基于cuda加速的平滑薄板样条形变参数计算方法
技术领域
1.本发明涉及图像配准、并行化加速技术领域,具体来说是基于cuda加速的平滑薄板样条形变参数计算方法。
背景技术:
2.将图像扭曲到标准坐标空间对于许多与图像计算相关的任务至关重要。然而,对于多维和高分辨率图像,精确的形变操作对于在计算机内存消耗很大,计算时间也非常的长。对于高通量图像分析研究,如大脑映射项目,需要具有与常见图像分析管道兼容的高性能图像扭曲工具。
3.图像配准可以通过多种方法实现,一些最常用的方法包括高斯平滑和热扩散,b样条方法和薄板样条(tps)方法。与tps相比,前三种方法需要额外的参数,但通常会产生不太精确的翘曲结果。tps形变的目标是求解一个函数 f,使得f(pi)=pi’(1≤i≤n),并且弯曲能量函数最小,同时图像上的其它点也可以通过插值得到很好的校正。可以把形变函数想象成弯折一块薄钢板,使这块钢板穿过给定的n个点,形变公式可表示如下:
[0004][0005]
其中uj为形变方法,c0为模板点,a为仿射分量,wk为非仿射分量, u(r)=r2log(r)为tps核函数,pi为模板点坐标,p为待配准点坐标。
[0006]
但是tps在拟合图像时候常常会出现较大的失真,局部会出现不切实际的形变,wahba等人在1990提出了平滑薄板样条形变方法(stps)通过添加平滑分量解决了这些问题,但当控制点数在几百、几千(这在当前的生物显微图像配准任务中很常见)时,仍然需要较长的时间来完成计算过程。
[0007]
而且现阶段为了得到更好的配准结果,通常通过迭代循环几百次甚至几千次来提高配准精度,这使得整个过程的时间代价无比高昂,一些很强大的工作站运行起来也很吃力。
[0008]
因此,如何实现在保证精度的同时,能够实现快速形变的平滑薄板样条形变方法已经成为急需解决的技术问题。
技术实现要素:
[0009]
本发明的目的是为了解决现有技术中平滑薄板样条形变在图像配准任务中控制点数较多(几百乃至几千)时计算时间长的缺陷,提供一种基于cuda 加速的平滑薄板样条形变参数计算方法来解决上述问题。
[0010]
为了实现上述目的,本发明的技术方案如下:
[0011]
一种基于cuda加速的平滑薄板样条形变参数计算方法,包括以下步骤:
[0012]
三维待配准特征点和模板特征点的处理:获取输入的n组待配准特征点和模板特征点,对其计算出每个待配准的特征点到每个模板特征点之间的距离,并放入尺寸为n
×n矩阵u中,将待配准特征点的三维坐标分别放入尺寸为 n
×
n的矩阵x中,将模板特征点的三维坐标放入尺寸为n
×
4的矩阵y中;
[0013]
对待配准点矩阵进行qr分解:利用基于cuda的cusolver中的函数、正交拓展核函数,对矩阵x进行qr分解得到q矩阵和r矩阵;
[0014]
平滑薄板样条形变参数的计算:利用矩阵u和y以及上步得到的矩阵q、r,在cuda中设计出适用于计算的乘法核函数,并基于cuda的cublas中的函数,分别计算得到平滑薄板样条形变的仿射分量和非仿射分量,得到平滑薄板样条形变参数。
[0015]
所述对待配准点矩阵进行qr分解包括以下步骤:
[0016]
基于cuda的cusolver库中的qr分解函数对矩阵x进行qr分解得到q矩阵和r矩阵,其表达式如下:
[0017][0018]
此时的q矩阵只有前四列有值且为正规正交、其余列为0,r矩阵只有前四行有值,尺寸为n
×
4,q1为q的前四列,尺寸为n
×
4,q2为需要拓展的部分,尺寸为n
×
(n-4),r1为r的前四列前四行,尺寸为4
×
4;
[0019]
基于cuda所设计的拓展正交核函数完成对矩阵q的拓展正交,从第五列开始填充;填充第i列时,采用以下步骤,i≥5:
[0020]
求得q的每一行的和再得到其平方根,得到值最小的一行的行号k;
[0021]
