1.本发明涉及神经网络的训练,所述神经网络例如可以被用作图像分类器。
背景技术:
2.人工神经网络knn借助于处理链将输入(诸如图像)映射到对于相应应用相关的输出,所述处理链通过大量参数被表征并且例如能够以层的形式被组织。例如,图像分类器对于所输入的图像提供:到预先给定的分类的一个或多个类别的分配作为输出。knn被训练,其方式是训练数据被输送给所述knn,并且处理链的参数被优化为使得所提供的输出尽可能好地与属于相应训练数据的、事先已知的额定输出协调一致。
3.所述训练典型地是非常计算耗费的并且与此相应地消耗很多能量。为了减少计算耗费,以名称“剪枝(pruning)”已知的是将参数的一部分设置为零并且不对其进行进一步训练。同时,这从而也抑制“过拟合(overfitting)”的趋势,所述“过拟合”对应于“背诵”训练数据,而不是理解在训练数据中包含的知识。此外,从de 10 2019 205 079 a1中已知:在knn的运行时间(推理(inferenz))对各个计算单元进行去激活,以便节省能量和热生成。
技术实现要素:
4.在本发明的范围中,开发了一种用于训练人工神经网络knn的方法。该knn的行为通过可训练参数表征。例如,可训练参数可以是权重,以所述权重对输送给knn的神经元或其他处理单元的输入进行相加用于激活所述神经元或其他处理单元。
5.在训练开始时,参数被初始化。为此可以使用任意值,诸如随机或伪随机值。重要的仅仅是:所述值不同于零,以便首先(zun
ä
chst)使在神经元或其他处理单元之间的所有连接至少以某种方式是激活的。
6.为了训练,提供训练数据,所述训练数据是用额定输出标记的,knn应该将训练数据分别映射到所述额定输出。将这些训练数据输送给knn并且由knn映射到输出。根据预先给定的成本函数(“损失函数”)评价输出与学习输出(lern-ausgabe)的一致性。
7.根据预先给定的标准(kriterium),从参数的集合中至少选择待训练的参数的第一子集和待保持的参数的第二子集。待训练的参数以如下目标而被优化:通过所述knn对训练数据的进一步处理预计导致通过成本函数的更好评价。分别使待保持的参数保留(belassen auf)在其初始化值或在优化时已经获得的值上。
8.尤其是例如可以在开始训练之前对一方面待训练的参数和另一方面待保持的参数进行选择。但是,也可以例如在训练期间才首次进行该选择,或者根据以前的训练进程而改变该选择。
9.如果例如在训练期间证实特定参数对通过成本函数进行的评价几乎没有影响,则可以将该参数从待训练的参数的集合转移(
ü
berf
ü
hren)到待保持的参数的集合中。于是,所述参数保持在其当前值并且不再被改变。
10.反之,例如在训练期间可能证实:因为没有足够的参数被训练,所以利用成本函数
测量的训练进度停滞。于是可以将更多的参数从待保持的参数的集合转移到待训练的参数的集合中。
11.因此在一种特别有利的扩展方案中,响应于knn的根据所述成本函数测量的训练进度满足预先给定的标准,将至少一个参数从待保持的参数的集合转移到待训练的参数的集合中。预先给定的标准尤其是例如可以包含:在训练步骤期间和/或在训练步骤序列期间成本函数的绝对值和/或以数值方式的(betragsm
äß
ig)变化保持在预先给定的阈值以下。
12.对于被保持的参数,不再为了更新、诸如为了对于各个参数具体变化的成本函数的值或梯度的反向传播(r
ü
ckpropagation)而产生耗费。就此而论,就像是在通过迄今为止的“剪枝”而对参数置零(nullsetzen)的情况下那样节省了计算时间和能量耗费。然而,与“剪枝”不同地,神经元或其他处理单元之间的连接并未完全被放弃,使得较少地为了减少计算耗费而牺牲掉knn的灵活性和表达能力(“可表达性(expressiveness)”)。
13.如果在开始训练之后才决定保持特定的参数,则knn至少在一定程度上已经被设置为已经通过开始时的初始化和可能通过迄今为止的训练所设定(festlegen)的参数的值。在这种情形下,仅仅保持参数是比置零要小得多的干预。与此相应地,通过保持参数而被引入到knn的输出中的误差按趋势(tendenziell)要小于通过对参数置零而引入的误差。
14.结果,因此可以基于以下预给定:仅应对具体knn的参数的特定部分进行训练,通过保持剩余参数而比在“剪枝”范畴内利用将这些剩余参数置零获得更好的训练结果。例如,可以借助于如下测试数据来测量训练结果的质量,所述测试数据在训练期间未曾被使用但是针对自身而言像是针对训练数据那样的所属的额定输出是已知的。knn越好地将测试数据映射到额定输出,训练结果就越好。
