媒体内容发现以及角色组织技术
1.本技术是分案申请,其原案申请是申请号为pct/us2014/028582、申请日为2014年3月14日的pct申请并且于2015年10月19日进入中国国家阶段,国家申请号为201480022305.0,名称为“媒体内容发现以及角色组织技术”。
2.相关申请的交叉引用
3.本技术请求保护2013年3月15日提交的美国发明申请no.13/844,125以及2013年10月28日提交的美国发明申请no.14/065,332的优先权,它们中的每一个都通过引用在此并入本文。
技术领域
4.本发明总体涉及媒体内容发现领域,更具体地涉及采用角色分解的媒体内容发现。
背景技术:
5.诸如电视节目和电影之类的媒体已经变得越来越普及而且越来越容易在消费者的日常生活中获取,媒体的数量及多样化也同样得到了极大的提高。以前,消费者受限于主要的电视网络所广播的很少的几个电视频道。随着技术的发展,各种媒体都可用于随客户方便而按需观看。随着这种按需能力在电视行业(例如,点播电影)和个人计算机领域(例如,youtube视频流)变得更加普遍,消费者在任何一个时刻都被选择能力所冲击。类似地,消费者搜索媒体以发现满足个人喜好和品位的新内容的能力仍不够有效而且效率不高。
6.传统的发现新媒体的技术依赖于朋友和熟人介绍他们认为该消费者会喜欢的媒体。或者,消费者可查看预览俘获他们的注意力的媒体或者消费者可由于媒体包括喜欢的男演员或女演员而查看该媒体。然而,这些技术具有的一个很大的缺陷就是,它们仅仅使用非常狭隘的精确度来识别内容而且可能是不可靠的。例如,虽然喜爱的女演员可能在电影中表演一个受教育的、谦逊的、控制局势的人物角色,该女演员可在后面的电影中表演一个未受教育的、没有礼貌的、不受欢迎的人物角色。因此,理解角色的品质有利于理解这些角色所出现的媒体。
7.由此,有效并可靠地分解角色的品质的技术是有利的。
技术实现要素:
8.描述了用于发现并推荐媒体内容的系统和处理。针对媒体内容中出现的多个角色的一组突显值被访问。该组突显值与媒体内容关联。用户的角色偏好函数被访问。角色偏好函数包括识别多个偏好系数的信息。多个偏好系数的每个偏好系数与多个属性中的至少一个关注属性关联。第一角色模型被访问。第一角色模型包括识别多个角色中的第一角色的多个属性的第一属性值组的信息。第一角色与该组突显值的第一突显值关联。第二角色模型被访问。第二角色模型包括识别多个角色中的第二角色的多个属性的第二属性值组的信息。第二角色与该组突显值的第二突显值关联。通过执行多个偏好系数与第一属性值组的
乘积的求和来计算第一角色的第一角色评级。通过执行多个偏好系数与第二属性值组的乘积的求和来计算第二角色的第二角色评级。根据第一突显值、第二突显值、第一角色评级和第二角色评级计算媒体内容评级。根据媒体内容评级向用户推荐媒体内容。
附图说明
9.图1图示出矢量空间中针对多个角色的角色模型。
10.图2图示出用于执行角色和媒体内容的发现和组织的示例框图。
11.图3图示出用于推荐媒体的示例处理。
12.图4图示出用于推荐媒体的另一示例处理。
13.图5图示出示例计算系统。
具体实施方式
14.提供下面的描述以使得本领域普通技术人员能够做出及实现各种实施例。具体装置、技术和应用的描述仅仅被提供作为示例。本领域普通技术人员很容易想到对此处描述的示例的各种修改,而且此处定义的总原理可适用于其它示例和应用,而不脱离本技术的精神和范围。因此,各种实施例并不限于此处描述和表示的示例,而是遵循与权利要求一致的最宽范围。
15.此处描述的实施例包括旨在实现根据媒体中的角色(或角色的属性)来组织并发现角色和媒体内容的技术。媒体和媒体内容指的是用于存储和传递信息的内容。例如,媒体内容可包括电视节目、电影、youtube视频、数字流网络视频、书籍、诗篇、故事、音频文件、广告、新闻等。
16.角色指的是人物角色。例如,角色可包括政治家、男演员/女演员、现实人物、漫画角色等。角色的属性指的是角色的品质。例如,角色的职业(例如,科学家、律师、医生、秘书)、人口统计信息(例如,年纪、性别、种族、亲代状态)、位置(例如,城市、乡村)、社会特征(例如,亲切的、忠诚的、搞笑的、领导、受欢迎、友好)、物理特征(例如,高、矮、体重、吸引力)、智力特征(例如,能胜任具体人物、聪明的、努力的、擅长数学)、生命特征(例如,受压迫的、被宠坏的)等都是角色的属性。可在二进制空间表示属性,例如在角色是“亲切的”或“不亲切的”之间进行区分。还可以在连续空间中表示属性,例如在实数范围0至10、-10至10、0至100等上区分角色亲切的程度。
17.消费者可能由于某个特定电视节目中角色所勾勒出的积极信息而喜欢这个特定电视节目。这种积极信息通常基于角色在该节目中的多种属性,而不是严格地基于角色的动作或角色的口头讲述的内容。例如,被描绘成自信且聪明的有魅力的女性角色即勾勒了积极信息。为了理解为什么消费者被角色吸引,有用的是建立捕获角色的属性的角色模型。也可以,要么通过直接引导出为什么特定消费者喜欢角色或者与角色有关联,要么通过简单地根据一系列喜欢的和/或不喜欢的角色推断偏好函数,来开发基于消费者的优选属性的角色偏好函数。角色模型和角色偏好函数被用于向消费者推荐媒体,对消费者喜欢或者响应特定内容段的可能性进行评级,向消费者推荐新角色,向消费者推荐或传递其它内容,或者对消费者喜欢特定角色或内容段的可能性进行评级。
18.矢量空间中的角色模型
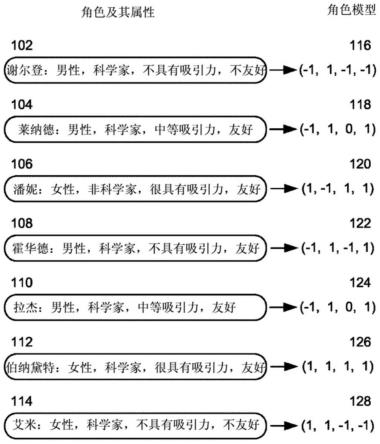
19.图1图示出矢量空间中多个角色的角色模型。在图1中,根据来自电视节目生活大爆炸的角色102-114的属性对角色模型116-128进行映射。电视节目生活大爆炸是情景喜剧,其将各种各样角色带到了一起,从具有有限社会技能的令人讨厌的智力发达的角色到没有受过太多教育但是社交能力强的角色。图1所示的每个角色模型捕获了相关角色的属性的多维的表示。在该示例中,每个角色模型116-128以矢量的形式进行存储。本领域普通技术人员将理解的是,可利用各种方法来存储角色模型。
