1.本技术涉及通信技术领域,尤其涉及一种词语相似度确定方法、装置、存储介质及计算机设备。
背景技术:
2.近年来,随着互联网信息技术的不断进步,智能语音功能得到了越来越多的应用。例如利用智能语音功能控制智能家电等。比如,对于智能电视来说,智能语音功能可用于搜索电视剧/电影/短视频等,尤其是对于识字不多的小孩或者老人,智能语音功能提供了较大的便利。
3.当用户使用智能语音功能搜索影片时,通常通过识别语音信息中的标签,将标签与媒资标签体系中的媒资标签进行比对,以返回与对应标签匹配的媒资标签所对应的影片。通常,媒资标签体系较为固定,例如包括喜剧、家庭伦理、校园、恐怖、战争等。
4.由于利用智能语音功能进行搜索的用户语言习惯不同、用户对象也差异较大,在进行搜索时,用户的高频话术中的标签,与媒体标签体系中书面化表达的媒资标签可能不一致,如用户习惯于查找“打仗片”,而媒体标签中的对应为“战争片”,从而导致无法正确匹配;而且存在大量用户语音中的标签与媒资标签体系中的媒资标签意义相似,但不完全相同,从而不能很好匹配,导致降低媒资数据返回的质量和数量,降低了数据匹配的准确性。
技术实现要素:
5.本技术实施例提供一种词语相似度确定方法、装置、存储介质及计算机设备,能提高词语相似度确定的准确性,提高数据匹配的准确性。
6.本技术实施例提供了一种词语相似度确定方法,包括:
7.获取需确定相似度的第一词语和第二词语;
8.基于同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合;
9.基于同义词词林确定第一义项集合中处于叶子结点的第一义项在所述叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在所述叶子结点中的同义词义项集合,作为第二同义词义项集合;
10.根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度;
11.根据所述义项相似度确定所述第一词语和所述第二词语之间的相似度。
12.本技术实施例还提供了一种词语相似度确定装置,包括:
13.获取模块,用于获取需确定相似度的第一词语和第二词语;
14.第一义项确定模块,用于基于同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合;
15.第二义项确定模块,用于基于同义词词林确定第一义项集合中处于叶子结点的第一义项在所述叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在所述叶子结点中的同义词义项集合,作为第二同义词义项集合;
16.第一相似度确定模块,用于根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度;
17.第二相似度确定模块,用于根据所述义项相似度确定所述第一词语和所述第二词语之间的相似度。
18.本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有多条指令,所述指令适于由处理器加载以执行上述任一项词语相似度确定方法。
19.本技术实施例还提供了一种计算机设备,包括处理器和存储器,所述处理器与所述存储器电性连接,所述存储器用于存储指令和数据,所述处理器用于上述任一项所述的词语相似度确定方法中的步骤。
20.本技术提供的词语相似度确定方法、装置、存储介质及计算机设备,通过同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合,并确定第一义项集合中处于叶子结点的第一义项在叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在叶子结点中的同义词义项集合,作为第二同义词义项集合,根据第一义项集合中各第一义项和第二义项集合中的各第二义项、以及第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度,根据义项相似度来确定第一词语和第二词语之间的相似度。本技术实施例中的词语相似度确定的方案中第一义项与第二义项之间的义项相似度的确定不仅考虑了第一义项和第二义项本身,同时还考虑了处于叶子结点的第一义项和处于叶子结点的第二义项的同义词义项集合,即还考虑了处于叶子结点的第一义项和第二义项所在叶子结点中编码为“=”的其他义项的集合,由于叶子结点中同义词义项包括的信息较多,且同义词义项与对应的第一义项和第二义项表达的意思相近,如此,利用同义词义项集合来增强对第一义项和第二义项的相似度的影响,改善了若第一义项和第二义项属于同义词词林下的不同大类分支,义项相似度极低的情况,提高了词语相似度确定的准确性,进一步提高数据匹配的准确性。
附图说明
21.下面结合附图,通过对本技术的具体实施方式详细描述,将使本技术的技术方案及其它有益效果显而易见。
22.图1为本技术实施例提供的同义词词林的示意图。
23.图2为本技术实施例提供的词语相似度确定方法的流程示例图。
24.图3为本技术实施例提供的词语相似度确定方法的子流程示意图。
25.图4为本技术实施例提供的确定最短路径长度的示意图。
26.图5为本技术实施例提供的确定两义项相似度的示意图。
27.图6为本技术实施例提供的确定两词语相似度的示意图。
28.图7为本技术实施例提供的词语相似度确定装置的结构示意图。
29.图8为本技术实施例提供的计算机设备的结构示意图。
30.图9为本技术实施例提供的计算机设备的另一结构示意图。
具体实施方式
31.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
32.本技术实施例提供一种词语相似度确定方法、装置、存储介质及计算机设备。本技术实施例提供的任一种词语相似度确定装置,可以集成在计算机设备中,该计算机设备包括终端或者服务器等设备。该终端可以包括智能手机、pad、穿戴式设备、机器人、智能电视、智能空调、智能车载设备、个人计算机(pc,personal computer)等。该服务器可以是独立的物理服务器,也可以是区块链系统中的服务结点,还可以是多个物理服务器构成的服务器集群,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(content delivery network,cdn)、以及大数据和人工智能平台等基础云计算服务的云服务器。
