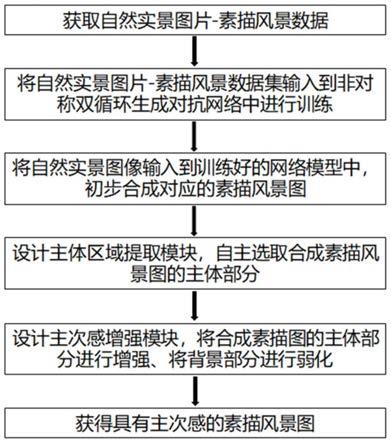
1.本发明属于计算机视觉技术领域,涉及一种视图重要性网络与自注意力机制相结合的三维物体识别方法。
背景技术:
2.近年来随着室内机器人和计算机视觉的发展,室内机器人为人类主动在室内找寻、抓取物体已成为现实,其中如何准确识别三维物体是该领域中基本的问题之一。随着普林斯顿大学开源了modelnet项目,为研究人员提供一个全面、清晰的三维物体模型集合,促使三维物体识别领域涌现出了各种方法。三维物体识别方法根据输入的数据类型不同,可以分为三类:基于点云的三维物体识别、基于体素的三维物体识别以及基于多视图的三维物体识别。
3.基于点云的三维物体识别方法,通常将数据采集设备收集到的无序点云直接进行卷积处理,获得三维物体的类别信息;基于体素的三维物体识别方法,通常会将无序的点云进行分块,形成体素数据后再利用卷积处理的方法获得三维物体的类别信息。上述两种方法存在数据采集设备昂贵,数据维度高,处理成本高等问题,难以广泛应用于日常生活中。而基于多视图的方法由于其数据的易获得且便于处理,获得了更多的关注,并由于imagenet等大规模数据集用于cnn模型预训练等,基于多视图的三维物体识别方法取得了最优的识别结果,成为主流方法。
4.基于多视图的三维物体识别方法通常将三维物体模型从多个视角进行渲染,进而获得待识别三维物体的多视图,在获取的多视图上应用卷积网络进行分类。例如su等人提出了基于多视图的三维物体识别方法的开篇之作mvcnn,其效果优于大多数基于点云、体素的方法。但是mvcnn方法中使用了最大池化方法,三维物体的大部分视图信息都被丢失,因此有待进一步挖掘研究基于多视图的三维物体识别方法。
技术实现要素:
5.本发明针对现有基于多视图的三维物体识别方法的不足加以改进,提出一种视图重要性网络与自注意力机制相结合的三维物体识别方法,该方法先通过视图重要性网络计算多视图中每个视图的重要性得分,根据对应的重要性得分进行不同程度的增强,视图重要性网络加强了有益于三维物体识别视图的表达,而后通过自注意力机制融合不同视图间的非局部信息以进一步增强多视图的特征表达。通过视图重要性网络与自注意力机制相结合的方式,三维物体多视图的特征表达得到了增强,实验结果表明,利用增强后的多视图进行识别分类,准确率得到了有效提高,证明了本方法具有良好的性能。
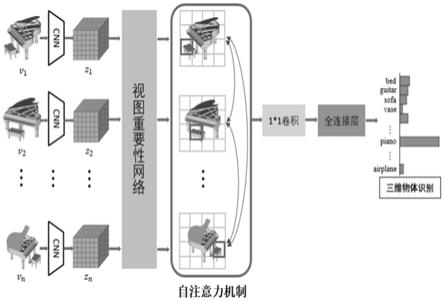
6.为实现这个目标,本发明的技术方案是:步骤1,将待识别三维物体从n个不同的视角进行投影获得n个不同的二维视图,其中,n大于等于二;步骤2,通过基础cnn模型对n个视图进行特征提取,得到对应视图的特征图;步骤3,通过视图重要性网络输出n个视图各自对
三维物体识别的重要性得分,其中得分越高表示该视图所包含用于物体识别的关键信息越丰富,并根据重要性得分对特征进行加强,获得视图增强特征图;步骤4,将视图增强特征图使用自注意力机制进行处理,得到跨视角增强特征图;步骤5,将三维形状描述符输入到全连接网络进行多视角物体识别,实现三维物体识别。
7.在本发明提供的一种视图重要性网络与自注意力机制相结合的三维物体识别方法中,还可以具有这样的特征:其中,步骤1包括:将三维物体模型从n个视角进行投影,进而获取到该物体的n个渲染视图v={v1,v2,...,vn},其中vi为该物体的第i个视图。
8.在本发明提供的一种视图重要性网络与自注意力机制相结合的三维物体识别方法中,还可以具有这样的特征:其中,步骤2包括:将渲染视图v={v1,v2,...,vn}经过基础cnn模型提取出n个视图各自的初始视觉特征图z={z1,z2,...,zn},其中zi为该物体的第i个视图,zi∈rc×h×w,z∈rn×c×h×w,其中n代表多视图的数量,c代表每个视觉特征图的通道数,h代表每个视觉特征图的高度,w代表每个视觉特征图的宽度。
9.在本发明提供的一种视图重要性网络与自注意力机制相结合的三维物体识别方法中,还可以具有这样的特征:其中,步骤3包括:将n个视图的初始视觉特征图z={z1,z2,...,zn}输入到视图重要性网络,视图重要性网络将对每一个视图进行打分,如公式(1),
