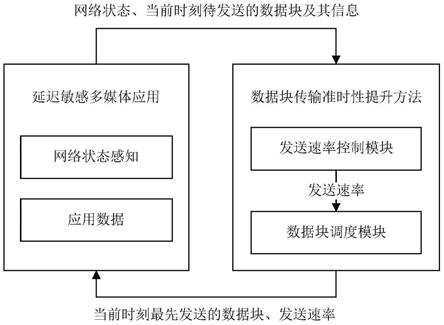
1.本发明涉及多媒体领域,具体为用于延迟敏感多媒体应用的一种基于强化学习的数据块传输准时性提升方法。
背景技术:
2.目前,实时或交互式媒体应用程序(如在线课程、视频会议等)需要低延迟以满足其多种服务的要求。这些延迟敏感多媒体应用程序通常用数据块来传输数据。数据块不能按时到达会严重影响用户体验,如视频会议过程中卡顿可能导致用户更换视频会议应用。延迟敏感应用程序应该在最大可接受的端到端延迟内将每个数据块传输完毕,保证每个数据块的传输都具有准时性。
3.数据块的发送速率是影响数据块准时性的一个重要因素,可以通过调整发送速率使更多的数据块准时到达。数据块的发送速率与网络当前时刻的可用带宽紧密相关,例如在网络可用带宽紧张时,如果增加发送速率,会导致数据块中的数据包大量丢失,从而验证用户体验。数据块的调度是影响数据块准时性的另一个重要因素,选择一个数据块传输可能会导致其他数据块超时过期,从而影响用户体验。
4.数据块的发送速率通常通过拥塞控制算法进行调整,但需要工程师的手动调整才能适应延迟敏感多媒体应用,这可能花费几个月甚至几年的时间。目前缺少在延迟敏感多媒体应用数据块调度方向上的研究,需要合理设计数据块调度算法,以让更多的数据块准时到达。考虑已有技术,应提出综合控制数据块发送速率并对数据块进行调度能够提升数据块传输准时性的方法,从而提高用户体验质量。
技术实现要素:
5.为了克服现有技术中延迟敏感多媒体应用数据块传输准时性的不足,本发明提供一种基于强化学习的数据块传输准时性提升方法,包括发送速率控制模块和数据块调度模块。发送速率控制模块根据不同的网络状况控制数据块的发送速率,减少因网络拥塞丢失的数据块中数据包的数量;数据块调度模块根据发送速率控制模块得到的发送速率,根据数据块调度算法,选择当前时刻最适合发送的数据块,从而减少超时过期的数据块的数量;两个模块共同协作,在不同的网络状况下,尽可能多地使数据块在其过期时间前到达,从而提升数据块的准时性,保证用户体验质量。
6.发送速率控制模块,用于基于深度q网络(deep q-learning network,dqn)强化学习算法根据当前时刻的网络状态(state)选择当前时刻调整数据块发送速率的动作(action),执行动作得到当前时刻的发送速率。发送速率控制模块设置深度q网络(dqn)算法的代理(agent)、状态(state)、奖励(reward)和动作(action),然后根据动作选择策略(policy)调整发送速率。
7.代理(agent):代理观察状态(state)并根据动作选择策略(policy)选出动作(action)来控制发送速率,得到执行此动作后的新状态和奖励(reward),然后将状态、选择
的动作、新状态和奖励存入经验池。代理(agent)是深度q网络(dqn)算法的执行单元。发送速率控制模块共包含一个代理。
8.状态(state):我们设置3个状态(state),分别是一定时间间隔内的最大带宽(max_bw)、当前时刻的带宽(bw)、当前时刻的往返时间(rtt)。状态(state)是深度q网络(dqn)算法的输入。
9.动作(action):动作(action)用于控制发送速率,是一条更改发送速率值的命令,执行动作即按照动作更改发送速率的值。动作是深度q网络(dqn)算法的输出。深度q网络算法中的动作是离散的,我们根据一定时间间隔内的最大带宽(max_bw),设置八个动作来调整发送速率,动作和发送速率的值的对应关系如下表:
10.动作发送速率的值02*ln2*p*max_bw11.15*p*max_bw20.85*p*max_bw30.3*p*max_bw4,5,6,7k*p*max_bw
11.其中p是限制发送速率的一个参数,可以根据具体应用场景进行设置,k是发送速率保持列表[1.25,0.75,1,1,1,1,1,1]中的一个随机值。
[0012]
奖励(reward):代理(agent)执行不同的动作会获得不同的奖励(reward)。奖励(reward)用来计算执行动作的价值,价值是根据马尔可夫决策过程得到的未来所有的奖励和,也可以称作“动作效用值”,表示在当前状态s
t
选择动作a
t
能够获得的全局收益,用于帮助深度q网络(dqn)算法调整动作选择策略(policy)中的神经网络的参数。我们根据以下三种情况设置奖励函数:
[0013]
(1)如果往返时间没有改变,则说明执行动作后网络状况良好,数据块中的数据包能够继续正常传输,不会丢失,奖励应当增加;
[0014]
(2)如果往返时间在没有丢失数据包的情况下变得更长,说明在执行动作后网络发生拥塞,奖励应当略有减少;
[0015]