33.该计算机设备中提供词语(关键词)匹配功能。例如,计算机设备中提供有智能语音功能,通过接收用户语音,提取用户语音中的词语(关键词),将该词语(关键词)与预设词语(预设关键词)进行匹配,以确定相似度;或者计算机设备中提供搜索功能,根据用户输入的词语(关键词),将该词语(关键词)与预设词语(预设关键词)进行匹配,以确定相似度等,最后根据相似度以提供某项服务。其中,预设词语(预设关键词)可以是媒资标签等。
34.本技术中以同义词词林来说明词语相似度的确定。本技术中的同义词词林以哈尔滨工业大学对梅家驹等人于1983年编撰的汉语词库的同义词词林进行改进的版本为例进行说明。
35.在该版本中,同义词词林共有七万多个词语,12个大类,94个中类,1428个小类,4026个词群和17797个原子群。如图1所示,同义词词林为5层树状结构,每个结点可能存在多个词语。前四层结点代表类别,而叶子结点存放了词语及其同义词、相关词等。第一至三大类多属名词,数词和量词在第四大类中,第五类多属形容词,第六至十类多是动词,十一类多属虚词,十二类是难以被分到上述类别中的一些词语。大类和中类的排序遵照具体概念到抽象概念的原则。
36.请参看图1并结合表1,同义词词林共提供了五层编码,同义词词林中的词语的编码为8位。第二层用大写英文字母表示,占1位;第三层用小写英文字母表示,占1位;第四层为二位十进制整数表示,占二位;第五层用大写英文字母表示,占1位;第六层用二位十进制整数表示,占2位;最后一位,即第八位编码有三种情况:“=”表示“相等”、“同义”。“#”表示“不等”、“同类”、“相关”。“@”表示“自我封闭”、“独立”,它在词典中没有同义词也没有相关词。例如,“ae07c01=渔民渔翁渔家渔夫渔父打鱼郎”,其中,“ae07c01=”为义项编码,“渔民渔翁渔家渔夫渔父打鱼郎”为该类的词语。同一个词语可能在不同的类别中同时存在,即词语的义项编码不是唯一的。其中,词语含有多种语义,义项为其一种语义定义或解释。
37.表1同义词词林中词语的编码结构
[0038][0039]
在详细介绍本技术实施例中的词语相似度确定方法之前,先简单介绍下当前的基于同义词词林的词语相似度的研究情况。
[0040]
关于相似度的计算,dekang lin认为任何两个对象的相似度取决于它们的共性和个性,他从信息理论的角度给出任意两个对象相似度的通用公式,该通用公式如公式(1)所示。
[0041][0042]
其中分子是描述s1,s2共性所需要的信息量大小,分母是完整的描述出s1,s2所需要的信息量大小。dekang lin的这一理论是目前绝大多数基于语义词典的方法的词语相似度计算模型的基本思想。
[0043]
wu等人在机器翻译作词语选择问题的时候,提出了基于最近公共父结点深度和两词语义项路径长度的方法。他们定义词语的义项s1和s2的相似度计算公式如式(2)所示。
[0044][0045]
其中h为义项s1与义项s2最近公共父结点(lcp)在同义词词林中的层数,d为s1与s2在同义词词林中的最短路径长度。现有技术中,最短路径长度为s1所在的分支结点到最近公共父结点的路径长度与s2所在的分支结点到最近公共父结点的路径长度之和。之后,基于路径计算词语相似度公式多在上述(2)式上改进而得,例如,陈宏朝等人结合(2)式考虑了词林密度对义项相似度的影响,提出了对(2)的改进算法,如以下公式(3)所示。
[0046][0047]
其中α为避免根结点深度为0设定值在0-1之间,其中,i为分支结点所在层的编号,weight(i)为连接分支结点与最近公共父结点的边的权重,同义词词林中的每层所对应的边有不同权重,越靠近根层数权重越大,n表示两个义项最近公共父结点(lcp)的直接孩子的数量,k表示两个义项在最近公共父结点中的分支间距。
[0048]
以上为基于路径的词语相似度计算方法。下面将对基于信息内容的词林词语相似度计算方法进行简单的介绍。
[0049]
使用本体和信息内容的方法来计算词语相似度可以追溯到1995年resnik,即一对词语的相似度由它们的共性(即公共父结点)决定。基于此后衍生出多种广泛使用的词语相似度计算方法。resnik将两词语的相似度,通过其公共父结点的信息含量决定,并通过父结点的或然概率表示其信息含量,具体请参看公式(4)与公式(5)。
[0050]
sim
resnik
(s1,s2)=ic(lcs(s1,s2))
ꢀꢀꢀ
(4)
[0051]
ic
resnik
(c)=-log(p(c))
ꢀꢀꢀ
(5)
[0052]
其中ic(c)表示结点c的信息含量,lcs(s1,s2)表示义项s1,s2的最近公共父结点。seco等人在resnik的基础上,调整了信息含量计算方式,引入层级及下位结点数辅助计算。其中,层级越低,子结点数越少,其蕴含的信息越丰富。具体请参看公式(6)。
[0053][0054]
其中hypo(c)为c结点的子结点的数量,maxnodes为同义词词林的本体所有叶子结点数量。lin的研究在resnik基础上加入两词本身信息含量的影响;meng等人对lin的计算方法进行了非线性改进。
[0055]
现有的基于同义词词林的词语相似度计算方法单一,范围限制性强,词典外词语无法进行相似度计算(相似度为0),词性区分明显(第一至三类为名词,第四类为数词和量词,第五类多为形容词),结果具有较强主观性,直接使用已有的词语相似度计算方法,去计算媒资标签,词典覆盖不完全、词性会有很大的影响、特征(相似度)随计算方式变化而不同。
[0056]
现有基于同义词词林的词语相似度确定方法,并不能很好的体现词语的相似之处,词语相似度完全依赖路径及词林位置,对词语在不同大类下的相似之处不能很好的展现:若两义项属于同义词词林下不同大类分支,相似度极低近似为0。例如,“恋爱”、“爱情”、“言情”,对于媒资标签来说,其应为同义词,然而在现有的基于同义词词林的词语相似度确定方法中,“爱情”与“恋爱”及“言情”属于不同大类分支,“爱情”与“恋爱”及“言情”相似度较低,而“言情”与“恋爱”相似度极高,降低了词语相似度确定的准确性。
[0057]
为了解决上述问题,本技术实施例中提出了词语相似度确定方法、装置、计算机可读存储介质及计算机设备。下面将对本技术实施例中的词语相似度确定方法、装置、计算机可读存储介质及计算机设备进行详细说明。需说明的是,以下实施例的序号不作为对实施例优选顺序的限定。
[0058]
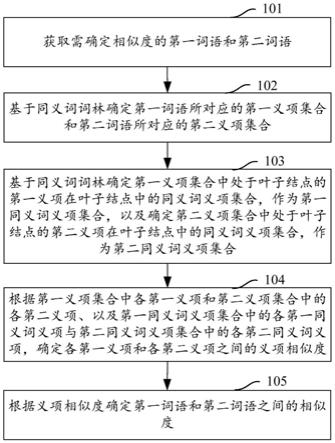
