子模块21,所述噪音样本点剔除子模块21用于计算所述主要矫正
社区原始数据集合中的样本点的均值以及标准差,并基于所述样本点的均值和标准差判断所述样本点是否为噪音样本点,得到剔除噪音样本点后的主要矫正社区数据集合;
62.边界样本确定子模块22,所述边界样本确定子模块22用于基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合;
63.选择概率计算子模块23,所述选择概率计算子模块23用于计算所述主要矫正社区边界样本集合中的边界样本的选择概率;
64.样本生成子模块24,所述样本生成子模块24用于基于所述选择概率随机生成新的样本点,得到主要社区矫正样本点集合。
65.其中,所述边界样本确定子模块22包括:
66.一次寻找近邻样本单元,所述一次寻找近邻样本单元用于寻找主要矫正社区数据集合中的每个样本在次要矫正社区原始数据集合中的近邻样本,并将近邻样本组成多数类边界样本集合;
67.二次寻找近邻样本单元,所述二次寻找近邻样本单元用于寻找多数类边界样本集合中的每个边界样本在所述主要矫正社区数据集合中的近邻样本,并将近邻样本组成主要矫正社区边界样本集合。
68.其中,所述选择概率计算子模块23包括:
69.局部密度计算单元,所述局部密度计算单元用于计算所述主要矫正社区边界样本集合中的边界样本在其同类和异类样本点的局部密度;
70.相对密度计算单元,所述相对密度计算单元用于根据所述局部密度计算边界样本在整个样本空间中的相对密度;
71.权重计算单元,所述权重计算单元用于根据所述相对密度计算所述边界样本的权重值;
72.选择概率确定单元,所述选择概率确定单元用于对所述权重值进行归一化操作,得到所述主要矫正社区边界样本集合中的边界样本的选择概率。
73.其中,所述样本生成子模块24包括:
74.少数类边界样本选择单元,所述少数类边界样本选择单元用于根据选择概率在主要矫正社区边界样本集合中选择少数类边界样本;
75.欧氏距离计算单元,所述欧氏距离计算单元用于计算所述少数类边界样本与其多数类边界样本之间的欧氏距离;
76.样本点生成单元,所述样本点生成单元用于将少数类边界样本作为超球体的中心点,以欧氏距离为半径,在所述超球体中随机生成新的样本点;
77.主要社区矫正样本点集合获得单元,所述主要社区矫正样本点集合获得单元用于对少数类边界样本中的所有样本点,重复样本点生成的步骤,直到得到样本点数量满足要求的主要社区矫正样本点集合。
78.本发明提出了一种基于概率加权过采样的社区矫正率预测系统,其首先对主要矫正社区的样本点数据进行去噪,然后筛选出主要矫正社区的边界样本点并计算这些边界样本点被选取作为样本生成点的选择概率,最后依次根据选择概率选择样本生成点,并在其次要矫正社区类的邻域内生成新的主要矫正社区样本点,从而达到数据样本数量的平衡,克服了现有技术因数据样本数量不平衡而导致的对社区矫正率检测率较低的问题。
79.此外,请参阅图2所示,本发明实施例还提供一种基于概率加权过采样的社区矫正率预测方法,包括:
80.s1:输入社区矫正原始数据集合,其中所述社区矫正原始数据集合包括次要矫正社区原始数据集合和主要矫正社区原始数据集合;
81.s2:剔除所述主要矫正社区原始数据集合中的噪音样本点,获得剔除噪音样本点后的主要矫正社区数据集合,基于所述主要矫正社区数据集合获得主要矫正社区边界样本集合,计算所述主要矫正社区边界样本集合中的样本的选择概率,并根据所述选择概率生成主要社区矫正样本点集合;
82.s3:将生成的主要社区矫正样本点集合和社区矫正原始数据集合进行求和,获得最终的社区矫正数据集合,利用最终的社区矫正数据集合对神经网络模型进行训练,得到社区矫正率预测模型;
83.s4:接收待预测的社区矫正样本,并将其输入至所述社区矫正率预测模型,输出所述社区矫正样本的预测结果,判断该社区矫正样本是否为主要矫正社区。
84.本发明提出了基于概率加权过采样的社区矫正率预测方法,其首先对主要矫正社区的样本点数据进行去噪,然后筛选出主要矫正社区的边界样本点并计算这些边界样本点被选取作为样本生成点的选择概率,最后依次根据选择概率选择样本生成点,并在其次要矫正社区类的邻域内生成新的主要矫正社区样本点,从而达到数据样本数量的平衡,克服了现有技术因数据样本数量不平衡而导致的对社区矫正率检测率较低的问题。
85.在本发明公开的一种基于概率加权过采样的社区矫正率预测方法中,对于上述实施方式的s1,包括:
86.输入社区矫正原始数据集合d={(xi,yi)|xi∈rd,yi∈{0,1},i=1,
…
,n},n是社区矫正原始数据集中样本的总数,d是社区矫正原始数据集的特征数,xi表示第 i条社区矫正数据,yi是其标签。若yi=0,则xi为次要社区;若yi=1,则xi为主要社区。令d=d
maj
∪d
min
,其中d
maj
为多数类数据集合,即次要矫正社区原始数据集合,其样本数记为n
maj
;d
min
