1.本发明涉及加密引擎和软硬件协同安全领域,具体地说,是一种基于高速缓存的加密引擎加速方法。
背景技术:
2.近些年来,主流的处理器和硬件厂商在产品中提供了加密引擎,例如intel aes-ni;越来越多的安全解决方案从纯软件的、完全依赖于通用指令集的设计,转向了软硬件协同的、使用密码学硬件原语的设计,例如intel sgx、arm pa。一方面,基于加密引擎的设计通过领域专用架构提高了密码学运算的效率,让此前由于性能开销过高而不能在主流商业处理器上运用的安全机制得以普及。另一方面,加密引擎不易泄露中间加密结果,且可以安置在片上系统的不同位置,提供了更强大、更全面的安全保护。
3.在某些运行时的保护场景中,加密和解密运算会成对出现或重复出现。例如使用arm pa保护指针完整性,由于对函数指针的摘要和验证往往成对出现,因此相同的加密运算也会重复出现;此外,当同一函数在循环中被多次调用时,arm pa也需要多次执行相同的加密操作。虽然集成在处理器中的加密引擎加速了密码学运算,但是相比普通的算术和逻辑运算,仍然需要数倍的周期才能够完成。在经常调用的运行时保护中,上述性能开销仍然有必要优化。因此,为了降低重复执行的密码学运算的性能开销,本发明提出了一种基于高速缓存的加密引擎加速方法。
技术实现要素:
4.本发明的目的在于,针对背景技术中所描述的加密引擎重复执行相同密码学运算的性能开销问题,提供一种基于高速缓存的加密引擎加速方法。
5.本发明公开了一种基于高速缓存的加密引擎加速方法,包括:
6.1)使用高速缓存存储加密引擎的密码学运算的历史记录;
7.2)在加密引擎需要执行新的密码学运算操作时,首先查询高速缓存以快速得到运算结果,若缓存未命中,则通过加密引擎的运算单元执行相应的密码学运算操作。
8.作为进一步地改进,本发明在高速缓存中查询指定的密码学运算的结果,速度高于使用运算单元计算得到结果。
9.作为进一步地改进,本发明所述的密码学运算历史记录包括:
10.1)时间上,历史记录来自加密引擎上电以来通过运算单元执行的部分或全部密码学运算操作;
11.2)结构上,高速缓存的每一历史记录条目都包括加密引擎所使用的密码学算法的输入和输出或输入和输出的等价表示。
12.作为进一步地改进,本发明所述的输入和输出根据密码学算法的不同,包括:明文、密文、密钥、初始化向量、可调参数(可调分组密码中的tweak)、密码学算法每轮的中间结果。
13.作为进一步地改进,本发明所述的输入和输出的等价表示,等价表示不直接包含加密引擎所使用的密码学算法的全部输入或输出,当需要执行新的密码学运算且缓存命中时,加密引擎能够通过高速缓存中的等价表示,得到相应的密码学运算的结果。
14.作为进一步地改进,本发明所述的查询高速缓存包括以下步骤:
15.1)通过加密引擎需要执行的新的密码学运算,确定高速缓存的查询操作需要匹配缓存中历史记录的哪些项,若缓存命中,需要为加密引擎提供历史纪录的哪个项作为输出结果;
16.2)匹配上一步中确定的需要匹配的历史记录的项,若缓存中存在某个历史记录条目的每一项都与新的密码学运算相符,则高速缓存命中,由缓存直接输出密码学运算的结果。
17.本发明的有益效果如下:
18.本发明针对加密引擎重复执行相同密码学运算的性能开销问题,提供了一种基于高速缓存的加密引擎加速方法。目前,尚未出现解决这一问题的相关解决方案。实验表明,将该方法运用在基于qarma密码学算法的、类似于arm pa机制所使用的、旨在保护linux内核的返回地址、函数指针、部分敏感数据和中断上下文的加密引擎中,高速缓存拥有8个历史记录入口(entry)时,运行micro benchmark的性能开销相比于没有高速缓存的加密引擎,从4.5%降至2.6%。在更接近日常使用情况的macro benchmark中,以spec int 2017为例,本发明将运行时的性能开销降至低于0.2%。vivado生成的xilinx vc707评估板的网表显示,拥有8个以寄存器堆为存储介质的历史记录入口的高速缓存,功耗和面积开销均小于浮点运算单元。基于本发明的加密引擎在重复执行相同密码学运算场景下,能够在较小的功耗和面积额外开销下,获得性能的显著提升。