(3)如果估计的往返时间变长并且丢失了一些数据包,说明在执行动作后网络发生严重拥塞,则奖励应当根据丢失数据包的数量显着减少。
[0016]
根据上述三种情况,设置奖励(reward)的计算公式如下:
[0017]
reward=α(last_rtt-rtt γ)-β(drop_packet_nums)
[0018]
其中rtt是这一时刻的往返时间,last_rtt是上一时刻的往返时间。drop_packet_nums是这两个时刻之间丢失的数据包数。α和γ在网络未发生拥塞时称为增益系数,在网络发生拥塞时称为惩罚系数。β是网络已经发生丢包时的惩罚系数。α》0,增益系数和惩罚系数用于表明它在不同情况下的含义,其值并不变,在奖励为正值时称为增益系数,在奖励为负值时称为惩罚系数。last_rtt-rtt的值可能是正数也可能是负数,当last_rtt-rtt的值是正数时,说明此数据包的往返时延比上一个数据包的往返时延小,说明网络状况变好,对应的,奖励值reward是正数,之后计算的动作价值将会增加;当last_rtt-rtt的值是负数时,说明此数据包的往返时延比上一个数据包的往返时延大,说明网络发生拥塞,对应的,奖励值reward是负数,之后计算的动作价值将会减小。γ》0,用于防止last_rtt-rtt值为0,导致
网络不拥塞但奖励却不增加。β》0,用于衡量网络的丢包程度,丢包越多说明越拥塞。
[0019]
深度q网络(dqn)算法的动作选择策略以ε概率用ε-贪心探索方法、以1-ε概率用神经网络来选择动作,从而调整发送速率,0《ε≤1。
[0020]
ε-贪心探索方法即从前面所述的八个动作中随机选择一个动作。ε-贪心探索方法的执行概率为ε,ε与代理(agent)选择动作的次数的关系如下式:
[0021][0022]
其中i为代理(agent)选择动作的次数,εi为本次动作探索的概率,ε
i-1
为上次动作探索的概率。
[0023]
若发送速率控制模块的代理(agent)本次选择动作时未执行ε-贪心探索方法,则通过神经网络选择动作。深度q网络(dqn)算法包含两个神经网络q和神经网络q以当前时刻的状态(state),即一定时间间隔内的最大带宽(max_bw)、当前时刻的带宽(bw)、当前时刻的往返时间(rtt)为输入,计算并输出前面所述的八个动作中的一个动作。发送速率控制模块执行神经网络q输出的动作即可改变发送速率。神经网络从前面所述的经验池中随机抽取状态作为输入,其输出作为神经网络q的真实值,帮助神经网络q调整网络权重。
[0024]
数据块调度模块,用于根据数据块的信息和数据块调度算法从当前时刻到达的数据块队列中选择当前时刻发送的数据块。
[0025]
数据块信息包括数据块的大小、数据块的过期时间、数据块的优先级和数据块的传输时间。数据块必须在某时刻前从发送端到达接收端,超过此时刻到达的数据块会失效,损害用户的体验质量,这个时刻就是数据块的过期时间。数据块具有不同的优先级,表示该数据块对延迟敏感多媒体应用的重要程度,应该尽可能多地让高优先级的数据块准时到达。数据块的传输时间等于数据块大小与数据块发送速率的商,该发送速率由发送速率控制模块得到,当前时刻加上数据块的传输时间小于过期期限说明该数据块能够在过期时间前传输完毕。
[0026]
数据块调度算法对数据块队列中的每一个数据块依次按照数据块调度规则进行判断,选出符合规则的数据块。当数据块不符合某条规则时,不再将该数据块与之后的规则进行判断,而是对队列中的下一个数据块依次按照规则进行判断。
[0027]
数据块调度算法的规则如下:
[0028]
(1)该数据块能够在其过期时间前传输完毕。
[0029]
(2)该数据块的损失分数最小。
[0030]
选择一个数据块传输时可能导致其他数据块超时,即,同一时刻只能选择一个数据块进行发送,其他数据块会在该数据块传输完毕后再从中选择另一个数据块开始发送。而在第一次选择的数据块的传输过程中,其他数据块中的某些数据块可能在此数据块的传输过程中超过其过期时间,所以选择一个数据块会对其他数据块造成影响。我们用损失分数衡量在某时刻选择一个数据块进行传输对其他数据块造成的影响。设数据块b传输完毕后才开始传输就会超过其过期时间的数据块有m个,则数据块b损失分数的值等于m个超过过期时间的数据块的优先级的和,其公式如下:
[0031][0032]
block_priorityi表示m个超过其过期时间的数据块中的第i个数据块的优先级。loss_score表示选择数据块b进行发送的损失分数,损失分数的值等于超过过期时间的数据块的优先级的和。损失分数越小说明该数据块对其它数据块造成的影响越小。
[0033]
(3)该数据块具有更高的优先级。
[0034]
(4)该数据块的传输时间比其他数据块短。
[0035]
如果在当前时刻的数据块队列中不止一个数据块符合上述规则,则随机选取一个符合规则的数据块作为当前时刻发送的数据块。