图2是本技术实施例提供的词语相似度确定方法的流程示意图,该词语相似度确定方法应用于计算机设备中,该词语相似度确定方法包括如下步骤。
[0059]
101,获取需确定相似度的第一词语和第二词语。
[0060]
其中,第一词语和第二词语可以分别是一个词语,还可以是多个词语。例如,第一词语为一个词语,第二词语为多个词语,则将第一词语与第二词语中的多个词语之间一一确定相似度。本技术实施例以第一词语和第二词语分别为一个词语为例进行说明。
[0061]
102,基于同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合。
[0062]
基于同义词词林,找到第一词语所对应的义项,将第一词语所对应的义项的集合作为第一义项集合,同时找到第二词语所对应的义项,将第二词语所对应的义项的集合作为第二义项集合。
[0063]
表2打仗和战争在同义词词林中的义项编码
[0064][0065]
如表2所示,第一词语和第二词语分别为“打仗”和“战争”,“打仗”所对应的第一义项集合中包括hb02c中的“打仗”和hb02c01=中的“打仗”,“战争”所对应的第二义项集合中包括di11中的“战争”、di11b中的“战争”、di11b01=中的“战争”。
[0066]
103,基于同义词词林确定第一义项集合中处于叶子结点的第一义项在叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在叶子结点中的同义词义项集合,作为第二同义词义项集合。
[0067]
其中,第一义项集合中包括各第一义项,第二义项集合中包括各第二义项。义项所对应的同义词义项集合包括:当义项在叶子结点上,并且所对应的义项编码的最后符号为“=”,则同义词义项集合为叶子结点上其他义项(所对应的词语)的集合;当义项不在叶子结点上,或者义项所对应的义项编码的最后符号不为“=”,则同义词义项集合为该义项。
[0068]
将处于叶子结点的第一义项在叶子结点中的同义词义项集合,作为第一同义词义项集合,将处于叶子结点的第二义项在叶子结点中的同义词义项集合,作为第二同义词义项集合。
[0069]
假设第一义项和第二义项分别用s1,s2来表示。第一义项s1所对应的第一同义词义项集合可用similar(s1)来表示,第二义项s2所对应的第二同义词义项集合可用similar(s2)来表示。
[0070]
如表2所示,当s1为hb02c中的“打仗”,由于s1所在的分支结点不属于叶子结点,则similar(s1)为s1;当s1为hb02c01=中的“打仗”,因为s1所在的分支结点属于叶子结点,且s1所对应的义项编码的最后符号为“=”,则similar(s1)包括“作战战斗交战交火交锋交兵杀战征征战上阵”,即除去“打仗”之后的义项集合。同理,当s2为di11中的“战争”,由于s2所在的分支结点不属于叶子结点,则similar(s2)为s2;当s2为di11b01=中的“战争”时,由于s2所在的分支结点为叶子结点,且s2所对应的义项编码的最后符号为“=”,则similar(s2)包括“战事战乱战祸烟尘战火烽火烽烟狼烟兵火兵燹刀兵兵戈干戈战仗乱大战”,即除去“战争”之后的义项集合。其中,叶子结点中包括了更多的信息,其蕴含的信息较为丰富。
[0071]
表2中,“打仗”所对应的各第一义项和“战争”所对应的各第二义项在同义词词林中分别属于h与d两大类分支下,其公共父结点为根结点,蕴含信息量为0。按照已有词语相似度确定方法,其相似度极低,且与其他同属两分支下任意两义项相似度并无明显区分。现有的词语相似度确定方法在确定相似度时仅考虑最近公共父结点蕴含信息量或者通过最近公共父结点的深度,然而最近公共父结点蕴含信息量或者通过最近公共父结点的深度并不能完全描绘两词语之间的相似度,存在不合理之处。因此,本技术实施例中还考虑了义项的同义词义项集合,根据同义词义项集合来确定义项之间的相似度。其中,理解为若两义项之间相似,则其同义词也较为相似。具体请参看下文中的对应描述。
[0072]
104,根据第一义项集合中各第一义项和第二义项集合中的各第二义项、以及第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度。
[0073]
第一同义词义项集合中包括至少一个同义词义项,将所包括的各同义词义项确定为各第一同义词义项,同理,第二同义词义项集合中包括至少一个同义词义项,将所包括的各同义词义项确定为各第二同义词义项。第一义项集合中包括各第一义项,第二义项集合中包括各第二义项。
[0074]
根据一个第一义项和一个第二义项,以及该第一义项所对应的第一同义词义项集合中的各第一同义词义项、该第二义项所对应的第二同义词义项集合中的各第二同义词义项,确定该第一义项和该第二义项之间的义项相似度。按照同样的方法,可确定出各第一义项和各第二义项之间的义项相似度。
[0075]
其中,第一义项与第二义项之间的义项相似度的确定不仅考虑了第一义项和第二义项本身,同时还考虑了处于叶子结点的第一义项和处于叶子结点的第二义项的同义词义项集合,即还考虑了处于叶子结点的第一义项和第二义项所在叶子结点中编码为“=”的其他义项的集合,由于叶子结点中同义词义项包括的信息较多,且同义词义项与对应的第一义项和第二义项表达的意思相近,如此,利用同义词义项集合来增强对第一义项和第二义项的相似度的影响,改善了若第一义项和第二义项属于同义词词林下的不同大类分支,相似度极低的情况,提高了词语相似度确定的准确性,进一步提高数据匹配的准确性。
[0076]
在一实施例中,上述104的步骤,包括:根据第一义项集合中各第一义项和第二义项集合中的各第二义项、以及第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项共同特征和义项差异特征;根据义项共同特征和义项差异特征确定各第一义项和各第二义项之间的义项相似度。
[0077]
其中,义项共同特征指的是第一义项和第一义项之间的相似之处,义项差异特征指的是第一义项和第二义项之间的不同之处。
[0078]
根据一个第一义项和一个第二义项,以及该第一义项所对应的第一同义词义项集合中的各第一同义词义项、该第二义项所对应的第二同义词义项集合中的各第二同义词义项,确定该第一义项和该第二义项之间的义项共同特征和义项差异特征,根据义项共同特征和义项差异特征确定该第一义项和该第二义项之间的义项相似度。按照同样的方法,得到各第一义项和各第二义项之间的义项相似度。
[0079]