20.在图1的示例中,角色模型116-128的矢量是四维的。每个角色模型的第一维中的值基于角色的性别,其中女性由1表示,男性由-1表示。每个角色模型的第二维中的值基于角色是否是科学家,其中科学家由1表示,而非科学家由-1表示。每个角色模型的第三维中的值基于角色的吸引力,其中-1表示没有吸引力,0表示中等吸引力,而1表示很有吸引力。每个角色模型的第四维中的值基于角色是否友好,其中1表示友好,而-1表示不友好。
21.在情景喜剧生活大爆炸中,谢尔登102是研究量子力学和弦理论的男性理论物理学家。谢尔登具有b.s.、m.s.、m.a.、ph.d.和sc.d.文凭。他是一个不友好的内向的人,他的外表不具吸引力。谢尔登的102属性被映射至矢量116。矢量116是(-1,1,-1,-1)。清楚起见,矢量116被注释为(-1[男性],1[科学家],-1[没有吸引力],-1[不友好])。
[0022]
在生活大爆炸中,莱纳德104是男性物理学家。他在24岁时获得了他的ph.d.学位。他的外表吸引力是中等的,表示他不是没有吸引力也不是很有吸引力,而且他是友好的。莱纳德的104属性被映射至矢量118。矢量118是(-1,1,0,1)。清楚起见,矢量118被注释为(-1[男性],1[科学家],0[中等吸引力],1[友好])。
[0023]
潘妮106是友好的、具有吸引力的、高个的、金发碧眼的女性服务员,她正在追求演艺事业。潘妮的106属性被映射至矢量120。矢量120是(1,-1,1,1)。清楚起见,矢量120被注释为(1[女性],-1[非科学家],1[很有吸引力],1[友好])。
[0024]
霍华德108是男性的航空航天工程师,他具有工程学硕士学位。他在社交上是容易相处的而且友好的,但是外表不吸引人。霍华德的108属性被映射至矢量122。清楚起见,矢量122是(-1,1,-1,1)。矢量122被注释为(-1[男性],1[科学家],-1[没有吸引力],1[友好])。
[0025]
拉杰110是加利福尼亚理工学院的男性粒子物理学家而且具有ph.d学位。他的外表吸引力是中等的,而且他是友好的。拉杰的110属性被映射至矢量124。矢量124是(-1,1,0,1)。清楚起见,矢量124被注释为(-1[男性],1[科学家],0[中等吸引力],1[友好])。
[0026]
伯纳黛特112是女性,具有微生物学的ph.d.学位。她不但具有吸引力而且是友好的。伯纳黛特的112属性被映射至矢量126。矢量126是(1,1,1,1)。清楚起见,矢量126被注释为(1[女性],1[科学家],1[很有吸引力],1[友好])。
[0027]
艾米114是女性,具有神经生物学的ph.d.学位。她是不友好的,而且外表不具有吸引力。艾米的114属性被映射至矢量128。矢量128是(1,1,-1,-1)。清楚起见,矢量128被注释为(1[女性],1[科学家],-1[没有吸引力],-1[不友好])。
[0028]
矢量空间驱动搜索
[0029]
矢量空间中描述的角色模型可被用于各种搜索。在一个示例中,图1的角色模型116-128可被用来快速精确地识别呈现特定属性的所有角色。为了识别出很具有吸引力的所有角色,进行其中对角色模型矢量的第三个元素执行等式测试的搜索。如上所述以及如
图1的示例所示,每个矢量的第三维(或第三个值)表示相关角色的吸引力。具有作为矢量的第三维的大于0的值的所有角色模型与很有吸引力的角色关联。在图1的示例中,潘妮和伯纳黛特通过确定他们具有大于0的吸引力值而被快速并且精确地识别为很有吸引力。
[0030]
类似地,谢尔登、霍华德和艾米可被快速并且精确地识别为不具有吸引力,因为他们具有小于0的吸引力值,表示他们不具有吸引力。如上所述,角色模型116-128的第二维(或第二值)描述了角色是科学家还是非科学家。针对所有科学家的搜索将识别在第二维中具有值1的所有角色模型。在图1的示例中,针对科学家的搜索返回结果——谢尔登、莱纳德、霍华德、拉杰、伯纳黛特和艾米—除了潘妮之外的所有人。
[0031]
此外,针对角色的特定特点的搜索可能取决于角色模型矢量的多个维度。例如,可通过识别具有将他们识别为“喜欢科学”而且“擅长科学”的角色模型的角色来进行针对“科学家”的搜索。
[0032]
矢量空间还可用于确定角色之间的距离。该距离表示了(类似的或不类似的)两个角色彼此有多关联。多种技术可被用来确定两个角色之间的距离。
[0033]
采用第一技术,可采用加权的欧氏距离来确定与第一角色模型矢量(x1,x2,x3,x4)相关的第一角色以及与第二角色模型矢量(y1,y2,y3,y4)相关的第二角色之间的距离d,加权的欧氏距离为:
[0034][0035]
一般地说,针对n维空间的第一角色与第二角色之间的加权的欧氏距离d可使用下述等式计算:
[0036][0037]
作为该第一技术的示例,可使用图1的角色模型116和118来如下地计算谢尔登和莱纳德之间的距离,假设对于所有i有权值βi=1:
[0038][0039]
如该计算所示,具有相同值的角色模型的元素不对距离有贡献。因此,如果两个角色具有相同的角色模型,他们的距离将为0。在谢尔登和莱纳德的情况下,他们共享许多但不是所有属性。具体地,谢尔登和莱纳德之间的差异是他们的吸引力和他们的友好度。友好度的开方差值的贡献(即,4)比吸引力的的开方差值所导致的贡献(即,1)更大。由此,两个角色之间的距离是5的平方根。
[0040]
采用第二技术,与第一角色模型矢量(x1,x2,x3,x4)相关的第一角色和与第二角色模型矢量(y1,y2,y3,y4)相关的第二角色之间的距离d可通过进行角色模型的值的比较来确定:
[0041][0042]
