1.本发明涉及智能设备领域,特别是涉及一种基于时间关系抽取文本因果 关系的方法及系统。
背景技术:
2.因果关系抽取任务是nlp(neuro-logical pattern,思维逻辑层次)中一 个基本任务,因果关系抽取是获取文本中实体间的原因和结果关系,通过因 果分析可以进行事件的预测和推理事件发生的诱因。因果关系抽取可以应用 于多种领域,如金融、医学推理分析等。因果关系抽取还常常使用在问答系 统中,对于各种的提问帮助给出问题的原因。而时间关系对于因果关系的提 取具有重要的作用。
3.目前利用事件之间的时间关系进行因果推理的模型很少。mostafazadeh 等人提出了一种标注结构(caters),通过大量故事类事件获得因果关系 相关的时间关系判别。ning等人提出了一个联合学习框架tcr,综合条件 约束模型和整数线性规划,推断符合特定规则的事件因果关系。以上两个典 型工作局限于采用特征工程和统计机器学习方法;而且,因果关系一定具有 时间关系,但时间关系不一定伴随因果关系,并且,缺乏同时标记两种关系 的公开数据集;因此,需要一种平衡时间信息对因果关系抽取影响的均衡机 制,提高利用事件之间的时间关系进行因果推理得到的因果关系的准确性。
技术实现要素:
4.本发明的目的是提供一种基于时间关系抽取文本因果关系的方法及系 统,能够提高因果关系抽取的准确性。
5.为实现上述目的,本发明提供了如下方案:
6.一种基于时间关系抽取文本因果关系的方法及系统,所述方法包括:
7.对句子中的词之间的关系进行标注,生成关系矩阵;
8.构建tc-gat模型;
9.通过所述句子中的词和所述关系矩阵对所述tc-gat模型进行训练;
10.通过训练好的tc-gat模型抽取所述句子的因果关系。
11.可选的,所述tc-gat模型包括bilstm模型、gat模型、bert模型 和均衡机制的门控模型。
12.可选的,所述通过所述句子中的词和所述关系矩阵对所述tc-gat模型 进行训练,具体包括:
13.以所述句子中的词为输入,对bilstm模型进行训练,输出为所述句子 中的词的双向向量;
14.以所述句子中的词的双向向量和所述关系矩阵为输入,对gat模型进 行训练,输出为所述句子中的词的图注意力特征;
15.以所述句子中的词为输入,对bert模型进行训练,输出为所述句子中 的词的状
态;
16.将所述句子中的词的状态与所述句子中的词的词嵌入进行向量拼接,得 到所述句子中的词的自注意力特征;
17.以所述句子中的词的图注意力特征和所述句子中的词的自注意力特征 作为输入,对均衡机制的门控模型进行训练,得到所述句子的因果关系。
18.可选的,所述bilstm模型为:
19.h
bilstm
=bilstm([e1,...,e
t
,...,e
l
]);
[0020][0021]
其中,e
t
∈ir
l
×n为第t个词嵌入,l为句子的长度,为由bilstm生 成的句中第t个词的双向向量表示,为前向lstm获得的输出,为后向 lstm获得的输出,h
bilstm
为bilstm模型的输出。
[0022]
可选的,所述均衡机制的门控模型为:
[0023][0024][0025]
其中,wg为参数矩阵,bg为偏置项,为向量拼接操作,g为均衡系数, h
t
′
为最后均衡机制输出的向量表示,α∈ir
2l
×m为系数权重矩阵,为由bert 的顶层四个隐藏层产生的第t个词的状态与词嵌入之和,为句子中的词的 图注意力特征。
[0026]
一种基于时间关系抽取文本因果关系的系统,所述系统包括:标注模块 和构建模块;
[0027]
所述标注模块,用于对句子中的词之间的关系进行标注,生成关系矩阵;
[0028]
所述构建模块,用于构建tc-gat模型,以所述句子中的词和对应的所 述关系矩阵为输入,对所述tc-gat模型进行训练,输出为所述句子的因果 关系。
[0029]
可选的,所述构建模块包括bilstm模型模块、gat模型模块、bert 模型模块和均衡机制的门控模型模块。
[0030]
可选的,所述bilstm模型模块,用于以所述句子中的词的词嵌入为输 入,对输入双向长时记忆网络模型进行训练,输出为所述句子中的词的双向 向量;
[0031]
