1.本发明涉及自然语言处理技术领域,具体是一种基于多任务框架的方面词和方面类别联合抽取和检测方法。
背景技术:
2.基于方面的情感分析(aspect-based sentiment analysis,简称absa)的基本任务是分析出评论中用户针对特定对象所表达的情感的极性。absa任务中又可以细分出多个子任务。从目标识别角度,针对方面词和观点词,存在抽取问题;针对方面类别,存在分类问题。从情感分析角度,对方面词和方面类别存在情感分类问题。以这句评论为例:“waiters are very friendly and the pasta is simply average.”,该评论中提到了两个方面词:“waiter”和“pasta”,而对这两个方面表达的情感极性分别为“积极的”和“消极的”,同时这两个方面词所属的类别分别为“service”和“food”。
3.近期的许多研究者都采用多任务框架来将absa任务的子任务结合在一起,以此来提升模型在absa任务中的性能。目前大多数现有工作都只是将方面词抽取任务(aspect term extraction,简称ate)和观点词抽取任务(opinion target extraction,简称ote)相结合,进行联合抽取,这种方法有助于模型更快更精确地抽取出具体的方面词。但是这些方法忽略了方面类别检测任务(aspect category detection,简称acd)对absa任务的贡献。我们认为ate任务和acd任务都是分类任务,二者具有很强的相似性,可以结合在一起。其次方面词和方面类别之间存在语义对齐信息,可以对文本进行不同粒度的特征建模,从而提高模型抽取性能。
4.在考虑文本内在的语法和句法信息方面,大部分现有工作只考虑了句子的语法依赖信息,而文本中还存在词共现信息。词共现信息可以从语料库中提取出词语的搭配信息,并辐射到文本中,从而帮助模型更精确的抽取出方面词。此外,词共现信息还有助于模型在ate任务中检测出含多个单词的方面词的边界。例如在评论“waiters are friendly and the fugu sashimi is out of the world.”中,“fugu”和“sashimi”这两个在语料库中共现了5次,代表着一个特定食物的名称。如果没有词共现信息的帮助,模型可能会将“fugu”或者“sashimi”当作两个方面词,从而做出错误的预测。
技术实现要素:
5.本发明的目的是针对现有技术的不足,而提供一种基于多任务框架的方面词和方面类别联合抽取和检测方法。这种方法提升了模型在任务中的性能,提高了模型的捕捉能力。
6.实现本发明目的的技术方案是:
7.一种基于多任务框架的方面词和方面类别联合抽取和检测方法,包括如下步骤:
8.步骤1、采用预训练的bert模型对文本进行编码,得到文本嵌入表示;
9.步骤2、利用双向长短时记忆网络对文本嵌入表示进行正反两个方向的时序建模,
提取文本中的序列信息,生成文本特征表示,分别用于后续的ate和acd两个任务;
10.针对ate任务:
11.步骤3、利用多层图卷积神经网络将词共现矩阵和依赖树矩阵与步骤2得到的文本特征表示融合,生成ate文本特征表示;
12.步骤4、将ate文本特征表示输入到ate共享向量生成器中,得到ate共享向量,用于将ate任务信息传递到acd任务中;
13.步骤5、利用多头注意力机制将acd任务的信息整合进ate文本特征表示中,生成最终的ate文本表示;
14.步骤6、利用条件随机场对ate最终文本表示进行序列标注;
15.针对acd任务:
16.步骤7、利用门控机制将ate任务中的信息整合进acd文本表示中,生成acd文本特征表示;
17.步骤8、将acd文本特征表示输入到acd共享向量生成器中,得到acd共享向量,用于将acd任务信息传递到ate任务中;
18.步骤9、利用多头注意力机制将ate任务的信息整合进acd文本特征表示中,生成最终的acd文本表示;
19.步骤10、通过多标签分类器对acd最终文本表示进行标签预测。
20.步骤1中所述的预训练的bert模型把文本序列作为输入,并将序列中的每个单词都映射为一个词向量,最终得到文本嵌入表示。
21.步骤2中所述的双向长短时记忆网络以文本嵌入表示作为输入,先对文本嵌入表示进行正向的时序建模,提取正向序列的上下文信息,生成正向序列向量,随后对文本嵌入表示进行反向的时序建模,抽取反向序列的上下文信息,生成反向序列向量,最后将两个向量拼接得到文本特征表示,用于后续的ate和acd任务。
22.步骤3中所使用的依赖树矩阵是通过stanford nlp解析器得到,词共现矩阵是通过对网络上公开数据集内的数据进行统计,并构建矩阵得到。
23.步骤3中所述的利用多层图卷积神经网络将词共现矩阵和依赖树矩阵整合生成ate文本表示的具体步骤如下:
