1.本发明涉及英语学习智能辅助领域,具体涉及一种英语学习辅助方法及系统。
背景技术:
2.英语是当今世界上主要的通用语言之一,也是世界上最广泛使用的语言。我国的基础教育发展战略中,也把英语教育作为公民素质教育的重要组成部分,并将其摆在突出地位,英语能力已成为了一种必备的技能。
3.然而在英语学习的过程中,由于不同学习者的学习能力不同,语言发展水平的也各不相同,针对不同水平的英语学习者,如果使用相同的教学方式,那么就无法保证每个人都取得最好的学习效果,因此个性化的教学十分重要。同时随着互联网技术的发展,网络上涌现了大量的英语阅读材料,这为英语的学习提供了丰富的资源。如何充分发挥互联网的资源优势,从丰富的网络语料中有效提取适合学生个性化学习的英文文本,这已成为英语学习中一个亟待解决的问题。
4.为了满足这些需求,需要实现一个英语语言水平评估,英语知识和文本推荐系统,从而为学习者提供更有效的个性化推荐,推动语言学习者语言水平的发展。
5.现有的英语学习辅助系统和方法大致可以分为两类:
6.第一类方法主要是基于文本词汇难度评估用户水平,进行文本推荐。该类方法通常是根据用户提供的作文或者可理解的阅读材料,提取文章中的所有词汇,然后根据单一的词汇统计特征(如频率等)对用户进行语言水平评估。该类方法一方面忽视了语法难度对阅读的影响;另一方面,以频率等统计特征作为词汇难度忽视了第二语言学习者并不存在充分语境的学习条件,往往不能反映语言学习者学习词汇的实际难度。因此,基于这类方法做出的能力评估及文本推荐常常出现对学习者不友好,真实学习难度差异巨大的情况。
7.第二类方法基于多种语言特征评估用户水平,进行文本推荐。该类方法通常选择大量的语言特征,如词汇频率,音节数,词性等多个维度,采用机器学习等方法确定文本的难度。这种方法在标准数据集上能够取得较好的效果,但在实际使用中缺乏依据,并且训练语料库的限制。如果使用的是外文标准语料库,其并不能够反应中国等第二语言学习者的能力水平判断。第二,训练需要大量的标注集合,这对于语料库的构建和积累提出了巨大的挑战,故这类方法很难用于实际教学活动中。第三,众多维度特征有时互产生互相的干扰,与实际教学进度产生不一致,这会进一步降低这类方法的实用性。
8.同时,这两类方法在推荐文本时,通常是采用欧式距离计算文本相似度,选择与用户上传的文本难度最接近的阅读材料进行推荐。但是相似的文本不一定适合语言学习者学习。更适合的一种方式是先对语言学习者需要学习的语法和词汇进行合理的分级,然后基于该分级准确评估学习者真实水平,最终向学习者推送包含下一阶段需要学习的词汇和语法的阅读文本。
9.综上所述,现有的方法都难以有效对针对第二语言学习者的英语语言水平评估,这使得基于第二语言学习的自动化推送十分困难。
技术实现要素:
10.为了解决上述技术问题,本发明提供一种英语学习辅助方法及系统。
11.本发明技术解决方案为:一种英语学习辅助方法,包括:
12.步骤s1:根据现有词典,构建词汇分级表;
13.步骤s2:根据英语教学大纲,构建语法分级表;
14.步骤s3:用户上传作文;根据所述作文,为所述用户创建用户词汇表,并结合所述词汇分级表,确定用户词汇等级;
15.步骤s4:根据所述作文,为所述用户创建用户语法表,结合所述语法分级表,确定用户语法等级;
16.步骤s5:根据所述用户词汇等级和所述用户语法等级,为所述用户推荐阅读内容。
17.本发明与现有技术相比,具有以下优点:
18.1、本发明公开了一种英语学习辅助方法,可以更加全面、准确地评估用户的真实英语水平。
19.2、本发明选择基于专家编写的词典解释对词汇进行分级,更符合真实的词汇难度划分;在进行语法水平评估时,使用了英语教学大纲作为依据构建语法分级表,从而保证了语法评估结果更有权威性。
20.3、本发明在为用户进行内容推荐时,一方面,同时提供了词汇,语法和文章的推荐,从而保证了推送内容的全面性;另一方面,在推送文章时,不是挑选难度近似的文章,而是基于“i 1”理论,根据用户词汇和语法的发展水平,选择下一语言发展水平需要学习的词汇、语法和以及包含这些内容的文章,更加合理和有效的促进学习者英语水平的发展。