所述gat模型模块,用于以所述句子中的词的双向向量和所述关系矩 阵为输入,对图注意力网络模型进行训练,输出为所述句子中的词的图注意 力特征;
[0032]
所述bert模型模块包括bert预训练的语言表征模型单元和拼接单 元;所述bert预训练的语言表征模型单元,用于以所述句子中的词为输入, 对bert预训练的语言表征模型进行训练,输出为所述句子中的词的状态; 所述拼接单元,用于将所述句子中的词的状态与所述句子中的词的词嵌入进 行向量拼接,得到所述句子中的词的自注意力特征;
[0033]
所述注意力均衡机制的门控模型模块,用于以所述句子中的词的图注意 力特征和所述句子中的词的自注意力特征作为输入,对均衡机制的门控模型 进行训练,得到所述句子的因果关系。
[0034]
可选的,所述bilstm模型为:
[0035]hbilstm
=bilstm([e1,...,e
t
,...,e
l
]);
[0036][0037]
其中,e
t
∈ir
l
×n为第t个词嵌入,l为句子的长度,为由bilstm生 成的句中第t个词的双向向量表示,为前向lstm获得的输出,为后向lstm 获得的输出,h
bilstm
为bilstm模型的输出。
[0038]
可选的,所述均衡机制的门控模型为:
[0039][0040][0041]
其中,wg为参数矩阵,bg为偏置项,为向量拼接操作,g为均衡系数, h
t
′
为最后均衡机制输出的向量表示,α∈ir
2l
×m为系数权重矩阵,为由bert 的顶层四个隐藏层产生的第t个词的状态与词嵌入之和,为句子中的词的 图注意力特征。
[0042]
根据本发明提供的具体实施例,本发明公开了以下技术效果:
[0043]
本发明提供的一种基于时间关系抽取文本因果关系的方法及系统,包 括:对句子中的词之间的关系进行标注,生成关系矩阵;构建tc-gat模型; 通过所述句子中的词和所述关系矩阵对所述tc-gat模型进行训练;通过训 练好的tc-gat模型抽取所述句子的因果关系。本发明通过均衡图注意力机 制和自注意力机制的图神经网络模型,提高因果关系抽取准确度的方法。
附图说明
[0044]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实 施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅 仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性 劳动性的前提下,还可以根据这些附图获得其他的附图。
[0045]
图1为本发明基于时间关系抽取文本因果关系的方法的流程图;
[0046]
图2为本发明基于时间关系抽取文本因果关系的系统的结构框图;
[0047]
图3为本发明时间轴上的时间顺序示意图;
[0048]
图4为本发明对句子中的词之间的关系进行标注的示意图;
[0049]
图5为本发明构建的tc-gat模型整体框架图;
[0050]
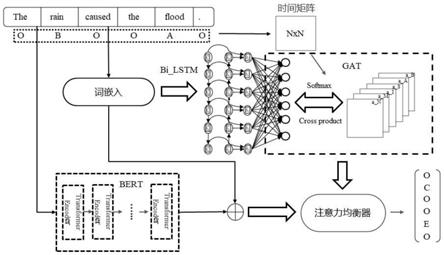
图6为本发明构建的tc-gat模型中的gat的网络结构图;
[0051]
图7为本发明对句子中的词之间的关系矩阵的示意图;
[0052]
图8为semeval2010 task8数据集中精度(p)、召回率(r)和f1评分(f) 的比较结果示意图;
[0053]
图9为tc-altlex数据集中精度(p)、召回率(r)和f1评分(f)的比较结果 示意图;
[0054]
图10为本发明对新闻例句进行标注得到对应的时间关系示意图;
[0055]
图11为本发明应用tc-gat模型对新闻例句提前因果关系的结果示意 图。
[0056]
符号说明:
[0057]
标注模块—1,构建模块—2,bilstm模型模块—3,gat模型模块—4, bert模型模块—5,均衡机制的门控模型模块—6。
具体实施方式
[0058]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行 清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而 不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做 出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0059]
