1.本发明属于图像超分辨率技术领域,特别是涉及一种基于卷积神经网络的图像超分辨率重建方法。
背景技术:
2.图像分辨率泛指成像或显示系统对细节的分辨能力,表示图像中存储的信息量,通常表示为“水平像素数x垂直像素数”。通常情况下,图像的分辨率越高表示图像包含的细节越多,提供的信息量越大。图像超分辨率技术(imagesuper-resolution,简称sr),是根据单张或多张低分辨率(low resolution,简称lr)图像来重建高分辨率(highresolution,简称hr)图像的技术,该技术能够提供更加丰富的视觉信息,是计算机视觉领域中的经典问题。单幅图像超分辨率(single image super-resolution,简称sisr),是指根据给定的低分辨率图像信息恢复出有良好视觉体验的高分辨率图像。图像超分辨率技术主要研究的问题是如何将低分辨率图像重建为高分辨率图像,该技术重点关注图像的细节,即图像的高频信息。
3.chao dong在《super-resolution convolutional neural network》一文中公开了一种图像超分辨率重建方法,该方法相对于传统的重建方法肉眼可见的有更好的效果,在结构相似性以及峰值信噪比这两项衡量指标上来看,对于不同倍数的图像都有值0.001到2.07范围的不通程度提高,但srcnn仍然存在肉眼明显可见重建后的图像细节丢失、过平滑的问题,并且其对参数的变化过于敏感,参数的微小变化就会引起结果值的很大变动,造成调参困难。
技术实现要素:
4.针对上述技术问题,本发明提供了一种基于卷积神经网络的图像超分辨率重建方法,以提高超分辨率图像的普适性,并使超分辨率图像重建效果更好。
5.为实现上述技术目的中的至少其中一个,本发明所采用的技术方案是,一种基于卷积神经网络的图像超分辨率重建方法,包括以下步骤:
6.步骤s1:收集图像并对图像进行预处理;
7.步骤s2:使用优化器在现有图像超分辨率重建模型的基础上,将卷积层拆分为多层,卷积核拆小,每层中加入反卷积层,以构建改进的训练模型;使预处理后的图像在改进的训练模型中反复进行卷积,最后进行图像尺寸还原输出卷积处理的结果;
8.步骤s3:根据卷积处理的结果调整参数并重复步骤s2,最终输出重建后的图像。
9.进一步地,所述步骤s1中图像预处理是指通过倍数放大的方法来模拟模糊的、需要进行超分辨率重建的图像。
10.进一步地,所述倍数放大的方法为双插值法。
11.进一步地,所述步骤s2中的卷积函数为:
[0012][0013]
其中,f,g是实数集上的两个可积函数,n表示训练样本数,n∈(-∞, ∞),τ是训练次数,f(τ)表示当前输入的像素值,g(n-τ)表示过去所有输入的像素值。
[0014]
进一步地,所述步骤s2中采用损失函数衡量每次卷积对输出的影响,所述损失函数为:
[0015][0016]
其中w
t
为常量,t表示训练的样本数,hr表示高分辨率,sr表示超分辨率,i
thr
表示高分辨率图像的向量表示,i
tsr
表示超分辨率图像的向量表示。
[0017]
进一步地,所述步骤s2中,选用的优化器为adam优化器;训练参数为:步长:4,图像特征数:25~28,组数:4~8,学习率:1*10-(α 1)
,最大迭代次数:1*10
α
,通道数:3;其中α取3~5。
[0018]
进一步地,所述步骤s2中,选用的优化器为adam优化器;训练参数为:步长:4,图像特征数:25,组数:4,学习率:0.0001,最大迭代次数:1000,通道数:3。
[0019]
进一步地,所述步骤s3中的调整参数指调整训练参数和卷积核的层数。
[0020]
本发明的有益效果是:使因为各种原因变得模糊的图像通过超分辨率重建模型进行训练后,使其最大程度恢复到原本清晰的状态,本发明相比于现有的图像超分辨率重建的方法来说,有以下优势:1.对机器性能的要求不高,很普通的机器可以做到的训练效果就能很好的重建出清晰的图像;2.采用了拆分卷积核的创新想法,使模糊的图像进入模型后达到层层训练不断在卷积层中过滤的效果,最后得出期望的结果。
附图说明
[0021]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0022]
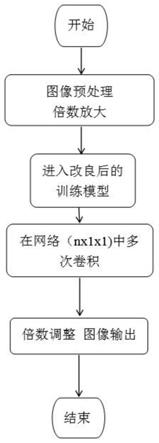
图1是本发明实施例基于卷积神经网络的图像超分辨率重建方法流程图。
[0023]
图2是本发明实施例的卷积流程图。
[0024]
图3是本发明实施例的训练结果图。
[0025]
图4是本发明实施例的输出效果图。
具体实施方式
[0026]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0027]
如图1所示,本发明提供了一种基于卷积神经网络的图像超分辨率重建方法,包括
以下步骤:
[0028]
步骤s1:收集图像并对图像进行预处理;
[0029]
步骤s2:使用优化器对现有的srcnn模型进行改进,将预处理后的图像输入改进后的训练模型进行卷积处理,输出卷积处理的结果;
[0030]
步骤s3:根据卷积处理的结果调整参数并重复步骤s2,最终输出重建后的图像。
[0031]
进一步地,所述步骤s1中图像预处理是指通过倍数放大的方法来模拟模糊的、需要进行超分辨率重建的图像。
[0032]
优选的,所述倍数放大的方法为双插值法。
[0033]
进一步地,所述步骤s2的具体方法为:即在现有srcnn的图像超分辨率重建模型(chao dong,《super-resolution convolutional neural network》)的基础上,将卷积层拆分为多层,卷积核拆小(卷积核拆分基于循环回传、卷积过滤的思想),每层中加入反卷积层,使预处理后的图像在模型中反复进行卷积,卷积函数见公式(1),损失函数见公式(2),反复卷积的原理类似于淘沙,逐层得出更精细的结果,最后进行图像尺寸还原输出结果。
