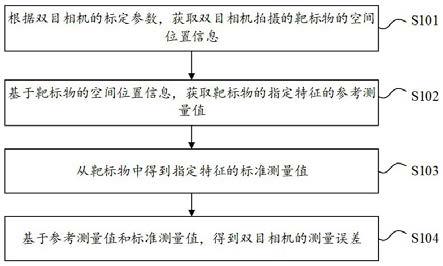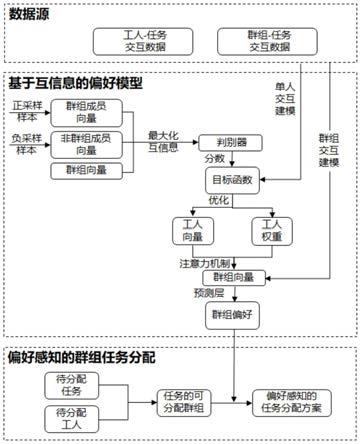
1.本发明涉及信息技术领域,尤其涉及一种基于互信息和偏好感知的空间众包任务分配方法。
背景技术:
2.随着gps应用的智能设备的流行和无线网络技术的发展,空间众包作为一个分配地区性任务给移动工人的框架在近年受到了广泛的关注。
3.现存的大多研究方法中大多关注个人任务分配,即一个任务只分配给单个工人。其中,他们考虑了工人们的拒绝率、工人技能、平台利润等因素以提高系统可行性,考虑了通过预测未来任务和工人的时空分布以将闲置工人进行合理调度。但是,在现实生活的场景里,一些复杂的任务往往不可能被单个工人独立完成,而是需要一些工人合作去完成任务。因此,研究重点指向了群组任务分配问题。而在空间众包的任务分配问题中,与单一任务分配相比,群组任务分配更为复杂,并且目前在这方面的研究较少。最近有研究提出了空间众包中的top-k群组推荐问题,即为每个任务推荐合适的群组。同时,有研究考虑到复杂任务的完成需要工人的合作,提出了一种基于贪心法和博弈论的方法,即指派多个合作质量高的工人共同完成一项任务。然而,大多不考虑工人是否对任务感兴趣的分配方法可能导致工人拒绝执行任务或低质量地完成任务。因此,有人在考虑社交影响因素的情况下,使用二部图嵌入模型和注意力机制来学习工人群体对不同类别任务的偏好,并根据他们的偏好将任务分配给群体。此外,也有人考虑使用工人之间的社交网络以缓解群组与任务的交互数据的稀疏性。
4.但是,以上方法都有一些不同的缺陷。首先,大多研究方法只适用于单人任务分配,而不适用于群组任务分配问题。其次,群组任务分配中通常只考虑了单个因素,即合作质量、任务偏好与社交关系等。最后,额外的信息通常很难获得,例如工人之间的社交网络。因此,通过附加信息来缓解群组交互数据稀疏性的方法不再适用。
技术实现要素:
5.本发明的目的是要提供一种基于互信息和偏好感知的空间众包任务分配方法。能有效解决群组交互历史信息稀疏导致的群组信息表示的问题。
6.为达到上述目的,本发明是按照以下技术方案实施的:
7.本发明包括构建基于互信息的偏好模型和基于偏好感知的群组任务分配方法,所述构建基于互信息的偏好模型包括以下步骤:
8.s11:利用工人与任务的历史交互数据通过多层感知机得到每个工人的向量;
9.s12:通过工人与任务的历史交互数据调整工人的向量,并且通过工人的个人偏好预测所有该工人所在的群组的任务偏好;
10.s13:使用kl散度描述采用群组向量预测的群组偏好与真实历史交互信息之间的差别;
11.s14:将群组成员向量与非群组成员向量进行对比学习,并与群组向量一起训练得到判别器;
12.s15:获取工人与群组之间不同的上下文关系,利用工人的任务偏好加权合成群组的任务偏好与群组向量得到的偏好预测进行损失衡量,从而建基于互信息的偏好模型;
13.所述基于偏好感知的群组任务分配方法包括以下步骤:
14.s21:筛选出对于任务而言满足条件的可分配群组集合;
15.s22:对所有的任务构造一个任务依赖图;
16.s23:使用递归树构造算法将类转化为一个平衡树结构,使其兄弟结点不共享相同的可分配工人,即将全局最优分配问题转化为若干个独立的局部最优分配子问题;
17.s24:使用深度优先搜索方法对树进行遍历,在每个兄弟结点上找到局部最优分配方法。
18.本发明的有益效果是:
19.本发明是一种基于互信息和偏好感知的空间众包任务分配方法,与现有技术相比,本发明首先通过注意力机制得到群组的表示向量,然后使用对比学习的方法训练得到一个判别器以得到不同工人与不同群组之间的相关性,从而去优化得到工人和群组的表示向量,而后通过预测层得到群组的任务偏好,最后实现了一个考虑群组偏好的树分解算法以生成最优的群组任务分配方案。在不引入其它数据的情况下,通过最大化工人之间的互信息对群组任务偏好进行有效的建模,并结合树分解的方法提高群组任务分配数量及完成率。本发明能够有效地提高任务成功率和分配任务总数,实现了在群组交互历史信息稀疏情况下对任务偏好感知的群组任务分配。
