一种基于注意力机制和lstm的tor网站指纹识别方法
技术领域
1.本发明涉及网络安全技术领域,具体为一种基于注意力机制和lstm的tor网站指纹识别方法。
背景技术:
2.洋葱路由器(tor)是一种通信工具,可为互联网用户提供匿名性。tor对通信的内容和路由信息进行加密,不仅通过随机分配的节点路由转发加密的流量,还通过分割流量数据为固定长度512b的cell,并采用周期性切换circuit等匿名手段,以此来确保用户浏览活动的隐私。目前已有数百万的用户每天通过tor来匿名访问网站,从而来隐蔽自己的网络活动。
3.循环神经网络是深度学习领域中一类特殊的内部存在自连接的神经网络,适合处理时序数据,虽然rnn在处理时间序列关系上表现良好,但标准rnn结构存在梯度消失或梯度爆炸问题。长短时神经网络(long short term memory,lstm)是rnn的变体,其改进了传统rnn的记忆模块,避免了因为数据持续输入而无法长期保存有效历史信息的问题。
4.网站指纹是访问一个网站过程中产生的网络流量,例如数据包的大小、顺序和时间等非敏感信息可以形成网站指纹(website fingerprinting,wf)。对于不同的网站,其网页内容都大不相同(如网页代码、图片、脚本、样式表等等),因此尽管通信内容加密,浏览器在加载网页时产生的匿名流量元数据也不尽相同。因此,可以通过网站指纹来区别不同的网站。
5.tor等匿名网络常常被不法分子滥用以遮盖其网络犯罪行为,严重违背了保护用户隐私和匿名性的设计初衷,若缺乏有效的监管技术,政府难以识别追踪隐藏在匿名网络中的非法地下网站,无法准确打击相关犯罪行为,因此,提高匿名网络的监管水平势在必行,而网站指纹识别的方法恰好能对匿名网络实施监管和审查。
6.现有的网站指纹识别方法主要分为传统机器学习方法和深度学习方法,传统机器学习方法依靠人工提取特征,成本较高的同时,网站指纹识别的准确率也比较低;而深度学习方法不依靠人工提取特征,直接从tor流量中提取出cell序列作为输入,经过多层神经网络进行学习,最终输出网站的类别,但这种方法对长时间序列输入特征没有区分,会忽略某些包含重要信息量的时序节点。
7.基于对上述资料的检索,可以看出,现有tor网站指纹识别存在准确率比较低的缺陷,为此,特提出一种基于注意力机制和lstm的tor网站指纹识别方法,本方法设计了注意力机制和lstm网络相结合的模型结构,在lstm网络的基础上,设计了更适合处理长序列的多分支lstm网络,同时引入了注意力机制,来对lstm网络提取出来的时间特征进行权重参数优化,以突出关键时间特征对指纹识别结果的影响。
技术实现要素:
8.(一)解决的技术问题
9.针对现有技术的不足,本发明提供了一种基于注意力机制和lstm的tor网站指纹识别方法,解决了现有tor网站指纹识别存在准确率比较低的问题。
10.(二)技术方案
11.为实现上述目的,本发明提供了如下技术方案:一种基于注意力机制和lstm的tor网站指纹识别方法,具体包括以下步骤:
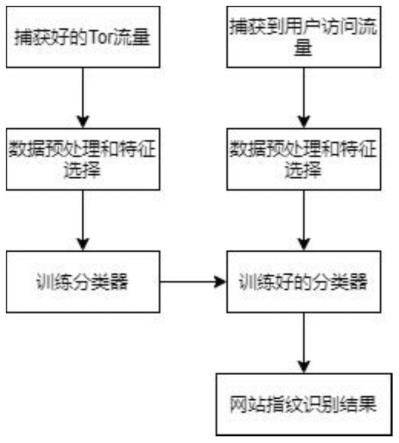
12.步骤一、流量捕获:使用tcpdump工具收集访问流量,并对每条访问流量打上标签,捕获到被监控网站的访问流量;
13.步骤二、特征筛选:对捕获好的访问流量做数据预处理,得到tls记录长度序列,将tls记录长度向512的整数倍取近似,按照数据包方向添加符号,最终转化成cell表示序列,作为网站指纹识别模型的输入;
14.步骤三、模型构建:搭建输入层、partition层、lstm层、注意力机制层、融合层和softmax层,构建出基于注意力机制和lstm的分类器模型,将步骤二中的cell表示序列输入到模型中,通过partition层将cell表示序列划分成两个部分,构建多分支lstm网络架构来进行时间特征的提取,对每个分支分别经过lstm层提取时间特征,接着通过注意力机制层对时间特征矩阵进行加权优化,得到优化后的时间特征,融合两个分支网络输出的时间特征,然后通过softmax层进行多分类,最终输出所识别网站的类别;
