基于bert的两阶段民间故事检索方法
技术领域
1.本发明属于计算机技术领域,具体涉及到计算机信息检索系统。
背景技术:
2.21世纪是信息化的时代,互联网的发展使得收集民间故事的工作变的简单,进而人们可以了解到的民间故事大大增加。同时,文本信息处理的门槛和难度与日俱增,对文本检索技术的质量标准和效率要求也与日俱增。通常情况下,在大量的民间故事中找到符合需求的民间故事需要耗费大量的时间,而且检测的结果往往达不到预期结果。传统的检索方法有很多,例如有基于文本相似度计算的方法、基于本体的检索方法和基于聚类的检索方法。但是传统的检索方法是基于文本的浅层特征进行匹配计算的,因此存在很大的问题:第一,如果被检索的数据集很大,传统检索方法极度耗费时间并且检测准确度很低。第二,民间故事通常包含丰富的文本内容,仅仅依靠文本的浅层特征是远远不够的。因而寻求一种新的检索方法显得格外重要。民间故事包含了丰富的历史知识、深厚的民族情感,种类丰富且数量庞大。如何从种类繁多,数量庞大的民间故事中查询相关的民间故事成为民间故事检索的难点。
技术实现要素:
3.本发明所要解决的技术问题在于克服上述现有技术的缺点,提供一种检索准确率高、检索速度快的基于bert模型的两阶段民间故事检索方法。
4.解决上述技术问题采用的技术方案是由下述步骤组成:
5.(1)收集民间故事
6.从民族民间文化资源管理系统中找到民间故事部分,采用爬虫方法将民间故事中的文本数据爬取下来,得到民间故事。
7.(2)民间故事数据预处理
8.删除民间故事内容中的乱码、内容为空、与内容不符、同义词随机替换的部分。
9.(3)构建民间故事数据集
10.将民间故事处理成标题-内容的民间故事对,制作成民间故事数据集y,y∈{t1:c1,t2:c2,
…
,tn:cn},其中tn表示第n个民间故事的标题,cn表示第n个民间故事的内容,n选取10000条民间故事,按9:1的比例分为训练集、测试集。
11.(4)一阶段构建向量搜索引擎
12.采用bert-whitening模型将民间故事数据集y转化成词向量j,用faiss检索方法对词向量j建立数据库向量d,d∈{d1,d2,
…
,dn},将数据库向量d采用倒排快速索引方法分割为n个空间,n为有限的正整数,构建成向量搜索引擎。
13.(5)筛选候选民间故事集合
14.将用户的查询请求q通过bert-whitening模型转化成查询向量qv,将查询向量qv与数据库向量d按下式确定余弦相似度cosθ:
[0015][0016]
其中
·
表示点积操作,d表示数据库向量中的一个向量,||||表示取模操作,返回前k个候选民间故事集合g,g∈{g1,g2,
…
,gk},k取值为20~50。
[0017]
(6)训练bert模型
[0018]
将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0019]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0020]
其中,y为真实值,y取值为0或1,a为预测值,a∈(0,1);模型的学习率r∈[10-5
,10-3
],丢弃率取值为[0.05,0.1],训练轮数为[10,15],每轮训练的批尺寸为8,优化器选择adam,迭代至交叉熵损失函数l(y,a)收敛。
[0021]
(7)二阶段确定相关度
[0022]
将训练好的bert模型输出的词嵌入e和第l个编码层的输出x
l
,l为有限的正整数,对查询请求q和候选民间故事集合按下式确定候选民间故事集合g的相关度f1:
[0023]
e=es e
p
e
t
[0024]
x1=e
[0025][0026][0027]
q=x
l-1
×
wq[0028]
k=x
l-1
×
wk[0029]
v=x
l-1
×
wv[0030]
f1=s(h
12
)
[0031]
其中表示多头注意力计算的输出,es表示句子词嵌入,e
p
表示位置词嵌入,e
t
表示词嵌入,c表示将注意力矩阵连接操作,aj表示注意力矩阵,s(h
12
)表示softmax函数,x
l-1
是bert模型的第l-1层输出,dk是输入向量的维度,j表示多头注意力的个数,wq,wk,wv是线性映射矩阵,q、k、v表示在训练过程中学习参数矩阵。
[0032]
按下式确定相关度f:
[0033]
f=0.5
×
f1 0.5
×
f2[0034][0035]
wi=s(ri)
[0036]
其中,f2表示查询请求和候选民间故事子片段的相似度和,ri表示查询请求和候选民间故事子片段的相似度,wi表示每个子片段相关度的权重,s(ri)表示softmax函数。
