基于vit的深度学习神经网络数据增强方法
技术领域
1.本发明涉及机器视觉技术领域,具体涉及一种基于vit的深度学习神经网络数据增强方法。
背景技术:
2.vision transformer在自然语言处理的几乎所有任务中都占主导地位。近期它也已被引入计算机视觉领域,并在图像分类、目标检测和图像分割等任务中显示出巨大的前景。比如申请公布号为cn113239981a的局部特征耦合全局表征的图像分类方法中,建立的网络模型包括卷积神经网络分支、视觉转换器分支、启动模块,构建了对偶网络结构,针对性的保留、增强局部特征和全局表征。
3.最近的研究发现,基于vision transformer的网络很难优化,并且在训练数据不足的情况下很容易过拟合。mixup和cutmix被引入解决这个问题,但是存在背景中的像素对标签空间的贡献大小的问题,通过在混合输入层面来解决像素对标签空间的贡献大小,但是存在参数量大和难训练的问题,因此需要新的方法来解决像素对标签空间的贡献大小。
4.现多数技术研究人员由于技术的原因,通过在混合输入层面上最具描述性的部分来解决它,而这些解决的方法存在以下问题:(1)它们往往较少考虑将背景图像放入混合中,造成提取的图像特征不明显;(2)参数量大,训练的难度会加大。
技术实现要素:
5.本发明提供一种基于vit的深度学习神经网络数据增强方法,针对背景技术中提到的技术问题,本发明提供了全新的解决思路及具体方案。
6.包括如下步骤:
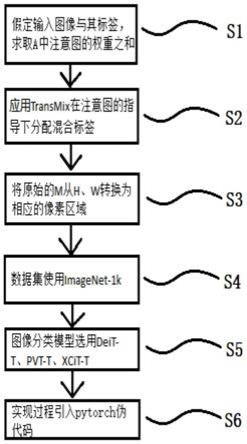
7.s1、假定a是输入的图像,ya是输入图像a的标签,将ya的权重λ设置为位于a中的注意图的权重之和;
8.s2、transmix在注意图的指导下分配混合标签,所述注意图明确定义为多头类attentiona,按照cutmix的输入混合过程进行;
9.s3、将原始的m从h、w转换为相应的像素区域,网络可以学习到根据每个数据点在注意力图中的响应动态地重新分配标签的权重,所述m为图像位置的二进制的掩码,所述h、w分别为图像的高和宽;
10.s4、数据集使用imagenet-1k,所述imagenet-1k包含1.28m训练图像和50k验证图像;
11.s5、图像分类模型选用deit-t、pvt-t、xcit-t,其中,模型deit-t、pvt-t训练300轮,模型xcit-t训练400轮,热身轮数为20轮;
12.s6、本方法实现过程的pytorch伪代码如下:
13.h,w:theheightandwidthoftheinputimage
14.p:numberofpatches
15.m:0-initializedmaskwithshape(h,w)
16.downsample:downsamplefromlength(h*w)to(p)
17.(bx1,bx2,by1,by2):boundingboxcoordinate
18.for(x,y)in loader:loadaminibatchwithnpairs
19.cutmiximageinaminibatch
20.m[bx1:bx2,by1:by2]=1
[0021]
x[:,:,m==1]=x.flip(0)[:,:,m==1]
[0022]
m=downsample(m.view(-1))
[0023]
#attentionmatrixa:(n,p)
[0024]
logits,a=model(x)
[0025]
#mixlabelswiththeattentionmap
[0026]
lam=matmul(a,m)
[0027]
y=(1-lam)*y lam*y.flip(0)
[0028]
crossentropyloss(logits,y).backward()。
[0029]
优选地,s1步骤中,所述标签根据每个像素的显著性重新加权,而不是按照混合输入的相同比例线性插值。
[0030]
优选地,s2步骤中,所述混合过程的混合公式如下:
[0031][0032][0033]
式中,m∈{0,1}
h,w
代表表示二进位掩码,表示从两幅图像中抽取和填充的位置,1为二进位掩码,*代表元素相乘,λ为混合标签中的比例,代表训练样本。
[0034]
优选地,s2步骤中,在增强过程中,将一个随机采样的区域xb移除,并用xa裁剪的区域填充,裁剪区域的边界框坐标为(r
x
,ry,rw,rh)。混合目标分配系数λ等于裁切面积比
[0035]
优选地,s3步骤中,所述注意力图的输入集中程度与混合标签获得更高的值响应成正比,具体如下公式:
[0036]
λ=a
·
↓
(m)
[0037]
式中,
↓
表示最近邻插值下采样。
[0038]
优选地,所述步骤s4的实现基于timm库。
[0039]
优选地,步骤s5中,在部署deit训练方案时,所有基线都包含正则化方法,包括randaug、stochastic depth、mixup和cutmix,不使用重复增广的方法;transmix与cutmix共享相同的裁剪区域作为图像的输入,而标签的分配是这两种方法的平均值。
[0040]
本发明的基于vit的深度学习神经网络数据增强方法,使用了transmix方法,只需几行代码就可实现,简单易行且不会对模型引入任何额外参数,使训练的难度减小;本发明解决了背景中的像素对标签空间的贡献大小的问题,提取的图像特征明显;方法中使用混合的增强模式对于模型的泛化在实际应用中有效、可靠,特别是对于vision transformers(vits),相对于现有技术出现的由于增强过程中的随机过程、混合图像中没有有效对象问题,本方法在标签空间中仍然有响应,可以根据每个像素的显著性重新加权,不需要额外的