本发明的目的是提供一种基于时间关系抽取文本因果关系的方法及系 统,能够提高因果关系抽取的准确性。
[0060]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图 和具体实施方式对本发明作进一步详细的说明。
[0061]
如图1所示,本发明提供的基于时间关系抽取文本因果关系的方法,包 括:
[0062]
步骤101:对句子中的词之间的关系进行标注,生成关系矩阵。
[0063]
步骤102:构建tc-gat模型。具体的,tc-gat模型包括bilstm模 型、gat模型、bert模型和均衡机制的门控模型。
[0064]
步骤103:通过句子中的词和关系矩阵对tc-gat模型进行训练。具体 包括:
[0065]
以句子中的词为输入,对bilstm模型进行训练,输出为句子中的词的 双向向量。
[0066]
具体的,bilstm模型为:
[0067]hbilstm
=bilstm([e1,...,e
t
,...,e
l
]);
[0068][0069]
其中,e
t
∈ir
l
×n为第t个词嵌入,l为句子的长度,n为句子的维度,为由bilstm生成的句中第t个词的双向向量表示,为前向lstm获得的输 出,为后向lstm获得的输出,h
bilstm
为bilstm模型的输出。
[0070]
以句子中的词的双向向量和关系矩阵为输入,对gat模型进行训练, 输出为句子中的词的图注意力特征。
[0071]
以句子中的词为输入,对bert模型进行训练,输出为句子中的词的状 态。
[0072]
将句子中的词的状态与句子中的词的词嵌入进行向量拼接,得到句子中 的词的自注意力特征。
[0073]
以句子中的词的图注意力特征和句子中的词的自注意力特征作为输入, 对均衡机制的门控模型进行训练,得到句子的因果关系。
[0074]
具体的,均衡机制的门控模型为:
[0075][0076][0077]
其中,wg为参数矩阵,bg为偏置项,为向量拼接操作,g为均衡系数, h
′
t
为最后均衡机制输出的向量表示,α∈ir
2l
×m为系数权重矩阵,l为句子长度, m为系数权重矩阵的维度,为由bert的顶层四个隐藏层产生的第t个词 的状态与词嵌入之和,为句子中的词
的图注意力特征。
[0078]
步骤104:通过训练好的tc-gat模型抽取句子的因果关系。
[0079]
如图2所示,本发明提供的基于时间关系抽取文本因果关系的系统,包 括:标注模块1和构建模块2。
[0080]
标注模块1,用于对句子中的词之间的关系进行标注,生成关系矩阵。
[0081]
构建模块2,用于构建tc-gat模型,以句子中的词和对应的关系矩阵 为输入,对tc-gat模型进行训练,输出为句子的因果关系。具体的,构建 模块2包括bilstm模型模块3、gat模型模块4、bert模型模块5和均 衡机制的门控模型模块6。
[0082]
进一步的,bilstm模型模块3,用于以句子中的词的词嵌入为输入, 对输入双向长时记忆网络模型进行训练,输出为句子中的词的双向向量。具 体的,bilstm模型为:
[0083]hbilstm
=bilstm([e1,...,e
t
,...,e
l
]);
[0084][0085]
其中,e
t
∈ir
l
×n为第t个词嵌入,l为句子的长度,n为句子的维度,为由bilstm生成的句中第t个词的双向向量表示,为前向lstm获得的输 出,为后向lstm获得的输出,h
bilstm
为bilstm模型的输出。
[0086]
gat模型模块4,用于以句子中的词的双向向量和关系矩阵为输入,对 图注意力网络模型进行训练,输出为句子中的词的图注意力特征。
[0087]
bert模型模块5包括bert预训练的语言表征模型单元和拼接单元; bert预训练的语言表征模型单元,用于以句子中的词为输入,对bert预 训练的语言表征模型进行训练,输出为句子中的词的状态;拼接单元,用于 将句子中的词的状态与句子中的词的词嵌入进行向量拼接,得到句子中的词 的自注意力特征。
[0088]