附图说明
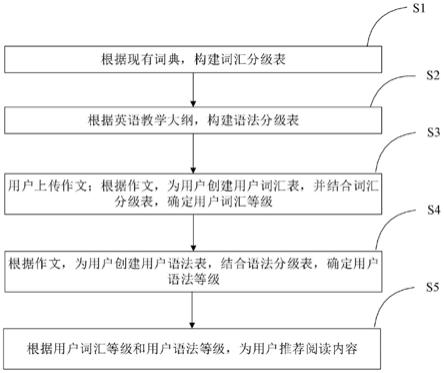
21.图1为本发明实施例中一种英语学习辅助方法的流程图;
22.图2为本发明实施例中构建词汇分级表的流程图;
23.图3为本发明实施例中词汇统计模块的流程图;
24.图4为本发明实施例中simplicity算法的流程图;
25.图5为本发明实施例中为用户创建用户词汇表的流程图;
26.图6为本发明实施例中确定用户词汇等级的流程图;
27.图7为本发明实施例中为用户创建用户语法表的流程图;
28.图8为本发明实施例中语法统计模块的流程图;
29.图9为本发明实施例中确定用户语法等级的流程图;
30.图10为本发明实施例中为用户推荐阅读内容的流程图;
31.图11为本发明实施例中一种英语学习辅助系统的结构框图。
具体实施方式
32.本发明提供了一种英语学习辅助方法,可以更加全面、准确地评估用户的真实英语水平。
33.为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
34.本发明提供的方法的核心思想是基于语言习得领域的“i 1”理论。“i 1”理论是美国的心理学家和教育家克拉申提出的,“i”代表学习者目前的语言知识水平,“1”表示略高于语言学习者现有水平的语言知识。用户通过大量接触“i 1”水平的语言知识,用户的语言水平就可以从“i”过渡到“i 1”阶段;而如果学习内容是“i 10”,甚至是“i 100”,那就太难了,超过了学习者的学习能力,从而知识无法掌握。基于这种思想,结合中国英语学习者的基础学习点:词汇和语法,提供了一种英语学习辅助方法和系统,能够从词汇和语法两方面数字化的评估用户英语水平,最终向用户适合当前学习水平的英文阅读文本。
35.为了方便理解下述实施例,对其中所使用的数据表及对应表名如下所列:
[0036][0037][0038]
实施例一
[0039]
如图1所示,本发明实施例提供的一种英语学习辅助方法,包括下述步骤:
[0040]
步骤s1:根据现有词典,构建词汇分级表;
[0041]
步骤s2:根据英语教学大纲,构建语法分级表;
[0042]
步骤s3:用户上传作文;根据作文,为用户创建用户词汇表,并结合词汇分级表,确定用户词汇等级;
[0043]
步骤s4:根据作文,为用户创建用户语法表,结合语法分级表,确定用户语法等级;
[0044]
步骤s5:根据用户词汇等级和用户语法等级,为用户推荐阅读内容。
[0045]
在英语词典中,每个英文单词都有对应的英语解释,词典的编纂者在编写这些解释时,一般会选用多个比“被解释词”更简单的“解释词”解释它。因此,可以根据词典中的“解释词”与“被解释词”相对难度关系进行排序。本发明实施例采用图的表示与算法构建词汇分级表,即:词典中的每一个单词都是该图中的一个节点;假设a、b表示词典中的两个单词,如果存在一词条a是“被解释词”、b是该词条中a的“解释词”,那么就可以在图中构建从a到b的边。根据下述两个假设条件,计算单词的难度:
[0046]
1.数量假设:如果一个单词被很多其它单词解释,说明这个单词比较简单,也就是该词汇simplicity值会相对较高(在图中,即被单词a解释的单词越多,a越简单)。
[0047]
2.质量假设:如果一个单词被一个simplicity值很高的单词解释,那么这个单词的simplicity值也会相应地提高(在图中,即用于解释单词a的单词越简单,a也越简单)。
[0048]
本发明实施例采用simplicity表示单词的简单程度,simplicity越小,单词难度越高。
[0049]
如图2所示,在一个实施例中,上述步骤s1:根据现有词典,构建词汇分级表,具体包括:
[0050]
步骤s101:选取一本词典,获取其中所有单词的所有的解释,组成词典语料库dictcorpus;其中,dictcorpus以map结构存储所有所述单词及其对应的所有解释,每个元素形如《word,[sense1,sense2...]》;
[0051]
步骤s102:初始化有向图g,令g为空,令item为dictcorpus的第一个元素;