[0034]
卷积处理的结果包含当下输入效果以及对过去的所有输入的效果,即是累积的结果。在图像处理中,卷积处理的结果,其实就是把每个像素周边的,甚至是整个图像的像素都考虑进来,对当前像素进行某种加权处理。
[0035]
卷积是通过两个函数f和g生成第三个函数的一种数学算子,表征函数f与g经过翻转和平移的重叠部分函数值乘积对重叠长度的积分。卷积是分析数学中一种重要的运算,一般定义函数f,g的卷积如下:
[0036][0037]
在公式中,f,g是实数集上的两个可积函数,n表示训练样本数,n∈(-∞, ∞),τ是训练次数,f(τ)表示当前输入的像素值,g(n-τ)表示过去所有输入的像素值。随着n的不同取值,这个积分就定义了一个新函数(f*g)(n),当τ取不同值时,g(n-τ)能沿着轴“滑动"(对应图像的平移和翻转),让τ从-∞滑动到 ∞,两函数交会时,计算交会范围中两函数乘积的积分值。换句话说,我们是在计算一个滑动的加权总和。也就是使用g(n-τ)当做加权函数,来对f(τ)取加权值。最后得到的就是f和g的卷积。本质上就是先将一个函数翻转,然后进行滑动叠加,在图像处理中可以达到边缘强化等效果。整体上来说,就是翻转、滑动、叠加、滑动、叠加
···
这样不断重复的过程,形成卷积,多次滑动得到的一系列叠加值,构成了卷积函数。
[0038]
之所以使用卷积进行超分辨处理,是因为进行“卷”(翻转)的目的其实是施加一种约束,它指定了在“积”的时候以什么为参照。基于在约束条件的情况下进行积分以得到理想效果的思想,将卷积网络中的卷积核“切割”,使图像可以进行多次卷积,每次卷积效果结合上一次的卷积效果进行叠加,使得模糊图像的边缘强化,直至得到当前环境中的最优解,这么做相当于加深网络,不断生成新的图像,如图2所示。运行结果证明,图像在卷积层中进行多次输入输出后得到的叠加效果较为理想。
[0039]
损失函数:
[0040][0041]
其中w
t
为常量,t表示训练的样本数,hr(high resolution)表示高分辨率,sr(super resolution)表示超分辨率,i
thr
表示高分辨率图像的向量表示,i
tsr
表示超分辨率图像的向量表示。该损失函数用于衡量每次卷积中对输出的影响。本发明模型只有6个需要学习的参数(详见下列序号6),损失的计算也仅仅需要网络的输出与真实高分图像,损失函数选择mse损失,其中n是训练样本数,表示mse损失为一个batch(步长)的损失均值。选用mse损失是为了获得高的峰值信噪比psnr,而psnr是常用的图像高分辨率算法的评估指标。
[0042]
优选的,所述步骤s2中选用的优化器为adam优化器,训练参数组合为:“batch_size”(步长):4,“num_features”(图像特征数):25~28,“num_groups”(组数):4~8(该值具体根据所用数据集而定),“learning_rate”(学习率):1*10-(α 1)
,“num_epochs”(最大迭代次数):1*10
α
,通道数:3。需要说明的是学习率中的α未进行最优求解,建议α的值取为3~5。
[0043]
进一步地,所述步骤s3具体是指对训练结果不够理想时,调整训练参数和卷积核的层数后重复步骤s2的操作直至得出相对理想效果。
[0044]
实施例
[0045]
步骤s1,将从网络上下载到的数据集,即多组用于训练图像相关模型的图片集合,进行预处理,即通过双插值放大4倍的方法来模拟模糊的、需要进行超分辨率重建的图像,并将此组模糊的图像传入改良后的网络进行模型训练。
[0046]
步骤s2,将待改进的srcnn模型的三层卷积(9x9,5x5,1x1)全部拆成9个1x1卷积层。在本实施例中选用的n值为3,模型使用的adam优化器,本实施例中选用的训练参数为:“batch_size”:4,“num_features”:25,“num_groups”:4,“learning_rate”:0.0001,“num_epochs”:1000,通道数:3。随后将预处理后的图像输入该模型进行反复卷积训练,输出训练结果,见图3。
[0047]
步骤s3,当训练结果不够理想时,调整参数和卷积核的层数后重复上述操作直至得出相对理想效果。最后将超分辨率重建的结果与原图进行对比,总结效果,使实验具备更高的可靠性,本实施例具体结果见图4。
[0048]
对采用本发明方法和传统方法得到的sr质量进行定量评价,选取psnr(peak signal-to-noise ratio,峰值信噪比)和ssim(structure similarity index,结构相似性)作为评价指标,两个评价指标值越高代表重建结果的像素值和原标准越接近,并且两个评价指标成正比增长,值越大,效果越好。具体评价结果见表1:
[0049]
表1传统方法的psnr和ssim指标对比
[0050][0051]
上表为传统方法的图像超分辨率重建模型运行结果,下表为本模型重建图像后所得的结果数据,经过对比明显优于上述模型。下表以四倍像素值进行重建,所以应以表1中scale所对应的值4这一行进行对比psnr和ssim值,在表2中对应第四列和第五列。
[0052]
表2本发明重建图像后所得的结果数据
[0053][0054][0055]
从数据上来看,相对于所对标的已有的srcnn模型来看,本发明的psnr改进约0.56,ssim改进约0.0157。结果表明,相比其他传统方法,本发明方法取得更好的重建效果。
[0056]
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0057]
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。