第一义项s1和第二义项s2之间的义项共同特征可使用comm(s1,s2)来表示,第一义项s1和第二义项s2之间的义项差异特征可使用diff(s1,s2)来表示,则第一义项s1和第二义项s2之间的义项相似度sim(s1,s2)可使用如下公式(7)来确定。
[0080][0081]
其中,t为超参数,表示相似度中义项之间的义项共同特征与义项差异特征对相似度数值的影响,可根据具体需求调整。
[0082]
该实施例中增加了根据第一义项的各第一同义词义项、第二义项的各第二同义词义项来确定第一义项和第二义项的义项共同特征和义项差异特征,如此利用同义词义项集
合来增强对第一义项和第二义项之间的义项共同特征和义项差异特征的影响,进一步地增强对第一义项和第二义项之间的相似度的影响,改善了若第一义项和第二义项属于同义词词林下的不同大类分支,相似度极低的情况,提高了词语相似度确定的准确性,进一步提高数据匹配的准确性。
[0083]
在一实施例中,如图3所示,上述104的步骤包括如下步骤1041至1045。
[0084]
1041,确定第一义项集合中各第一义项和第二义项集合中的各第二义项之间的第一相似度。
[0085]
第一义项和第二义项之间的第一相似度可通过第一义项和第二义项的最近公共父结点的信息含量来确定。例如,确定第一义项和第二义项之间的最近公共父结点,并根据最近公共父结点所对应的信息含量确定第一义项和第二义项之间的第一相似度。
[0086]
1042,确定第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项之间的第二相似度。
[0087]
第一同义词义项和第二同义词义项之间的第二相似度可通过第一同义词义项和第二同义词义项的最近公共父结点的信息含量来确定。例如,确定第一同义词义项和第二同义词义项之间的最近公共父结点,并根据最近公共父结点所对应的信息含量确定第一同义词义项和第二同义词义项之间的第二相似度。
[0088]
在一实施例中,可直接计算各第一同义词义项和各第二同义词义项之间的第二相似度。例如,表2中的hb02c01中的第一同义词义项“战”和di11b01中的第二同义词义项“战”的相似度为100%,hb02c01中的第一同义词义项“上阵”和di11b01中的第二同义词义项“烟尘”的相似度为0等。
[0089]
由于第一同义词义项集合中的第一同义词义项包括至少一个,第二同义词义项集合中的第二同义词义项包括至少一个,因此第二相似度也包括至少一个。通常情况下第二相似度包括多个。
[0090]
1043,根据第一相似度和第二相似度确定各第一义项和各第二义项之间的义项共同特征。
[0091]
在一实施例中,将第一相似度和第二相似度进行加权求和,以得到第一义项和第二义项之间的义项共同特征。
[0092]
在一实施例中,上述1043的步骤,包括:将第二相似度按照从高到低的顺序排列,并获取前预设数量的目标第二相似度;获取第一超参数以及预设数量的第二超参数,第二超参数与目标第二相似度一一对应,所述第一超参数和预设数量的第二超参数相加之后的和为一;利用第一超参数、第二超参数分别与第一相似度、目标第二相似度进行加权求和,以得到各第一义项和各第二义项之间的义项共同特征。
[0093]
其中,若第二相似度中包括多个,将第二相似度按照相似度值从高到低的顺序排列,从排列后的第二相似度中,获取前预设数量的目标第二相似度值。预设数量可以是3个,还可以是2、4等整数值的数量,以预设数量为3为例进行说明。获取第一超参数和预设数量的第二超参数,第二超参数与目标第二相似度一一对应。其中,预设数量的第二超参数和第一超参数的和为1。
[0094]
在一实施例中,预设数量的第二超参数的值可以相同。可以理解地,目标第二相似度中各目标第二相似度与各第二超参数一一对应。在另一实施例中,预设数量的第二超参
数的值各不相同。例如,目标第二相似度中相似度最高的目标第二相似度与第二超参数中参数值最高的对应,......,目标第二相似度中相似度最低的目标第二相似度与第二超参数中参数值最低的对应。
[0095]
将第一超参数与第一相似度,预设数量的第二超参数与预设数量的目标第二相似度进行加权求和,即将第一超参数与第一相似度相乘的值,加上各第二超参数与对应的各目标第二相似度相乘之后的值,以得到第一义项和第二义项之间的义项共同特征。
[0096]
如表2所示,现有的同义词词林中的对于“作战”与“战争”的同义词义项集合中的相似之处“战”并未进行描述。而本技术实施例中,利用同义词义项集合中的第二相似度,来对同义词义项集合中的相似之处进行描述。结合同义词义项集合中的第二相似度和第一义项之间的第一相似度来确定义项共同特征,增强了词语义项之间共同之处对义项相似度的影响,改善了若第一义项和第二义项属于同义词词林下的不同大类分支,相似度极低的情况,提高了词语相似度确定的准确性,进一步提高数据匹配的准确性。
[0097]
在一实施例中,确定第一义项和第二义项之间的义项共同特征可根据如下公式(8)来确定。
[0098][0099]
其中,β、βk为可调节的第一超参数和第二超参数,预设数量为3。第一义项s1和第二义项s2之间的相似度仅用lcs(s1,s2)并不能完全表示出其最近公共父结点的信息含量或者s1与s2之间的相似之处,故公式(8)中引入seco等人关于结点信息含量的定义:即上述公式(6),引入层级及下位结点数(子结点数)辅助计算,其中,层级越低,子结点数越少,其蕴含的信息越丰富。即公式(8)中的ic(.)的计算请参看上述公式(6),以提高第一义项和第二义项之间的义项共同特征的准确度。
[0100]
1044,基于各第一义项和各第二义项的最短路径长度,确定各第一义项和各第二义项之间的义项差异特征。
[0101]
在一实施例中,上述1044的步骤,包括:获取各第一义项和各第二义项的最短路径长度、各第一义项和各第二义项的最近公共父结点;获取最近公共父结点所对应的层数权重,以及确定最近公共父结点的直接孩子数、各第一义项和各第二义项所在最近公共父结点的分支距离;根据最短路径长度、层数权重、直接孩子数和分支距离确定各第一义项和各第二义项之间的义项差异特征。
[0102]
在同义词词林中,每层都对应有权重,称为层数权重。
[0103]
在一实施例中,确定第一义项和第二义项之间的义项差异特征可按照如下公式(9)来确定。
[0104][0105]
其中,i为第一义项s1和第二义项s2的最近公共父结点所在层数,d为第一义项s1和第二义项s2的最短路径长度,n为第一义项s1和第二义项s2最近公共父结点的直接孩子数,k为第一义项s2和第二义项s2所在最近公共父结点的分支距离。