将q传入gpu中,分配n个线程,对应第i列的每一个元素;
[0022]
第n个线程计算内容为:q的第一列至第i-1列的第n行乘以第k行的第一到第i-1个元素;
[0023]
所有线程执行完毕得到扩充的第i列初始的值,将得到的结果从gpu中拿出放入尺寸为n
×
1矩阵t;
[0024]
将t的第k个元素加1,再将t归一化,填充到q的第i列;
[0025]
计算得到正规正交的q矩阵。
[0026]
所述平滑薄板样条形变参数的计算包括以下步骤:
[0027]
利用以下公式及基于cuda的cublas库函数、基于cuda设计的矩阵乘法核函数完成仿射分量以及非仿射分量的计算,其计算公式如下:
[0028][0029][0030]
其中b=c λi,尺寸为n
×
4的w为非仿射分量,λ为平滑系数,尺寸为(n-4)
×
(n-4)的i为单位矩阵,尺寸为4
×
4的a为仿射分量;
[0031]
对w进行计算:
[0032]
使用cuda完成u、q2的相乘得到尺寸为(n-4)
×
(n-4)的矩阵c;
[0033]
将上一步计算的结果加上与平滑系数相乘的i矩阵得到尺寸为 (n-4)
×
(n-4)矩阵b,并利用基于cuda中的cusolver库中的函数得到b的逆矩阵;
[0034]
使用cuda完成q2、b-1
、的乘积得到尺寸为n
×
n的矩阵d,
[0035]
首先转换输入的矩阵q2、b-1
为一维数组,再分配n
×
(n-4)个线程,将核函数中的blockdim固定设置为二维block尺寸为32*32;
[0036]
每个线程对应有唯一的行号和列号,其行号范围为0到n,列号范围0到 n-4,与矩阵q2b-1
大小相对应;
[0037]
每个线程计算出矩阵q2b-1
的一个元素,线程号(m,n)的线程计算矩阵q2b-1
第m行第n列的元素,
[0038]
方法为q2的第m行乘以b-1
的第n列得到对应位置的元素;
[0039]
再分配n
×
n个线程,将核函数中的blockdim固定设置为二维block尺寸为32*32;
[0040]
每个线程对应有唯一的行号和列号,其行号范围为0到n,列号范围0到 n,与矩阵大小相对应;
[0041]
每个线程计算出矩阵的一个元素,线程号(m,n)的线程计算矩阵第m行第n列的元素,方法为q2b-1
的第m行乘以的第n列得到对应位置的元素,其中的第m行即为q2的第m列,把行索引转换为q2列索引,以此减少一个输入;最后得到矩阵d;
[0042]
在cpu上完成d和y的相乘得到非仿射分量w;
[0043]
在cpu上完成a的计算,得到仿射分量,至此得到所有平滑薄板样条形变参数。
[0044]
所述进行矩阵c的计算包括以下步骤:
[0045]
将输入的矩阵u、q2转换成一维数组,在gpu中分配(n-4)
×
n个线程,并将核函数中的blockdim固定设置为二维block尺寸为32*32;
[0046]
设定每个线程对应有唯一的行号、列号,其行号范围为0到n-4,列号范围0到n,与矩阵大小相对应;
[0047]
设定线程号(m,n)的线程计算矩阵第m行第n列的元素,
[0048]
其方法为的第m行乘以u的第n列,其中的第m行即为q2的第m列,把行索引转换为q2列索引,以此减少一个输入;
[0049]
再分配(n-4)
×
(n-4)个线程,将核函数中的blockdim固定设置为二维block 尺寸为32*32;
[0050]
设定每个线程对应有唯一的行号和列号,其行号范围为0到n-4,列号范围0到n-4,与矩阵大小相对应;
[0051]
设定每个线程计算出矩阵的一个元素,线程号(m,n)的线程计算矩阵第m行第n列的元素,
[0052]
其方法为的第m行乘以u的第n列得到对应位置的元素;
[0053]
最后得到矩阵c。
[0054]
有益效果
[0055]