在该比较中,两个比较值的结果在它们不相等时为1类似地,两个比较值的结果在它们相等时为0。如果x1和y1不相等,(x1!=y1)的值将为1。这将贡献值1至距离或者
如果x1和y1相等,(x1!=y1)的值将为0。这将不对距离产生贡献。由此,在角色共享属性时,使用该第二技术,针对角色的距离将较小。
[0043]
再次地,事实可能是,某些轴总体上更重要或者就特定用户而言比其它用户更重要。这再次地可以由一系列“权值”βi表示。更一般地说,第一角色和第二角色之间针对n维空间的距离d可采用下述等式进行计算:
[0044][0045]
作为该第二技术的示例,可采用图1的角色模型116和118如下地计算谢尔登和莱纳德之间的距离:
[0046]
d(sheldon,leonard)=((-1)!=(-1)) (1!=1) ((-1)!=0) ((-1)!=1)=2
[0047]
如该计算所示,具有相同值的角色模型的元素不对距离做出贡献。因此,如果两个角色具有相同的角色模型,他们的距离将为0。在谢尔登和莱纳德的情况下,他们共享许多但不是全部的属性。具体地,霍华德和拉杰之间的差异是吸引力的友好性。这两个差异的每一个都对距离产生相同量的共享(即,1)。由此,这两个角色之间的距离为2。
[0048]
这两种技术都使用常用于计算矢量空间中的距离的简单的对称的函数。然而,在角色的情况下,事实可能是,在计算从第一角色至第二角色的距离时,可能会更重要地考虑对角色“重要”的属性,同时在计算从角色至角色的反向距离时,可能会考虑对角色“重要”的属性。例如
–
可能会确定不管何时角色在特定属性上是“中性的”,该属性上的“权值”为0,否则该属性上的“权值”为1。在该情况下,从谢尔登至莱纳德的距离为:
[0049][0050]
然而,
[0051][0052]
因此,谢尔登至莱纳德的距离大于莱纳德至谢尔登的距离,这是因为“外表”对于谢尔登的角色比莱纳德的角色更凸显。存在许多方式来使得这些距离函数变得更复杂来适应角色空间或者特定用户的特征。
[0053]
在完全的一般意义上,将角色空间中的两个元素变成数量的任意函数可用作距离函数。对于距离d:
[0054][0055]
在另一示例中,用于确定两个角色之间的距离的第一和第二技术都将得到潘妮和谢尔登之间的距离大于针对谢尔登和莱纳德计算的距离。潘妮和谢尔登之间的距离对于这两种技术都会得到它们的最大值,这是因为潘妮和谢尔登在他们的角色模型的所有四个维度上都是完全相反的。
[0056]
如上所述,角色之间的距离表示了角色之间的相似度。因此,在已知消费者喜欢特定角色时,计算系统可推荐与已知角色相距相对较小的距离的其它角色。系统可推荐与已
知角色相距的距离小于具体阈值的所有已知角色。可替换地,或者此外地,系统可推荐x个最接近的角色,其中x是用户设置的或者系统确定的阈值。可替换地,或者此外地,系统可根据相关性或距离的水平来推荐排列的列表。
[0057]
开发角色模型
[0058]
图1所示的角色模型116-128提供了单个电视节目的示例。为了开发跨越大量媒体内容的大量角色的角色模型,自动化技术、部分自动化技术、手工技术及其组合被采用。下文讨论了多种技术,它们可单独或者组合使用。
[0059]
文本的语义分析可被用来开发角色模型。在基于文本的不同媒体之间识别与角色相关的文本,例如网站。从文本中汇集与角色相关的项。语义分析技术随后被用来将角色映射至期望的特征空间。例如,可通过识别与潘妮106关联的文本来采用语义分析开发针对潘妮106的角色模型。例如,在文本是相对于角色的名字或图像的特定数量的单词或更少单词时,可利用角色来识别文本。从识别出的文本中汇集诸如“工程师”、“科学”或“善于分析”之类的各种项。这些术语被映射至角色的适当属性。在该情况下,适当属性是“科学家”。在一个示例中,每次项被映射至角色属性时,该角色的属性值增大一个确定的量—例如1。类似地,当项被映射至角色的属性的负面时,例如“不喜欢数学”,该角色的属性值减小一个确定的量—例如1。在任一情况下,属性值增大或减小的确定的量可基于该项的强度值。项“工程师”可具有强度值0.25,同时项“美丽动人”具有强度值1.0。类似地,“极其美丽动人”可具有强度值1.5。映射和强度值可存储在数据库中以方便在开发角色模型时进行访问。
[0060]
描述角色的项的潜在源包括角色的官方网页、角色的维基百科网页以及角色出现的节目、粉丝专页、社交网络主页、社交网络聊天工具(例如,来自twitter的推文、facebook评论等)以及其他源。
[0061]
汇集用户对角色的响应也可用来开发角色模型。例如,与角色的属性关联的响应可被确定为“积极的”或“消极的”并且可被用来相应地增大或减小角色模型中的属性值。可从网络上汇集用户的响应,例如社交网络、网页、电子邮件等。此外,角色模型可基于用户明确的拇指向上和拇指向下、利用用户喜欢的其它网页和/或用户作为一部分的互联网组聚集用户对角色的偏好、提到角色的网页和互联网组的专家评价、针对节目的尼尔森评级、奖项、行业性杂志、专家评论和编辑复审。
[0062]
调查方法可被用来开发角色模型。可进行调查以访问大众对于角色的属性的意见。调查可询问多个问题来获得针对更敏感的属性的潜在值。例如,为了访问“社会能力”属性,可询问回答者角色是否有很多朋友,角色是否熟悉大众文化,以及角色是否能够适应正式以及非正式场合。
[0063]
例如,这些调查可以是审视每个回答者对角色的总体反应的标淮长度的调查或者采用诸如mechanical turk之类的服务的询问回答者单个分开的问题的小型调查。
[0064]
专家验证可被用来开发角色模型。诸如“代理”或“道德角色”之类的具体属性可受益于各种领域的专家的给料,包括媒体学习和心理学。对于这些属性,调查方法可组合来占据数据库的大部分,其中确保方法被用来占据的大部分的对随机选择的子集的专家验证遵循这些领域的最佳实践。
[0065]