[0106]
需要注意的是,本技术实施例中的第一义项s1和第二义项s2的最短路径长度的确定方式与原有计算方式不同。原有计算方式中,第一义项和第二义项之间的相似度都是利用第一义项所在的分支结点到最近公共父结点的路径长度与第二义项所在的分支结点到最近公共父结点的路径长度之和来表示,并未有其他的考虑。本技术实施例中考虑了包含关系下义项之间相似度以及非包含关系下相似度的区分。如表3所示,词语“戏曲”中包括了词语“昆剧”、“京剧”等,原有计算方式中并未考虑这些对最短路径长度的影响。
[0107]
表3戏曲、昆剧、京剧在同义词词林中的义项编码
[0108][0109]
基于此,本技术实施例中给第一义项和第二义项的最短路径长度重新进行来定义,提供了一种新的定义第一义项和第二义项的最短路径长度的方式。具体地,上述获取各第一义项和各第二义项的最短路径长度的步骤,包括:根据第一词语所对应的各第一义项与第二词语所对应的各第二义项的最近公共父结点和叶子结点中是否存在第一词语或者第二词语来确定各第一义项和各第二义项的最短路径长度。具体分为以下几种情况。
[0110]
当第一词语所对应的第一义项和第二词语所对应的第二义项的最近公共父结点中包括第一词语或者第二词语,则第一义项和第二义项的最短路径长度为最近公共父结点与第二义项所对应的分支结点的路径长度,或者为最近公共父结点与第一义项所对应的分支结点的路径长度。
[0111]
如图4中的a图所示,第一义项所对应的分支结点(当前a图中的叶子节点)中包括第一词语w1,第二义项所对应的分支结点中包括第二词语w2,第一义项和第二义项所对应的最近公共父结点lcp中包括第二词语w2,意味着第一词语w1和第二词语w2属于包含关系,则第一义项和第二义项的最短路径长度为最近公共父结点与第一义项所对应的分支节点的路径长度,即d=l1。其中,l1为a图中的第一义项所对应的分支节点到最近公共父结点之间的两个边的路径距离之和。根据边权重来确定边所对应的路径距离。对于不同层数采用不同的边权重:越靠近根结点权重越大,越接近叶子结点权重越小,同理l2也是如此理解,下文中将不再赘述。
[0112]
当第一词语所对应的第一义项和第二词语所对应的第二义项仅在叶子结点中出现,则第一义项和第二义项的最短路径长度为第一义项所对应的叶子结点到最近公共父结点之间的路径长度、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度之和。
[0113]
如图4中的b图所示,第一义项所对应的分支结点中包括第一词语w1,第二义项所对应的分支结点中包括第二词语w2,第一义项所对应的分支结点、第二义项所对应的分支结点都为叶子结点,则第一义项和第二义项的最短路径长度d为第一义项所对应的叶子结
点到最近公共父结点之间的路径长度l1、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度l2之和,即d=l1 l2。
[0114]
当第一词语所对应的第一义项与第二词语所对应的第二义项的最近公共父结点中不包括第一词语或者第二词语,但第一词语或者第二词语既在叶子结点中出现,同时也在非最近公共父结点中出现,则第一义项和第二义项的最短路径长度为第一义项所对应的叶子结点到最近公共父结点之间的路径长度、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度之和。
[0115]
如图4中的c图所示,第一词语w1所对应的第一义项与第二词语w2所对应的第二义项的最近公共父结点中不包括第一词语w1或者第二词语w2,但第二词语w2在叶子结点中出现,同时也在非最近公共父结点中出现,则第一义项和第二义项的最短路径长度为第一义项所对应的叶子结点到最近公共父结点之间的路径长度l1、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度l2之和,即d=l1 l2。
[0116]
其中,虽然第二词语w2在叶子结点中出现,但其不在最近公共父结点中出现,其不属于包含关系,在非最近公共父结点中出现,则意味着非最近公共父结点中的第二词语w2属于类别,因此,第一义项和第二义项之间真正的最短路径距离还是l1 l2。
[0117]
当第一词语所对应的第一义项与第二词语所对应的第二义项不仅在最近公共父结点中出现,同时也在对应的叶子结点中出现,则第一义项和第二义项的最短路径长度为第一义项所对应的叶子结点到最近公共父结点之间的路径长度、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度之和。
[0118]
如图4中的d图所示,第一词语w1所对应的第一义项与第二词语w2所对应的第二义项不仅在最近公共父结点中出现,同时也在对应的叶子结点中出现,则意味着在最近公共父结点中出现的第一词语w1和第二词语w2属于类别,而叶子节点中的第一词语w1和第二词语w2对应的是第一义项和第二义项,则第一义项和第二义项的最短路径长度为第一义项所对应的叶子结点到最近公共父结点之间的路径长度l1、与第二义项所对应的叶子结点到最近公共父结点之间的路径长度l2之和,即d=l1 l2。
[0119]
上述四种情况中,a图所对应的情况属于包含关系,b图、c图和d图所对应的情况均属于并列关系。该实施例中,将包含关系和并列关系进行了一定的区分,且根据不同关系,重新定义了两义项的最短路径距离的计算方式,使得包含关系的两义项相似度大于同等情况下并列关系的两义项的相似度,使其更适用于媒资标签的相似度的计算。
[0120]
1045,根据义项共同特征和义项差异特征确定各第一义项和各第二义项之间的义项相似度。
[0121]
具体地,根据义项共同特征和义项差异特征确定各第一义项和各第二义项之间的义项相似度,可按照上述公式(7)中的方式来确定,具体请参看上文中的描述,在此不再赘述。
[0122]
上述实施例中详细介绍了如何确定第一义项和第二义项之间的义项相似度。具体可结合图5来理解上述确定第一义项和第二义项之间的义项相似度确定的过程。其中,w11、w12、......、w1n为第一同义词集合,w21、w22、......、w2n为第二同义词集合。
[0123]
105,根据义项相似度确定第一词语和第二词语之间的相似度。
[0124]
第一词语和第二词语之间的相似度可根据第一词语所对应的义项和第二词语所
对应的义项的义项相似度最大值来确定。
[0125]