10.score=softmax{f(z1),f(z2),...,f(zn)},
ꢀꢀꢀ
(1)
11.公式(1)中,f代表为视图重要性打分的网络层,通过训练,该网络层能够根据视图特征的信息丰富度为视图的重要性打分,由此可以将包含视觉特征信息丰富的特征进行突出;softmax函数确保各视图的重要性总和为1,避免出现视图重要性分数差异悬殊;视图的初始特征图将与其重要性相乘,并与其初始特征图相加,如公式(2),
12.pi=zi scorei*zi,
ꢀꢀꢀꢀ
(2)
13.公式(2)中,zi为该物体的第i个视图的初始视觉特征图,scorei表示视图重要性网络对第i个视图重要性的打分。每个视图的初始特征图与其重要性相乘,并与其初始特征图相加,得到三维物体n个视图增强特征图p={p1,p2,...,pn},pi∈rc×h×w,p∈rn×c×h×w。
14.在本发明提供的一种视图重要性网络与自注意力机制相结合的三维物体识别方法中,还可以具有这样的特征:其中,步骤4包括以下子步骤:
15.步骤4-1,将视图增强特征图p={p1,p2,...,pn}分别输入到三个卷积网络,生成新的特征映射pq,pk和pv,pq,pk,pv∈rn×c×h×w。将pk进行转置操作,并与pq进行矩阵相乘,获得特征图在空间上的关联关系,如公式(3),
[0016][0017]
公式(3)中,s代表相似度,i和m为视角的索引,其中i,m∈[1,n],n为视角数,由于h与w数值相等,因此l2表示单个视角特征图中所有的空间位置,综上,s
im
包含了任一视角下任一空间位置的视图增强特征与所有视角中的任一空间位置的特征的关系,关联关系越强,则在矩阵中的权值越大。
[0018]
步骤4-2,将s
im
与pv进行矩阵相乘,得到跨视角增强特征图a={a1,a2,...,an},ai∈rc×h×w,a∈rn×c×h×w。通过自注意力机制,打破了特征的局部性,实现了跨视角的非局部特
征增强,使任一视角的任一空间上的特征表示更加丰富,有效增强了视图特征的表达。
[0019]
在本发明提供的一种视图重要性网络与自注意力机制相结合的三维物体识别方法中,还可以具有这样的特征:其中,步骤5包括:
[0020]
将跨视角增强特征图a={a1,a2,...,an}通过1*1卷积进行降维,其中1*1卷积通过跨视角的方式对特征进行了提取,避免了最大池化所带来的信息丢失问题。降维后的特征将输入到全连接层进行分类,实现三维物体的识别。
[0021]
有益效果
[0022]
1)通过视图重要性网络对不同的视图进行相应的加权,能够突出有利于三维物体识别的视图,同时抑制了非重要视图的表达;2)通过自注意力机制融合不同视图间的非局部信息,实现了跨视角的空间特征增强,以进一步增强多视图的特征表达;3)采用1*1卷积代替最大池化操作进行特征降维,避免了信息丢失带来的识别精度下降。
附图说明
[0023]
图1为本发明方法的网络框架示意图;
[0024]
图2为本发明提出的视图重要性网络的实例实验结果;
[0025]
图3为本发明实例中的自注意力机制示意图;
具体实施方式
[0026]
本发明基于深度学习的开源工具pytorch实现,使用gpu处理器nvidia gtx3090训练网络模型。
[0027]
下面结合附图和具体实施方式对本发明方法中各个模块构成做进一步说明,应理解文中的具体实例说明仅用于说明本发明,而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0028]
本发明的网络框架组成和流程如图1所示,具体包括如下步骤:
[0029]
步骤1,将三维物体模型从n个视角进行投影,进而获取到该物体的n个渲染视图v={v1,v2,...,vn},其中vi为该物体的第i个视图,在本实验中n设置为12,即采用12个视角进行三维物体识别。
[0030]
步骤2,将渲染视图v={v1,v2,...,vn}经过基础cnn模型提取出n个视图各自的初始视觉特征图z={z1,z2,...,zn},其中zi为该物体的第i个视图。具体的,我们采用了在单张图像上进行物体识别的预训练vgg网络,并移除最后一层全连接层保留其余网络,进行初始视觉特征图提取。