用户反馈可被用来开发角色模型。用户对角色的响应可被汇集并被用来反馈至角色模型的数据库。例如,当消费者经由社交网络赞同与朋友分享或观看媒体内容中的给定
角色时,促使消费者提供为什么他们喜欢、分享或观看该特定角色或媒体内容的反馈。
[0066]
角色偏好函数
[0067]
因此,用于确定距离的所述技术还没有从消费者的角度在各种角色属性的重要性之间做出区分。更精确地,已经定义可应用至任意角色的单个距离函数。通过考虑消费者是否更关心沿角色模型的一些维的相似性(相对于角色模型的其它维),可以精炼这些搜索技术。关于消费者的该偏好信息被捕获在角色偏好函数中而且被用于确定偏好和角色之间的距离。
[0068]
不同消费者可具有不同角色偏好函数,它们中的每一个都基于相关的消费者的偏好。例如,杰西卡作为开电视的人,可能仅仅关心角色的性别以及角色的吸引力。具体地,她喜欢具有吸引力的角色以及女性角色。可以直接或者间接收集这些偏好。例如,用户可直接输入他们的偏好或者通过识别用户喜欢哪个角色来学习用户的偏好。如上文间接提到的那样,可在一系列针对每个属性的“权值”βi中对这些用户专用偏好进行编码。在此,杰西卡的角色偏好函数被表示为:
[0069]
f(jessica)=β1·
c1 0
·
c2 β3·
c3 0
·
c4[0070]
其中β2,β3都大于0。在该示例中,第二和第四属性上的系数(即,c2科学家属性的系数以及c4友好度属性的系数)为0,因为杰西卡不关心它们,而且她喜欢的属性上的系数(即,c1性别属性的β1系数和c3吸引力属性的β3系数)是正数。如果杰西卡更喜欢男性角色而不是女性角色,性别属性的β1系数会是负数。这些系数可被称为消费者的偏好系数,而且它们关联着角色模型的所有或者一些值。偏好系数可以是整数或者实数。负面偏好(例如,对于属性是不喜欢的)也可并入偏好函数。本领域普通技术人员将理解的是,系数具有参数类型,而且对于其他函数形式更一般的参数可采用来取代系数。
[0071]
在另一示例中,乔治作为另一个作为开电视的人,仅仅对角色的科学家维感兴趣。乔治喜欢科学家而不管他们的其它属性。乔治的角色偏好函数显然比杰西卡的角色偏好函数简单地多,因为乔治仅仅关心一个维度—科学家维。因此,所有其它维的系数或权值为0。乔治的角色偏好函数被简化为:
[0072]
f(george)=β2·
c2[0073]
其中β2大于0。杰西卡的和乔治的偏好在他们的角色偏好函数中被捕获。这些角色偏好函数可被用来推荐角色以及确定角色之间的距离,其中推荐和距离对于与角色偏好函数关联的消费者都是个别地加以考虑的。
[0074]
如上所述,系统可基于角色偏好函数来推荐角色。采用杰西卡的角色偏好函数和图1所示的角色模型,系统将把潘妮106和伯纳黛特112的等级定地很高。该系统将推荐潘妮106和伯纳黛特112给杰西卡,因为根据潘妮的角色模型120、伯纳黛特的角色模型126和杰西卡的角色偏好函数的组合,潘妮106和伯纳黛特112的等级被定地很高。可利用消费者的角色偏好函数来计算被推荐为等级的推荐值:
[0075][0076]
其中β表示消费者沿n属性的偏好系数,而且c表示角色沿相同n属性的的属性,例如来自角色模型。可针对不同角色多次计算该角色偏好函数以针对特定消费者确定之间的距离。
[0077]
根据乔治的角色偏好函数和图1所示的角色模型,系统将都是科学家的所有角色进行同等定级并且将他们推荐给乔治。类似的等式可被用来针对乔治计算推荐值。
[0078]
除了捕获了消费者喜欢或不喜欢什么的信息,角色偏好函数还可表示不同或附加信息。例如,杰西卡的角色偏好函数可表示杰西卡喜欢什么、杰西卡过去看过什么类型的角色或内容、杰西卡对什么类型的角色或内容提供过反馈、反馈是正面的还是负面的、以及这些元素中的一个或多个的组合等。
[0079]
系统还可通过使用角色偏好函数以及角色模型的组合来确定角色之间的距离。例如,根据上述杰西卡的角色偏好函数以及图1所示的角色模型,系统将会把潘妮和伯纳黛特识别为具有相对低的距离,因为潘妮和伯纳黛特具有相同性别(女性)和吸引力(很有吸引力)。回想性别和吸引力是杰西卡的角色偏好函数中关联的两个维度。如果性别和吸引力是与杰西卡的角色偏好函数有关的唯一的一些维度,潘妮和伯纳黛特之间的距离为0。类似地,系统将确定霍华德和潘妮具有相对大的距离,因为霍华德和潘妮在性别和吸引力方面都不同。具体地,霍华德不具有吸引力而且是男性,而潘妮很具有吸引力而且是女性。再次,回想杰西卡的角色偏好函数强调了性别和吸引力维。因此,霍华德和潘妮可被系统看作是相对于杰西卡的角色偏好函数是相反的,因为霍华德和潘妮在性别和吸引力方面都不同。
[0080]
角色偏好函数的第二阶项
[0081]
在一些情况下,可使用第二阶或更高项来计算基于角色模型和角色偏好函数的角色之间的距离。例如,消费者可能喜欢男性科学家但是可能不喜欢女性科学家。类似地,消费者可能喜欢很有吸引力的女性以及很有吸引力的科学家。为了在这些组合之间做出区分,第二阶或更高偏好需要被捕获在角色偏好函数中。对于第二阶项,注意,例如,针对很有吸引力的女性角色(第二阶)的偏好不同于针对很有吸引力的角色(第一阶)和女性角色(第一阶)的偏好。
[0082]
在一个示例中,名叫布赖恩的消费者喜欢女性科学家角色(第二阶)一级很有吸引力的角色(第一阶)以及友好的角色(第一阶)。注意,针对女性科学家的偏好不同于针对女性角色以及作为科学家的角色的偏好。布赖恩的角色偏好为:
[0083]
f(c)=β1·
c1 β2·
c2 β3·
c3 β4·
c4 γ
1,2
·
c1·
c2 γ
3,4
·
c3·
c4[0084]
其中β1,β2,β3,β4,γ
1,2
,γ
3,4
>0。正系数γ
1,2
,γ
3,4
捕获的第二阶项提供了针对布赖恩的偏好的对于角色推荐和角色之间的距离的更精确的度量。为了清楚表示,利用注释将布赖恩的角色偏好描述为如下:
[0085]