第一词语w1和第二词语w2之间的相似度可根据公式(10)来确定。
[0126]
sim(w1,w2)=max{sim(s1,s2)}
s1∈s(w1),s2∈s(w2)
ꢀꢀꢀ
(10)
[0127]
其中,s(w1)和s(w2)分别表示第一词语w1所对应的第一义项集合、第二词语w2所对应的第二义项集合。
[0128]
具体地,确定第一词语和第二词语之间的相似度具体可参看图6,图6中的词语1和词语2分别为第一词语和第二词语。
[0129]
本技术实施例中的词语相似度确定的方案中第一义项与第二义项之间的义项相似度的确定不仅考虑了第一义项和第二义项本身,同时还考虑了处于叶子结点的第一义项和处于叶子结点的第二义项的同义词义项集合,即还考虑了处于叶子结点的第一义项和第二义项所在叶子结点中编码为“=”的其他义项的集合,由于叶子结点中同义词义项包括的信息较多,且同义词义项与对应的第一义项和第二义项表达的意思相近,如此,利用同义词义项集合来增强对第一义项和第二义项的相似度的影响,同时本技术中结合了基于信息与基于路径的词语相似度计算方法,改善了若第一义项和第二义项属于同义词词林下的不同大类分支,相似度极低的情况,提高了词语相似度确定的准确性,进一步提高数据匹配的准确性。
[0130]
表4和表5是基于同义词词林的词语相似度对比结果,可以看出利用本技术实施例中的词语相似度确定方法大大提高了词语相似度确定的准确性。
[0131]
其中,参数t取4,β=0.85,β1=0.05,β2=0.05,β3=0.05,weight=[0.0,0.038,0.096,0.192,0.289,0.385]。其中,mc人工判定值指的是miller&charles(mc)发布的人工确定的词语相似度的结果。
[0132]
表4基于同义词词林的词语相似度对比结果
[0133][0134]
表5基于同义词词林的词语相似度对比结果
[0135][0136]
在一实施例中,当用户使用智能语音功能搜索影片时,通常通过识别语音信息中的标签,将标签与媒资标签体系中的媒资标签进行比对,其中,将标签与媒资标签进行比对的方式可参看上文中本技术实施例中提出的词语相似度确定方法中的任一实施例中所描述的内容,根据比对的比对结果返回相关的影片。
[0137]
根据上述实施例所描述的方法,本实施例将从词语相似度确定装置的角度进一步进行描述,该词语相似度确定装置具体可以作为独立的实体来实现,也可以集成在计算机设备中来实现。
[0138]
请参阅图7,图7具体描述了本技术实施例提供的词语相似度确定装置,应用于计算机设备中。该词语相似度确定装置可以包括:获取模块201、第一义项确定模块202、第二义项确定模块203、第一相似度确定模块204以及第二相似度确定模块205。
[0139]
获取模块201,用于获取需确定相似度的第一词语和第二词语。
[0140]
第一义项确定模块202,用于基于同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合。
[0141]
第二义项确定模块203,用于基于同义词词林确定第一义项集合中处于叶子结点的第一义项在所述叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在所述叶子结点中的同义词义项集合,作为第二同
义词义项集合。
[0142]
第一相似度确定模块204,用于根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度。
[0143]
在一实施例中,第一相似度确定模块204,具体用于根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项共同特征和义项差异特征;根据所述义项共同特征和所述义项差异特征确定各第一义项和各第二义项之间的义项相似度。
[0144]
在一实施例中,第一相似度确定模块204在执行所述根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项共同特征和义项差异特征的步骤时,具体执行:确定所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项之间的第一相似度;确定所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项之间的第二相似度;根据所述第一相似度和所述第二相似度确定各第一义项和各第二义项之间的义项共同特征;基于各第一义项和各第二义项的最短路径长度,确定各第一义项和各第二义项之间的义项差异特征。
[0145]
在一实施例中,第一相似度确定模块204在执行所述根据所述第一相似度和所述第二相似度确定各第一义项和各第二义项之间的义项共同特征的步骤时,具体执行:将第二相似度按照从高到低的顺序排列,并获取前预设数量的目标第二相似度;获取第一超参数以及预设数量的第二超参数,所述第二超参数与所述目标第二相似度一一对应,所述第一超参数和预设数量的所述第二超参数相加之后的和为一;利用所述第一超参数、所述第二超参数分别与所述第一相似度、所述目标第二相似度进行加权求和,以得到各第一义项和各第二义项之间的义项共同特征。
[0146]
在一实施例中,第一相似度确定模块204在执行所述基于各第一义项和各第二义项的最短路径长度,确定各第一义项和各第二义项之间的义项差异特征的步骤时,具体执行:获取各第一义项和各第二义项的最短路径长度、各第一义项和各第二义项的最近公共父结点;获取所述最近公共父结点所对应的层数权重,以及确定所述最近公共父结点的直接孩子数、各第一义项和各第二义项所在的所述最近公共父结点的分支距离;根据所述最短路径长度、所述层数权重、所述直接孩子数和所述分支距离确定各第一义项和各第二义项之间的义项差异特征。
[0147]
在一实施例中,第一相似度确定模块204在执行所述获取各第一义项和各第二义项的最短路径长度的步骤时,具体执行:根据第一词语所对应的各第一义项与所述第二词语所对应的各第二义项的最近公共父结点和叶子结点中是否存在所述第一词语或者所述第二词语来确定各第一义项和各第二义项的最短路径长度。
[0148]
在一实施例中,第一相似度确定模块204在执行所述根据第一词语所对应的各第一义项与所述第二词语所对应的各第二义项的最近公共父结点和叶子结点中是否存在所述第一词语或者所述第二词语来确定各第一义项和各第二义项的最短路径长度的步骤时,