[0052]
步骤s103:令itemword为item中的词汇,itemsenses为item中的所有解释;
[0053]
步骤s104:令sense为itemsenses的第一个元素;
[0054]
步骤s105:根据词汇统计模块,获取itemword一条解释中的所有互异单词的原形,记为sensewords,其中,词汇统计模块,具体包括:
[0055]
如图3所示,步骤s1051:将输入文本text按照空格和非单引号
“’”
的标点符号分割字符串,并将所有分割结果按分割次序存储在字符串链表strlist中;
[0056]
步骤s1052:按照字符串比对,统计strlist中各互异字符串,存储到字符串链表diffstrlist中,具体包括:
[0057]
步骤s10521:通过查询模块shortform遍历strlist中所有单词temp是否为若干单词的缩写:如果temp是某些单词的缩写,则将其进行拆分;
[0058]
步骤s10522:从strlist中移除temp,并将拆分后的两个单词加入strlist中;
[0059]
步骤s10523:统计strlist中各互异字符串,存储到字符串链表diffstrlist中;
[0060]
步骤s1053:令str为diffstrlist中的第一个字符串;
[0061]
步骤s1054:如果str只有首字母大写,则将str的首字母变为小写;转步骤2.5;
[0062]
步骤s1055:通过查询函数判断str是否为某一个单词的变形:如果str是某一个单词的变形,则将str变为其所对应的单词原形,转步骤s1056;否则,转步骤s1057;
[0063]
步骤s1056:如果textwords没有str且str属于wordlist,则将str存储到textwords中;
[0064]
步骤s1057:如str不是diffstrlist中最后一个元素,则将str后移一个元素,转步骤s1054;
[0065]
步骤s106:分别以itemword为弧尾节点,sensewords中的所有单词为弧头节点,把两个节点及有向边添加到g中;
[0066]
步骤s107:如果sense不是itemsenses的最后一个元素,则sense后移一个元素,转步骤s105,否则转步骤s108;
[0067]
步骤s108:如果item不是dictcorpus的最后一个元素,则item后移一个元素,转步骤s103,否则转步骤s109;
[0068]
步骤s109:根据simplicity算法,获取按simplicity值逆序排序,即难度从小到大的词汇表wordlist,wordlist每个元素为单词及其simplicity值,其中,simplicity算法,具体包括:
[0069]
如图4所示,步骤s1091:统计词典语料库中共计n个单词,并基于有向图g={v,e},其中,词典语料库中的所有单词构成节点集v,被解释词指向解释词的弧构成弧集e,将单词
和节点用序号表示(1,2..i..n),计算第i个单词simplicity值迭代计算公式(1)如下所示:
[0070][0071]
其中,xi表示节点i的simplicity值,即单词i的简单程度;xj表示节点j的simplicity值,即单词j的简单程度;k
jout
表示图中节点j的出度,即单词j的解释中“解释词”数量;xj除以k
jout
表示为:一个单词的解释中的解释词越多,这个单词越难,因为作为分母不能为0,所以一般取k
jout
=max(1,kj
out
);a
ij
表示节点j是否指向节点i,即单词i是否解释单词j,当存在节点j指向节点i的有向边时,a
ij
为1,否则为0;∑表示累加除了i节点以外所有其它节点的a
ij
×
xj/k
jout
值;α和β为预设的参数;
[0072]
步骤s1092:计算词典中所有单词的simplicity值,用矩阵的形式可以表示为公式(2):
[0073]
x=αad-1
x β1
ꢀꢀ
(2)
[0074]
其中,x为各节点simplicity值的列向量(x1,x2,..xn)
t
,1为列向量(1,1,1...)
