1.本发明涉及轻量级目标检测领域,具体涉及一种基于改进的yolov5s和ghostbottleneck的手机屏幕缺陷视觉检测方法和系统。
背景技术:
2.在手机制造生产线上总会产生一些制造缺陷,由于机器学习中大多数的图像特征提取是基于经验手动设置的,而人工检测则容易出现检测标准不一致的问题,传统机器学习检测系统与人工检测无法适应日趋庞大的生产线。而随着计算机显卡算力的提升,深度学习也在目标检测这一个方向得到极大的发展,二阶段的目标检测算法具有高精度且能检测小目标的优势,而一阶段的目标检测算法具有二阶段目标检测算法所不能企及的检测速度。采用基于深度学习的手机缺陷检测算法可以在速度上和精度上暂时满足当前手机制造流水线上的检测要求。
3.手机屏幕的组要组成部分有:盖板玻璃、触控模组、显示模组,但盖板玻璃是制造缺陷最容易出现问题的部件,因此盖板玻璃的缺陷检测是缺陷检测的一环。当前计算机视觉中,基于深度学习的缺陷检测主要有三个方面:语义分割方式、目标检测方式、基于gan生成方式。针对手机生产线上仍需要一种检测速度快、易被植入到各种设备上的检测模型。
技术实现要素:
4.为了克服现有的检测算法检测速度不足与部署难度较大的问题,本发明提供一种轻量级手机屏幕缺陷视觉检测方法和系统,用于手机屏幕的缺陷检测。
5.本发明解决其技术问题所采用的技术方案是:
6.一种手机屏幕缺陷视觉检测方法,包括以下步骤:
7.建立基于改进的yolov5s网络的手机屏幕缺陷检测模型;
8.采集手机屏幕缺陷图片,以手机屏幕缺陷图片作为训练样本对所述手机屏幕缺陷检测模型进行训练;
9.将待检测图片输入训练完成的所述手机屏幕缺陷检测模型,通过所述手机屏幕缺陷检测模型得到手机屏幕缺陷检测结果。
10.进一步地,所述手机屏幕缺陷图片中的手机屏幕缺陷包括下列中的至少一种:锯齿缺口、油污、屏幕划痕。
11.进一步地,所述基于改进的yolov5s网络的手机屏幕缺陷检测模型包括:
12.1)改进的ghostbottleneck:在ghostnet的ghostbottleneck中添加se模块,并将coordinate attention加入至ghostbottleneck中以改进其原有的注意力机制;
13.2)轻量化卷积模组:使用深度可分离卷积dwsconv或者深度卷积dwconv作为卷积模组;
14.3)改进的yolov5s网络结构:对yolov5s的主干网络backbone中的c3进行替换处理,将c3替换为改进的ghostbottleneck。
15.进一步地,对所述改进的yolov5s网络结构进行加深处理,包括:在进行卷积操作后,插入9个ghostbottleneck和3个ghostbottleneck。
16.进一步地,所述以手机屏幕缺陷图片作为训练样本对所述手机屏幕缺陷检测模型进行训练,包括:首先通过主干网络对图像进行特征提取,再通过神经网络进行特征学习,最后得到训练完成的手机屏幕缺陷检测模型。
17.一种采用上述方法的手机屏幕缺陷视觉检测系统,其包括:
18.模型建立模块,用于建立基于改进的yolov5s网络的手机屏幕缺陷检测模型;
19.模型训练模块,用于采集手机屏幕缺陷图片,以手机屏幕缺陷图片作为训练样本对所述手机屏幕缺陷检测模型进行训练;
20.缺陷检测模块,用于将待检测图片输入训练完成的所述手机屏幕缺陷检测模型,通过所述手机屏幕缺陷检测模型得到手机屏幕缺陷检测结果。
21.本发明的有益效果是:
22.本发明提出的手机屏幕缺陷视觉检测方案,使用能够进行高速检测的yolov5作为检测器,并在yolov5自带的yolov5s目标检测网络基础上提出一个改进的轻量级目标检测网络ghostbackbone,结合这两个工作便可得到一个轻量级且检测速度快的屏幕缺陷检测模型。
附图说明
23.图1是yolov5的bottleneck架构和conv架构示意图。其中,conv2d表示convolution2d卷积层,bn表示batchnormalization层,silu表示silu激活函数,conv表示经过一个conv2d处理之后再接bn层处理最后由silu激活函数输出的一个综合处理层,add与shortcut表示由两层conv构成的残差结构。
24.图2是yolov5的c3架构示意图。其中,concat表示将m个n维度的输出变为1个m*n维度的输出。
25.图3是yolov5的spp架构示意图。其中,k表示kernel_size,表示maxpooling的窗口大小,maxpoolling表示最大池化。
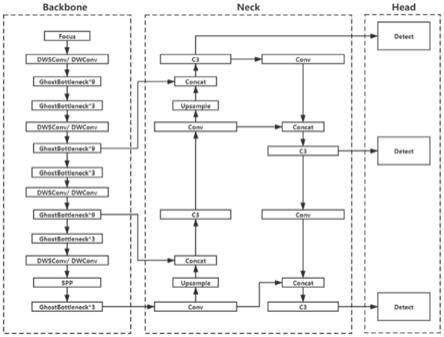