15.步骤四、模型训练:将采集到的数据随机划分为训练集和测试集,采用adam作为优化器,为防止深度神经网络训练过程中出现过拟合现象,采用dropout进行正则化,将交叉熵损失函数作为损失函数,使用accuracy作为评估指标,进行分类器的训练;
16.步骤五、性能评估:使用步骤四中的测试集对训练好的分类器模型进行性能评估。
17.通过采用上述技术方案,基于tor访问流量的数据特点,提取出cell序列作为模型输入特征,并基于注意力机制和lstm相结合的方式,使用多分支lstm网络从cell序列中提取时间特征,再使用注意力机制对时间特征做权重参数优化,以发现并突出关键时间特征对网站指纹识别结果的影响,弥补了现有tor网站指纹识别准确率比较低的缺陷。
18.本发明进一步设置为:所述步骤一中的进行流量捕获前首先设定要监控的网站的列表,并获取被监控网站的地址,通过tor browser来依次访问被监控网站,每个网站访问1000次。
19.本发明进一步设置为:所述步骤一种对每条访问流量打上的标签,包括访问流量所属的网站类别。
20.本发明进一步设置为:所述步骤二中的预处理方式为对tcp数据包序列进行tcp流重组,并记录每条tls记录长度,将其转化为tls记录长度序列。
21.本发明进一步设置为:所述步骤二中添加符号具体包括:请求数据包为正数,响应数据包为负数。
22.本发明进一步设置为:所述步骤三中采用划分子序列的方式,通过partition层将cell表示序列划分成两个部分。
23.通过采用上述技术方案,避免由于cell表示序列长度过长,单分支lstm网络容易造成训练时间长、梯度消失的问题。
24.本发明进一步设置为:所述步骤四中训练集和测试集的占比为80%和20%。
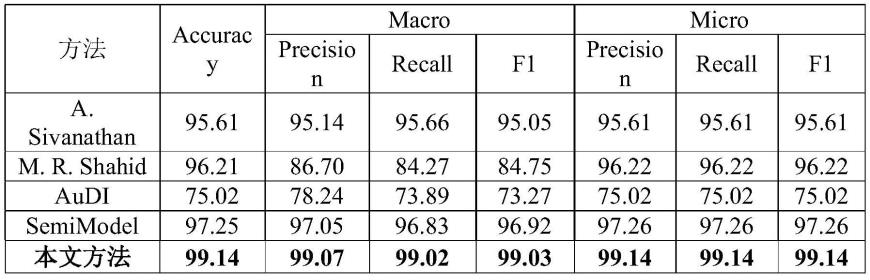
25.本发明进一步设置为:所述步骤五中的性能评估包括计算准确率、tpr和fpr指标。
26.(三)有益效果
27.本发明提供了一种基于注意力机制和lstm的tor网站指纹识别方法。具备以下有益效果:
28.(1)该基于注意力机制和lstm的tor网站指纹识别方法,通过基于tor访问流量的数据特点,提取出cell序列作为模型输入特征,并基于注意力机制和lstm相结合的方式,使用多分支lstm网络从cell序列中提取时间特征,再使用注意力机制对时间特征做权重参数优化,以发现并突出关键时间特征对网站指纹识别结果的影响,弥补了现有tor网站指纹识别准确率比较低的缺陷。
29.(2)该基于注意力机制和lstm的tor网站指纹识别方法,通过采用划分子序列的方式,将cell表示序列划分成两个部分,避免了由于cell表示序列长度过长,单分支lstm网络容易造成训练时间长、梯度消失的问题,并且采用dropout进行正则化,有效防止深度神经网络训练过程中出现过拟合现象。
附图说明
30.图1为本发明所述方法的算法流程图;
31.图2为本发明所述方法的数据预处理方法示意图;
32.图3为本发明的基于注意力机制和lstm的网络架构图。
具体实施方式
33.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
34.请参阅图1-3,本发明实施例提供以下两种技术方案:
35.实施例一、
36.一种基于注意力机制和lstm的tor网站指纹识别方法,具体包括以下步骤:
37.步骤一、流量捕获:使用tcpdump工具收集访问流量,并对每条访问流量打上标签,捕获到被监控网站的访问流量;
38.步骤二、特征筛选:对捕获好的访问流量做数据预处理,得到tls记录长度序列,将tls记录长度向512的整数倍取近似,按照数据包方向添加符号,最终转化成cell表示序列,作为网站指纹识别模型的输入;
39.步骤三、模型构建:搭建输入层、partition层、lstm层、注意力机制层、融合层和softmax层,构建出基于注意力机制和lstm的分类器模型,将步骤二中的cell表示序列输入到模型中,通过partition层将cell表示序列划分成两个部分,构建多分支lstm网络架构来进行时间特征的提取,对每个分支分别经过lstm层提取时间特征,接着通过注意力机制层对时间特征矩阵进行加权优化,得到优化后的时间特征,融合两个分支网络输出的时间特征,然后通过softmax层进行多分类,最终输出所识别网站的类别;