t
,a为元素值为a
ij
的邻接矩阵,d是元素为d
jj
=max(1,k
jout
)对角矩阵,d-1
对角线上是1/k
jout
;
[0075]
步骤s1093:使用迭代算法求解simplicity值,首先给每个单词赋予相同的simplicity值,然后根据公式(2)不断迭代计算x,当计算前后的x的各分量的总误差绝对值小于阈值时迭代结束;
[0076]
步骤s110:把wordlist每p个单词归为一级,存储到词汇分级表leveledwords[i]中,并把p个单词的平均simplicity值记作这一级单词的难度存储到lw[i]。
[0077]
在一个实施例中,上述步骤s2:根据英语教学大纲,构建语法分级表,具体包括:
[0078]
步骤s201:构建一个具有m个等级的语法分级表,将语法点存储到语法分级表leveledgrammars,其中leveledgrammars[i]表示等级为i的语法点列表,i∈[1,m];
[0079]
步骤s202:将英语教学大纲中所有的语法点存储到outlinegrammars中。
[0080]
如图5所示,在一个实施例中,上述步骤s3中用户上传作文;根据作文,为用户创建用户词汇表,具体包括:
[0081]
步骤s301:令texts为用户一次上传的所有作文;
[0082]
步骤s302:令text为texts的第一篇作文;
[0083]
步骤s303:将text传给词汇统计模块,获取textwords;
[0084]
步骤s304:把textwords中所有没有出现在用户词汇表userwords中的单词,添加到userwords中;
[0085]
步骤s305:如果text不是texts的最后一篇作文,则令text为texts下一篇作文,转步骤s303。
[0086]
根据用户已掌握的所有单词userwords,结合词汇分级表leveledwords,对用户的词汇能力进行等级判定。假设用户的词汇水平,由其掌握的词汇中难度排在前α的词汇决定(α可取10%至30%)。因此,可以通过计算这些词汇的难度平均值averagevalue,对比leveledwords中各级单词的难度值lw[i],确定用户的词汇等级。其中i为1至n的自然数,以wordsevaluate(userwords)表示对用户词汇userwords的词汇等级判定。
[0087]
如图6所示,在一个实施例中,上述步骤s3中确定用户词汇等级,具体包括:
[0088]
步骤s311:使用快速排序算法,按照simplicity值对userwords从小到大排序;
[0089]
步骤s312:将总simplicity值total初始化为0,即total=0,选取用来计算词汇难度的单词数量num=length(userwords)
×
α,num向下取整数,length方法用来获取userwords的单词数量;
[0090]
步骤s313:令pr为userwords第一个单词的simplicity值;
[0091]
步骤s314:令total=total pr;
[0092]
步骤s315:如pr不是userwords中第num个元素的simplicity值,则将pr后移一个元素,转步骤s314;否则,转步骤s316;
[0093]
步骤s316:用户词汇平均simplicity值averagevalue=total/num;
[0094]
步骤s317:令i=1;
[0095]
步骤s318:如果averagevalue《lw[i]且i《n 1,则i=i 1,转步骤s318;否则,转步骤s319;
[0096]
步骤s319:如果i《n 1,则用户的词汇等级userwordgrade=i;否则userwordgrade=n。
[0097]
如图7所示,在一个实施例中,上述步骤s4中根据作文,为用户创建用户语法表,具体包括:
[0098]
步骤s401:令texts为用户一次上传的所有作文;
[0099]
步骤s402:令text为texts的第一篇作文;
[0100]
步骤s403:将text传给语法统计模块,获取textgrammars,其中,语法统计模块,具体包括:
[0101]
如图8所示,步骤s4031:令textgrammars为set数据结构,初始为空;
[0102]
步骤s4032:令text为用户的第一篇作文;
[0103]
步骤s4033:令sentence是text的第一个句子;
[0104]
步骤s4034:使用stanfordparser的parse方法处理sentence,得到语法解析树,其中包含了sentence中的所有词性和句法英文标签labels;
[0105]
步骤s4035:令label为labels的第一个标签;
[0106]
步骤s4036:判断label是否属于英语教学大纲outlinegrammars,如果属于则把将label添加到textgrammars中;否则转步骤s4037;
[0107]
步骤s4037:如果label不是labels的最后一个标签,则令label为labels的下一个,转步骤s4036;否则转步骤s4038;
[0108]
步骤s4038:当sentence不是text的最后一个句子时,令sentence为text的下一个句子,转步骤s4034;否则转步骤s4039;
[0109]
步骤s4039:当text不是用户的最后一篇作文时,令text为该用户的下一篇作文,转步骤s4033;否则,退出本模块;
[0110]
步骤s404:把textgrammars中所有没有出现在用户语法表usergrammars中的语法,添加到usergrammars中;
[0111]
步骤s405:如果text不是texts的最后一篇作文,则令text为texts下一篇作文,转步骤s403;否则,将usergrammars存储到数据库。
[0112]
根据用户已掌握的所有语法点usergrammars,结合英语教学大纲构建的语法分级
