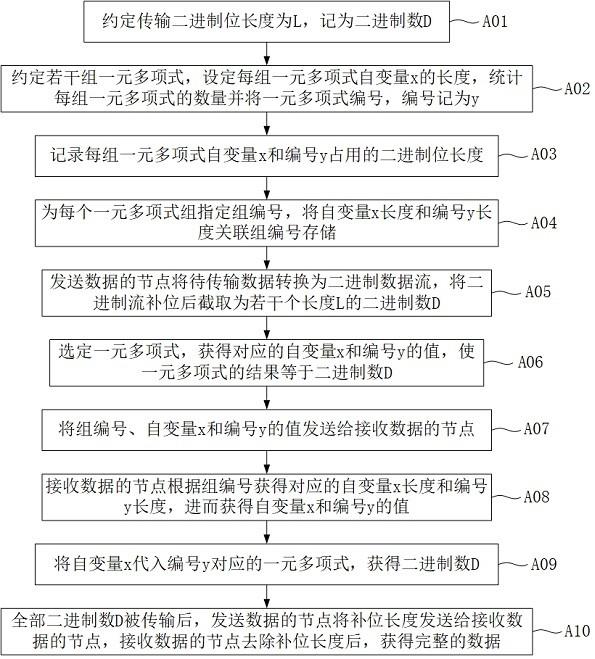
1.本发明属于计算机视觉领域中的视频目标检测(video object detection)领域,尤其涉及图像分类、目标检测和神经网络量化加速技术,具体为一种基于卷积神经网络的无人机场景视频目标检测方法。
背景技术:
2.随着低成本商用无人机的快速发展,无人机场景上的视频监控也越来越受到关注。一些研究已经从不同方面解决了这个问题。然而,在嵌入式平台上所做的尝试却很少。这项工作主要是为了在nvdia jetson tx2平台上开发一种有效和高效的基于无人机的行人检测算法框架。
3.现有的检测器大致可以分为两阶段(例如,faster-rcnn)和单阶段(例如, yolo和ssd)检测器。两阶段检测器首先生成区域建议框(proposals),并使用子网络来分类并修正区域建议框;而单阶段检测器直接给出检测器的最终结果,不需要生成区域建议框。一般来说,单阶段检测器的速度更快,而两阶段检测器的精度更高。考虑到嵌入式平台的计算能力,我们选择了基于mobilenet 的ssd检测器作为我们的基础模型。
4.在无人机场景中,图像分辨率通常很高,但视野中的人物相对较小。因此,如何平衡算法的速度与准确性是一项艰巨的任务。如果直接将检测器应用在高分辨率的图像上,对于嵌入式平台来说,计算成本将是巨大的。但如果我们直接将图像调整为低分辨率,由于外观信息非常有限,一些目标将无法被识别。在我们的观察中,相机中的大多数区域都没有目标。因此,节省这些区域的计算将大大加快检测过程,同时保持良好的性能。具体来说,我们利用帧之间的时间与空间关系来确定检测位置。
5.在这项工作中,结合两个基于mobilenetv1的ssd检测器,即heavydet和 minidet。heavydet是一个强大的全局检测器,它以滑动窗口的方式对整个图像进行检测,并找出整个领域的目标。为充分提取目标视频序列的时间-空间信息,假设目标在短时间内移动较小,然后利用前几帧的结果来确定当前帧中的局部搜索区域。这些搜索区域由minidet模型处理,它使用非常小的输入尺寸,使得该检测器比heavydet模型更有效率。此外,heavydet和minidet模型是动态交互的,以便在精确度和速度之间取得良好的平衡。
技术实现要素:
6.本发明旨在提供一种无人机场景视频目标检测框架,目的在于解决当前技术中无人机上嵌入式平台算力有限情况下视频目标检测推理速度缓慢,无法达到实际应用场景中的算法实时性要求的问题。
7.本发明的技术方案:
8.一种基于卷积神经网络的无人机场景视频目标检测方法,步骤如下:
9.步骤1、构建卷积神经网络模型,包括全局heavydet模型和局部minidet 模型,二者是动态交互的;
10.heavydet模型是基于mobilenet的ssd检测器,把原始图像分成多个子区域,相邻的子区域之间部分重叠,然后将一个图片的全部子区域作为一个批次输入到heavydet模型;接下来使用改进的nms来消除因目标出现在重叠区域而导致的假阳性;
11.改进的nms是在传统的nms的基础上添加预处理操作,具体过程如下:在执行传统nms前,先将所有子区域对应的目标边界框的位置坐标映射回原始图片,得到在原始图片坐标系下的目标边界框,然后再执行传统nms;
12.minidet模型是基于mobilenet的ssd检测器,以一个搜索区域作为其输入,并返回搜索区域中目标的位置;
13.步骤2、获取待检测视频序列,包含无人机场景下若干行人的视频序列,卷积神经网络模型的输入为上述视频序列中任意一帧的图像;
14.步骤3、使用卷积神经网络模型对视频序列进行无人机场景下行人目标检测,获取检测结果;