均衡机制的门控模型模块6,用于以句子中的词的图注意力特征和句子 中的词的自注意力特征作为输入,对均衡机制的门控模型进行训练,得到句 子的因果关系。具体的,可选的,均衡机制的门控模型为:
[0089][0090][0091]
其中,wg为参数矩阵,bg为偏置项,为向量拼接操作,g为均衡系数, h
t
′
为最后均衡机制输出的向量表示,α∈ir
2l
×m为系数权重矩阵,l为句子长度, m为系数权重矩阵的维度,为由bert的顶层四个隐藏层产生的第t个词 的状态与词嵌入之和,为句子中的词的图注意力特征。
[0092]
本发明提供的种基于时间关系抽取文本因果关系的方法及系统应用在 信息抽取场景中。在信息抽取场景中,多数实体和事件相互依赖,常呈现共 现关系,而因果关系抽取的目的是在描述事件的文本中标注因果实体。通过 总结发现,因果关系的发生往往伴随着时间线索,即:
[0093]
第一,原因发生在结果之前,结果发生在原因之后。
[0094]
第二,与原因(结果)事件同时发生的事件具有较高的概率是结果(原 因)事件。
[0095]
第三,包含原因实体的事件具有较高的概率是原因事件,反之亦然。
[0096]
如图3所示,为了便于说明时间关系和因果关系之间的关系,举两个时 间关系和因果关系共现的例子,具体如下所示:
[0097]
具体举例1,the《e1:rain》casedthe《e2:floods》.
[0098]
具体举例2,heavy《e1:rain》has been falling,causing《e2:floods》, people’s houses were《e3:damaged》,and somepeople《e4:died》inthe flood。
[0099]
具体举例1是一个简单的时间关系,即“rain”(原因)发生在“floods”(之 前),包含一堆因果关系实体。具体举例2则表述了一个复杂的时间关系,
ꢀ“
rain”包含“flood”,由于时间的对称性,“flood”也涉及到关系中,而“damaged
”ꢀ
和“died”同时发生,都在“rain”和“flood”之后出现,作为原因“rain”导致的结 果。因此,预测因果关系可以从考虑时间关系中受益。此外,时间关系和因 果关系信息的使用可以更好地提升下游任务表现,如对话生成、机器阅读理 解和知识图谱构建等。
[0100]
本发明提供的种基于时间关系抽取文本因果关系的方法及系统的设计 思路如下所述:
[0101]
为了充分利用文本中的时间信息,构建每个句子的时间关系图,本发明 首先在现有方法的基础上,设计了一套可以充分表征句中事件之间时间关系 的标注体系,能够生成关系矩阵。
[0102]
时间关系反映在实体的整个生命周期中。受实体生命周期的影响,时间 关系可以简要划分为五种类型:before(b),after(a),include(i),be included (n),simultaneous(s)。更细粒度的划分会产生更多的类型,增加数据标注 的难度,同时降低因果关系提取的性能。
[0103]
具体的,如图3所示,对于5个事件e1、e2、e3、e4和e5,e1发生在 e2、e3、e4和e5之前。由于时间关系的对称性,e2、e3、e4和e5发生在e1 之后;而e2和e3同时发生,e4、e5属于包含和被包含关系。由于当前公开 的因果关系数据集不包含时间关系信息,本发明根据上述规则提出了一种带 有时间关系的数据标注模式,能够生成关系矩阵。如图4所示,该标注体系 主要包括时间标签和因果标签。对于实体来说,自身是以r为标记,然后是 其对应的时间关系和其他实体。进一步的,r表示实体存在时间关系,m表 示时间关系中自身,b和a分别表示事件rain与flood之间的时间关系分别 为发生在之前和之后。
[0104]