15.用于选择待训练的参数的预先给定的标准尤其是例如可以包含参数的相关性评价(relevanzbewertung)。当训练尚未开始时这种相关性评价就已经可供使用:例如至少一个参数的相关性评价可以包含:在至少一个通过训练数据预先给定的点处在激活所述参数之后成本函数的偏导数(partielle ableitung)。因此,例如可以评估:如果与相应的参数相乘的激活从值1开始被改变,则由成本函数对于knn针对特定的训练数据所提供的输出所进行的评价如何发生变化。 与对自身而言所述变化小的参数的训练相比,对自身而言所述变化大的参数的训练预计会更强地对训练结果产生影响。
16.在此情况下,在激活之后成本函数的所述偏导数与在优化期间利用梯度下降法计算的相应参数之后的成本函数的梯度不是意义相同的。
17.以这种方式确定的参数相关性评价将取决于如下训练数据,knn基于所述训练数据来确定所述输出,然后又利用所述输出评估成本函数。如果knn例如被构造为图像分类器,并且基于显示交通标志的训练图像确定相关性评价,则所确定的参数相关性评价尤其是将涉及针对分类交通标志而言的相关性。而相反,如果例如基于来自产品的光学质量控制的训练图像确定该相关性评价,则该相关性评价将尤其是涉及恰好用于该质量控制的相关性。根据应用而定,总体上可用的参数的完全不同的子集可能是特别有关的,这在一定程度上类似于在人脑中不同大脑区域负责不同的认知任务。
18.现在,参数的无论如何还是被提供的相关性评价例如使得能够选择预先给定数量(“前n个(top-n)”)的最相关的参数作为待训练的参数。可替代地或也与之相组合地,可以选择自身的相关性评价比预先给定的阈值更好的参数作为待训练的参数。如果相关性评价
不仅相对彼此来评价所述参数,而是使该评价具有在绝对尺度上的意义,则这尤其是有利的。
19.如先前所阐述的那样,也可以在训练期间设定或事后改变总体可用的参数到待训练的参数和待保持的参数的分配。因此,在另一有利的扩展方案中,针对至少一个参数的相关性评价考虑该可训练参数在优化期间已经历的变化的历史记录(vorgeschichte)。
20.在另一有利的扩展方案中,用于选择待训练的参数的预先给定的标准包含:作为待训练的参数而选择根据预先给定的时间预算和/或硬件资源所确定的数量的参数。这尤其是例如可以以如下方式与相关性评价组合:作为待训练的参数选择与所确定的数量相应的“前n个”最相关的参数。然而,也可以在不考虑相关性的情况下根据预算选择待训练的参数,例如作为从总体可供使用的参数中进行的随机选择。
21.在另一特别有利的扩展方案中,从如下权重中选择待保持的参数,其中以所述权重对输送给所述knn的神经元或其他处理单元的输入进行相加用于激活所述神经元或其他处理单元。而相反地,选择利用所述激活而加性地结算的偏差值(bias-wert)作为待训练的参数。偏差值的数量要比权重的数量小出多倍。同时,保持被应用于由神经元或处理单元的多个输入组成的加权总和的偏差值与保持用于形成所述加权总和的权重相比而言更强烈地对knn的输出产生影响。
22.保持参数本身与在“剪枝”时置零类似地节省了用于更新这些参数的计算时间和能量耗费。同时,如在“剪枝”时那样,减少对于训练数据“过拟合”的趋势。如先前所阐述的那样,与“剪枝”相比的主要收益在于经改善的训练结果。这种改善首先利用所保持的不同于零的参数占用存储空间来换取。
23.在另一特别有利的扩展方案中,这种存储耗费被剧烈减少,其方式是参数利用来自于由确定性算法基于起始配置所产生的数列(zahlenfolge)中的值被初始化。于是,为了以压缩方式存储所有被保持的参数而仅必须存储表征确定性算法的说明以及起始配置。
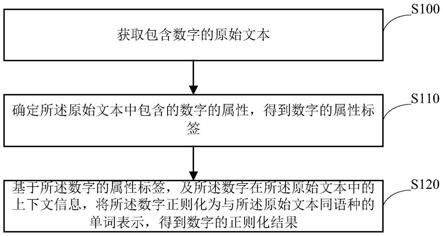
24.从而,完成训练的knn例如也可以以强烈压缩的形式通过网络被输送。在许多应用中,对knn进行训练的实体与稍后按规定使用knn的实体不同。因此,例如,至少部分自动驾驶的车辆的购买者不想先训练该车辆而是想立即使用所述车辆。因为智能电话的计算效率以及电池容量对于训练均是不足够的,所以knn在智能电话上的大部分应用程序也指示出:所述knn是已经训练完成的。在智能电话应用程序的示例中,knn必须要么与应用程序一起被加载到智能电话上要么事后被加载到智能电话上。在所述的强烈压缩的形式下,这特别快速地并且以小的数据量消耗而实现。
