1.本发明属于计算机软件技术领域,涉及单目标跟踪技术,具体为一种基于混合注意力机制的端到端单目标跟踪方法及装置。
背景技术:
2.作为计算机视觉中的基本任务,视觉物体跟踪旨在为视频中的一个任意一般物体估计它在每一帧中出现的空间位置并标出物体边框。尽管目标跟踪已经取得了显著的进步,但如何设计一个简单而有效的端到端跟踪器仍然是一个挑战。主要挑战来自尺度变化、目标变形、遮挡和来自相似目标的混淆。
3.当前流行的跟踪器通常包含三个组件来完成跟踪任务:(1)cnn主干网络,用于提取待跟踪目标和搜索区域的一般特征;(2)融合模块,用于在跟踪目标和搜索区域之间进行信息通信,以进行后续的目标感知定位;(3)精确定位边界框模块,用来产生最终的跟踪结果。其中,融合模块是跟踪算法中的最关键的部分,它负责将待跟踪的目标信息整合到搜索区域的特征中,从而根据特定的跟踪目标出特定的框。传统的信息融合方法包括基于相关性的操作和在线模型更新算法。近期,由于transformer的全局和动态建模能力,它被引入到跟踪领域来做跟踪目标和跟踪区域的信息交互,并产生良好的跟踪性能。主要是利用transformer模型对目标特征和搜索区域进行特征融合,然后再将融合后的特征进行预测实现跟踪,然而,这些基于transformer的跟踪器仍然依赖于卷积主干网络来进行特征的提取,仅在相对高级和抽象的表示空间中应用注意力操作。但卷积主干网络的表示能力是有局限性的,首先它通常是基于一般的目标识别任务做的预训练,其次可能忽略用于跟踪的更精细的结构信息。
技术实现要素:
4.本发明要解决的问题是:如何设计一个简洁的端到端目标跟踪框架,不依赖卷积网络进行特征提取,并进一步能将特征提取和信息融合模块统一起来。
5.本发明的技术方案为:一种基于混合注意力机制的端到端单目标跟踪方法,构建一个跟踪框架mixformer用于目标跟踪,所述跟踪框架mixformer为一个端到端训练的transformer跟踪网络,包括一个主干网络和一个跟踪头,跟踪框架mixformer的构建实现包括如下阶段:
6.1)数据准备阶段,对训练数据集中所有视频帧裁剪出目标搜索区域,从每个视频的帧序列的前半部分抽取两帧作为模板帧,后半部分抽取一帧作为测试帧,对测试帧标注目标框作为验证帧,每个验证帧中目标框的对角坐标作为离线训练过程中的真实标签;
7.2)网络配置阶段,主干网络为一个基于混合注意力模块的特征提取器,将特征提取和信息融合通过transformer结构统一起来,跟踪头为一个回归头,采用卷积网络实现;将模板帧和测试帧同时输入到主干网络中产生融合了模板信息的测试帧特征,然后再将该测试帧特征通过回归头产生目标的对角坐标,作为测试帧产生的最终目标框;
8.其中,主干网络基于混合注意力机制,对模板帧和测试帧的特征进行自注意力和互注意力操作,自注意力用于提取模板帧和测试帧的自身特征,互注意力用于目标帧和测试帧的特征信息交互,以得到融合了模板信息的测试帧特征;
9.3)离线训练阶段,对于回归头目标框的训练,采用l1损失函数和giou损失函数来进行监督,结合由验证帧得到的真实标签,使用adamw优化器,通过反向传播算法来更新整个网络参数,不断训练配置的网络,直至达到迭代次数,得到跟踪框架mixformer;
10.在线跟踪,对待跟踪视频的第一帧标注目标搜索区域作为模板帧,后续帧作为测试帧,输入训练得到的跟踪框架mixformer,输出得到测试帧上的目标框,实现目标跟踪。
11.进一步的,主干网络的互注意力操作只进行单向的从模板帧到测试帧的互注意力,不进行从测试帧到模板帧的互注意力,得到融合了模板信息的测试帧特征。
12.进一步的,跟踪头还包括一个分类头,分类头用于得到测试帧的分类目标置信度,分类头具有一个预设的可学习的置信度向量,分别与测试帧特征和模板帧自身特征进行注意力操作,感知二者的信息预测得到当前测试帧的分类目标置信度,在跟踪过程中,从已经跟踪完的视频帧序列中挑选出置信度符合条件的帧补充作为模板帧。
13.在线跟踪时,首先裁剪出待跟踪视频的第一帧图像中的目标搜索区域,作为模板帧f
train
,待跟踪的帧作为测试帧f
test
,经过跟踪框架mixformer得到测试帧f
test
上的目标框,在跟踪过程中,从已经跟踪完的帧序列中每n帧挑选出一个置信度最高的帧及其跟踪得到的目标框作为标签,补充作为模板帧f
train
。
14.本发明构建了一个整洁有效的跟踪框架,只包含一个同时进行特征提取和信息融合的主干网络和一个跟踪头。本发明跟踪框架的这种耦合范式有如下优势。首先,它将使我们的特征提取更加适配于特定的跟踪目标,并捕获更多与目标相关的判别性特征。此外,它还允许更多尺度的目标信息融合,从而更好地捕获目标和搜索区域之间的相关性。