本发明的基于cuda加速的平滑薄板样条形变参数计算方法,与现有技术相比利用gpu的并行架构对大矩阵代数运算做了并行化,实现了平滑薄板样条形变参数快速计算,有效提升了图像配准算法的运行效率。
[0056]
实验证明本方法在cpu为i7-10700f、gpu为rtx-2080的平台下获得了大约9倍的加速比,极大的缩短了形变时间。
附图说明
[0057]
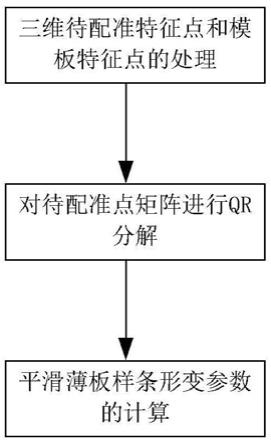
图1为本发明的方法顺序图。
具体实施方式
[0058]
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
[0059]
如图1所示,本发明所述的一种基于cuda加速的平滑薄板样条形变参数计算方法,包括以下步骤:
[0060]
第一步,三维待配准特征点和模板特征点的处理。
[0061]
获取输入的n组待配准特征点和模板特征点,对其计算出每个待配准的特征点到每个模板特征点之间的距离,并放入尺寸为n
×
n矩阵u中,将待配准特征点的三维坐标分别放入尺寸为n
×
n的矩阵x中,将模板特征点的三维坐标放入尺寸为n
×
4的矩阵y中。
[0062]
第二步,对待配准特征点矩阵进行qr分解:利用基于cuda的cusolver 中的函数、正交拓展核函数,对矩阵x进行qr分解得到q矩阵和r矩阵。通过分析算法的时间消耗多的部分将其放入gpu中计算,利用gpu自身的硬件优势可以快速计算出对应的q矩阵和r矩阵,相较于传统cpu算法可以节省大量时间。其具体步骤如下:
[0063]
(1)基于cuda的cusolver库中的qr分解函数对矩阵x进行qr分解得到q矩阵和r矩阵,其表达式如下:
[0064][0065]
此时的q矩阵只有前四列有值且为正规正交、其余列为0,r矩阵只有前四行有值,尺寸为n
×
4,q1为q的前四列,尺寸为n
×
4,q2为需要拓展的部分,尺寸为n
×
(n-4),r1为r的前四列前四行,尺寸为4
×
4。
[0066]
(2)基于cuda所设计的拓展正交核函数完成对矩阵q的拓展正交,从第五列开始填充;填充第i列时,采用以下步骤,i≥5:
[0067]
a1)求得q的每一行的和再得到其平方根,得到值最小的一行的行号k;
[0068]
a2)将q传入gpu中,分配n个线程,对应第i列的每一个元素;
[0069]
第n个线程计算内容为:q的第一列至第i-1列的第n行乘以第k行的第一到第i-1个元素;
[0070]
所有线程执行完毕得到扩充的第i列初始的值,将得到的结果从gpu中拿出放入尺寸为n
×
1矩阵t;
[0071]
a3)将t的第k个元素加1,再将t归一化,填充到q的第i列。
[0072]
(3)计算得到正规正交的q矩阵。
[0073]
第三步,平滑薄板样条形变参数的计算:利用矩阵u和y以及上步得到的矩阵q、r1,在cuda中设计出适用于计算的乘法核函数,并基于cuda的cublas 中的函数,分别计算得到
平滑薄板样条形变的仿射分量和非仿射分量,得到平滑薄板样条形变参数。由于大矩阵乘法在cpu中计算耗时较大,且计算时矩阵内的每个元素的计算都互不干扰,所以可以并行运算进而可节省大量运算时间。本发明根据算法公式设计核函数将矩阵乘法放入核函数中,并且通过修改数据索引使得输入减少,节省数据传入时间。且基于cuda的cublas中的函数完成矩阵求逆,简洁方便。其具体步骤如下:
[0074]
(1)利用以下公式及基于cuda的cublas库函数、基于cuda设计的矩阵乘法核函数完成仿射分量以及非仿射分量的计算,其计算公式如下:
[0075][0076][0077]
其中b=c λi,尺寸为n
×
4的w为非仿射分量,λ为平滑系数,尺寸为(n-4)
×
(n-4)的i为单位矩阵,尺寸为4
×
4的a为仿射分量。
[0078]
(2)对w进行计算:
[0079]
a1)使用cuda完成u、q2的相乘得到尺寸为(n-4)