25.knn的越多参数在训练期间被保持,存储器节省就越大。例如可以彻底保持knn的99%或更多的权重,而训练结果不显著受害。
26.从中提取用于对参数进行初始化的值的数列尤其是可以例如是伪随机数列。所述初始化于是基本上与利用随机值进行的初始化具有相同的效果。然而当随机值恰好具有最大熵并且不能被压缩的时候,在确定性算法的起始配置中则可以压缩任意长度的伪随机数序列。
27.因此,在一种特别有利的扩展方案中,产生knn的压缩件(komprimat),所述压缩件至少包括:
•
表征所述knn的架构的说明;
•
表征所述确定性算法的说明;
•
用于所述确定性算法的起始配置;和
•
所述待训练的参数的完成训练的值。
28.在一种特别有利的扩展方案中,选择被构造为图像分类器的knn,所述图像分类器将图像映射到对预先给定的分类的一个或多个类别的分配。恰好在该knn的这种应用情况下,可以在训练期间保持参数的特别大的部分,而所述分类的在结束训练之后实现的精度并不显著受害。
29.本发明还提供另一方法。在该方法的范畴内,首先利用先前描述的方法对人工神经网络knn进行训练。随后将已经利用至少一个传感器记录的测量数据输送给knn。测量数据尤其是可以例如是图像数据、视频数据、雷达数据、激光雷达数据或超声数据。
30.由kkn将测量数据映射到输出。根据如此获得的输出生成操控信号。利用所述操控信号操控车辆、对象识别系统、用于对产品进行质量控制的系统和/或用于医学成像的系统。
31.利用先前描述的方法进行训练在此上下文中引起:可以使knn能够更快速地根据测量数据产生有意义的输出,使得最终生成操控信号,分别被操控的技术系统以对于以感测方式所检测的情形而言适当的方式对所述操控信号作出反应。一方面,节省计算耗费,使得训练总体上更快速地运行。另一方面,完成训练的knn可以更快速地从对所述knn进行了训练的实体被转移(transportieren)到运行待操控的技术系统并且为此需要knn的输出的实体。
32.先前描述的方法尤其是可以例如是以计算机实现的并且因此以软件来体现。因此,本发明还涉及一种具有机器可读指令的计算机程序,当所述机器可读指令在一个或多个计算机上被执行时,所述机器可读指令促使所述一个或多个计算机执行所描述的方法之一。在该意义上说,同样能够执行机器可读指令的用于车辆的控制设备和用于技术设备的嵌入式系统也应被视为计算机。
33.本发明还涉及具有计算机程序的机器可读数据载体和/或下载产品。下载产品是可以通过数据网络传输的、即可以由数据网络的用户下载的数字产品,所述数字产品可以例如在线上商店中被出售用于立即下载。
34.此外,计算机可以装备有计算机程序、机器可读数据载体或下载产品。
附图说明
35.下面与根据附图对本发明优选实施例的描述一起来进一步示出改善本发明的其他措施。
36.图1示出用于训练knn 1的方法100的实施例;图2示出方法200的实施例;图3示出与在“剪枝”时的置零相比而言对参数12b的保持对knn 1的性能的影响。
具体实施方式
37.图1是用于训练knn 1的方法100的一种实施例的示意流程图。在步骤105中,可选地选择knn 1,所述knn被构造为图像分类器。
38.在步骤110,knn 1的可训练参数12被初始化。根据块111,用于该初始化的值可以尤其是例如从数列中得到(beziehen),确定性算法16基于起始配置16a提供所述数列。根据块111a,数列可以尤其是例如是伪随机数列。
39.在步骤120中,提供训练数据11a。这些训练数据是用额定输出13a标记的,knn 1应该分别将训练数据11a映射到所述额定输出13a。
40.训练数据11a在步骤130中被输送给knn 1,并且由knn 1映射到输出13。在步骤140中根据预先给定的成本函数14评价这些输出13与学习输出13a的一致性。
41.根据预先给定的标准15,从参数12的集合中至少选择待训练的参数12a的第一子集和待保持的参数12b的第二子集,所述预先给定的标准尤其是例如也可以利用评价14a。预先给定的标准15尤其是可以例如包含参数12的相关性评价15a。
42.待训练的参数12a在步骤160中以如下目标被优化:通过knn 1对训练数据11a的进一步处理预计导致通过成本函数14的更好评价14a。要训练的参数12a的完成训练的状态用附图标记12a*标出。
