技术特征:
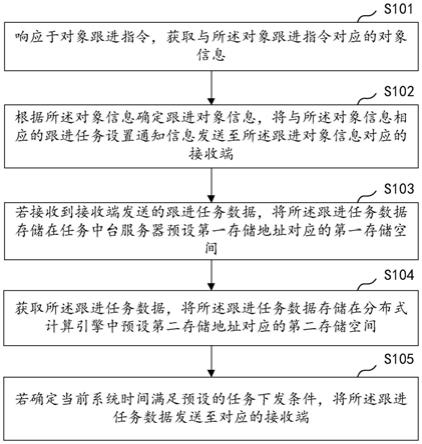
1.一种基于深度强化学习的货箱堆叠优化方法,其特征在于,包括如下步骤:步骤一,状态获取:根据货箱堆叠顺序及提箱优先级,设计m个环境状态变量来代表每个栈的堆存状态,再根据当前步骤使用的n个栈状态及其待堆叠的货箱状态,计算得到当前时刻的n
×
m维状态矩阵s,并将其传递给特征提取网络;步骤二,特征提取:通过设计特征提取网络,提取状态矩阵s中适合于堆叠决策网络决策的特征,得到n
×
p维的特征矩阵t,并将其传递给堆叠决策网络;步骤三,堆叠决策:首先设计堆叠决策网络的结构,然后再将特征矩阵t作为堆叠决策网络的输入数据,输出为各个栈的概率分布,进而选择一个栈堆叠货箱;步骤四,堆叠策略训练:使用深度强化学习算法进行特征提取网络和堆叠决策网络的训练,采用决策评价网络对特征提取网络和堆叠决策网络的输出进行评价,优化堆叠决策并更新特征提取网络和堆叠决策网络的参数,通过训练后的特征提取网络和堆叠决策网络进行特征提取和堆叠决策。2.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,步骤一中,环境状态变量的个数m=6,具体包括如下:(1)栈中已堆叠货箱数占最高堆叠层数的百分比;(2)下一个要堆放的货箱优先级;(3)待堆叠货箱中的最高优先级;(4)栈优先级,等于栈最顶部货箱的优先级;(5)待堆叠货箱中优先级高于栈优先级的个数;(6)栈中货箱的无序堆叠数。3.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,步骤二中,特征提取网络为基于自注意力机制的特征提取网络,将状态矩阵s进行变换得到特征矩阵t的计算公式如下:q=s
×
w
q
,k=s
×
w
k
,v=s
×
w
v
其中,t为特征矩阵,attention表示自注意力机制层,softmax为激活函数,q、k和v分别是状态矩阵s通过不同的权重矩阵变换得到的矩阵;和分别是用于生成q、k和v的权重矩阵,均为可学习的参数;d
q
,d
k
和d
v
分别表示权重矩阵w
q
、w
k
和w
v
中最后一维的维度大小。4.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,步骤三中,堆叠决策网络包括多层感知机网络、mask层和softmax函数,所述多层感知机网络包括输入层、隐层和输出层,隐层为三层,输入层神经元个数为64,隐层神经元个数分别为128、128和32,输出层的神经元个数为1。5.根据权利要求4所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,所述多层感知机网络中进行的运算如下:h1=w1t b1,h2=w2h1 b2,
h3=w3h2 b3,o=w4h3 b4;其中,h1、h2、h3分别为三层隐层的值,维度分别为n
×
128、n
×
128、n
×
32;t为特征矩阵;o为多层感知机网络的输出,维度为n
×
1;w1∈r
64
×
128
、w2∈r
128
×
128
、w3∈r
128
×
32
和w4∈r
32
×1为权重矩阵,均为可学习的参数;b1、b2、b3和b4为偏置。6.根据权利要求4所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,特征矩阵t作为堆叠决策网络的输入,经过多层感知机网络以后,得到的数据维度为n
×
1,然后对数据进行降维,得到各个栈的初始得分;然后再连接mask层,其输出为经过进一步筛选的各个栈的得分;这些筛选后的各个栈的得分再通过softmax函数计算得到n个栈的概率。7.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,步骤三中,进行栈选择时,采用贪心策略,即选择可选栈概率最大的,或者对栈概率分布进行采样选择。8.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,步骤四中,深度强化学习算法为ppo算法。9.根据权利要求1所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,所述决策评价网络为多层感知机网络,包括输入层、隐层和输出层,隐层为三层,输入层神经元个数为64,隐层神经元个数分别为128、128和32,输出层的神经元个数为1。10.根据权利要求9所述的一种基于深度强化学习的货箱堆叠优化方法,其特征在于,所述决策评价网络的输入为特征矩阵t进行均值池化后得到的当前价值估计,输出为一个标量值,以此评估特征提取网络和堆叠决策网络的表现。
技术总结
本发明公开了一种基于深度强化学习的货箱堆叠优化方法,包括如下步骤:根据货箱堆叠顺序及提箱优先级,设计m个环境状态变量来代表每个栈的堆存状态,再根据当前步骤使用的n个栈状态及其待堆叠的货箱状态,计算得到当前时刻的状态矩阵S;通过设计特征提取网络,进一步提取状态矩阵S中的特征,得到特征矩阵T;将特征矩阵T作为堆叠决策网络的输入数据,输出为各个栈的概率分布,进而选择一个栈堆叠货箱;使用深度强化学习算法进行特征提取网络和堆叠决策网络的训练,训练时采用决策评价网络对输出进行评价,优化堆叠决策并更新参数。本发明所公开的方法能够适应货箱数和栈最高堆叠层数发生变化的情况,以达到提高货箱堆叠和提取效率的目的。提取效率的目的。提取效率的目的。
技术研发人员:李歧强 段振堂 宋文
受保护的技术使用者:山东大学
技术研发日:2022.02.18
技术公布日:2022/5/31
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。