26.图4是ghostbackbone-deep的完整结构图。其中,backbone是特征提取网络的主干网络,neck是为了使主干网络更好地提取特征,head表示根据特征提取网络得到的结果做出预测。
具体实施方式
27.下面通过具体实施例和附图,对本发明做进一步详细说明。
28.本发明以现有的yolov5s与ghostnet为基础,对其加以改进并进行适当的结合。
29.ghostnet说明:ghostnet在yolov5的源代码中由ghostconv和ghostbottleneck组成,ghostconv的作用主要是实现ghostbottleneck的pointwise expansion(逐点展开)和pointwise linear projection(逐点线性处理)这两个操作。如表1所示,在yolov5中ghostbottleneck和华为开源的ghostbottleneck相对比,可以发现se(squeeze-and-excitation,挤压和激发)模块的代码被删除,由于yolov5暂没有正式的论文但从代码角度可以分析出:se模块可以被自行地在backbone中加入,而不是把其固定在bottleneck中并
且使用参数调度。针对某个特征层,ghost module只用卷积生成部分真实特征层,剩余的特征层被称作ghost特征层,ghost特征层并不通过卷积生成,而是对真实特征层进行线性运算计算获得,然后将真实特征层和ghost特征层合并为完成的特征层。相对于以前的网络,ghost module可以比他们进行更少的卷积计算。ghostbottleneck参照了resnet中的残差块结构设计了两种类型ghostbottleneck(g-bneck):一种为步长为1的bottleneck(g-bnecks1);另一种则为步长为2的bottleneck(g-bnecks2)。g-bneck内部中由g-bnecks1和g-bnecks2组成:为了增加通道数目,第一个ghost module用作扩张层;为了与shortcut(残差模块)的通道数匹配,第二个ghost module用来减少通道的数目。
30.表1 yolov5中已实现的ghostbottleneck架构一览
[0031][0032]
yolov5s说明:在yolov5的网络配置中,没有明显的neck设置,因此spp被整合在backbone中,但纵观yolov5s的配置文件不难发现neck为panet,而且从head配置中就能看出在head中包含了panet和detect。如表2所示,yolov5s由四个主要模块组成,分别是:focus,conv(convolution),c3(csp bottleneck with 3convolutions),spp。
[0033]
表2 yolov5s的backbone
[0034]
数量模块模块内参数1focus[64,3]1conv[128,3,2]3c3[128]1conv[256,3,2]9c3[256]1conv[512,3,2]9c3[512]1conv[1024,3,2]1spp[1024,[5,9,13]]3c3[1024,false]
[0035]
a.foucus说明:
[0036]
focus用于对图像进行切片操作,如图4所示。它可以将单个通道内的图像切割为四个通道,这种方法可以让一张较大的图片被切割为像素降低的四张长得差不多的图片,这是为了不丢失信息然后进行二倍下采样获得特征图。focus是一种保留信息,但是会提升计算量的结构。这样获取特征图是普通下采样的flops(浮点运算数)的四倍,flops计算方法如下式所示:
[0037]
flops=cw×ch
×
ch
in
×
ch
out
×h×w[0038]
其中,cw表示卷积窗口的宽,ch表示卷积窗口的高,ch
in
表示数据的输入,ch
out
表示数据的输出,h表示输出特征图的高,w表示输出特征图的宽。
[0039]
当进行focus操作的时候,输入通道变为4倍,即如下式所示:
[0040][0041]
其中,flops(conv)表示采用conv层处理的浮点运算数数量,flops(focus)表示采用focus层处理的浮点运算数数量。
[0042]
b.c3说明:
[0043]
如图1、图2表示,c3代表了有3个卷积层的bottleneckcsp,bottleneckcsp是一个用作于获得图片特征的一个模块,它的主要模块为conv、bottleneck并且如图1所示:第一个conv2d的大小为1*1,然后加入到bn silu中,构成了一个卷积层(kernel size=1*1);第二个也是同样的道理,其kernel size=3*3。