如图5所示,本发明提出了利用时间关系预测因果关系的模型tc-gat (temporal-causalityby graphattentionnetwork),模型由两个主要步骤组 成:第一步:将时间关系引入因果关系抽取,通过图神经网络,获得时间信 息的图注意力表示,通过bert编码句子,获得上下文信息的自注意力表示; 第二步,运用均衡机制机制,平衡时间信息和自注意力信息对因果关系抽取 的影响。首先,通过词嵌入得到包含因果实体的句子的向量表示。然后进入 本方法设计的两条平行的信息流动路径:一条是将句子向量输入bilstm进 行浅层编码,然后基于时间关系信息,以词为节点,bilstm输出为节点初 始向量,构建图网络,通过gat得到基于图注意力的特征向量;另一条是 将词嵌入拼接到bert中进行深层编码,以获得基于自注意力的特征向量。 最后,将两种特征通过均衡机制进行调节,实现抽取因果实体;具体的,初 始化阶段,根据本专利提出的标注体系给出了输入句子中事件的时间关系, 经过图注意力和自注意力两条信息路径后,进行特征融合,最终得到图5中 右下角的标签序列,即rain为原因(cause,c),flood为结果(effect,e)。
[0105]
其中,基于图注意力的特征通过bilstm模型和gat模型获得。
[0106]
进一步的,双向长时记忆网络(bilstm)有三种门结构(输入门、遗忘 门和输出门),以便选择性地忘记部分历史信息,增加部分当前输入信息, 并包含从前到后、从后到前的时间可变特征,最终集成到当前时间步并产生 一个输出状态。bilstm因其每一个时间步可对应一个词、组合两个方向信 息的特点,在自然语言处理任务中得到广泛应用。根据上述优点,考虑到表 征事件之间时间关系的图结构更为注重事件的位置和指向,不需要复杂的语 义理解,因此本发明采用bilstm进行浅层编码。将句子x对应的词嵌入作 为bilstm的输入,输出上下文状态:
[0107]hbilstm
=bilstm([e1,...,e
t
,...,e
l
]);
[0108][0109]
其中,e
t
∈ir
l
×n为第t个词嵌入,l为句子的长度,n为句子的维度,为由bilstm生成的句中第t个词的双向向量表示,为前向长短期记忆获 得的输出,为后向长短期记忆获得的输出,h
bilstm
为bilstm模型的输出。
[0110]
进一步的,如图6所示,图注意力网络(gat)提出了一种利用注意机 制对相邻节点特征进行加权求和的方法。相邻节点特征的权重完全取决于节 点特征,与图结构无关。gat以注意力机制取代图卷积网络(gcn)中固 定的标准化操作。从本质上讲,gat将原始的gcn标准化函数与使用注意 权重的邻居节点特征聚合函数相结合。在本发明的模型中,我们利用gat 来获得时间关系的注意权值,可以有效地将不同的时间关系集成到模型中。 与gcn相比,gat表明了各个时间关系以及关系内各个事件词的重要性, 有助于提高预测的准确性。
[0111]
为构建时间关系图,首先,利用句子中的时间标签生成时间矩阵。如图 7所示,每个单词标记为自环时间关系m;没有时间关系的单词之间标记为 o;相互时间关系包括表示发生顺序的a(after)、b(before)和s (simultaneous),表示从属关系的n(be-include)和i(include)。由此得 到对应的矩阵adja、adjb、adjs、adjn和adji,分别对应于五种类型的相互时 间关系,以及自环时间关系矩阵adjm。
[0112]
具体的,我们以自环时间关系和五种相互时间关系为结点计算相似系 数,以单词自身的m作为每种相互时间类型的邻接节点,即:
[0113]er
=α([h
t
wm,h
t
wr]);
[0114]
其中,wr∈n×m是每种时间关系的权重矩阵,是以 bilstm输出初始化的节点特征,α∈ir
2l
×m是系数权重矩阵,t表示第t个词, h
t
表示上一层的输出,wm表示对应m关系的权重系数,er表示相似系数。
[0115]
在得到相似系数后,便可以合并各类关系矩阵,即:
[0116][0117]
其中,αr为关系的注意力权重,adjr∈{adjb,adja,adjs,adji,adjm,adjn}为 对应的时间关系矩阵,k为r中的一种关系,ek表示对应时间关系的相似系 数,leakyrelu(er)和leakyrelu(ek)均为激活函数。
[0118]
根据计算得到的注意权重,可以更新节点特征,即:
[0119][0120]
其中,表示获得的特征输出,σ表示sigmoid函数,wr′
表示对应时间 关系的权重系数。
[0121]