15.将步骤2获取的视频序列中的每帧图像作为步骤1构建的卷积神经网络模型的输入,然后利用卷积神经网络模型对输入图像中所有行人的位置进行预测;
16.heavydet模型负责在整张图片中精细检测行人,然后将检测结果扩展为一个搜索区域;minidet模型负责在搜索区域中逐帧修正;heavydet模型和minidet 模型交替执行;
17.在预测行人位置时,heavydet模型搜索整个图像以初步定位目标位置,然后以heavydet模型的检测出的目标边界框的几何中心为中心扩大1.5倍的区域作为minidet的搜索区域;将minidet模型应用于搜索区域以获得关于目标的边界框,该边界框将被继续扩展1.5倍作为下一帧的搜索区域;直到heavydet模型再次检测整个图像,以完善minidet模型的结果并初始化进入该区域的新目标;
18.当minidet模型未能在一个搜索区域中找到任何目标时,将目标的边界框保留在最后一帧中,并降低其分数;只有当搜索区域中检测到一些目标或启动了 heavydet模型时,搜索区域的位置才会被更新;检测边界框的扩展可能会覆盖邻近的目标,进而导致重复检测,采用下面两种方法来解决重复检测的问题:第一种方法是在训练阶段忽略只有部分可见的目标;另一种方法是在收集 minidet的结果时执行改进的nms;
19.步骤4、输出上述检测结果,基于上述检测结果,将所有行人的边界框可视化输出;
20.步骤5、获取卷积神经网络模型,包括:
21.搭建待训练卷积神经网络模型;
22.获取训练数据集、测试数据集以及验证数据集;
23.使用训练数据集训练前述卷积神经网络模型,得到经过训练的卷积神经网络模型的权重;
24.使用tensorrt对已训练的卷积神经网络模型进行量化加速。
25.所述的获取训练数据集、测试数据集以及验证数据集包括:
26.获取无人机场景行人检测数据集;
27.对检测数据集中的所有数据进行人工标注;
28.将标注后的数据集拆分为训练数据集、测试数据集以及验证数据集。
29.本发明的有益效果:
30.(1)在精确度和速度之间取得良好平衡
suppression,nms)来消除因目标出现在重叠区域而导致的假阳性。
44.传统的nms主要用于目标检测中提取一张图片中置信度高的边界框,而抑制置信度低的误检框。一般来说,模型输出的目标边界框会非常多,具体数量由anchor(锚框)数量决定,其中会有很多重复的框定位到同一个目标,nms 用来去除这些重复的框,获得真正的目标边界框。而本文方法中先将原始图片拆分为了多个有重叠区域的子区域,传统的nms并不能消除多个子区域之间存在的重复检测的误检框,因此对传统的nms进行了改进,添加了预处理操作。具体方法是,在执行传统nms前,先将所有子区域对应的目标边界框的位置坐标映射回原始图片,得到在原始图片坐标系下的目标边界框,然后再执行传统 nms。
45.minidet模型也是一个基于mobilenet的ssd检测器,以一个小的搜索区域作为其输入,并返回搜索区域中目标的位置。这些搜索区域是之前检测到的目标边界框经过扩展获得的,尺寸是检测到的目标边界框尺寸的1.5倍,中心位置重合。由于人的移动速度通常比较缓慢,搜索区域也会倾向于覆盖之前检测到的所有目标。当使用minidet处理图像时,许多没有目标的区域被忽略了。因此,计算负荷得到减轻,检测器的速度也得到提高。
46.步骤2、获取待检测视频序列;其中,该视频序列为包含无人机场景下若干行人的视频序列,该视频序列既可以是已经录制好的视频,诸如录像机等图像记录装置实时在线获取的视频亦可,这里不做严格要求。前述卷积神经网络的输入为上述视频序列中任意一帧的图像。
47.步骤3、使用上述卷积神经网络模型对前述视频序列进行无人机场景下行人目标检测,获取检测结果;