[0044]
c.spp说明:
[0045]
spp指代的是空间金字塔池化操作,这是一种无视输入尺寸并产生固定输出的方法,是用于提升网络感受野的一种方法。它在yolov5(version4.0)的结构如图3所示:
[0046]
根据上述说明,本发明将yolov5s部分加以保留,将轻量级网络部分加以补充,最初的技术路线如下:将现有的ghostbottleneck进行补全、改进;针对yolov5s的网络结构进行改进、加深处理。
[0047]
与现有的技术相比,本发明提出了ghostbackbone(幻影主干网络),它采用了ghostnet中的ghostbottleneck并使用coordinate attention改进其原有的注意力机制,实验证明了ghostbackbone在识别准确度、缺陷检测速度、降参这三个方面上相对于mobilenetv3s和yolov5s有较高的性价比,使得ghostbackbone部署在手机生产线上变为可能。其中,coordinate attention参见:hou,qibin,daquan zhou,and jiashi feng.coordinate attention for efficient mobile network design[j].arxiv preprint arxiv:2103.02907,2021mar 4.
[0048]
上述的技术路线,在下面将以图表的方式对本发明进行详细说明。
[0049]
1.改进ghostbottleneck:
[0050]
已经实现的ghostbottleneck如表1所示,表1中没有集成se模块。因此改进的ghostbottleneck需要添加se模块并把coordinate attention加入至ghostbottleneck中作为可选模块作为对比,改进之后的ghostbottleneck如表3所示:
[0051]
表3改进的ghostbottleneck架构一览
[0052][0053]
其中,coordinate attention是来自新加坡国立大学的qibin hou的现有轻量级注意力机制技术,它将不同方向的1d特征编码进行聚合最后获得感兴趣的区域,并通过这种方法提升对目标的检测注意力。
[0054]
2.使用轻量化卷积模组:
[0055]
在本发明的网络将使用dwsconv(depthwise separable convolution,深度可分离卷积)或者dwconv(depthwise convolution,深度卷积)作为卷积模组,dwsconv与dwconv的参数量相对于正常的卷积参数量都有极大的减少,能显著地降低参数量。以dwsconv参数量计算方法为例:n为参数量,cw为卷积核宽度,ch为卷积核高度,iw为图像宽度,ih为图像高度,nin为输入通道数,nout为输出通道数。
[0056]
一个标准卷积如下式所示:
[0057][0058]
n=
①×②×③
[0059]
一个dwconv如下式所示:
[0060][0061]
n=
①×②×
nout
[0062]
一个pointwise convolution(逐点卷积)如下式所示:
[0063][0064]
n=1
×1×①×②
[0065]
在使用了dwsconv替代标准卷积之后,参数量就可以如下式所示被明显的压缩。
[0066][0067]
其中,(1)表示标准卷积参数量计算式,(2)表示深度卷积参数量计算式,(3)表示逐点卷积参数量计算式。
[0068]
3.改进网络模型:
[0069]
表4展示了本发明的ghostbackbone的最基本的网络架构(ghostbackbone-simple)。
[0070]
表4 ghostbackbone-simple一览
[0071]
数量模块模块内参数1focus[64,3]1dwsconv/dwconv[128,3,2]3ghostbottleneck[128,3,1,option]1dwsconv/dwconv[256,3,2]9ghostbottleneck[256,3,1,option]1dwsconv/dwconv[512,3,2]9ghostbottleneck[512,3,1,option]1dwsconv/dwconv[1024,3,2]1spp[1024,[5,9,13]]3ghostbottleneck[1024,3,1,option]
[0072]