f(c)=β1·
c1[gender] β2·
c2[scientist] β3·
c3[attractiveness] β4·
c4[friendliness] γ
1,2
·
c1[gender]
·
c2[scientist] γ
3,4
·
c3[attractiveness]
·
c4[friendliness]
[0086]
偏好的第二阶被捕获在布赖恩的角色偏好函数中以提供针对布赖恩的偏好的对于角色推荐和角色之间的距离的更精确的度量。
[0087]
具体地,布赖恩的角色偏好函数显示布赖恩喜欢女性科学家。采用权值的矢量以及针对第二阶项γ的权值的矩阵将其存储在布赖恩的角色偏好函数中。因此,在采用布赖恩的角色偏好函数计算推荐和距离时,系统可考虑布赖恩的第二阶偏好。在关于布赖恩的角色偏好函数的这个示例中,第一角色a和第二角色b之间的距离d被确定为如下:
[0088][0089]
本领域技术人员将很容易理解的是,其它技术可被用来表示角色偏好函数。
[0090]
偏好模型
[0091]
可采用来自多个角色偏好函数的数据并结合与角色偏好函数关联的用户的相关已知属性来开发偏好模型。用户的数据库被汇集,将用户与一个或多个属性以及它们的角色偏好函数关联起来。采用该数据库,可针对个人或一群人来确定偏好模型。
[0092]
例如,假设75%的用户是女性而且具有科学、技术、工程或数学(stem)领域的文凭,而且她们具有表示她们喜欢观看媒体中的女性科学家的用户配置文件。这强烈地表示具有stem领域的文凭的其它女性也会喜欢观看媒体中的女性科学家。因此,当提供她们的性别为女性而且具有与stem相关的教育背景的新用户加入系统,系统可预测新用户将会喜欢观看女性科学家,而无需要求直接来自新用户的关于她的观看偏好的反馈。由此,系统可采用上述技术利用新用户喜欢女性科学家的预测来推荐媒体。
[0093]
类似地,多个角色偏好函数可被用来预测特定人口统计会喜欢什么特征。例如,如果正在进行群体观看(例如在电影院),关于组员的属性的统计可被预先采集。与群体的属性有关的统计可被用来识别该群体很可能喜欢的角色的类型。采用上述技术,可以识别出该群组很可能喜欢的媒体。偏好模型还可扩展涵盖媒体至任意类型的角色。
[0094]
涵盖依赖于人口统计信息,可按照大量不同方式来计算用户专用偏好函数:1)直接引导:询问用户他们对特定角色、角色属性或属性组合的偏好。2)从喜爱的角色和节目进行推断。例如,给定用户喜欢的一组角色以及用户不喜欢的一组角色,通过假设用户“喜欢”角色的可能性是用户的角色偏好函数的s型函数(例如,),可以估计出偏好权值。通过找出使得用户喜欢以及不喜欢这些角色组的联合概率最大的系数β、γ,系统能计算出用户的角色偏好函数。3)根据生理记录进行推断:在没有消费者直接报告关于他们的角色偏好的情况下,视线追踪、面部反应、姿态映射或者任意数量的其它类型的生理记录可被用来检测哪个角色要求消费者的最多注意力,以及该注意力是正面的还是负面的。给定对角色的这些生理反应,可遵循与针对2)描述的方法类似的方法来推断偏好模型。偏好模型还可扩展涵盖媒体至任意类型的角色。
[0095]
内容推荐
[0096]
关于角色的信息可被用来确定评级以及媒体内容的推荐,而且用来确定媒体内容之间的距离。例如,喜欢很有吸引力的科学家的消费者很可能会喜欢采用多个作为很有吸引力的科学家的角色的节目。相同消费者很可能会不喜欢主要采用作为没有吸引力的非科学家的角色的节目。
[0097]
可采用针对媒体内容中的所有或者一些角色的消费者的偏好的突显性加权求和来对媒体内容进行评估。可通过多种方式来确定媒体内容中的角色的相对突显性。
[0098]
确定突显性的一种方法是使得突显性基于角色获得的在屏时间相对于所有角色的总在屏时间的百分比。简单举例来说,考虑包括医生、工程师和代理人作为角色的喜剧节目。医生的总在屏时间为1100秒,工程师的总在屏时间为1500秒,而且代理人的总在屏时间为仅仅600秒。采用该第一方法,角色(char)相对于所有角色(allchars)的突显性s可被计算为:
[0099][0100]
在医生、工程师和代理人的特定示例中,针对每个角色的突显性被计算如下:
[0101][0102][0103][0104]
确定突显性的另一种方法是使得突显性基于在社交媒体中针对角色检测到的互动数量。例如,twitter、facebook、google 、instagram以及其它社交联网网站可被监控来追踪角色的名字呗提及的次数、角色的图像被公开的次数、角色的引用被确认的次数(例如,facebook上喜欢角色的粉丝专页)等。采用该方法,媒体内容中的一个角色引发互动的次数相对于媒体内容中的所有角色引发互动的次数的对比来确定角色的相对突显性。例如,该计算可如下执行:
[0105][0106]
确定突显性的另一种方法是考虑角色在互联网上总体的流行程度。可通过多种方式来确定流行程度。一种方法是识别在可靠搜索引擎上搜素角色名字所返回的搜索结果的数量。例如,在google中搜索“比尔
·
克林顿”会返回大约40400000个结果。在google中搜索“小布什”会返回大约95800000个结果。因此,角色小布什相对于角色比尔
·
克林顿更突显。采用该方法,角色在互联网上总体的流行程度可被用来以与针对角色的在屏分钟数的方式类似的方式计算突显性,如上所述。
[0107]
用于搜集总体的或者指定用户的角色突显性的另一方法是采用对角色的生理反应。例如,视线追踪数据可被用来评估观看者平均地花费在看谢尔登、莱纳德和潘妮上的时间多于生活大爆炸的任意其它角色,从而赋予这些角色在人群中的特别高的突显性。可替换地,或者此外地,系统可计算特定用户,杰西卡,将她的大部分时间花在观看潘妮上,表明对于她来说潘妮是最突显的角色。用于搜集指定用户的突显性的另一方法是分析用户在社交网络上响应于观看该节目而做出的行为。
[0108]