参数和最小的计算开销;本方法应用的transmix是基于vits的注意地图混合标签,它可以弥补输入空间和标签空间之间的差距;此外,本发明在imagenet分类上还可以在尺度上改进各种基于vits的模型。
附图说明
[0041]
图1为本发明基于vit的深度学习神经网络数据的流程图。
具体实施方式
[0042]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0043]
结合参阅附图1本发明基于vit的深度学习神经网络数据的流程图,包括如下步骤:
[0044]
s1、假定a是输入的图像,ya是输入图像a的标签,将ya的权重λ设置为位于a中的注意图的权重之和;所述标签根据每个像素的显著性重新加权,而不是按照混合输入的相同比例线性插值。本步骤确定了图像标签的策略。
[0045]
s2、transmix在注意图的指导下分配混合标签,所述注意图明确定义为多头类attentiona,按照cutmix的输入混合过程进行;所述混合过程的混合公式如下:
[0046][0047][0048]
式中,m∈{0,1}
h,w
代表表示二进位掩码,表示从两幅图像中抽取和填充的位置,1为二进位掩码,*代表元素相乘,λ为混合标签中的比例,代表训练样本。
[0049]
在增强过程中,将一个随机采样的区域xb移除,并用xa裁剪的区域填充,裁剪区域的边界框坐标为(r
x
,ry,rw,rh)。混合目标分配系数λ等于裁切面积比
[0050]
s2步骤为s1步骤的具体图像标签策略实施过程。
[0051]
s3、将原始的m从h、w转换为相应的像素区域,网络可以学习到根据每个数据点在注意力图中的响应动态地重新分配标签的权重,所述m为图像位置的二进制的掩码,相当于图像的掩膜功能,所述h、w分别为图像的高和宽。本s3步骤为网络根据标签策略的方法,可以分配标签的权重。
[0052]
s4、数据集使用imagenet-1k,所述imagenet-1k包含1.28m训练图像和50k验证图像;所述注意力图的输入集中程度与混合标签获得更高的值响应成正比,具体如下公式:
[0053]
λ=a
·
↓
(m)
[0054]
式中,
↓
表示最近邻插值下采样。
[0055]
该步骤的实现基于timm库,对超参数做了微小的修改。
[0056]
s5、图像分类模型选用deit-t、pvt-t、xcit-t,其中,模型deit-t、pvt-t训练300轮,模型xcit-t训练400轮,热身轮数为20轮;在部署deit训练方案时,所有基线都包含正则
化方法,包括randaug、stochastic depth、mixup和cutmix,不使用重复增广的方法;transmix与cutmix共享相同的裁剪区域作为图像的输入,而标签的分配是这两种方法的平均值。
[0057]
s6、本方法实现过程的pytorch伪代码如下:
[0058]
h,w:theheightandwidthoftheinputimage
[0059]
p:numberofpatches
[0060]
m:0-initializedmaskwithshape(h,w)
[0061]
downsample:downsamplefromlength(h*w)to(p)
[0062]
(bx1,bx2,by1,by2):boundingboxcoordinate
[0063]
for(x,y)in loader:loadaminibatchwithnpairs
[0064]
cutmiximageinaminibatch
[0065]
m[bx1:bx2,by1:by2]=1
[0066]
x[:,:,m==1]=x.flip(0)[:,:,m==1]
[0067]
m=downsample(m.view(-1))
[0068]
#attentionmatrixa:(n,p)
[0069]
logits,a=model(x)
[0070]
#mixlabelswiththeattentionmap
[0071]
lam=matmul(a,m)
[0072]
y=(1-lam)*y lam*y.flip(0)
[0073]
crossentropyloss(logits,y).backward()。
[0074]
本发明的基于vit的深度学习神经网络数据增强方法,使用了transmix方法,只需几行代码就可实现,简单易行且不会对模型引入任何额外参数,使训练的难度减小;本发明解决了背景中的像素对标签空间的贡献大小的问题,提取的图像特征明显;方法中使用混合的增强模式对于模型的泛化在实际应用中有效、可靠,特别是对于vision transformers(vits),相对于现有技术出现的由于增强过程中的随机过程、混合图像中没有有效对象问题,本方法在标签空间中仍然有响应,可以根据每个像素的显著性重新加权,不需要额外的参数和最小的计算开销;本方法应用的transmix是基于vits的注意地图混合标签,它可以弥补输入空间和标签空间之间的差距;此外,本发明在imagenet分类上还可以在尺度上改进各种基于vits的模型。
[0075]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