40.步骤四、模型训练:将采集到的数据随机划分为训练集和测试集,采用adam作为优化器,为防止深度神经网络训练过程中出现过拟合现象,采用dropout进行正则化,将交叉
熵损失函数作为损失函数,使用accuracy作为评估指标,进行分类器的训练;
41.步骤五、性能评估:使用步骤四中的测试集对训练好的分类器模型进行性能评估,进一步说明。
42.实施例二、
43.本实施例作为上一实施例的改进,一种基于注意力机制和lstm的tor网站指纹识别方法,具体包括以下步骤:
44.步骤一、流量捕获:首先设定要监控的网站的列表,并获取被监控网站的地址,通过tor browser来依次访问被监控网站,每个网站访问1000次,使用tcpdump工具收集访问流量,并对每条访问流量打上标签,即访问流量所属的网站类别,捕获到被监控网站的访问流量;
45.步骤二、特征筛选:对捕获好的访问流量做数据预处理,对tcp数据包序列进行tcp流重组,并记录每条tls记录长度,将其转化为tls记录长度序列,得到tls记录长度序列,将tls记录长度向512的整数倍取近似,按照数据包方向添加符号,即请求数据包为正数,响应数据包为负数,最终转化成cell表示序列,作为网站指纹识别模型的输入;
46.步骤三、模型构建:搭建输入层、partition层、lstm层、注意力机制层、融合层和softmax层,构建出基于注意力机制和lstm的分类器模型,将步骤二中的cell表示序列输入到模型中,采用划分子序列的方式,通过partition层将cell表示序列划分成两个部分,构建多分支lstm网络架构来进行时间特征的提取,对每个分支分别经过lstm层提取时间特征,接着通过注意力机制层对时间特征矩阵进行加权优化,得到优化后的时间特征,融合两个分支网络输出的时间特征,然后通过softmax层进行多分类,最终输出所识别网站的类别;
47.步骤四、模型训练:将采集到的数据随机划分为训练集和测试集,训练集和测试集的占比为80%和20%,采用adam作为优化器,为防止深度神经网络训练过程中出现过拟合现象,采用dropout进行正则化,将交叉熵损失函数作为损失函数,使用accuracy作为评估指标,进行分类器的训练;
48.步骤五、性能评估:使用步骤四中的测试集对训练好的分类器模型进行性能评估,计算准确率、tpr和fpr指标。
49.实施例二相对于实施例一的优点在于:采用划分子序列的方式,将cell表示序列划分成两个部分,避免了由于cell表示序列长度过长,单分支lstm网络容易造成训练时间长、梯度消失的问题,并且采用dropout进行正则化,有效防止深度神经网络训练过程中出现过拟合现象。
50.综上所述,可以看出:
51.1)、基于注意力机制和lstm相结合的方法,该方法的核心步骤包括:
52.a、首先通过多分支lstm网络来提取时间特征;
53.b、接着通过注意力机制对时间特征做权重参数优化;
54.c、最后融合多分支加权处理之后的时间特征,再经过softmax层输出最终网站识别的结果。
55.2)、基于注意力机制的特征优化方法,该方法的核心步骤包括:
56.d、首先设计一个全连接神经网络作为权重函数,将原始特征通过全连接神经网络
得到其相应的权重参数;
57.e、使用softmax激活函数来对输出权重参数进行归一化;
58.f、将原始特征与归一化后的权重参数进行逐元素间的乘积,最终得到权重参数优化后的特征。
59.即本发明基于tor访问流量的数据特点出发,首先提取出cell序列作为模型输入特征,考虑到cell序列的两个特点:具有时序性;序列长度过长,容易忽略某些包含重要信息量的时序节点。因此本发明提出了基于注意力机制和lstm相结合的方法,使用多分支lstm网络从cell序列中提取时间特征,再使用注意力机制对时间特征做权重参数优化,以发现并突出关键时间特征对网站指纹识别结果的影响,弥补了现有tor网站指纹识别准确率比较低的缺陷。
60.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。