本领域技术人员可以容易地理解,上述突显性技术不是必须考虑媒体内容的所有角色。例如,最小阈值可被设置以使得在突显性计算中不考虑不突出的角色(例如,接收很少在屏时间的角色,引发很少社交媒体互动的角色,在互联网上的流行程度很低的角色等)。可替换地,或者此外地,最大阈值也可被设置以使得在突显性计算时特定媒体内容中的非常流行的角色不会使其它角色相形见绌。
[0109]
消费者的偏好、角色的属性和角色的突显性被考虑来针对媒体内容计算评级。该评级可随后被用来对各种媒体内容分级以及向消费者推荐媒体内容。考虑更喜欢观看电视节目中的女性的名为史蒂文的消费者。史蒂文已经表明,或者已经从他的展现的偏好推断
出,他特别喜欢看女性科学家而且他更喜欢电视节目中的在他看来具有吸引力的科学家。系统针对史蒂文的偏好计算每个角色的角色偏好函数以考虑这些属性。角色偏好函数表示角色的消费者的评级。为了计算角色偏好函数,角色的突显性被使用。在该情况下,针对图1中识别的角色,每个角色的突显性被预先计算并在下面的表1中识别出来。在该情况下,利用节目生活大爆炸的特定剧集,基于每个角色的在屏时间计算突显值。如上所述,可以使用其它方法。此外,该计算可以基于媒体内容的单个场景、媒体内容的单个剧集、媒体内容的单季或者媒体内容的所有可用节目。
[0110]
角色突显性谢尔登0.2莱纳德0.2潘妮0.2霍华德0.15拉杰0.15伯纳黛特0.05艾米0.05
[0111]
表1-示例的突显值
[0112]
使得表示n个不同维上的角色clar的属性值。下述角色偏好函数被用来计算针对每个角色的评级:
[0113][0114]
此外,更高阶项也可被包含。例如,角色偏好函数可被扩展成:
[0115][0116]
针对每个用户单独地确定系数β以允许个性化的推荐。对于史蒂文表示的偏好,下述角色偏好函数被用来计算针对每个角色的评级:
[0117]
f(char)=gender (gender*scientist) (attractiveness*scientist)
[0118]
采用图1的角色模型和史蒂文的角色偏好函数,针对史蒂文,图1所示的角色的评级s被计算如下:
[0119]
f(sheldon)=-1 (-1
×
1) (-1
×
1)=-3
[0120]
f(leonard)=-1 (-1
×
1) (0
×
1)=-2
[0121]
f(penny)=1 (1
×‑
1) (1
×‑
1)=-1
[0122]
f(howard)=-1 (-1
×
1) (-1
×
1)=-3
[0123]
f(rajesh)=-1 (-1
×
1) (0
×
1)=-1
[0124]
f(bernadette)=1 (1
×
1) (1
×
1)=3
[0125]
f(amy)=1 (1
×
1) (-1
×
1)=1
[0126]
这些计算的角色评级对于针对生活大爆炸的特定剧集识别的角色是有效的。计算
的角色评级以及它们相应的突显值可被用来计算针对生活大爆炸识别的该特定剧集的节目评级。通过求取每个角色的突显性和评级的乘积之和来执行节目评级的计算。利用突显性矢量和角色评级矢量剧集评级r被计算为:
[0127][0128]
在史蒂文的具体示例中,相对于图1所示的角色,生活大爆炸(tbbt)剧集的评级r被计算为:
[0129]
r(tbbt)=(0.2
×‑
3) (0.2
×‑
2) (0.2
×‑
1) (0.15
×‑
3) (0.1s
×‑
1) (0.05
×
3) (0.05
×
1)=-1.6
[0130]
因此,消费者史蒂文对于生活大爆炸的该特定剧集的评级是-1.6。对于推荐,该评级值与类似地针对其他节目计算的评级值进行比较。根据评级值来准备定级。例如,具有最高评级值的媒体内容将被定级为最高,同时具有最低评级值的媒体内容将被定级为最低。最高定级的节目被推荐给消费者,因为这些高度定级的节目表示消费者很可能感兴趣或很可能喜欢的节目。本领域普通技术人员将理解的是,系数具有参数类型,而且用于其他函数形式的更加一般化的参数可被采用来取代系数。
[0131]
系统集成
[0132]
上述技术可被分别或组合地使用以产生一个强大的系统来根据消费者偏好发现和组织角色和媒体内容。
[0133]
图2图示出组合技术的示例框图,用于执行角色和媒体内容的发现和组织。在块202,系统访问来自用户的反馈。该反馈被用来确定用户的偏好以及开发角色偏好函数。反馈可能是明确的,例如通过直接的问题。反馈可能是不明确的,例如通过分析用户点击、观看、评论或分享的网站等。反馈可能是生理学的,例如视线追踪、皮肤电反应、脑电图、面部表情跟踪、姿态映射等。角色偏好函数被存储在数据库中并且与从其接收到反馈的用户关联。
[0134]
在块204,角色模型中将要包含的属性被确定。描述了多个示例。角色的外表属性可被追踪,例如性别、年纪等。人格属性可被追踪,例如亲和力、幽默感、残忍等。社会属性或地位可被追踪,例如关系(父母/祖父母),社区领导、职业等。附加属性可被追踪,例如种族、社会经济阶层等。
[0135]
在块206,从数据源提取角色以及他们的属性的相关数据。可以从诸如维基百科、粉丝专页、社交网络(例如facebook和twitter)之类的网站的文本、调查、专家验证和其它源提取数据。
[0136]
在块208,执行角色分解。从数据源提取的数据被用来针对角色模型数据库中的角色对在块204中识别出来的每个属性进行赋值。例如,上述各种技术可被用来为每个角色的角色模型赋值。
[0137]
在块210,用户偏好模型和角色模型被访问以在角色模型的角色属性上确定用户偏好。偏好数据被用来发现用户可能喜欢的新角色或新节目。偏好数据还可被用来根据用户的偏好组织角色或节目,例如识别哪些角色相似或者不相似。由此,系统能够有效并且可靠地推荐角色和媒体内容给用户。
[0138]
图3图示出用于推荐媒体的示例处理。在块302,推荐系统访问一组突显值。该组突