15.本发明基于上述跟踪方法还提供一种基于混合注意力机制的端到端单目标跟踪装置,具有计算机存储介质,所述计算机存储介质中配置有计算机程序,所述计算机程序用于实现上述的跟踪框架mixformer,所述计算机程序被执行时实现上述的跟踪方法。
16.本发明与现有技术相比有如下优点。
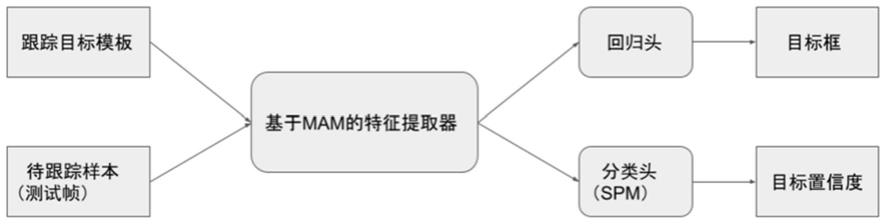
17.本发明提出了一种基于混合注意力机制的端到端单目标跟踪方法,构建了一个基于transformer的跟踪框架mixformer,采用了特殊设计的transformer骨干网络,即基于混合注意力模块mam的特征提取器来同时进行特征提取与目标信息融合,如图2所示,首先将目标帧和测试帧的拼接向量分割开来并且分别reshape成一个2d向量,然后过一个多头注意力函数,将产生的两个2d向量拼接并且过一个线性层即可得到融合了模板信息的测试帧特征。最后如图1所示,通过两个简单的回归头和分类头,得到跟踪目标框并进一步通过在线跟踪结果补充更新跟踪标签,得到了一个简洁清晰的跟踪框架,能有效地提升跟踪准确性。
18.本发明设计了一种可在线更新的模板样本空间,在跟踪过程中通过置信度预测模块来筛选更适应与当前跟踪的模板样本,从而提升模型的鲁棒性。相比现有的跟踪方法,本发明的在线跟踪方法能对跟踪过程中的物体变形有更好的适应能力,有效地提升目标回归的精度。
19.本发明在视觉物体跟踪任务上取得了很好的准确性,提升了物体回归的精度。相
较于现有方法,本发明提出的mixformer跟踪方法在多个视觉跟踪测试基准数据集(lasot,trackingnet,got-10k,vot2020,uav123)中都达到了最佳的跟踪成功率和定位准确度。
附图说明
20.图1是本发明跟踪框架mixformer的框架示意图。
21.图2是本发明中主干网络的混合注意力模块mam示意图。
22.图3是本发明分类头的置信度预测模块spm示意图。
具体实施方式
23.本发明提出了一种跟踪框架mixformer,旨在将特征提取和信息融合模块通过transformer结构统一起来。注意力模块是一个非常灵活的体系结构构建块,具有动态和全局建模能力,对数据结构的假设很少,可以普遍应用于不同类型的关系建模。本发明的核心思想是利用这种注意力操作的灵活性,提出了一种混合注意力模块mam,如图2所示,该模块首先将目标模板帧和测试帧的拼接向量分割开来并且分别reshape成一个2d向量,然后过一个多头注意力函数,将产生的两个2d向量拼接并且过一个线性层即可。将mam模块重复多次即可得到基于mam的特征提取器,通过多个串行的mam模块,加深了网络深度。该模块同时执行目标模板和搜索区域的特征提取和信息交互。在mam中,本发明设计了一个混合交互方案,对来自目标模板和搜索区域的特征,即模板帧和测试帧进行自注意力和互注意力操作。自注意力负责提取目标模板或搜索区域的自身特征,而互注意力则保证它们之间的通信,以混合目标和搜索区域信息。此外,为了降低mam的计算成本,并且允许使用多个模板来处理在线目标变形等问题,我们进一步提出了一种特定的不对称注意力机制,即在mam做互注意力的过程中,只进行单向的从模板帧到测试帧的互注意力,不进行从测试帧到模板帧的互注意力。
24.本发明提出的一种基于混合注意力机制的端到端单目标跟踪方法,经过在trackingnet-train、lasot-train、coco-train、got-10k-train四个训练数据集上进行离线训练,在uav123、vot2020、lasot-test、trackingnet-test、got-10k五个测试集上测试达到了高准确率和追踪成功率,具体使用python3.7编程语言,pytorch1.7深度学习框架实施。
25.图1是本发明方法的跟踪框架示意图,通过设计的端到端训练的transformer跟踪网络,直接得到待跟踪物体的目标框,从而实现目标追踪任务。整个方法包括数据准备阶段、网络配置阶段、离线训练阶段以及在线跟踪阶段,具体实施步骤如下:
26.1)数据的准备阶段,即生成训练样例阶段。在离线训练过程中,在离线训练过程中生成训练样例,首先对离线训练数据集中每个视频的每一帧图像进行目标区域抖动处理,然后裁剪出抖动处理后的目标搜索区域,从每个视频帧序列的前半部分抽取三帧作为训练帧,从每个视频帧序列的后半部分抽取一帧作为测试帧,对测试帧标注目标框作为验证帧,对于每个验证帧中目标框的左上角点和右下角点的坐标,作为离线训练过程中的真实标签。