附图说明
20.图1为本发明基于互信息和偏好感知的空间众包任务分配的总体架构图;
21.图2为本发明适用的任务分配场景的示例图;
22.图3为本发明中对比方法对任务有效时间参数的研究;
23.图3中:(a)cpu时间;(b)任务成功率;(c)任务分配总数;
24.图4为本发明中对比方法对工人在线时长参数的研究;
25.图4中:(a)cpu时间;(b)任务成功率;(c)任务分配总数;
26.图5为本发明中对比方法对工人可达距离半径参数的研究;
27.图5中:(a)cpu时间;(b)任务成功率;(c)任务分配总数;
28.图6为本发明中对比方法对群组中工人数量参数的研究;
29.图6中:(a)cpu时间;(b)任务成功率;(c)任务分配总数;
30.图7为本发明中对比方法对任务总数参数的研究;
31.图7中:(a)cpu时间;(b)任务成功率;(c)任务分配总数;
32.图8为本发明中对比方法对工人总数参数的研究;
33.图8中:(a)cpu时间;(b)任务成功率;(c)任务分配总数。
具体实施方式
34.下面结合附图以及具体实施例对本发明作进一步描述,在此发明的示意性实施例
以及说明用来解释本发明,但并不作为对本发明的限定。
35.本发明利用历史交互数据得到初始的工人表示向量,并使用注意力机制得到相应群组的表示向量。相比使用群组内成员的平均值或者最大值替代群组表示,注意力机制则考虑了每个工人对整个群组最终决定的不同贡献。而后,本发明通过最大化群组成员与非群组成员表示之间的互信息对比学习到工人与群组之间的上下文信息,从而避免使用其它额外数据。接着,基于工人向量与上下文信息,使用偏好权重动态调整的方法优化群组向量的表示,从而缓解了群组与任务间历史交互数据的稀疏而导致的过拟合问题。最后,本发明基于树分解的方法将全局最优的群组分配问题转化为独立的局部最优分配的子问题。相比贪心算法,本发明更加有效地完成了群组任务的分配。
36.本发明整个网络架构分为两部分:基于互信息的偏好模型和偏好感知的群组任务分配。
37.所述基于互信息的偏好模型:
38.首先利用工人与任务的历史交互数据x
wc
通过多层感知机得到每个工人的向量表示w,即个人任务偏好,公式如下:
[0039][0040][0041]
其中,fe表示偏好编码函数,xw表示工人与任务的历史交互数据矩阵,xw表示工人w在xw的对应行向量,与表示权重矩阵,b1和b2表示偏置。
[0042]
通过工人与任务的历史交互数据x
wc
来调整工人的向量表示w,并且通过工人w的个人偏好去预测所有该工人所在的群组的任务偏好π(w)。因此,该目标函数表示为:
[0043][0044]
π(w)=softmax(w)
[0045]
其中,x
wi
表示工人w对第i种任务的偏好,|xw|表示工人w的历史交互任务的数量,kc表示预测层的权重矩阵。
[0046]
利用注意力机制可以学习到不同群组成员对最终决定的贡献,因此群组表示向量的加权计算公式如下:
[0047][0048][0049]
其中,gi和wj分别表示第i个群组和第j个工人的表示向量,α(j,i)表示工人wj在群组gi中的权重,h
t
表示注意力网络的隐藏层参数,k
agg
则是一个参数矩阵。
[0050]
使用kl散度描述使用群组向量g预测的群组偏好与真实历史交互信息之间的差别,损失函数可以表示为:
[0051][0052]
π(g)=softmax(g)
[0053]
其中,x
gi
表示群组g对第i种任务的偏好,|xg|表示群组g的历史交互任务的数量,kc表示预测层的权重矩阵。
[0054]