为少数类数据集合,即主要矫正社区原始数据集合,其样本数记为n
min
。令所需新生成的样本点个数为n
new
=n
maj-n
min
。
87.在本发明公开的一种基于概率加权过采样的社区矫正率预测方法中,对于上述实施方式的s2,包括:
88.s2.1:计算主要矫正社区原始数据集合中的样本的均值μ=[μ1,μ2,...,μd]
t
以及标准差σ=[σ1,σ2,...,σd]
t
。本实施例假定满足一定条件的样本点为噪音样本点,即,若对i∈[1,
…
,n
min
],j=1,
…
,d,只要|x
ij-μj|>4σj成立,则该样本点被认为是噪音样本点,若样本点为噪音样本点,则去除这些样本点,得到主要矫正社区数据集合d'
min
,其样本点个数记为n'
min
。
[0089]
s2.2:在主要矫正社区数据集合d'
min
中,对于其中的每个样本xi∈d'
min
在次要矫正社区原始数据集合d
maj
中寻找其k1个近邻,并将所有找到的近邻样本组成一个多数类的边界样本集合,记为对于每个多数类的边界样本在主要矫正社区数据集合d'
min
中寻找其k2个近邻,并将所有找到的近邻样本组成一个少数类的边界样本集合,也就是主要矫正社区边界样本集合,记为令该集合的数量为
[0090]
s2.31:计算所有主要矫正社区边界样本xi在其同类和异类样本点的局部密度:
[0091][0092][0093]
其中表示样本xi和样本之间的欧氏距离,k是预定义的近邻个数,density
min
(xi)是xi在其少数类中的局部密度,表示xi在其少数类集合d'
min
中的第k个近邻样本点;density
maj
(xi)是xi在其多数类中的局部密度,表示的是xi在多数类集合d
maj
中的第k个近邻样本。
[0094]
s2.32:计算所有在整个样本空间中的相对密度:
[0095][0096]
s2.33:计算所有的权重w(xi):
[0097][0098]
其中mi是xi在两类数据的近邻样本中多数类样本的个数。
[0099]
s2.34:对权重值进行归一化操作,得到每个主要矫正社区边界样本的选择概率sp(xi):
[0100][0101]
s2.41:根据选择概率sp(xi)在主要矫正社区边界样本集合中选择一个少数类的边界样本xi。
[0102]
s2.42:计算样本与其多数类最近邻样本之间的欧氏距离
[0103]
s2.43:将样本作为超球体的中心点,以距离为半径,在这个以xi为中心点的超球体中随机选择一个点,即为生成新的样本点。
[0104]
s2.44:对中的所有样本点,重复样本生成的s2.41-s2.43,直到样本点数量达到n
new
。由此,得到新的主要社区矫正样本点集合d
new
。
[0105]
为了验证本发明提出的基于概率加权过采样的社区矫正率预测系统及其方法的性能。本发明在us_crime数据集上进行五折交叉验证实验,将数据集随机划分成五份,其中一份作为测试集,其余四份作为训练集进行新数据样本的生成。在样本生成后,对测试集进行分类,采用随机森林rf (n_estimators=100)和adaboost(n_estimators=50)来对过采样之后得到新的数据集进行分类,我们取十次五折交叉验证得到的平均值作为该实验的结果。在过采样方法中,对比方法采用smote和borderline-smote。
[0106]
采用auc,f1-score,g-mean三个不同评价指标下对分类效果进行评估,
[0107]
auc=area under receiver operating characteristic curve
[0108][0109][0110][0111][0112]
其中tp、fn、fp以及tn见表1中的混淆矩阵所示。
[0113]
表1混淆矩阵
[0114] 预测值=1预测值=0真实值=1tpfn真实值=0fptn
[0115]
分类结果如表2所示,本发明与smote和borderline-smote相比,在auc, f1-score和g-mean这三个指标下的效果较好。
[0116]
表2三种过采样方法的结果对比
[0117][0118]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0119]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0120]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特
定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0121]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0122]
显然,上述实施例仅仅是为清楚地说明所作的举例,并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。