本网络模型由原有的yolov5s的backbone改进而来,本次改进使用了轻量级卷积dwconv卷积和dwsconv,并对c3进行了替换处理(即将c3替换为改进的ghostbottleneck)。但是,后续研究表明,表4网络仍有提升空间,对模型ghostbackbone-simple进行了加深处理,加深之后得到模型ghostbackbone-deep的backbone架构如表5所示:在进行卷积操作后,插入9个ghostbottleneck和3个ghostbottleneck。
[0073]
表5 ghostbackbone-deep的backbone一览
[0074]
数量模块模块内参数1focus[64,3]1dwsconv/dwconv[128,3,2]9ghostbottleneck[128,3,1,option]3ghostbottleneck[128,3,1,option]1dwsconv/dwconv[256,3,2]9ghostbottleneck[256,3,1,option]3ghostbottleneck[256,3,1,option]1dwsconv/dwconv[512,3,2]9ghostbottleneck[512,3,1,option]3ghostbottleneck[512,3,1,option]1dwsconv/dwconv[1024,3,2]1spp[1024,[5,9,13]]3ghostbottleneck[1024,3,1,option]
[0075]
最后完整的网络模型图可被抽象为图4所示。其中,backbone是特征提取网络的主干网络,neck是为了使主干网络更好地提取特征,head表示根据特征提取网络得到的结果做出预测。
[0076]
本发明设计的网络模型在github开源的yolov5(release 4.0)上运行,此版本集
合了训练、测试、检测代码,并且模型代码通过配置文件yaml进行修改。训练和检测步骤如下:
[0077]
1)放置coco格式的数据集文件夹;
[0078]
2)在models文件夹中调整网络模型参数;
[0079]
3)在train.py中调整模型、迭代次数等参数,调整完成之后执行train.py;
[0080]
4)在detect.py修改权重文件、检测硬件等参数,在data文件中的放入待检测图片,并运行detect.py,输出手机屏幕缺陷检测结果。其中,待检测图片是指待检测的手机缺陷图片。
[0081]
如果需要客制化自己的模型,应该把自己的代码植入到experimental.py中,并在yolo.py中的parse_model函数中进行参数上的设置,最后运行yolo.py来测试自己是否设置成功。上述的模型代码,将由本发明组成。
[0082]
综上,本发明的一种手机屏幕缺陷视觉检测方法,包括以下步骤:
[0083]
1)采集各种缺陷的手机屏幕缺陷图片,比如:jag(锯齿缺口)、oil(油污)、screen_scratch(屏幕划痕)。
[0084]
2)训练网络:以手机屏幕缺陷图片作为训练样本,对本发明的改进的yolov5s网络进行训练。首先主干网络会对图像进行特征提取,再通过神经网络进行特征学习,最后得到被训练好的手机屏幕缺陷检测模型。
[0085]
3)缺陷检测:将待检测图片输入训练完成的本发明的改进的yolov5s网络,本网络模型经训练之后可以直接输入一张无预处理的手机屏幕缺陷图片,并利用神经网络对此图像进行特征分析,最后得到手机屏幕缺陷预测检测结果。
[0086]
表6是本发明的检测模型与对比模型(yolov5s)的检测结果。
[0087]
表6
[0088][0089]
基于同一发明构思,本发明的另一实施例提供一种采用上述方法的手机屏幕缺陷视觉检测系统,其包括:
[0090]
模型建立模块,用于建立基于改进的yolov5s网络的手机屏幕缺陷检测模型;
[0091]
模型训练模块,用于采集手机屏幕缺陷图片,以手机屏幕缺陷图片作为训练样本对所述手机屏幕缺陷检测模型进行训练;
[0092]
缺陷检测模块,用于将待检测图片输入训练完成的所述手机屏幕缺陷检测模型,通过所述手机屏幕缺陷检测模型得到手机屏幕缺陷检测结果。
[0093]
基于同一发明构思,本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0094]
基于同一发明构思,本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执
行时,实现本发明方法的各个步骤。
[0095]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。