为了优化工人的向量表示,将群组成员向量w与非群组成员向量表示进行对比学习,并与群组向量g一起训练得到判别器d,具体公式如下:
[0055]
d(w,g)=σ(w
t
wg)
[0056]
其中,σ(
·
)表示非线性函数,w表示参数矩阵判别器输入的向量w可以是群组成员向量w也可以是非群组成员向量
[0057]
群组成员向量w只要保证w∈g即可,而非群组成员向量则是在符合负采样分布的条件下进行负采样,满足:
[0058][0059]
其中,η控制采样率,i(
·
)表示指示函数,|w|表示所有工人数量,表示工人与任务的交互矩阵x
wc
中工人对应的行,xg表示群组与任务的交互矩阵x
gc
中群组g所对应的行。
[0060]
最终,基于最大化互信息的方式,判别器d的优化目标可表示为:
[0061][0062]
其中,g表示所有的群组,μg表示群组g中所有的工人和所有采样的非群组工人的数量之和,则表示期望。
[0063]
因为通过工人w的个人偏好去预测所有该工人所在的群组的任务偏好会导致过拟合的问题。所以,无法使用目标函数o
worker
来对整体模型进行优化。因此,对群组成员引入偏好权重的动态调整技术,从而获取到工人与群组之间不同的上下文关系,从而利用工人的任务偏好加权合成群组的任务偏好与群组向量得到的偏好预测进行损失衡量:
[0064][0065]
最终,基于互信息的偏好建模部分的目标函数o可以表示为:
[0066]
o=o
mi
o
group
λo
wg
[0067]
在使用标准随机梯度下降方法最小化目标函数o后,可以得到群组的表示向量g和相应的任务偏好π(g)。
[0068]
所述偏好感知的群组任务分配:
[0069]
首先筛选出对于任务s而言满足条件的可分配群组集合awg((s)):
[0070]
awg((s))={{awg1(s),awg2(s),
…
,awg
|||awg(s)|||
(s)}}
[0071]
其中,|awg(s)|表示可分配群组集合awg((s))内所有的群组数量。其中,每个可分配群组awg(s)需要满足三个条件:
[0072][0073]
|awg(s)|=s.numw
[0074]
t
now
t(wi.l,s.l)≤wi.off
[0075]
上述三个条件分别表示所有在可分配群组里面的工人都要属于对该任务的可分配工人集合aws(s);每个可分配群里里面的工人数量需要正好满足每个任务s所需的工人数量;每个可分配群组里的工人都需要在其下班之前到达任务地点。
[0076]
其中,可分配工人集合aws(s)需要满足如下四个条件:
[0077]
w.on≤t
now
≤w.off
[0078]
d(w.l,s.l)≤w.r
[0079]
t
now
t(wi.l,s.l)≤s.e
[0080]
t
now
t(w.l,s.l)≤w.off
[0081]
上述四个条件分别表示:可分配工人集合里的每个工人当前需要处于工作状态;任务s需要在工人w的可达范围之内;工人需要在任务过期之前到达执行地点;工人需要在其下班之前到达任务地点。
[0082]
之后,对所有的任务构造一个任务依赖图g(v,e),每个顶点代表一个待分配的任务,两个任务分配方案中若有共同的可用工人,则两个任务顶点之间添加一条边。接着,使用最大势算法将任务依赖图分成若干个类,每一个类均是一个最大团。然后,使用递归树构造算法将类转化为一个平衡树结构,使其兄弟结点不共享相同的可分配工人,即将全局最优分配问题转化为若干个独立的局部最优分配子问题。最后,使用深度优先搜索方法对树进行遍历,在每个兄弟结点上找到局部最优分配方法。其中,在搜索过程中,任务优先分配给对此任务偏好更高的可分配群组。
[0083]
本发明的实验部分使用了一个空间众包平台实验验证常用的twitter签到数据集,该数据集提供了在美国除夏威夷和阿拉斯加地区从2010年9月至2011年1月的签到数据,共有62462个地点和61412个用户位置。同时,使用foursquare的接口生成任务的种类信息。