19.本方法使用高速缓存存储加密引擎的密码学运算的历史记录,在加密引擎需要执行新的密码学运算操作时,加密引擎首先查询高速缓存以快速得到运算结果,若缓存未命中,则通过加密引擎的运算单元执行相应的密码学运算操作。本方法针对目前流行并在商业产品中得到应用的运行时保护场景中,加密和解密运算会成对出现或重复出现的情景,为加密引擎提供加速,降低密码学运算的性能开销。实验证明,在使用集成在处理器中的加密引擎保护linux操作系统内核的函数指针、返回地址、部分敏感数据和中断上下文时,本方法能够在较小的功耗和面积额外开销下,获得显著的性能提升。特别地,在运行spec int 2017测试集时,性能开销低于0.2%。
附图说明
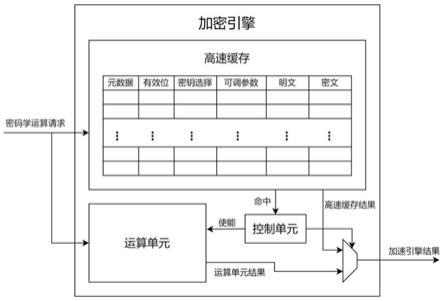
20.图1是使用一种基于高速缓存的加密引擎加速方法的某加密引擎的模块设计图;
21.图2是使用一种基于高速缓存的加密引擎加速方法与不使用本发明的加密引擎保护linux函数指针、返回地址、部分敏感数据和中断上下文,在运行unixbench时各个测试样例的性能开销对比图。
具体实施方式
22.本发明公开了一种基于高速缓存的加密引擎加速方法,包括如下步骤:
23.1)使用高速缓存存储加密引擎的密码学运算的历史记录;
24.2)在加密引擎需要执行新的密码学运算操作时,首先查询高速缓存以快速得到运算结果,若缓存未命中,则通过加密引擎的运算单元执行相应的密码学运算操作。
25.步骤1)中的高速缓存,在高速缓存中查询指定的密码学运算的结果,速度高于使用运算单元计算得到结果。本发明未对高速缓存的缓存组织形式或介质进行限制,实施中可以使用包括寄存器堆、sram、tcam介质。
26.步骤1)中的密码学运算历史记录,包含以下时间和结构上的特征。时间上,历史记录来自加密引擎上电以来通过运算单元执行的部分或全部密码学运算操作。受到物理介质容量的限制,高速缓存根据指定的更新策略和替换策略,会选择性地存储部分密码学运算的输入和输出,也会选择性地替换部分原本在缓存中的密码学运算的输入和输出。结构上,高速缓存的每一历史记录条目(item)都包括加密引擎所使用的密码学算法的输入和输出或它们的等价表示。输入和输出根据密码学算法的不同,包括:明文、密文、密钥、初始化向量、可调参数(可调分组密码中的tweak)、密码学算法每轮的中间结果。例如,加密引擎的密码学算法是某可调分组密码,则输入和输出包括:明文、密文、可调参数、密钥。密码学算法的输入和输出的等价表示不直接包含加密引擎所使用的密码学算法的全部输入或输出,当需要执行新的密码学运算且缓存命中时,加密引擎能够查询高速缓存是否命中,若缓存命中则能够通过高速缓存中结构上使用的等价表示存储的历史记录,得到相应的密码学运算的结果。例如,某些情况下,密钥较长,为了节省存储空间,如果加密引擎使用的密钥个数较少,则可以在高速缓存中存储密钥的编号,用以代替密钥本身。加密引擎仍能够通过密钥的编号,匹配新的运算所使用的密钥编号,正确执行高速缓存的查询。
27.步骤2)中的查询高速缓存,其特征在于,包括以下2个步骤。首先,通过外部请求加密引擎执行的新的密码学运算为加密运算还是解密运算,确定高速缓存的查询操作需要匹配缓存中历史记录的哪些项,若缓存命中,需要为加密引擎提供历史纪录的哪个项作为输出结果。一般地,加密操作匹配高速缓存中的明文和密钥,输出密文;解密操作匹配高速缓存中的密文和密钥,输出明文。第二步,匹配上一步中确定的需要匹配的历史记录的项。对于加密请求,高速缓存遍历每个入口,对比每一个历史记录条目的明文和密钥是否与加密引擎外部输入的密码学运算请求的明文和密钥完全相同,若是则命中,输出对应条目的密文;对于解密请求,高速缓存对比每一个历史记录条目的密文和密钥是否与密码学运算请求的密文和密钥完全相同,若是则命中,输出对应条目的明文。
28.下面结合说明书附图,通过具体实施例对本发明的技术方案作进一步地说明:
29.图1是使用一种基于高速缓存的加密引擎加速方法的某加密引擎的模块设计图;包括高速缓存、运算单元和控制单元。一种基于高速缓存的加密引擎加速方法,包括:
30.(1)使用高速缓存存储加密引擎的密码学运算的历史记录;
31.(2)在加密引擎执行新的密码学运算操作时,加密引擎外部的密码学运算请求信号同时传递给高速缓存和运算单元,高速缓存根据运算请求遍历所有入口,查询并对比每个历史记录条目并将是否命中的信号传递给控制单元。若缓存命中,控制单元通过图1中的名为加速引擎结果的信号,将高速缓存查询结果输出到加密引擎外部;否则。控制单元使能运算单元,待运算单元完成密码学运算,控制单元将结果从运算单元输出到加密引擎外部。
32.具体地,实施例中的加密引擎提供qarma可调分组密码的运算功能,集成在处理器的流水线中,需要支持较高的时钟频率,因此步骤(1)的高速缓存以寄存器堆为介质。在高
速缓存的入口数量较少时,寄存器堆能够用来搭建全相联的高速缓存,在一个周期内完成查询并匹配所有历史记录条目,速度高于需要4个周期才可以完成的运算单元。此外,寄存器堆搭建的高速缓存不会成为处理器的时序关键路径。
33.具体地,步骤(1)的密码学运算的历史记录,在结构上由加密引擎所使用的qarma算法的输入和输出的等价表示组成。在实施例的应用场景中,以加密运算为例,加密引擎所支持的qarma算法的输入和输出为64位明文、64位可调参数、128位密钥和64位密文;在具体的加密引擎设计中,共有4个数值固定但不相等的密钥,因此2位就可以编码所有密钥。每一个历史记录条目包括:宽度与高速缓存所使用的替换策略相关的元数据、表示历史记录条目有效的1位有效位、表示密码学运算使用了哪个密钥的2位密钥选择、64位可调参数、64位明文、64位密文。
34.根据上述查询高速缓存的匹配方式,实施例的密码学运算历史记录所使用的等价表示,虽然不直接包含qarma算法的密钥,但是当执行新的密码学运算时,加密引擎能够查询高速缓存是否命中,若缓存命中也能够根据等价表示提供相应的密码学运算的结果。
35.在实施例的实际应用场景中,处理器流水线向加密引擎发起密码学运算请求,并提供加密引擎需要的明文或密文、密钥选择、加密使能或解密使能、可调参数等信号。如果加密引擎接收到加密请求,首先,高速缓存会匹配明文、密钥选择、可调参数项,若某个有效位为1的历史记录条目的上述每项都等于请求信号的对应项,则缓存命中,加密引擎向处理器输出本历史记录条目的密文;对于解密请求,高速缓存匹配密文、密钥选择、可调参数项,若缓存命中,则加密引擎输出明文。若缓存未命中,则加密引擎的控制单元使能运算单元执行相应的密码学运算。运算单元完成密码学运算后,加密引擎将结果向处理器输出,并根据更新策略和替换策略更新高速缓存中的历史记录。实施例中的更新策略为运算单元完成的所有运算都作为最新的密码学运算的历史记录存入高速缓存中,替换策略为lru。新的历史记录会替换掉原本在高速缓存中的、最久没有被更新或查询命中的历史记录条目。
36.使用一种基于高速缓存的加密引擎加速方法,在实施例中加速对linux内核函数指针、返回地址、部分敏感数据、中断上下文的保护。当高速缓存有8个历史记录入口时,运行用户态应用程序spec int 2017,性能开销小于0.2%。图2是使用一种基于高速缓存的加密引擎加速方法与不使用本发明的加密引擎保护linux函数指针、返回地址、部分敏感数据和中断上下文,在运行unixbench时各个测试样例的性能开销对比图,在以unixbench为代表的micro benchmark中,与未使用本发明的同一加密引擎相比,使用本发明的加密引擎在运行unixbench的性能开销降低了1.9%,平均开销从4.5%降低到了2.6%。其中,除execl以外的系统调用密集型测试样例,即pipe、context1、spawn、syscall,性能提升明显。在面积和功耗开销方面,8个历史记录入口的高速缓存,均小于浮点运算单元的开销,大约是整数乘法器的2倍开销。
37.本领域普通技术人员可以理解,以上所述仅为发明的单个实例,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。