43.待保持的参数12b在步骤170中分别被保留在其初始化值或在优化160时已得到的值上。
44.在考虑完成训练的参数12a*、确定性算法16以及其起始配置16a的情况下,可以在步骤180中形成knn 1的压缩件1a,所述压缩件1a与原则上在knn 1中可供使用的参数12的完整集相比是极其紧凑的(kompakt)。在无knn 1的性能的可察觉的损失的情况下可能的是:以数量级150的因子进行压缩。
45.在框150内给出如下多种示例性可能性:如何能够从总共可供使用的参数12中一方面选择待训练的参数12a以及另一方面选择待保持的参数12b。
46.根据块151,例如可以选择预先给定数量的“前n个(top-n)”最相关的参数12和/或自身的相关性评价15a比预先给定阈值更好的这种参数12作为待训练的参数12a。
47.根据块152,例如可以选择基于预先给定的时间预算和/或硬件资源确定的数量的参数12作为待训练的参数12a。
48.根据块153,例如可以从权重中选择待保持的参数12b,以所述权重对输送给knn1的神经元或其他处理单元的输入进行相加用于激活所述神经元或其他处理单元。而相反地,根据块154可以选择可以利用所述激活加性地结算(verrechnen)的偏差值作为待训练的参数12a。因此,待训练的参数12a包括所有偏差值,但是仅包括所述权重的一小部分。
49.根据块155,响应于knn 1的根据成本函数14测量的训练进度满足预先给定的标准17,可以将至少一个参数12从待保持的参数12b的集合转移到待训练的参数12a的集合中。
50.图2是方法200的一种实施例的示意流程图。在步骤210中,利用上述方法100训练knn 1。在步骤220中,将已利用至少一个传感器2记录的测量数据11输送给该knn 1。在步骤230中,由knn 1将测量数据11映射到输出13。在步骤240中根据这些输出13生成操控信号240a。在步骤250中,利用操控信号240a操控车辆50、对象识别系统60、用于产品质量控制(qualit
ä
tskontrolle)的系统70和/或用于医学成像的系统80。
51.图3根据两个示例示出:如果作为不待训练的参数12b的不待训练的权重不被设置为零而是取而代之地被保持在其当前状态下,则被用作图像分类器的knn 1的分类精度a随着这些权重12b的配额(quote)q而变好多少。在图表(a)和(b)中,分别关于配额q绘制分类
精度a。而相反,在knn 1中利用激活加性地结算的所有偏差值继续被训练。因此根据图1中的块153选择不待训练的参数12b,并且根据图1中的块154选择偏差值作为待训练的参数12a。因此,即使配额为q=1时,分类能力也仍然不会被降到随机猜测(raten)的分类能力。
52.图表(a)涉及架构“lenet-300-100”的knn 1,所述架构已基于用于对来自mnist数据集的手写数字进行分类的任务被训练。水平线(i)代表当所有可训练的参数12实际上被训练时可达成的最大分类精度a。曲线(ii)显示当参数12的相应配额q被保持在其当前状况并且不进一步被训练时出现的分类精度a的下降。曲线(iii)显示当替代于此地利用snip算法(“基于连接敏感度的单次网络剪枝(
„
single-shot network pruning based on connection sensitivity“)”)选择参数12的相应配额q并且将这些参数设置为零时出现的分类精度a的下降。曲线(i)至(iii)分别利用置信区间予以说明,其中针对曲线(i)的方差消失。
53.图表(b)涉及架构“lenet-5-caffe”的knn 1,所述架构已同样基于用于对来自mnist数据集的手写数字进行分类的任务被训练。类似于图表(a),水平线(i)代表当knn 1的所有可用参数12实际上被训练时出现的最大分类精度a。曲线(ii)显示当参数12的相应配额q被保持时出现的分类精度a的下降。曲线(iii)显示当代替地利用snip算法(“基于连接敏感性的单次网络剪枝”)选择参数12的相应配额q并且将这些参数设置为零时出现的分类精度a的下降。
54.在两个图表(a)和(b)中,一方面参数12的保持与另一方面参数12的置零之间的质量差异随着不待训练的参数12的配额q增加而变得越来越大。当将参数12置零时,此外分别存在临界配额q,在该临界配额的情况下,分类精度a突然急剧崩溃。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。