[0084]
本次实验记录和对比的指标有三个,分别是:cpu时间、任务分配成功率(asr)和任务分配总数。对比实验设计引入了不同的偏好模型和任务分配方法,共设计了五个对比方法:
[0085]
(1)优化群组任务分配算法(ogta):该算法基于树分解进行群组任务分配,但没有考虑工人群组的偏好。
[0086]
(2)平均偏好算法(avg) 优化群组任务分配算法(ogta):平均偏好算法用于计算具体的群组偏好值,优化群组任务分配算法用于群组任务分配
[0087]
(3)基于社交影响的偏好模型(sip) 优化群组任务分配算法(ogta):基于社交影响的偏好模型用于计算具体的群组偏好值,优化群组任务分配算法用于群组任务分配
[0088]
(4)基于互信息的偏好模型(mipm) 基于贪心的群组任务分配算法(ggta):基于互信息的偏好模型用于计算具体的群组偏好值,基于贪心的群组任务分配算法用于群组任务
分配
[0089]
(5)基于互信息的偏好模型(mipm) 优化群组任务分配算法(ogta):基于互信息的偏好模型用于计算具体的群组偏好值,优化群组任务分配算法用于群组任务分配,为本发明提出的方法
[0090]
采用控制变量法对相关参数的不同设置下各模型的结果进行研究:
[0091]
(1)只改变任务有效时间做五组实验,分别设置为0.9h,1.3h,1.7h,2.1h,2.5h,实验结果如图3所示;
[0092]
随着任务有效时间的增加,优化群组任务分配算法相关的方法的cpu时间相应增加(但均在可控范围内);在任务分配成功率方面,基于偏好建模的方法的任务分配成功率相应增加,且基于互信息的偏好建模方法明显优于其它方法;在任务分配总数方面,基于优化群组任务分配算法的相关方法均取得更好的效果。因此,本发明提出的mimp ogta的方法同时保证了任务分配成功率和任务分配总数。
[0093]
(2)只改变工人在线时长做五组实验,分别设置为1.0h,1.5h,2.0h,2.5h,3.0h,实验结果如图4所示;
[0094]
随着工人在线时长的增加,所有算法的cpu时间均逐渐增加;基于互信息的偏好建模方法在任务分配成功率方面明显优于其它方法,且基于优化群组任务分配的方法在任务分配总数上也优于基于贪心的群组任务分配的方法。
[0095]
(3)只改变工人可达距离半径做五组实验,分别设置为6km,7km,8km,9km,10km,实验结果如图5所示;
[0096]
随着工人可达距离半径的增加,所有算法的cpu时间均增加,但本发明提出的mimp ogta的方法在任务分配成功率与任务分配总数上仍是最优。
[0097]
(4)只改变群组中工人数量做四组实验,分别设置为2,3,4,5,实验结果如图6所示;
[0098]
随着群组中工人数量的增加,所有算法的cpu时间均减少,基于偏好建模的方法的任务分配成功率均下降但基于互信息的偏好建模的方法仍明显优于其它方法,且优化群组任务分配算法在任务分配总数上仍有优势。
[0099]
(5)只改变任务总数做五组实验,分别设置为500,1000,1500,2000,2500,实验结果如图7所示;
[0100]
随着任务总数的增加,优化群组任务分配算法相关的方法的cpu时间相应增加(但均在可控范围内),但本发明提出的mimp ogta的方法在任务分配成功率与任务分配总数上仍是最优。
[0101]
(6)只改变工人总数做五组实验,分别设置为1000,2000,3000,4000,5000,实验结果如图8所示;
[0102]
随着工人总数的增加,所有算法的cpu时间均增加,且本发明提出的mimp ogta的方法在任务分配成功率与任务分配总数上仍是最优。
[0103]
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。