[0031]
步骤3,将n个视图的初始视觉特征图z={z1,z2,...,zn}输入到视图重要性网络,视图重要性网络将对每一个视图进行打分,如公式(1),
[0032]
score=softmax{f(z1),f(z2),...,f(zn)},
ꢀꢀꢀ
(1)
[0033]
公式(1)中,f代表为视图重要性打分的网络层,通过训练,该网络层能够根据视图特征的信息丰富度为视图的重要性打分,由此可以将包含视觉特征信息丰富的特征进行突出;sofimax函数确保各视图的重要性总和为1,避免出现视图重要性分数差异悬殊;视图的初始特征图将与其重要性相乘,并与其初始特征图相加,如公式(2),
[0034]
pi=zi scorei*zi,
ꢀꢀꢀ
(2)
[0035]
公式(2)中,zi为该物体的第i个视图的初始视觉特征图,scorei表示视图重要性网络对第i个视图重要性的打分。每个视图的初始特征图与其重要性相乘,并与其初始特征图相加,得到三维物体n个视图增强特征图p={p1,p2,...,pn},pi∈rc×h×w,p∈rn×c×h×w。
[0036]
如图2所示,图中展示了视图重要性网络对原始三维物体飞机渲染后的十二个不同视角的重要性赋值的样例,使用视图重要性网络的目的在于,让有利于三维物体识别、包含物体丰富信息的视图获得更多的关注,同时对缺乏物体显著特征的视图赋予较低的权值,进而减少了干扰。
[0037]
步骤4包括以下子步骤:
[0038]
步骤4-1,将视图增强特征图p={p1,p2,...,pn}分别输入到三个卷积网络,生成新的特征映射pq,pk和pv,pq,pk,pv∈rn×c×h×w。将pk进行转置操作,并与pq进行矩阵相乘,获得特征图在空间上的关联关系,如公式(3),
[0039][0040]
公式(3)中,s代表相似度,i和m为视角的索引,其中i,m∈[1,n],n为视角数,由于h与w数值相等,因此l2表示单个视角特征图中所有的空间位置,综上,s
im
包含了任一视角下任一空间位置的视图增强特征与所有视角中的任一空间位置的特征的关系,关联关系越强,则在矩阵中的权值越大。
[0041]
步骤4-2,将s
im
与pv进行矩阵相乘,得到跨视角增强特征图a={a1,a2,...,an},ai∈rc×h×w,a∈rn×c×h×w。通过自注意力机制,打破了特征的局部性,实现了跨视角的非局部特征增强,使任一视角的任一空间上的特征表示更加丰富,有效增强了视图特征的表达。
[0042]
如图3所示,图中展示了自注意力机制进行跨视角的非局部特征增强的样例,对于输入的n个视角的特征将输入到θ,和g三个卷积层网络进行特征映射,分别获得到pq,pk和pv。pq与转置后的pk进行矩阵相乘,获得相似度矩阵,相似度矩阵包含了每个空间位置的特征与其他空间位置特征的关系。通过将相似度矩阵与pv进行相乘,实现跨视角的非局部特征增强,输出n个视角的特征。
[0043]
步骤5,将跨视角增强特征图a={a1,a2,...,an}通过1*1卷积进行降维,其中1*1卷积通过跨视角的方式对特征进行了提取,避免了最大池化所带来的信息丢失问题。降维后的特征将输入到全连接层进行分类,实现三维物体的识别。
[0044]
本实施例中,还对本发明的一种视图重要性网络与自注意力机制相结合的三维物体识别方法进行对比实验来评估分类识别效果。我们选取了三维物体识别常用的普林斯顿大学开源的modelnet40数据集进行实验与评估,modelnet40数据集包含了40个类别,12311个三维物体的模型,其中有9843个被划为训练集,2468个被划为测试集。modelnet40数据集中的样本数量在不同的类之间是不相等的,因此我们遵从了其他工作中报告的平均实例精度(inst acc)和平均类精度(class acc)两个指标,其中平均实例精度(inst acc)计算所有样本中正确预测的百分比,而平均类精度(class acc)是每个类别精度的平均值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。