显值与媒体内容关联。每个突显值与来自媒体内容的一个角色关联。突显值表示了角色对于节目的感觉或定调有多重要。角色的突显值越高,角色越重要。在块304,系统访问角色偏好函数。角色偏好函数与系统用户关联。角色偏好函数包括识别多个偏好系数的信息。多个偏好系数中的每个偏好系数与从多个属性选择的至少一个关注属性关联。例如,偏好函数可表示用户具有与“性别”关注属性关联的偏好系数1以及与“科学家”关注属性关联的偏好系数1。
[0139]
在块306,系统访问第一角色模型。第一角色模型与来自媒体内容的第一角色关联。第一角色模型包括识别第一属性值组的信息。属性值与第一角色的属性匹配。属性可以与其中角色偏好函数包括偏好系数的属性相同。第一角色还与来自该组突显值的第一突显值关联。在计算媒体内容的评级时第一突显值将被用来确定第一角色具有多大的影响。
[0140]
在块308,系统访问第二角色模型。第二角色模型与来自媒体内容的第二角色关联。第二角色模型包括识别第二属性值组的信息。属性值与第二角色的属性匹配。属性可以与其中角色偏好函数包括偏好系数的属性相同。第二角色还与来自该组突显值的第二突显值关联。在计算媒体内容的评级时第二突显值将被用来确定第二角色具有多大的影响。
[0141]
在块310,系统通过执行多个偏好系数与第一属性值组的乘积的求和来计算第一角色的第一角色评级。例如,系统将使得针对性别的偏好系数乘以针对性别的第一角色的属性值。系统还将使得针对科学家的偏好系数乘以针对科学家的第一角色的属性值。针对性别和科学家的这两个乘积随后被加在一起。第一角色的第一角色评级基于该和值。
[0142]
在块312,系统类似地通过执行多个偏好系数与第二属性值组的乘积的求和来计算第二角色的第二角色评级。例如,系统将使得针对性别的偏好系数乘以针对性别的第二角色的属性值。系统还将使得针对科学家的偏好系数乘以针对科学家的第二角色的属性值。针对性别和科学家的这两个乘积随后被加在一起。第二角色的第二角色评级基于该和值。
[0143]
在块314,系统计算媒体内容评级。媒体内容评级是根据第一突显值、第二突显值、第一角色评级和第二角色评级计算的。突显值被用来对每个角色评级对媒体内容评级的影响进行加权。
[0144]
在块316,系统根据媒体内容评级向用户推荐媒体内容。推荐可能简单地提供媒体内容的标题,提供媒体内容的链接,显示媒体内容等。例如,媒体内容可能是系统已经确定用户会喜欢、连接或同情的广告。在其它示例中,媒体内容可以是一篇现成的文章、游戏、移动应用或计算机应用等。
[0145]
总体上,图3的块可按照各种顺序执行,而且在一些情况下可部分地或者完全地并行执行。此外,不是必须执行所有块。例如,该组突显值不是必须在访问第一和第二角色模型之前被访问。
[0146]
图4图示出用于推荐媒体的示例处理。在块402,推荐系统计算一组突显值的第一突显值。第一突显值与媒体内容的多个角色的第一角色关联。根据第一角色在媒体内容中的在屏时间来计算第一突显值。更具体地,系统确定或访问总在屏时间值。例如,总在屏时间值可以是媒体内容的所有(或选择的)角色花在屏幕上的时间之和。系统还确定或访问第一角色的在屏时间。通过使得第一角色的在屏时间除以总在屏时间值来计算第一突显值。
[0147]
在块404,系统计算该组突显值的第二突显值。第二突显值与媒体内容的多个角色
的第二角色关联。根据媒体内容中的第二角色的在屏时间来计算第二突显值。更具体地,系统确定或访问第二角色的在屏时间。通过使得第二角色的在屏时间除以总在屏时间值来计算第二突显值。
[0148]
该组的突显值与媒体内容关联。每个突显值与来自媒体内容的一个角色关联。突显值表示了角色对于节目的感觉或定调有多重要。角色的突显值越高,角色越重要。
[0149]
在块406,系统访问角色偏好函数。角色偏好函数与系统的用户关联。角色偏好函数包括识别多个偏好系数的信息。多个偏好系数中的偏好系数的每一个都与从多个属性选择的至少一个关注属性关联。例如,偏好函数可表示用户具有与“女性科学家”关注属性关联的偏好系数0.8、与“女性”关注属性关联的偏好系数1、以及与“科学家”关注属性关联的偏好系数1。
[0150]
角色偏好函数是二阶函数。二阶函数具有第一阶项和第二阶项。角色偏好函数将多个偏好系数的至少一个关联至多个属性的两个或更多关注属性。在该示例中,角色偏好函数将偏好系数0.8关联至“女性科学家”的关注属性。
[0151]
在块408,系统确定第一角色模型。第一角色模型与来自媒体内容的第一角色关联。第一角色模型包括识别第一属性值组的信息。属性值与第一角色的属性相匹配。与属性值关联的属性可以与其中角色偏好函数包括偏好系数的属性相同。
[0152]
通过在诸如网站、电子书、电子报纸杂志、社交媒体等的电子源中识别与第一角色关联的文本内容来确定第一角色模型。系统汇集了与来自文本内容的第一角色关联的多个属性项。例如,系统可汇集诸如“可爱”、“聪明”、“合群的”等的项。系统将多个属性项的至少一些映射至多个属性的至少一些。该映射允许识别汇集的项(例如“可爱”)与被追踪的角色的属性(例如“很有吸引力”)之间的关系。系统根据多个属性项更新第一角色的属性值。
[0153]
在块410,系统计算第一角色的第一角色评级。系统结合第一角色模型将角色偏好函数的第一阶项和第二阶项进行相加。对于第一阶项,系统计算作为第一阶的多个偏好系数与第一属性值组的乘积。在该示例中,系统使得与“科学家”关联的偏好系数1与针对“科学家”的第一角色模型的属性值相乘。类似地,系统将与“女性”关联的偏好系数1与针对“女性”的第一角色模型的属性值进行相乘。对于第二项,系统确定多个偏好系数的至少一个与多个属性的两个或更多关注属性的第一属性值组的每个属性值的乘积。换言之,系统计算作为第二阶的多个偏好系数与第一属性值组的乘积。在该示例中,系统将与“女性科学家”关联的偏好系数0.8与针对“女性”的第一角色模型的属性值进行相乘而且与针对“科学家”的第一角色模型的属性值进行相乘。第一阶项和第二阶项随后相加以产生第一角色评级。