具体执行:当所述第一词语所对应的第一义项和所述第二词语所对应的第二义项的最近公共父结点中包括所述第一词语或者所述第二词语,则所述第一义项和所述第二义项的最短路径长度为所述最近公共父结点与所述第二义项所对应的分支结点的路径长度,或者为所述最近公共父结点与所述第一义项所对应的分支结点的路径长度;当所述第一词语所对应的第一义项和所述第二词语所对应的第二义项仅在叶子结点中出现,则所述第一义项和所述第二义项的最短路径长度为所述第一义项所对应的叶子结点到所述最近公共父结点之间的路径长度、与所述第二义项所对应的叶子结点到所述最近公共父结点之间的路径长度之和;当所述第一词语所对应的第一义项与所述第二词语所对应的第二义项的最近公共父结点中不包括第一词语或者第二词语,但第一词语或者第二词语既在叶子结点中出现,同时也在非最近公共父结点中出现,则所述第一义项和所述第二义项的最短路径长度为所述第一义项所对应的叶子结点到所述最近公共父结点之间的路径长度、与所述第二义项所对应的叶子结点到所述最近公共父结点之间的路径长度之和;当所述第一词语所对应的第一义项与所述第二词语所对应的第二义项不仅在所述最近公共父结点中出现,同时也在对应的叶子结点中出现,则所述第一义项和所述第二义项的最短路径长度为所述第一义项所对应的叶子结点到所述最近公共父结点之间的路径长度、与所述第二义项所对应的叶子结点到所述最近公共父结点之间的路径长度之和。
[0149]
第二相似度确定模块205,用于根据所述义项相似度确定所述第一词语和所述第二词语之间的相似度。
[0150]
具体实施时,以上各个模块可以作为独立的实体来实现,也可以进行任意组合,作为同一或若干个实体来实现,以上各个模块的具体实施可参见前面的方法实施例,具体可以达到的有益效果也请参看前面的方法实施例中的有益效果,在此不再赘述。
[0151]
另外,本技术实施例还提供一种计算机设备,如图8所示,计算机设备300包括处理器301、存储器302。其中,处理器301与存储器302电性连接。
[0152]
处理器301是计算机设备300的控制中心,利用各种接口和线路连接整个计算机设备的各个部分,通过运行或加载存储在存储器302内的应用程序,以及调用存储在存储器302内的数据,执行计算机设备的各种功能和处理数据,从而对计算机设备进行整体监控。
[0153]
在本实施例中,计算机设备300中的处理器301会按照如下的步骤,将一个或一个以上的应用程序的进程对应的指令加载到存储器302中,并由处理器301来运行存储在存储器302中的应用程序,从而实现各种功能,如:
[0154]
获取需确定相似度的第一词语和第二词语;基于同义词词林确定第一词语所对应的第一义项集合和第二词语所对应的第二义项集合;基于同义词词林确定第一义项集合中处于叶子结点的第一义项在所述叶子结点中的同义词义项集合,作为第一同义词义项集合,以及确定第二义项集合中处于叶子结点的第二义项在所述叶子结点中的同义词义项集合,作为第二同义词义项集合;根据所述第一义项集合中各第一义项和所述第二义项集合中的各第二义项、以及所述第一同义词义项集合中的各第一同义词义项与第二同义词义项集合中的各第二同义词义项,确定各第一义项和各第二义项之间的义项相似度;根据所述义项相似度确定所述第一词语和所述第二词语之间的相似度。
[0155]
该计算机设备可以实现本技术实施例所提供的词语相似度确定方法任一实施例中的步骤,因此,可以实现本发明实施例所提供的任一词语相似度确定方法所能实现的有
益效果,详见前面的实施例,在此不再赘述。
[0156]
图9示出了本发明实施例提供的计算机设备的具体结构框图,该计算机设备可以用于实施上述实施例中提供的词语相似度确定方法。该计算机设备包括以下的模块/单元。
[0157]
rf电路410用于接收以及发送电磁波,实现电磁波与电信号的相互转换,从而与通讯网络或者其他设备进行通讯。rf电路410可包括各种现有的用于执行这些功能的电路元件,例如,天线、射频收发器、数字信号处理器、加密/解密芯片、用户身份模块(sim)卡、存储器等等。rf电路410可与各种网络如互联网、企业内部网、无线网络进行通讯或者通过无线网络与其他设备进行通讯。上述的无线网络可包括蜂窝式电话网、无线局域网或者城域网。上述的无线网络可以使用各种通信标准、协议及技术,包括但并不限于全球移动通信系统(global system for mobile communication,gsm)、增强型移动通信技术(enhanced data gsm environment,edge),宽带码分多址技术(wideband code division multiple access,wcdma),码分多址技术(code division access,cdma)、时分多址技术(time division multiple access,tdma),无线保真技术(wireless fidelity,wi-fi)(如美国电气和电子工程师协会标准ieee 802.11a,ieee 802.11b,ieee802.11g和/或ieee 802.11n)、网络电话(voice over internet protocol,voip)、全球微波互联接入(worldwide interoperability for microwave access,wi-max)、其他用于邮件、即时通讯及短消息的协议,以及任何其他合适的通讯协议,甚至可包括那些当前仍未被开发出来的协议。
[0158]
存储器420可用于存储软件程序(计算机程序)以及模块,如上述实施例中对应的程序指令/模块,处理器480通过运行存储在存储器420内的软件程序以及模块,从而执行各种功能应用以及数据处理。存储器420可包括高速随机存储器,还可包括非易失性存储器,如一个或者多个磁性存储装置、闪存、或者其他非易失性固态存储器。在一些实例中,存储器420可进一步包括相对于处理器480远程设置的存储器,这些远程存储器可以通过网络连接至计算机设备400。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0159]