[0037]
(8)展示检索结果
[0038]
将相关度f进行由高到低的排序,相似度最高的民间故事作为最终检索结果展示给用户。
[0039]
在本发明的(3)步骤中,所述的标题-内容的民间故事对为:将民间故事的标题和
内容进行分词,标题t拆分为:
[0040]
t={t1,t2,
…
,tu}
[0041]
其中u为标题的长度;
[0042]
内容s拆分为:
[0043]
s={s1,s2,
…
,sz}
[0044]
其中z为内容的长度。
[0045]
在本发明的(5)和(7)步骤中,所述的查询请求q为:进行解析、分词处理,通过bert-whitening模型转换成词向量v。
[0046]
在本发明的(6)步骤中,将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0047]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0048]
在(6)步骤中,所述的将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0049]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0050]
其中,y为真实值,y取值为0或1,a为预测值,a最佳为0.5,模型的学习率r最佳为10-4
,丢弃率取值最佳为0.08,训练轮数最佳为12,每轮训练的批尺寸为8,优化器选择adam,迭代至交叉熵损失函数l(y,a)收敛。
[0051]
在本发明的(7)步骤中,所述的候选民间故事集合g包含有5个子片段,每个子片段的长度为128,前一个子片段的结尾与后一个子片段的开头有10%的内容重复。
[0052]
在本发明的(7)步骤的下式中:
[0053]
x1=e
[0054]
其中x
l
表示bert模型第l个编码层的输出,l取值为[1,12]。
[0055]
本发明与现有技术相比有以下优点:
[0056]
由于本发明采用了两阶段的检索方法,将faiss检索算法与bert预训练语言模型相结合,使得模型能够更好地了解民间故事的上下文信息,将查询请求先筛选候选民间故事集合再利用bert模型进行相关度计算,在提升传统检索速度的同时,增加了检索的准确率,检索结果准确。本发明可以帮助用户在大量的民间故事中快速准确地找到想要了解的民间故事,减少了用户等待时间,激发了用户对于民间故事的兴趣,有利于传统文化的传播。
附图说明
[0057]
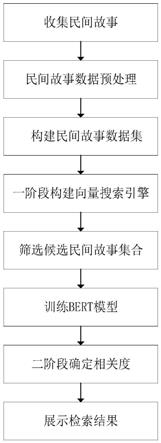
图1是本发明实施例1的流程图
具体实施方式
[0058]
下面结合附图和实施例对本发明进一步详细说明,但本发明不限于下述的实施方式。
[0059]
实施例1
[0060]
在图1中,本实施例的基于bert的两阶段民间故事检索方法由以下步骤组成:
[0061]
(1)收集民间故事
[0062]
从民族民间文化资源管理系统中找到民间故事部分,采用爬虫方法将民间故事中的文本数据爬取下来,得到民间故事。
[0063]
(2)民间故事数据预处理
[0064]
删除民间故事内容中的乱码、内容为空、与内容不符、同义词随机替换的部分。
[0065]
(3)构建民间故事数据集
[0066]
将民间故事处理成标题-内容的民间故事对,制作成民间故事数据集y,y∈{t1:c1,t2:c2,
…
,tn:cn},其中tn表示第n个民间故事的标题,cn表示第n个民间故事的内容,n选取10000条民间故事,按9:1的比例分为训练集、测试集。
[0067]
所述的标题-内容的民间故事对为:将民间故事的标题和内容进行分词,标题拆分为:
[0068]
t={t1,t2,
…
,tu}
[0069]
其中u为标题的长度。
[0070]
内容拆分为:
[0071]
s={s1,s2,
…
,sz}
[0072]
其中z为内容的长度。
[0073]
(4)一阶段构建向量搜索引擎
[0074]
采用bert-whitening模型将民间故事数据集y转化成词向量j,用faiss检索方法对词向量j建立数据库向量d,d∈{d1,d2,
…
,dn},将数据库向量d采用倒排快速索引方法分割为n个空间,n为有限的正整数,构建成向量搜索引擎。
[0075]
将用户的查询请求q通过bert-whitening模型转化成查询向量qv,将查询向量qv与数据库向量d按下式确定余弦相似度cosθ:
[0076][0077]
其中
·
