1.本发明属于计算机视觉技术领域,涉及一种利用对抗蒸馏实现的无数据细粒度分类模型 压缩系统及方法。
背景技术:
2.深度学习在各个领域中取得了令人瞩目的成就,但是目前的应用中,为了获得更好的表 现,模型的结构往往被设计的深且复杂。这样的模型很难应用于目前流行的嵌入式设备和移 动设备中。其次,随着安全隐私保护意识的逐渐增强,实际应用中的隐私数据(如医疗数据, 网购商品等),这些数据往往不对外开放。因此,模型压缩和隐私保护成为目前亟待解决课题。
3.知识蒸馏主要是将预训练的教师模型中的知识提出并蒸馏出潜在的暗知识,而后将其转 移给学生模型。这种方式能够提高学生模型的性能,同时是获得知识的学生模型可以代替教 师模型的部署。从而降低设备的部署的压力。其次,教师模型可以访问敏感的隐私数据并训 练模型,而学生模型无法访问这类数据。通过对抗生成网络生成替代样本可以辅助教师和学 生模型的训练并将教师模型的知识转移给学生模型,整个过程中学生模型不需要访问任何的 实际的样本。该方法不但能实现隐私保护还能很好的实现模型的压缩。
技术实现要素:
4.为了解决现有技术存在的不足,本发明的目的是提供一种利用对抗蒸馏实现的无数据细 粒度分类模型压缩方法。通过对抗蒸馏实现替代样本的合成,将教师和学生模型对样本的预 测转化为分类预测分布的拟合,并且通过差异度量使得学生模型能够学习教师模型的有效知 识。
5.本发明利用中间层结构化特征,将距离相似度和余弦相似度信息作为结构化知识,并将 这部分信息作为知识融入到教师模型的蒸馏过程中,以到达更好的学习效果。
6.本发明利用中间层特征进行对比学习,能够使得学生模型和教师模型相似样本之间的距 离更加接近,不相似的样本之间的距离更加远离,使得生成器能够生成多样性的样本表示。
7.本发明模型压缩系统的结构如图2,包括生成器、固定教师模型、学生模型;
8.所述生成器通过输入高斯噪声,在对抗蒸馏阶段中为教师模型和学生模型提供稳定的可 供调节的生成样本;
9.所述固定教师模型为经过预训练的模型;
10.所述学生模型是模型压缩知识蒸馏的目标和客体,用于压缩后代替教师模型进行部署和 推理。
11.所述固定教师模型通过在细粒度数据集上预训练获得,在对抗蒸馏过程中参数固定,通 过固定教师模型的输出层和中间层的输出为学生模型提供知识;
12.所述生成器包括gans系列模型,所述生成器的输入为随机分布的高斯噪声,输出作为 教师模型和学生模型的输入;
13.所述学生模型为结构相对简单的浅层模型,在对抗蒸馏过程中能进行参数更新,并从教 师模型的输出层和中间层输出中提取特征。
14.本发明提出了一种利用对抗蒸馏实现的无数据细粒度分类模型压缩方法,包括以下步骤:
15.第一步,利用相同的深层网络加载预训练时保存的模型参数作为教师模型,利用模型结 构较为简单的模型作为学生模型。
16.第二步,将随机分布的高斯噪声输入给生成器,生成器合成替代样本作为教师模型和学 生模型的输入。
17.第三步,教师模型和学生模型对生成器合成图像分别进行特征提取,并在各自的中间层 和输出层输出特征。
18.第四步,通过支持样本的决策分布差异度量使得学生模型能学习教师模型的分布并缩小 两者之间的差异。
19.第五步,利用中间层特征的距离相似性和角度相似性结构化信息进一步增强特征的表示。
20.第六步,利用教师和学生模型中间层特征进行对比学习以区分有效样本和无效样本;
21.第七步,通过最大-最小化训练进行对抗蒸馏,优化模型通过损失叠加最大最小化方式, 分别更新生成器模型和学生模型。
22.本发明中,细粒度样本是指包括但不限于动物相关数据(人类、鸟类、狗类等)、物品相 关数据(汽车、飞机,商品等)等,在实际应用中对应于大类中所包含的子类别数据。
23.所述第一步中,预训练教师模型是深层网络模型在细粒度数据集进行预训练,模型获得 了较为优秀的性能并保存模型的特征参数。深层网络加载预训练保存的模型参数作为教师模 型,而浅层模型为学生模型。
24.所述第二步中,随机高斯噪声z作为生成器g的输入,为生成器输出的合 成样本,分别输入教师模型t和学生模型s中。教师、学生模型以及生成器通过对抗蒸馏的 方式实现模型的训练,在迭代的过程中生成器合成的样本逐渐从噪声转化为风格化的样本。
25.所述第四步中,决策分布差异度量是指,教师模型和学生模型对样本的预测得到概率分 布,表示为s(g(z)),t(g(z)),这些概率分布中包含了隐空间的分类信息,通过对教师模型 分布信息学习并更新学生参数能够有效地学习教师模型中的分类参数。这里分布差异度量包 含了两种方式。其中一种如下,计算教师和学生输出分布之间的均方误差(mse)。
[0026][0027]