输入单元430可用于接收输入的数字或字符信息,以及产生与用户设置以及功能控制有关的键盘、鼠标、操作杆、光学或者轨迹球信号输入。具体地,输入单元430可包括触敏表面431以及其他输入设备432。触敏表面431,也称为触摸显示屏(触摸屏)或者触控板,可收集用户在其上或附近的触摸操作(比如用户使用手指、触笔等任何适合的物体或附件在触敏表面431上或在触敏表面431附近的操作),并根据预先设定的程式驱动相应的连接装置。可选的,触敏表面431可包括触摸检测装置和触摸控制器两个部分。其中,触摸检测装置检测用户的触摸方位,并检测触摸操作带来的信号,将信号传送给触摸控制器;触摸控制器从触摸检测装置上接收触摸信息,并将它转换成触点坐标,再送给处理器480,并能接收处理器480发来的命令并加以执行。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型实现触敏表面431。除了触敏表面431,输入单元430还可以包括其他输入设备432。具体地,其他输入设备432可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆等中的一种或多种。
[0160]
显示单元440可用于显示由用户输入的信息或提供给用户的信息以及计算机设备400的各种图形用户接口,这些图形用户接口可以由图形、文本、图标、视频和其任意组合来
构成。显示单元440可包括显示面板441,可选的,可以采用lcd(liquid crystal display,液晶显示器)、oled(organic light-emitting diode,有机发光二极管)等形式来配置显示面板441。进一步的,触敏表面431可覆盖显示面板441,当触敏表面431检测到在其上或附近的触摸操作后,传送给处理器480以确定触摸事件的类型,随后处理器480根据触摸事件的类型在显示面板441上提供相应的视觉输出。虽然在图中,触敏表面431与显示面板441是作为两个独立的部件来实现输入和输出功能,但是可以理解地,将触敏表面431与显示面板441集成而实现输入和输出功能。
[0161]
计算机设备400还可包括至少一种传感器450,比如光传感器、方向传感器、接近传感器以及其他传感器。作为运动传感器的一种,重力加速度传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向,可用于识别手机姿态的应用(比如横竖屏切换、相关游戏、磁力计姿态校准)、振动识别相关功能(比如计步器、敲击)等;至于计算机设备400还可配置的陀螺仪、气压计、湿度计、温度计、红外线传感器等其他传感器,在此不再赘述。
[0162]
音频电路460、扬声器461,传声器462可提供用户与计算机设备400之间的音频接口。音频电路460可将接收到的音频数据转换后的电信号,传输到扬声器461,由扬声器461转换为声音信号输出;另一方面,传声器462将收集的声音信号转换为电信号,由音频电路460接收后转换为音频数据,再将音频数据输出处理器480处理后,经rf电路410以发送给比如另一计算机设备,或者将音频数据输出至存储器420以便进一步处理。音频电路460还可能包括耳塞插孔,以提供外设耳机与计算机设备400的通信。
[0163]
计算机设备400通过传输模块470(例如wi-fi模块)可以帮助用户接收请求、发送信息等,它为用户提供了无线的宽带互联网访问。虽然图示出了传输模块470,但是可以理解的是,其并不属于计算机设备400的必须构成,完全可以根据需要在不改变发明的本质的范围内而省略。
[0164]
处理器480是计算机设备400的控制中心,利用各种接口和线路连接整个手机的各个部分,通过运行或执行存储在存储器420内的软件程序(计算机程序)和/或模块,以及调用存储在存储器420内的数据,执行计算机设备400的各种功能和处理数据,从而对计算机设备进行整体监控。可选的,处理器480可包括一个或多个处理核心;在一些实施例中,处理器480可集成应用处理器和调制解调处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,调制解调处理器主要处理无线通信。可以理解地,上述调制解调处理器也可以不集成到处理器480中。
[0165]
计算机设备400还包括给各个部件供电的电源490(比如电池),在一些实施例中,电源可以通过电源管理系统与处理器480逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。电源490还可以包括一个或一个以上的直流或交流电源、再充电系统、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。
[0166]
尽管未示出,计算机设备400还包括摄像头(如前置摄像头、后置摄像头)、蓝牙模块等,在此不再赘述。具体在本实施例中,计算机设备的显示单元是触摸屏显示器,计算机设备还包括有存储器,以及一个或者一个以上的程序(计算机程序),其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行一个或者一个以上程序包含用于进行上述本技术实施例中提供的词语相似度确定方法中任一实施例的步骤。
[0167]
具体实施时,以上各个模块可以作为独立的实体来实现,也可以进行任意组合,作为同一或若干个实体来实现,以上各个模块的具体实施可参见前面的方法实施例,在此不再赘述。
[0168]
本领域普通技术人员可以理解,上述实施例的各种方法中的全部或部分步骤可以通过指令(计算机程序)来完成,或通过指令控制相关的硬件来完成,该指令可以存储于一计算机可读存储介质中,并由处理器进行加载和执行。为此,本发明实施例提供一种存储介质,其中存储有多条指令,该指令能够被处理器进行加载,以执行本发明实施例所提供的词语相似度确定方法中任一实施例的步骤。
[0169]
其中,该存储介质可以包括:只读存储器(rom,read only memory)、随机存取记忆体(ram,random access memory)、磁盘或光盘等。
[0170]
由于该存储介质中所存储的指令,可以执行本发明实施例所提供的词语相似度确定方法任一实施例中的步骤,因此,可以实现本发明实施例所提供的任词语相似度确定方法所能实现的有益效果,详见前面的实施例,在此不再赘述。
[0171]
以上对本技术实施例所提供的一种词语相似度确定方法、装置、存储介质和计算机设备进行了详细介绍,本文中应用了具体个例对本技术的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本技术的方法及其核心思想;同时,对于本领域的技术人员,依据本技术的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本技术的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。