最后,本发明还利用多头注意力机制,将特征划分为多个子空间,再将 各个子空间的节点特征合并,得出最终结果,即:
[0122][0123]
其中,k表示多头注意力机制的多个头的个数,k和t均表示计数,没 有实际意义,h
t
表示上一层的输出,表示第k个头对应时间关系的注意力 权重,w
rk
表示第k个头对应的时间关系权重。
[0124]
具体的,基于自注意力的特征通过bert模型获得。
[0125]
进一步的,bert是当今最著名的预训练语言模型之一,该方法认为传 统的单向语言模型或两种单向语言模型的浅层拼接方法不适用于预训练,提 出了更高效的掩码语言模型,它可以生成语义信息更丰富的向量表示。
[0126]
在本发明的模型中,我们利用前面词嵌入得到的向量融入bert模块中, 以约束两条信息流动路径学习文本表示时不会差异过大。在bert中,对于 句子s中的每个词,其嵌入表示(embedding)都是通过与其对应的词嵌入 (word embedding)、分段嵌入(segment embedding)和位置嵌入(position
ꢀꢀ
embedding)相加而生成的。然后在句子首尾填充标识符,cls代表句子的 开头,sep表示句子的结尾,则bert后续transformer的输入为[cls,es,sep], 即:
[0127]hbert
=bert([cls,x1,...,x
t
,...,x
l
,sep]);
[0128][0129]
其中,e
t
∈irn表示基于图注意力特征的路径中使用的第t个词的词嵌入,表示由bert的顶层四个隐藏层产生的第t个词的状态与词嵌入之和,es表示句子s的嵌入表示,h
bert
表示由bert获得的输出表示,x
t
表示句子中 的第t个词,l表示句子长度,和分别表示bert模型的后四 层的输出。
[0130]
具体的,通过注意力均衡机制平衡时间关系对因果关系的影响。
[0131]
进一步的,时间关系对因果关系抽取有一定的负面影响。由于事件实体 的出现常常含有时间顺序,但事件之间不一定存在明显的因果关系。因此具 有时间关系的事件实体会影响模型对因果关系的判断。所以本发明提出了均 衡机制单元,目的是通过学习一个信息门控,来平衡时间关系对因果关系的 影响,即控制基于图注意力的特征和基于自注意力的特征对于词t的最终向 量表示的影响程度。均衡机制的门控设计如下:
[0132][0133]
[0134]
其中,wg为参数矩阵,bg为偏置项,为向量拼接操作,g为均衡系数, h
t
′
为最后均衡机制输出的向量表示,α∈ir
2l
×m为系数权重矩阵,l为句子长度, m为系数权重矩阵的维度,为由bert的顶层四个隐藏层产生的第t个词 的状态与词嵌入之和,为句子中的词的图注意力特征。
[0135]
最后,对tc-gat模型预测与优化,具体包括:
[0136]
首先,为了预测输入句子对应的标签序列,将经过均衡机制得到的词特 征映射到标签空间,然后进行归一化,即:
[0137]
p(x
t
)=softmax(w
oh′
t
bo);
[0138]
其中,p(x
t
)表示句子第t个词的预测值,wo表示权重,bo表示偏移值, o表示对前面值的区分。
[0139]
其次,在训练中,我们以交叉熵损失函数作为模型优化目标,即:
[0140][0141]
其中,l表示损失值,t表示第t个词,l表示句子长度,y
t
表示第t个 词的真实标签。
[0142]
本发明提供的tc-gat模型在两个数据集semeval2010 task8和 tc-altlex上的实验结果,相对于现有基于深度学习的基线模型,因果关系 抽取精度更高,具有更好的性能。
[0143]
此外,如图8所示,与semeval2010 task8数据集相比,新标注的数据 集tc-altlex除因果关系外,采用人工标记时间关系,包含较少的重复因果 实体,大多数句子包含多对因果实体,时间关系更随机、更复杂,带来的负 面影响也更大。因此,所有基线模型的精度都会降低。然而,我们的模型仍 然可以得到较好的结果,这表明我们的模型泛化性更强,更稳定。
[0144]