[0154]
属性项中的每一个可与强度值关联。这有助于在强项与较不强的项之间进行区分。例如,强项可表示一个角色是“相当友好的”。较不强的项可表示角色是“有时候友好的”。系统随后根据属性项的相应强度值更新第一角色的属性值。在该示例中,“相当友好的”可能关联至针对友好属性的1.5,而“有时候友好的”关联至针对友好属性的0.75。在一个示例中,系统在数据库中将第一角色的更新的属性值存储为矢量,该矢量与第一角色关联。
[0155]
在块412,系统确定第二角色模型。第二角色模型与来自媒体内容的第二角色相关。第二角色模型包括识别第二属性值组的信息。属性值与第二角色的属性相匹配。与属性值关联的属性可以与其中角色偏好函数包括偏好系数的属性相同。
[0156]
按照以上针对第一角色模型的方式类似的方式确定第二角色模型。部分地通过识别与电子源中的第二角色关联的文本内容来确定第二角色模型。系统汇集了与来自文本内容的第二角色关联的多个属性项。系统将多个属性项的至少一些映射至多个属性的至少一些。系统根据属性项的多个属性项和相应强度值来更新第一角色的属性值。在一个示例中,系统在数据库中将第二角色的更新的属性值存储为矢量,该矢量与第二角色关联。
[0157]
在块414,系统计算第二角色的第二角色评级。按照与第一角色评级类似的方式计算第二角色评级。然而,第二角色模型和第二角色属性值被使用。在块416,系统按照与针对第一角色的计算类似的方式计算第二角色的第二角色评级。
[0158]
在块416,系统计算媒体内容评级。媒体内容评级是根据第一突显值、第二突显值、第一角色评级和第二角色评级计算的。突显值被用来对每个角色评级对媒体内容评级的影响进行加权。
[0159]
在块418,系统访问最下的内容评级值。在块420,系统比较媒体内容评级和最小内容评级值。媒体内容评级是用数字表示的,最小内容评级值是用数字表示的。如果媒体内容评级大于最小内容评级值,系统移动至块422。否则,处理在块424结束。
[0160]
在块422,系统根据媒体内容评级向用户推荐媒体内容。推荐可能简单地提供媒体内容的标题,提供媒体内容的链接,显示媒体内容等。例如,媒体内容可能是系统已经确定用户会喜欢、连接或同情的广告。在其它示例中,媒体内容可以是一篇现成的文章、游戏、移动应用或计算机应用等。
[0161]
总体上,图4的块可按照各种顺序执行,而且在一些情况下可部分地或者完全地并行执行。此外,不是必须执行所有块。例如,第一角色评级和第二角色评级可被并行计算。
[0162]
虽然参考向用户推荐媒体来描述了图4和图5,上述技术可应用于各种其他系统。在一个示例中,系统可被用来提供接口给滤波器以及根据角色分解提供精确信息。更具体地,系统可被用来:针对项目列表改变排序,控制电视其它查看系统的查看能力,建议购买内容,推荐视频游戏或防止访问视频游戏,过滤内容以防止儿童查看具有负面消息的内容,对儿童正在观看的东西进行特征化,或者找出父母的期望和小孩的观看偏好的交集。
[0163]
在另一示例中,系统可根据角色分解向内容制造者提供信息以便理解观众偏好。更具体地,系统可被用来:根据汇集的用户需求或偏好对内容制造者汇集创建什么类型的角色的洞察力,或者识别最可能与特定目标用户组产生共情的角色的特征/属性以实现角色/名流与目标观众的映射。
[0164]
在另一示例中,系统可提供基于互补的同步的角色的浏览及信息发现。更具体地,系统可被用来提供第二屏幕经验,提升具有同步推荐的媒体观看体验,并且根据节目中出现的角色来提供内置广告。
[0165]
在又另一示例中,系统可用于用户产生的角色创作。用户可根据用户喜好的特征来创建他们自己的角色。这允许根据用户(或多个用户)取值最大的属性搜集对角色开发进行通知的用户产生的信号和数据。这还产生对用户偏好以及对特定类型的角色的潜在需求的洞察力而且明确地为内容提供者通知并指示新角色开发。
[0166]
图5描绘了配置用来实施上述步骤任意一个的示范性计算系统500。在本文中,计算系统500可包括,例如,处理器,存储器,储存器和输入/输出装置(如监视器,键盘,触摸屏,磁盘驱动,互联网连接等)。然而,计算系统500可包括电路或其他专用硬件用于实施这
些步骤的一些或所有部分。在一些可操作设置中,计算系统500可被配置为包括一个或多个单元的系统,其每一个配置用来以软件,硬件或其一些组合形式实施这些步骤的一些部分。
[0167]
图5描绘了具有多个可用来实施上述步骤的组件的计算系统500。主系统502包括母板504,具有输入/输出(“i/o”)部件506、一个或多个中央处理单元(“cpu”)508和存储部件510,其可能具有与其相关的闪存卡512。该i/o部件506连接显示器524、键盘514、磁盘存储器单元516、媒体驱动器单元518。该媒体驱动器单元518能够读/写计算机可读介质520,其能够包含程序522和/或数据。i/o部件506还可例如利用蜂窝数据连接或无线局域网通信连接至云存储。
[0168]
能够保存基于上述处理结果的至少一些值用于后续使用。或者,计算机可读介质能够用来存储(如,切实体现)用来通过计算机方式实施上述处理的任意一个的一个或多个程序。可以写入计算机程序,例如采用通用编程语言(如pascal,c,c ,java)或一些特定应用的指定语言。
[0169]
虽然以上仅仅详细描述了具体示例性实施例,但是本领域技术人员可以容易地理解,在没有实质地脱离本发明的新颖指教和优势的情况下多个修改是可行的。例如,以上公开的实施例的方面可以在其它组合中进行组合以形成其它实施例。由此,所有这种修改均包含在本发明的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