24.步骤3.1、利用图卷积神经网络将ate文本表示与文本的句法依赖矩阵进行卷积,生成融合了句法依赖信息的ate文本表示;
25.步骤3.2、利用图卷积神经网络将融合了句法依赖信息的ate文本表示与文本的词共现矩阵进行卷积,生成融合了词共现信息的ate文本特征表示。
26.步骤3中所述的多层图卷积神经网络包含多个层,除第一层是将步骤2得到的ate文本表示作为输入外,每一层图卷积神经网络都将上一层的输出作为该层输入。
27.步骤4中所述的ate共享向量生成器和步骤8中所述的acd共享向量生成器分别对输入的ate文本特征表示或acd文本特征表示进行最大池化操作,以此得到ate共享向量和acd共享向量。
28.步骤5中所述的多头注意力机制将acd共享向量作为查询矩阵,将ate文本特征表示作为键矩阵和值矩阵,获得最终的ate文本表示。
29.步骤7中所述的门控机制先是利用sigmoid函数计算ate共享向量对于acd文本表
示中每个单词向量的贡献度,然后通过加权求和的方式将acd共享向量和acd文本表示整合在一起,得到acd文本特征表示。
30.步骤9中所述的多头注意力机制将ate共享向量作为查询矩阵,将acd文本特征表示作为键矩阵和值矩阵,获得最终的acd文本表示。
31.与现有技术相比,本技术方案的有益效果是:
32.1.本技术方案提出通过多任务学习的方式同时进行方面词抽取和方面类别检测两个任务,并让两个任务相互影响,相互增强,从而提升模型在两个任务中的性能;
33.2.本技术方案在引入文本的语法依赖树的基础上,还引入了词共现信息,从而帮助模型更准确的检测出包含多个单词的方面词的边界,提升了模型在ate任务中的性能;
34.3.本技术方案设计了以共享向量的方式让ate任务和acd任务进行交互,对文本进行不同粒度的特征建模。同时设计以多头注意力的方式让文本特征表示从共享向量中学习不同任务提取出的特征信息,提高模型对文本中重要特征的捕捉能力。
35.这种方法提升了模型在任务中的性能,提高了模型的捕捉能力。
附图说明
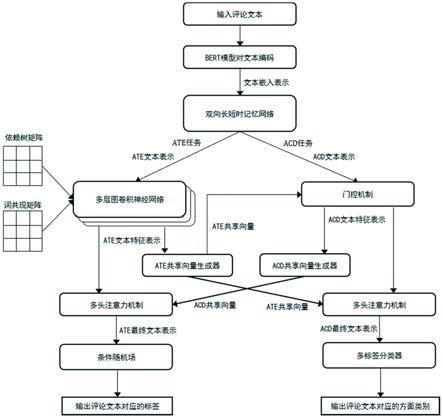
36.图1为实施例的流程示意图。
具体实施方式
37.下面结合附图及具体实施例对本发明作进一步的详细描述,但不是对本发明的限定。
38.实施例:
39.参照图1,一种基于多任务框架的方面词和方面类别联合抽取和检测方法,包括如下步骤:
40.步骤1、采用预训练的bert模型对文本进行编码,得到文本嵌入表示,即文本序列s={w1,w2,...,wn}作为预训练的bert模型的输入,bert模型会将目标单词投射到词向量空间中,同时整合周围上下文词的信息,从而生成文本嵌入表示e={e1,e2,...,en},其中n为句子长度,ei∈r
emb_dim
,emb_dim表示词嵌入的维度;
41.本例为了使bert模型能够更好地训练和微调,在文本序列的头部加上分类标识符“[cls]”,在尾部加上分隔标识符“[sep]”,如:“[cls] text [sep]”;
[0042]
步骤2、利用双向长短时记忆网络对文本嵌入表示进行正反两个方向的时序建模,提取文本中的序列信息,生成文本特征表示,分别用于后续的ate和acd两个任务;
[0043]
本例双向长短时记忆网络(bi-lstm)以文本嵌入表示作为输入,双向长短时记忆网络包含正向和反向的长短时记忆网络(lstm),长短时记忆网络的具体公式如下:
[0044]ft
=σ(wf·
[h
t-1
,e
t
] bf)
[0045]it
=σ(wi·
[h
t-1
,e
t
] bi)
[0046][0047][0048]ot
=σ(wo·
[h
t-1
,e
t
] bo)
[0049]ht
=o
t
*tanh(c
t
)
[0050]
其中,f
t
、i
t
和o
t
分别是lstm中t时刻遗忘门、记忆门和输出门的输出,σ是sigmoid激活函数,wf、wi和wo分别是遗忘门、记忆门和输出门的可学习的参数矩阵,bf、bi和bo分别是遗忘门、记忆门和输出门的偏置,和c
t
是t时刻的临时细胞状态和t时刻的细胞状态,h
t
是t时刻lstm输出的隐藏状态;
[0051]
正向lstm先对文本嵌入表示进行正向的时序建模,即从w1到wn的顺序,提取正向序列的上下文信息,生成正向序列向量,具体公式如下:
[0052][0053]
其中和分别表示t-1和t时刻正向lstm的输出,
[0054]
随后反向lstm对文本嵌入表示进行反向的时序建模,抽取反向序列的上下文信息,生成反向序列向量,具体公式如下:
[0055][0056]
其中和分别表示t-1和t时刻反向lstm的输出,
[0057]
最后将两个向量拼接得到文本表示h
t
,用于后续的ate和acd任务,具体公式如下:
[0058][0059]
最终得到文本表示h={h1,h2,...,hn};
[0060]
针对ate任务:
[0061]
步骤3、利用多层图卷积神经网络将词共现矩阵和依赖树矩阵与步骤2得到的文本特征表示融合,生成ate文本特征表示,具体步骤如下:
[0062]
步骤3.1、利用图卷积神经网络将ate文本表示h作为多层图卷积神经网络(gcn)的第0层输入,与文本的句法依赖矩阵d进行卷积,生成融合了句法依赖信息的ate文本表示,具体公式如下:
[0063][0064]
其中,依赖树矩阵是通过stanford nlp解析器得到,是第/层得到的ate文本表示中的第i个单词,是第/-1层gcn的输出中的第j个单词,d
ij
表示句法依赖矩阵中第i和第j个单词之间的依赖信息,di表示句法依赖矩阵中第i个单词的度,权重矩阵wd和偏置bd都是可学习的参数;
[0065]
步骤3.2、利用图卷积神经网络将融合了句法依赖信息的ate文本表示与文本的词共现矩阵a进行卷积,生成融合了词共现信息的ate文本特征表示的具体公式如下:
[0066]
[0067]
其中,词共现矩阵是通过对网络上公开数据集内的数据进行统计,并构建矩阵得到,a
ij
表示词共现矩阵中第i和第j个单词之间的共现信息;
[0068]
步骤4、将ate文本特征表示输入到ate共享向量生成器中,并对ate文本特征表示进行最大池化操作,具体公式如下:
[0069][0070]
得到ate共享向量,用于将ate任务信息传递到acd任务中;
[0071]
步骤5、利用多头注意力机制将acd任务的信息整合进ate文本特征表示中,多头注意力机制将acd共享向量作为查询矩阵,将ate文本特征表示h
ate
作为键矩阵和值矩阵,获得最终的ate文本表示具体公式如下:
[0072][0073]
其中,mha表示多头注意力机制;
[0074]
步骤6、利用条件随机场对ate最终文本表示进行序列标注,即将最终的ate文本表示作为观察序列,y={y1,y2,...yn}是对应于观察序列的标记序列,其中yi∈l={b,i,o},l是标签集,通过crf构建观察序列和标记序列之间的条件概率模型p(y|v
ate
),具体公式如下:
[0075][0076]
其中,tj(y
i 1
,yi,v
ate
,i)是定义在观测序列的两个相邻标记位置上的转移特征函数,sk(yi,v
ate
,i)是定义在观测序列的标记位置上的状态特征函数,z是规范化因子,λj和μk是可学习的参数;
[0077]
对于训练集通过最大化条件似然估计来训练crf模型,具体公式如下:
[0078][0079]
在通过训练得到参数λj和μk后,根据p(y|v
ate
)和v
ate
求出条件概率最大的序列,具体公式如下:
[0080]y*
=argmaxp
y∈l
(y|v
ate
,λ,μ),
[0081]
就是预测出的文本对应的标签序列;
[0082]
针对acd任务:
[0083]
步骤7、利用门控机制将ate任务中的信息整合进acd文本表示中,生成acd文本特征表示;
[0084]
本例门控机制先是利用sigmoid函数计算ate共享向量对于acd文本表示h中每个单词向量的贡献度ai,具体公式如下:
[0085][0086]
其中,hi是文本表示中的第i个单词,和是权重矩阵,bs是偏置,
[0087]
然后通过加权求和的方式将acd共享向量和acd文本表示整合在一起,得到acd文本特征表示具体公式如下:
[0088][0089]
其中,代表按位乘法;
[0090]
步骤8、将acd文本特征表示输入到acd共享向量生成器中,并对acd文本特征表示进行最大池化操作,得到acd共享向量,具体公式如下:
[0091][0092]
用于将acd任务信息传递到ate任务中;
[0093]
步骤9、利用多头注意力机制将ate任务的信息整合进acd文本特征表示中,其中多头注意力机制将ate共享向量作为查询矩阵,将acd文本特征表示h
acd
作为键矩阵和值矩阵,生成最终的acd文本表示具体公式如下:
[0094][0095]
其中,mha表示多头注意力机制;
[0096]
步骤10、通过多标签分类器对acd最终文本表示进行标签预测,多标签分类器中包含一个全连接层和一个softmax函数,先利用全连接层将最终的acd文本表示v
acd
映射到数据集的方面类别空间中,然后通过softmax函数计算出文本所包含的方面类别,具体公式如下:
[0097]
yc=softmax(w
cvacd
bc),
[0098]
其中,是文本对应的方面类别概率,代表文本包含第i个方面类别的概率,m是数据集中所含方面类别的个数,wc,bc分别为权重矩阵和偏置。
[0099]
步骤3中所述的多层图卷积神经网络包含多个层,除第一层是将步骤2得到的ate文本表示作为输入外,每一层图卷积神经网络都将上一层的输出作为该层输入。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。