27.2)网络配置阶段,即跟踪网络的配置阶段,本发明网络的整体结构与流程相较于其他跟踪器非常简洁,分为三个部分,整个框架和流程如图1所示,具体操作如下。
28.2.1)提取依赖于跟踪模板的测试帧特征:给定t帧跟踪模板和一个测试帧,将t帧跟踪模板拼接为模板帧,模板帧和测试帧二者的输入尺寸分别为t
×
128
×
128
×
3和320
×
320
×
3。首先通过一个卷积核大小为7且步长为4的卷积层生成有重叠的块向量。接下来把得到的块向量拉平并且把二者拼接起来,产生一个拼接向量f
token
,然后输入到混合注意力模块mam,从而产生融合了跟踪目标信息和测试帧信息的混合向量。其中mam的具体结构如图2所示,首先将二者的拼接向量f
token
分割开并且做reshape操作,进行自注意力操作得到模板帧和测试帧的自身特征,然后分别将二者的自身特征通过公共的多头注意力函数得到各自的query,key和value,然后如图2所示进行并行的注意力操作,最后将二者拼接后再过一个线性层实现交互,再与初始的向量f
token
相加即可得到一次混合的向量。通过重复m次上述操作,混合向量再分割reshape后进行自注意力和互注意力操作,加深网络深度,得到最终的混合特征,然后仅需要分割出混合特征中的测试帧对应特征并且进行reshape操作即可得到融合了模板信息的测试帧特征f
test
,大小为20
×
20
×
384。
29.2.2)得到测试帧中目标的跟踪框:跟踪回归头采用卷积网络,使用5个简单的卷积层作用于步骤2.1)得到的f
test
,输入通道数为384,输出通道数为2,分别得到目标的左上角和右下角的热力图,每个的大小都是20
×
20
×
1,最后通过取热力图最大值的方式得到左上角和右下角的坐标,从而得到目标框,即目标的跟踪框。
30.2.3)得到测试样本的分类置信度:本发明跟踪框架还针对在线跟踪在跟踪头中设置有一个分类头,将步骤2.1)得到f
test
经过一个分类置信度预测模块spm(score prediction module),可得到每个测试帧的分类置信度,即每个测试帧是否是正样本。spm的结构如图3所示,通过一个预设的可学习的置信度向量,分别与测试帧特征和目标模板帧自身特征进行attention注意力操作,感知二者的信息,从而预测得到最终的分类置信度,用于在线跟踪阶段挑选质量更高的在线样本作为模板帧用于跟踪。
31.下面以一个实施例具体说明网络配置阶段。使用上述基于mam的骨干网络,网络中载入imagenet预训练模型的参数,对测试帧提取依赖于目标模板的特征,特征图大小为20
×
20
×
384,分别代表了特征图的长度、宽度和通道数目。接下来将该特征图输入到回归头和分类头spm,分别得到最终的目标框和该目标框的分类置信度。该目标框即可作为跟踪的结果,分类置信度则用于挑选在线样本。
32.3)离线训练阶段,对于分类分支的离线训练使用交叉熵作为损失函数,对于回归分支使用了giou损失函数和l1损失函数,使用adamw优化器,设置单卡batchsize为32,总的训练轮数设置为500,学习率在400轮处学习率除以10,在8块nvidia tesla v100上训练,通过反向传播算法来更新整个网络参数,不断重复步骤2.1)至步骤2.3),直至达到迭代次数。
33.4)在线跟踪阶段,对待跟踪视频的第一帧标注目标搜索区域作为模板帧,后续帧作为测试帧,输入到训练好的网络中,在初始参数的基础上得到跟踪目标框。
34.作为优选方式,首先裁剪出待跟踪视频的第一帧图像中的目标搜索区域作为模板帧,作为初始目标模板,将待跟踪视频中待跟踪的帧作为测试帧,将目标模板和测试帧输入步骤2)的网络,得到测试帧上的目标框,在跟踪过程中,从已经跟踪完的帧序列中每20帧挑选出一个spm得到的分类置信度最高的帧及其跟踪得到的目标框作为标签,添加到在线目标模板集中,作为模板帧,实现对视频目标变形具有自适应性的在线目标跟踪。
35.在测试数据集上,跟踪的效率为22fps(nvidia gtx 1080ti),在跟踪精度上,在
got-10k数据集上auc达到了70.5%;在lasot数据集上,auc达到了69.5%;在trackingnet数据集上,auc达到了83.6%,pre达到了82.8%;在vot2020数据集上,eao达到了0.550,robustness达到了0.843,accuracy达到了0.760,在uav123数据集上,auc达到了70.4%。在上述测试数据集上的指标超过了当前效果最好的方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。