如图9所示,在实验中,lstm、bilstm、bert和bilstm crf模 型没有使用时间关系,抽取结果只能依靠上下文特征获得,总体性能较差。 在引入时间关系后,c-gcn和本发明的tc-gat模型的抽取效果都有了明 显提高,证明时间关系对因果关系的识别有着积极的影响。同时,比较c-gcn 模型和tc-gat模型,我们发现均衡机制的引入对抵消时间关系的负面影响 有很好的效果。
[0145]
本发明提出的基于深度学习的模型tc-gat,该模型利用深度神经网络 基于时间关系抽取因果关系。具体地,首先利用图注意力网络gat获取建 模句子的时间信息,其次通过bert编码句子的上下文信息。虽然时间信息 可以直观地表征因果关系,但它同时对预测产生了负面影响,即因果关系一 定具有时间关系,但时间关系不一定伴随因果关系。因此,本发明提出了一 种平衡时间信息对因果关系抽取影响的均衡机制。对比实验表明,该方法显 著提高了因果关系抽取的准确性。
[0146]
利用时间关系发现因果关系的另一个主要障碍是缺乏同时标记两种关 系的公开数据集。本发明设计了一种表征时间关系信息的标注模式。我们在 两个数据集上进行了实践:第一,在semeval2010 task8数据集中添加时间 标签,并选择其他关系样本作为负样本添加时间标签;第二,从维基百科因 果关系语料中采样部分数据,同时使用时间标签和因果标签对句子进行人工 标注。
[0147]
如图10和图11所示,作为本发明提供的基于时间关系抽取文本因果关 系的方法及系统的一种实施方式的实施例,本发明可以应用于当下疫情,通 过这种深度学习的方法
来对当下热点的疫情问题进行辅助和参考,提高防控 的方法。
[0148]
具体的,新闻例句:“the new coronavirus spreads easily and quickly.itmultiplies in the lungs ofthe human body and invades the lung cells,causing thenecrosis and hardening of the lung cells,causing the human body to havedifficulty breathing and severe suffocation to death.”对这一新闻例句进行标 注,得到对应的时间关系如图10所示。
[0149]
通过数据预处理后输入到本发明提供的tc-gat模型中,得到结果如图 11所示。根据图11所示的实验结果,可以得到:“multiplies”和“invade
”ꢀ
是原因,“necrosis”、“hardening”、“body”和“severe”是结果,表明 新冠病毒是通过繁殖,侵占肺部细胞致使肺部细胞坏死硬化。预测结果整体 看是准确的。
[0150]
在本发明中,涉及到的英文单词对应的中文表示如下所示:
[0151]
bert(bidirectional encoder representation from transformers)基于 transformer的双向编码表示;
[0152]
gat(graphattentionnetwork)图注意力网络;
[0153]
gcn(graph convolutionnetwork)图卷积网络;
[0154]
sa(selfattention)自注意力;
[0155]
bilstm(bi-directional long short-term memory)双向长短期记忆模 型;
[0156]
mlm(maskedlanguage model)掩码语言模型。
[0157]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都 是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。 本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例 的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的 一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改 变之处。综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