其中,n是一个batch中的样本的数量;z是输入噪声,服从高斯分布n(0,1);
[0028]
此外,差异性度量第二种是指分类预测的概率分布通过蒸馏能够显示其中的暗知识,这 一方法可以将这种差异放大,这里方法使用的是kl散度。损失计算公式如下:
[0029][0030]
其中,n是一个batch中的样本的数量;z是输入噪声,服从高斯分布n(0,1);σ是softmax函数。
[0031]
所述第五步中,中间层的距离相似度是指模型中间层的特征作为教师和学生的知识,传 统的独立对知识表达较为单一,基于特征构建特征之间关系可以进一步增强知识的表示。
[0032]
其中,距离相似度蒸馏是指基于特征构建特征之间的欧氏距离,对于输入的支持样本教师模型和学生模型分别从中抽取特征的表示结合为f
it
和f
is
,对于给定一个batch的样本得到的特征集合为和其中, |b|是样本的批大小batch size,和是教师模型和学生模型中样本的特征表示集合。从b 集合中任意采样一对样本距离相似性构建如下所示:
[0033][0034]
距离相似性蒸馏的通过如下公式表示:
[0035][0036]
其中,是具体的损失函数,本发明主要采用的是l1损失,用于学习两者之间的差异;i,j分别代表一个batch中的第i和第j个样本。
[0037]
其中,角度相似蒸馏是指基于特征构建特征之间的角度关系,从b集合中任意采样一个 三元组特征之间的结构关系可以通过角度相似性来衡量,如下式:
[0038][0039]
其中,是特征fj和fi之间的正则化向量,是特征fj,fi正则化 向量和fi,fk正则化向量之间的余弦相似性,φ(
·
)是损失函数,用于学习教师模型余弦相似性 和学生模型余弦相似性之间的差异,i,j,k分别代表集合b中的第i,第j和第k个样本。
[0040]
所述步骤六中,对比学习用于教师模型中间层输出特征,其功能在于能够拉近相似的样 本,推远不相似的样本,使得学生模型能够学习教师的模型中的有效样本,对比损失具体用 如下公式所示:
[0041]
[0042]
其中,τ是“温度”因子,用于调节相似度的大小。
[0043]
所述第七步中,对抗蒸馏是将生成器和教师-学生模型通过最大-最小化训练使得噪声样本 和实际样本的分布的差异最小化,同时最小化教师和学生模型之间的差异,并在训练的过程 中实现模型知识的迁移,公式如下:
[0044][0045]
如上公式最小化过程中,主要用于更新学生模型min
s e
z~n(0,1)
[d
*
(g(z))],生成器合成样 本教师和学生模型共同判别合成样本其中判别的方法为如上步 骤四、五、六中所述的方法。
[0046]
如上公式最大化过程主要更新生成器模型max
gez~n(0,1)
[d
*
(g(z))],其等价于最小化过程 的min
gez~n(0,1)
[-d
*
(g(z))],通过生成器合成样本教师和学生模型共同判别合成样 本其中判别的方法为如上步骤四、五、六中所述的方法。
[0047]
上述最大化和最小化过程的目标函数如下,对于学生模型使用随机梯度下降(sgd)来优 化,对于生成器模型使用adam优化:
[0048]
最小化的过程:
[0049]
min
s l
bf
αl
rd
β(l
dsd
l
asd
) μl
cl
,
[0050]
其中,α,β和μ为权重因子,用于平衡损失;
[0051]
最大化的过程:
[0052]
min
g-[l
bf
αl
rd
β(l
dsd
l
asd
) μl
cl
],
[0053]
其中,α,β和μ为权重因子,用于平衡损失。
[0054]
与现有技术相比,本发明的有益效果包括:本发明主要面向细粒度图像分类的隐私保护 和模型压缩;通过相对差异度量能有效提升学生模型识别的准确率,以及细粒度伪样本的生 成;在中间层特征基础之上构建结构化知识能够关注到特征区域上下文之间的关系进一步提 升模型的知识表示。对比学习,能够有效区分有效样本和无效样本提高模型的学习效果。
附图说明
[0055]
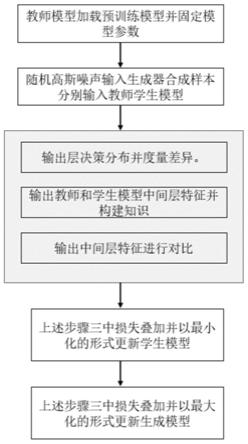
图1为本发明实施的具体流程。
[0056]
图2为本发明实例中对抗蒸馏的模型架构图。
具体实施方式
[0057]
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、 实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公知常识,本发明没有 特别限制内容。
[0058]
本发明提供的无数据细粒度对抗蒸馏方法,如图1所示,该方法包括以下步骤:
[0059]
第一步,加载预训练教师模型。教师模型的结构通常较深,并且已经在数据集上训练完 善,需要相同的深层网络预先加载模型参数作为教师模型。
[0060]
第二步,选择与教师模型相适配的生成器模型和学生模型。服从高斯分布的随机噪声作 为输入,选择浅层的同构或者异构网络作为学生模型。
[0061]
第三步,通过支持样本的决策分布差异度量使得学生模型能学习教师模型的分布并缩小 两者之间的差异。
[0062]
第四步,在教师和学生模型中间层特征和输出层分布上构建知识。在教师模型和学生模 型的中间层和输出层的特征之上分别构建知识。主要知识表现形式有中间层特征的结构知识 表示,包括但不限于距离和角度。输出层知识包括支持决策样本输出分布的相对差异度量。
[0063]
第五步,在教师模型中间层输出的特征进行对比学习,使得教师模型能够有效拉近与教 师相似样本之间的距离和推远与学生不相似样本之间的距离。
[0064]
第六步,最小化损失并更新学生模型。将上述第三步中的知识形式的损失相结合。以最 小化的形式更新学生模型,使得学生模型的能够进一步学习教师模型。
[0065]
第七步,最大化损失更新生成器模型。将上述第三步中的知识形式的损失相结合。以最 大化的形式更新生成器模型,使得生成器能够进一步生成多样性的伪造样本。
[0066]
本实施例的具体流程以具体模型和方法为例,如图1所示。
[0067]
所述流程中的第一步,如利用深度学习模型resnet34加载训练完善后保存模型的参数;
[0068]
所述流程中的第二步,在对抗蒸馏过程中,选取resnet18作为学生模型,dcgan作为 生成器。输入生成器的噪声符合高斯分布。
[0069]
所述流程中的第四步,在教师模型和学生模型的输出层和中间层提取知识。在输出层, 教师和学生模型的输出分布通过拟合损失函数(mse)来拟合教师模型的输出,同时通过kl散 度学习学生模型和教师模型分布之间的相对差异;接着在教师模型和学生模型的中间层特征 之上构建距离相似度信息和角度相似度信息,其中距离相似度信息主要是计算一个batch中 各个样本之间的欧氏距离。角度相似性信息主要计算一个batch中的各个样本之间的余弦相 似度信息。
[0070]
所述流程中的第五步,通过对比学习来使得拉近batch中的教师模型和学生模型之中相 似样本之间的距离和推远不相似样本之间的距离,并通过温度参数来调节之间的距离。
[0071]
所述流程中的第六步,最小化教师和学生模型的之间差异的损失来更新学生模型,确保 学生模型能够更好的学习教师模型。
[0072]
所述流程中的第七步,最大化教师和学生模型之间差异的损失来更新生成器模型,确保 生成器能够生成多样性的表示。
[0073]
训练过程中,模型主要参数有α、β、μ、τ。训练损失在一定范围,例如0.4
±
0.01,准 确率逐渐收敛,结束网络的训练。
[0074]
本发明方法还可以适用于其他细粒度分类任务,具体过程不再详细说明。
[0075]
本发明上述说明中的参数是根据实验结果确定的,即测试不同的参数组合,选取准确率 较优的一组参数。在实际以上的测试中,可根据需求对上述参数进行适当调整也可实现本发 明的目的。
[0076]
本发明能够在细粒度数场景下有效提高模型的实验效果。如下表1是在相关的细
粒度数 据集上实施的实验结果如下:
[0077]
表1.本发明在aircraft,standford cars和cub-200-2011细粒度数据集上的实验效果
[0078][0079]
如上表1,本发明能够在基准的细粒度数据集上取得良好的效果,相对于教师模型的恢 复率分别为94.6%,85.3%,96.1%。这能够超越绝大部分之前的方法,超越最优的算法5个 百分点,说明了该发明在细粒度样本的上的有效性。
[0080]
本发明还能在一般的数据集上取得良好的效果,如下表2在通用数据集cifar上的实验 结果比较。
[0081]
表2.本发明在cifar-10和cifar-100数据集上的实验效果
[0082][0083]
该发明在通用分类任务上也具有很好的泛化性,能够在取得良好的分类效果。在 cifar-10数据集上能取得94.32%的效果,能够提高近1百分点,在cifar-100数据集上也 能取得75.59%的效果,能够提高近6个百分点,进一步证明了该发明的有效性。
[0084]
本发明的保护内容不局限于以上实施例。在不背离本发明构思的精神和范围下,本领域 技术人员能够想到的变化和优点都被包括在本发明中,并且以所附的权利要求书为保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。