表示点积操作,d表示数据库向量中的一个向量,||||表示取模操作,返回前k个候选民间故事集合g,g∈{g1,g2,
…
,gk},k取值为20~50,本实施例的k取值为40。
[0078]
本实施例的查询请求操作为:进行解析、分词处理,通过bert-whitening模型转换成词向量v。
[0079]
(6)训练bert模型
[0080]
将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0081]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0082]
其中,y为真实值,y取值为0,a为预测值,a∈(0,1),模型的学习率r∈[10-5
,10-3
],丢弃率取值为[0.05,0.1],训练轮数为[10,15],每轮训练的批尺寸为8,优化器选择adam,迭代至交叉熵损失函数l(y,a)收敛。本实施例a取值为0.5,模型的学习率r取值为10-4
,丢弃率取值为0.08,训练轮数为12。
[0083]
(7)二阶段确定相关度
[0084]
将训练好的bert模型输出的词嵌入e和第l个编码层的输出x
l
,l为有限的正整数,本实施例的l取值为6,对查询请求q和候选民间故事集合按下式确定候选民间故事集合g的相关度f1:
[0085]
e=es e
p
e
t
[0086]
x1=e
[0087][0088][0089]
q=x
l-1
×
wq[0090]
k=x
l-1
×
wk[0091]
v=x
l-1
×
wv[0092]
f1=s(h
12
)
[0093]
其中表示多头注意力计算的输出,es表示句子词嵌入,e
p
表示位置词嵌入,e
t
表示词嵌入,c表示将注意力矩阵连接操作,aj表示注意力矩阵,s(h
12
)表示softmax函数,x
l-1
是bert模型的第l-1层输出,dk是输入向量的维度,j表示多头注意力的个数,wq,wk,wv是线性映射矩阵,q、k、v表示在训练过程中学习参数矩阵。
[0094]
按下式确定相关度f:
[0095]
f=0.5
×
f1 0.5
×
f2[0096][0097]
wi=s(ri)
[0098]
其中,f2表示查询请求和候选民间故事子片段的相似度和,ri表示查询请求和候选民间故事子片段的相似度,wi表示每个子片段相关度的权重,s(ri)表示softmax函数。
[0099]
(8)展示检索结果
[0100]
将相关度f进行由高到低的排序,相似度最高的民间故事作为最终检索结果展示给用户。
[0101]
完成基于bert的两阶段民间故事检索方法。
[0102]
实施例2
[0103]
本实施例的基于bert的两阶段民间故事检索方法由以下步骤组成:
[0104]
(1)收集民间故事
[0105]
该步骤与实施例1相同。
[0106]
(2)民间故事数据预处理
[0107]
该步骤与实施例1相同。
[0108]
(3)构建民间故事数据集
[0109]
该步骤与实施例1相同。
[0110]
(4)一阶段构建向量搜索引擎
[0111]
该步骤与实施例1相同。
[0112]
(5)筛选候选民间故事集合
[0113]
将用户的查询请求q通过bert-whitening模型转化成查询向量qv,将查询向量qv与数据库向量d按下式确定余弦相似度cosθ:
[0114][0115]
其中
·
表示点积操作,d表示数据库向量中的一个向量,||||表示取模操作,返回前k个候选民间故事集合g,g∈{g1,g2,
…
,gk},k取值为20~50,本实施例k取值为20。
[0116]
该步骤的其它步骤与实施例1相同。
[0117]
(6)训练bert模型
[0118]
将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0119]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0120]
其中,y为真实值,y取值为0,a为预测值,a∈(0,1),模型的学习率r∈[10-5
,10-3
],丢弃率取值为[0.05,0.1],训练轮数为[10,15],每轮训练的批尺寸为8,优化器选择adam,迭代至交叉熵损失函数l(y,a)收敛。本实施例a取值为0.01,模型的学习率r取值为10-5
,丢弃率取值为0.05,训练轮数为10。
[0121]
该步骤的其它步骤与实施例1相同。
[0122]
(7)二阶段确定相关度
[0123]
将训练好的bert模型输出的词嵌入e和第l个编码层的输出x
l
,l为有限的正整数,本实施例的l取值为6,确定候选民间故事集合g的相关度f1、确定相关度f的步骤与实施例1相同。