[0036]
一种基于强化学习的数据块传输准时性提升系统,其特征在于,包括发送速率控制模块和数据块调度模块;其中,
[0037]
所述发送速率控制模块,用于接收延迟敏感多媒体应用发过来的当前时刻t的网络状态s
t
与待发送的数据块;以及基于强化学习算法根据当前时刻t的网络状态s
t
,选择当前时刻t调整延迟敏感多媒体应用中数据块发送速率的动作,执行动作得到当前时刻t的发送速率并发送给数据块调度模块;
[0038]
所述数据块调度模块,用于选择当前时刻t最先发送的数据块,然后将最先发送的数据块和发送速率一起反馈给所述延迟敏感多媒体应用。
[0039]
本发明的有益效果是:
[0040]
1.本发明可以及时调整数据块的发送速率;
[0041]
2.本发明可以快速计算发送数据块对其他数据块的影响;
[0042]
3.本发明可以在各种网络状况下保障数据块传输的准时性;
[0043]
4.本发明可以提升延迟敏感多媒体应用用户的用户体验。
附图说明
[0044]
图1是本发明中的一种延迟敏感多媒体应用数据块传输准时性提升方法的结构框图。
[0045]
图2是本发明中的发送速率控制模块工作原理图。
[0046]
图3是本发明中的数据块调度算法流程图。
具体实施方式
[0047]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。
[0048]
本发明提供一种基于强化学习的数据块传输准时性提升方法,如图1所示,延迟敏感多媒体应用收集当前时刻的网络状态,和待发送的数据块一起发送到数据块传输准时性提升方法中。发送速率控制模块计算并输出当前时刻的发送速率到数据块调度模块,数据块调度模块选择当前时刻最先发送的数据块,然后将最先发送的数据块和发送速率一起反馈给延迟敏感多媒体应用。
[0049]
发送速率控制模块的工作原理如图2所示。发送速率控制模块以t时刻的网络状态st
为输入,包括一定时间间隔内的最大带宽(max_bw)、当前时刻的带宽(bw)、当前时刻的往返时间(rtt),以发送速率为输出。发送速率控制模块包括经验池、深度q网络(dqn)代理、动作执行三部分。
[0050]
dqn代理接收状态s
t
(图2中步骤
①
),以概率ε执行ε-贪心探索方法或以1-ε概率通过神经网络q计算输出动作a
t
(图2中步骤
②‑
1、步骤
②‑
2),由动作执行部分执行动作a
t
,更改数据块的发送速率。dqn代理然后将当前状态s
t
、输出动作a
t
、执行动作获得的奖励r
t
、执行动作后转移到的状态s
t 1
存入经验池(图2中步骤
③‑
1、步骤
③‑
2)。
[0051]
神经网络q和神经网络的网络结构完全相同,并按照如下规则更新权重:神经网络从经验池中随机抽取m个状态作为输入(图2步骤
④
),计算并输出这m个状态的计算结果,作为m个状态在神经网络q中的真实值,帮助神经网络q调整参数(图2步骤
⑤
)。神经网络q迭代到固定次数时后将自己的参数同步给神经网络(图2步骤
⑥
)。
[0052]
数据块调度模块根据数据块调度算法和数据块的信息从当前时刻待发送的数据块队列中选择最先发送的数据块。数据块信息包括数据块的大小、数据块的过期时间、数据块的优先级和数据块的传输时间,其中数据块的传输时间等于数据块的大小和发送速率的商。数据块调度算法流程如图3所示,步骤如下:
[0053]
(1)将同一时刻待发送的数据块放入发送队列;
[0054]
(2)从队列中选出能够在过期时间前传输完毕的数据块集合s1,判断方法为当前时间与数据块传输时间的和小于数据块的过期时间;
[0055]
(3)从s1选出损失分数最小的数据块集合s2;
[0056]
数据块的损失分数等于超过过期时间的数据块的优先级的和,设当前时刻选择的数据块为b,选择数据块b会导致m个数据块超过其过期时间,计算损失分数的公式如下:
[0057][0058]
block_priorityi表示m个超过过期时间的数据块中的第i个数据块的优先级。loss_score表示损失分数,损失分数的值即超过过期时间的数据块的优先级的和。损失分数越小说明该数据块对其它数据块造成的影响越小。
[0059]
(4)从s2中选出优先级最高的数据块集合s3;
[0060]
(5)从s3中选出传输时间最短的数据块集合s4;
[0061]
(6)从集合s4中随机挑选一个数据块,在当前时刻最先发送。
[0062]
尽管为说明目的公开了本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换、变化和修改都是可能的。因此,本发明不应局限于最佳实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