48.将上述视频序列中的每帧图像作为上述卷积神经网络的输入,然后利用该卷积神经网络对输入图像中所有行人的位置进行预测;
49.本方法的目标检测算法由heavydet和minidet组成,均基于ssd目标检测算法。heavydet模型负责在整张图片中精细检测行人,然后将该检测结果扩展为一个小的搜索区域,minidet模型负责在搜索区域中逐帧修正。heavydet模型和minidet模型这样交替执行,达到速度与精度的平衡。
50.具体来说,在预测行人位置时,heavydet模型仔细搜索整个图像以初步定位目标位置,然后将heavydet的检测结果扩大1.5倍作为minidet的搜索区域。将minidet模型应用于搜索区域以获得关于目标的边界框,该边界框将被继续扩展1.5倍作为下一帧的搜索区域。在处理若干帧后,heavydet再次检测整个图像,以完善minidet的结果并初始化进入该区域的新目标。heavydet和minidet 以这样的方式动态交替使用,在精确度和速度之间取得了良好的平衡。
51.可以注意到,minidet模型在其生命周期内可能会失败。如果minidet错过了一个目标,相应的搜索区域就会消失,这样这个目标就不会在接下来的帧中再次被识别,直到它被下一个heavydet检测到。为了修正这一点,将这些搜索区域保留一段时间,这样即使一个目标在一段时间内没有被检测到,它的轨迹也不会立即停止。具体来说,当minidet未能在一个搜索区域中找到任何目标时,我们将目标框保留在最后一帧中,并降低其分数。只有当搜索区域中检测到一些目标或启动了heavydet时,搜索区域的位置才会被更新。值得注意的是,检测边界框的扩展可能会覆盖邻近的目标,进而导致重复检测。采用下面两种方法来处理这个问题。第一种方法是在训练阶段忽略部分可见的目标,这使得模型对完整的人而
不是裁剪的人更加敏感。另一种方法是在收集minidet的结果时执行nms,这是处理重复检测的一种常规方式。
52.此外,当摄像机快速移动时,场景内目标的位置会发生激烈的变化。对于 minidet来说,要持续检测目标是非常困难的。在本文的算法框架中,对没有检测到任何目标的搜索区域的数量进行分析。如果未能检测到目标的搜索区域的比例足够高,将重新启动heavydet来再次搜索整个图像。没有必要经常启动 heavydet。本文算法框架会审查检测到的目标的数量,如果数量稳定,那么启动heavydet的频率就会降低。
53.步骤4、输出上述检测结果。包括:基于上述检测结果,将所有行人的边界框可视化输出。
54.步骤5、所述及的获取卷积神经网络模型,包括:
55.搭建待训练卷积神经网络模型;
56.获取训练数据集、测试数据集以及验证数据集;
57.使用前述训练数据集训练前述卷积神经网络模型,得到经过训练的卷积神经网络模型的权重。
58.使用tensorrt对前述已训练的卷积神经网络模型进行量化加速;
59.步骤6、上述获取训练数据集、测试数据集以及验证数据集包括:
60.获取无人机场景行人检测数据集;
61.对前述检测数据集中的所有数据进行人工标注;
62.将标注后的数据集拆分为训练数据集、测试数据集以及验证数据集。
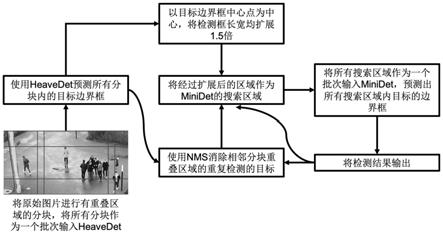
63.本发明实施例提供一种基于卷积神经网络的无人机场景视频目标检测方法,该方法由两个检测器组成,称为heavydet和minidet。heavydet模型仔细搜索整个图像以初步定位目标位置,然后将heavydet的结果作为minidet的搜索区域。将minidet模型应用于搜索区域以获得关于目标的边界框,该边界框将被继续扩展作为下一帧的搜索区域。在处理一段时间后,heavydet再次检测整个图像,以完善minidet的结果并初始化进入该区域的新目标。图1和表1展示了该方法的整体框架流程。