[0124]
其它步骤与实施例1相同。
[0125]
完成基于bert的两阶段民间故事检索方法。
[0126]
实施例3
[0127]
本实施例的基于bert的两阶段民间故事检索方法由以下步骤组成:
[0128]
(1)收集民间故事
[0129]
该步骤与实施例1相同。
[0130]
(2)民间故事数据预处理
[0131]
该步骤与实施例1相同。
[0132]
(3)构建民间故事数据集
[0133]
该步骤与实施例1相同。
[0134]
(4)一阶段构建向量搜索引擎
[0135]
该步骤与实施例1相同。
[0136]
(5)筛选候选民间故事集合
[0137]
将用户的查询请求q通过bert-whitening模型转化成查询向量qv,将查询向量qv与数据库向量d按下式确定余弦相似度cosθ:
[0138][0139]
其中
·
表示点积操作,d表示数据库向量中的一个向量,||||表示取模操作,返回前k个候选民间故事集合g,g∈{g1,g2,
…
,gk},k取值为20~50,本实施例k取值为50。
[0140]
该步骤的其它步骤与实施例1相同。
[0141]
(6)训练bert模型
[0142]
将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0143]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0144]
其中,y为真实值,y取值为0,a为预测值,a∈(0,1),模型的学习率r∈[10-5
,10-3
],丢弃率取值为[0.05,0.1],训练轮数为[10,15],每轮训练的批尺寸为8,优化器选择adam,迭代至交叉熵损失函数l(y,a)收敛。本实施例a取值为0.09,模型的学习率r取值为10-3
,丢弃率取值为0.1,训练轮数为15。
[0145]
该步骤的其它步骤与实施例1相同。
[0146]
(7)二阶段确定相关度
[0147]
将训练好的bert模型输出的词嵌入e和第l个编码层的输出x
l
,l为有限的正整数,本实施例的l取值为12,确定候选民间故事集合g的相关度f1、确定相关度f的步骤与实施例1相同。
[0148]
其它步骤与实施例1相同。
[0149]
完成基于bert的两阶段民间故事检索方法。
[0150]
实施例4
[0151]
在以上的实施例1~3中,本实施例的基于bert的两阶段民间故事检索方法由以下步骤组成:
[0152]
(1)~(5)步骤与实施例1相同。
[0153]
(6)训练bert模型
[0154]
将民间故事数据集y输入至bert模型进行训练,按下式确定交叉熵损失函数l(y,a):
[0155]
l(y,a)=y
×
lna (1-y)
×
ln(1-a)
[0156]
其中,y为真实值,y取值为1,其它参数与相应的实施例相同。
[0157]
其它步骤与实施例1相同。
[0158]
完成基于bert的两阶段民间故事检索方法。
[0159]
为了验证本发明的有益效果,发明人采用本发明实施例1的基于bert的两阶段民间故事检索方法与传统检索方法term frequency-inverse document frequency方法(以下简称tf-idf)和best match 25方法(以下简称bm25)进行了对比仿真实验。
[0160]
评价指标:平均倒数排名m(以下简称m),归一化折损累计增益n(以下简称n),检索时间t(以下简称t),m和n的大小,为评价检索准确性的评价指标,m和n大,表明检索准确性好。
[0161]
按下式计算平均倒数排名m:
[0162][0163]
其中,b取值1000,表示测试集中查询请求的数量,对每个查询qi,记它第一个相关的结果排在位置bi。
[0164]
按下式计算归一化折损累计增益n:
[0165]
[0166]
其中,表示结果按照相关性从大到小的顺序排序,取前10个结果组成的集合。ei表示查询相关值。
[0167]
实验及计算结果见表1。
[0168]
表1本发明与对比检索方法仿真实验结果表
[0169][0170]
由表1可见,实施例1方法平均倒数排名m为0.344,高于tf-idf方法、bm25方法;实施例1方法归一化折损累计增益n为0.389,高于tf-idf方法、bm25方法;实施例1方法检索时间为4813秒,少于tf-idf方法、bm25方法。实验表明本发明方法有更好的检索准确性和更快的检索速度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。