表leveledgrammars,对用户的语法能力进行等级判定。假设用户掌握的语法userwords中,包含了leveledwords中多个等级中的语法,则把最大的等级值判定为用户的语法等级。以grammarsevaluate(usergrammars)表示对用户语法usergrammars的语法等级判定。
[0113]
如图9所示,在一个实施例中,上述步骤s4中确定用户语法等级,具体包括:
[0114]
步骤s411:令grammar为usergrammars的第一个语法;
[0115]
步骤s412:获取用户语法等级usergrammargrade=max{1,grade(grammar)},其中grade(grammar)可以根据语法grammar得到其在leveledwords中的等级;
[0116]
步骤s413:如果grammar不是usergrammars的最后一个语法,则grammar后移,转步骤s412;否则,返回用户语法等级usergrammargrade。
[0117]
根据用户词汇等级和语法等级,向用户推送多篇文章及推送文章中用户未习得词汇和语法的解释和例句。语言学家认为,用户自主理解一段内容,至少要已知这段话里90%-95%的词汇。因此,结合“i 1”理论,考虑从包含大量文章的语料库corpusa中筛选出最多包含γ(可取1%-10%之间数值,本发明实施例取3%-5%)用户未掌握且属于“i 1”(i为用户词汇等级)等级词汇的k篇文章(k可取任意正整数,本发明实施例取5-10中数值)。同时,为了让用户在学习词汇的同时,学习到新的语法结构,该文章中同时要包含k个“j 1”(这里的j为用户语法等级)等级中用户未掌握的语法(本发明实施例k取1-3)。然后把这些文章推送给用户,同时从词汇语料库corpusb和语法语料库corpusc中提供文章中新词汇和语法的解释和例句辅助用户学习,其中corpusa,corpusb和corpusc假设已有,其中corpusa中包含大量的文章,corpusb中存储了英文中所有的词汇以及词汇的解释和例句,corpusc中存储了英文中所有的语法以及解释和例句。
[0118]
如图10所示,在一个实施例中,上述步骤s5:根据用户词汇等级和用户语法等级,为用户推荐阅读内容,具体包括:
[0119]
步骤s501:令tempcontents初始为空;
[0120]
步骤s502:令text为词典语料库中的第一篇文章;
[0121]
步骤s503:利用词汇统计模块得到text中的所有词汇words,利用语法统计模块得到text中的所有语法grammars;
[0122]
步骤s504:numword=length(words),numgrammar=length(grammars);
[0123]
步骤s505:
[0124]
i=wordsevaluate(userwords)j=grammarsevaluate(usergrammars);
[0125]
步骤s506:如果words至少有(1-γ)*numword个单词不属于userwrods记为newwords,其中,γ为预设的参数,而且words中剩余的单词属于leveledwords[i]或者leveledwords[i 1];而且grammars中至多存在k个语法点不属于usergrammars记为newgrammars,其中,k为预设的参数,且属于leveledgrammars[j]或者leveledgrammars[j 1],则把[text,newwords,newgrammars]添加到tempcontents中,转至步骤s507;否则,转至步骤s507;
[0126]
步骤s507:如果text不是词典语料库的最后一篇文章,则text后移,转步骤s503,否则转步骤s508;
[0127]
步骤s508:如果length(tempcontents)《=k,则令recommendcontents等于tempcontents;否则,截取tempcontents前k个元素,其中,k为预设的参数,赋值为
recommendcontents;
[0128]
步骤s509:推送recommendcontents中的text,并根据text中对应的newwords和newgrammars,从对应的词汇语料库corpusb和语法语料库corpusc提取解释和例句进行推送。
[0129]
本发明公开了一种英语学习辅助方法,可以更加全面、准确地评估用户的真实英语水平。本发明选择基于专家编写的词典解释对词汇进行分级,更符合真实的词汇难度划分;在进行语法水平评估时,使用了英语教学大纲作为依据构建语法分级表,从而保证了语法评估结果更有权威性。本发明在为用户进行内容推荐时,一方面,同时提供了词汇,语法和文章的推荐,从而保证了推送内容的全面性;另一方面,在推送文章时,不是挑选难度近似的文章,而是基于“i 1”理论,根据用户词汇和语法的发展水平,选择下一语言发展水平需要学习的词汇、语法和以及包含这些内容的文章,更加合理和有效的促进学习者英语水平的发展。
[0130]
实施例二
[0131]
如图6所示,本发明实施例提供了一种英语学习辅助系统,包括下述模块:
[0132]
构建词汇分级表模块61,用于根据现有词典,构建词汇分级表;
[0133]
构建词汇分级表模块62,用于根据英语教学大纲,构建语法分级表;
[0134]
确定用户词汇等级模块63,用于用户上传作文;根据作文,为用户创建用户词汇表,并结合词汇分级表,确定用户词汇等级;
[0135]
确定用户语法等级64,用于根据作文,为用户创建用户语法表,结合语法分级表,确定用户语法等级;
[0136]
推荐阅读内容模块65,用于根据用户词汇等级和用户语法等级,为用户推荐阅读内容。
[0137]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。