64.表1heavydet和minidet检测步骤
[0065][0066][0067]
整体算法框架以5帧为一个周期,每个周期开始的第一帧使用heacydet检测,之后使用minidet检测。当场景变化较大或目标位移较大时,minidet的搜索区域可能跟不上目标的移动,导致目标丢失,无法被检测到。针对这种情况,设置目标丢失阈值,当没有检测到目标的搜索区域大于全部搜索区域的40%时,启动heacydet检测接下来的3帧图片。当目标丢失百分比小于目标丢失阈值时,检测流程恢复正常。下面以一个实施例来具体说明本文方法流程。
[0068]
第一,由图1和表1所示,首先需要获取视频帧序列,该帧序列既可以是已经录制好的视频,诸如录像机等图像记录装置实时在线获取的视频亦可,这里不做严格要求。图1中输入图片为示例输入。
[0069]
第二,如果当前阶段(每5帧为一阶段)结束或快速移动发生,对当前阶段的第一帧图片按照图2所示方法进行有重叠区域的分块,将分块后的所有子图作为一个批次输入到heacydet模型。得到heacydet模型的检测结果。
[0070]
当摄像机快速移动时,场景内目标的位置会发生激烈的变化。对于minidet 来说,要持续检测目标是非常困难的。在本文的算法框架中,对没有检测到任何目标的搜索区域的数量进行分析。如果未能检测到目标的搜索区域的比例足够高,将重新启动heavydet来再次搜索整个图像。没有必要经常启动heavydet。本文算法框架会审查检测到的目标的数
量,如果数量稳定,那么启动heavydet 的频率就会降低。
[0071]
使用改进版本的nms来消除heacydet模型的检测结果中因目标出现在重叠区域而导致的假阳性。得到去除假阳性目标的检测结果。
[0072]
第四,对于当前阶段的后四帧图片,使用图3所示方法,将第三步检测结果中的所有目标的边界框扩大1.5倍,作为minidet模型的搜索区域。图3中实线框为heacydet模型检测出的目标边界框,虚线框为检测到的目标边界框经过扩展获得的,其尺寸是检测到的目标边界框尺寸的1.5倍,两者中心位置重合。
[0073]
第五,将第四步中所有的搜索区域作为一个批次输入到minidet模型,输出搜索区域中经过minidet修正的目标的位置。
[0074]
注意到,minidet模型在其生命周期内可能会失败。如果minidet错过了一个目标,相应的搜索区域就会消失,这样这个目标就不会在接下来的帧中再次被识别,直到它被下一个heavydet检测到。为了修正这一点,将这些搜索区域保留一段时间,这样即使一个目标在一段时间内没有被检测到,它的轨迹也不会立即停止。具体来说,当minidet未能在一个搜索区域中找到任何目标时,我们将目标框保留在最后一帧中,并降低其分数。只有当搜索区域中检测到一些目标或启动了heavydet时,搜索区域的位置才会被更新。值得注意的是,检测边界框的扩展可能会覆盖邻近的目标,进而导致重复检测。采用下面两种方法来处理这个问题。第一种方法是在训练阶段忽略部分可见的目标,这使得模型对完整的人而不是裁剪的人更加敏感。另一种方法是在收集minidet的结果时执行nms,这是处理重复检测的一种常规方式。
[0075]
第六,进入下一阶段,重复上述所有步骤直至视频帧结束。
[0076]
最终输出的检测效果如图5所示,从图中可以看出,本发明的视频目标检测框架在场景复杂、人员较多、目标较小的情况依然可以保持很好的检测效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。