×
(n-4)的矩阵c;进行矩阵c的计算:先将u、q2一行一行换成一维数组传入gpu中,在gpu中分配(n-4)
×
(n-4)个线程,并将核函数中的blockdim固定设置为32*32。
[0080]
进行矩阵c的计算包括以下步骤:
[0081]
a11)将输入的矩阵u、q2转换成一维数组,在gpu中分配(n-4)
×
n个线程,并将核函数中的blockdim固定设置为二维block尺寸为32*32;
[0082]
a12)设定每个线程对应有唯一的行号、列号,其行号范围为0到n-4,列号范围0到n,与矩阵大小相对应;
[0083]
a13)设定线程号(m,n)的线程计算矩阵第m行第n列的元素,
[0084]
其方法为的第m行乘以u的第n列,其中的第m行即为q2的第m列,把行索引转换为q2列索引,以此减少一个输入;
[0085]
a14)再分配(n-4)
×
(n-4)个线程,将核函数中的blockdim固定设置为二维 block尺寸为32*32;
[0086]
a15)设定每个线程对应有唯一的行号和列号,其行号范围为0到n-4,列号范围0到n-4,与矩阵大小相对应;
[0087]
a16)设定每个线程计算出矩阵的一个元素,线程号(m,n)的线程计算矩阵第m行第n列的元素,
[0088]
其方法为的第m行乘以u的第n列得到对应位置的元素;
[0089]
a17)最后得到矩阵c。
[0090]
a2)将上一步计算的结果加上与平滑系数相乘的i矩阵得到尺寸为 (n-4)
×
(n-4)矩阵b,并利用基于cuda中的cusolver库中的函数得到b的逆矩阵;
[0091]
a3)使用cuda完成q2、b-1
、的乘积得到尺寸为n
×
n的矩阵d,
[0092]
首先转换输入的矩阵q2、b-1
为一维数组,再分配n
×
(n-4)个线程,将核函数中的
blockdim固定设置为二维block尺寸为32*32;
[0093]
每个线程对应有唯一的行号和列号,其行号范围为0到n,列号范围0到n-4,与矩阵q2b-1
大小相对应;
[0094]
每个线程计算出矩阵q2b-1
的一个元素,线程号(m,n)的线程计算矩阵q2b-1
第m行第n列的元素,
[0095]
方法为q2的第m行乘以b-1
的第n列得到对应位置的元素;
[0096]
再分配n
×
n个线程,将核函数中的blockdim固定设置为二维block尺寸为32*32;
[0097]
每个线程对应有唯一的行号和列号,其行号范围为0到n,列号范围0到 n,与矩阵大小相对应;
[0098]
每个线程计算出矩阵的一个元素,线程号(m,n)的线程计算矩阵第m行第n列的元素,其中原理为q2b-1
的第m行乘以的第n列得到对应位置的元素,其中的第m行即为q2的第m列,把行索引转换为q2列索引,以此减少一个输入;最后得到矩阵d。
[0099]
(3)在cpu上利用传统方法完成d和y的相乘得到非仿射分量w;
[0100]
(4)在cpu上利用传统方法完成a的计算,得到仿射分量,至此得到所有平滑薄板样条形变参数。
[0101]
如表1所示,其为在1742组控制点下基于gpu加速的平滑薄板样条形变的运行时间结果示意表。
[0102]
表1 1742组控制点下基于gpu加速的平滑薄板样条形变的运行时间结果示意表
[0103]
点数:1742组第一次形变时间第二次形变时间第三次形变时间平均形变时间未加速25.83s26.26s26.18s26.09s加速之后3.01s2.96s3.08s3.01s
[0104]
从表1可以看出,基于在cpu为i7-10700f、gpu为rtx-2080的平台下完成,在控制点数为1742时对实验结果与未加速的实验结果做了对比,加速比可达到约9倍。
[0105]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。