1.本发明涉及图像分析技术领域,特别是涉及一种皮肤状态图像的类别识别和特征确定方法及系统。
背景技术:
2.皮肤病的智能辅助诊疗是一个数字化、远程医疗和信息学相互作用日益增强的交叉领域,需要对皮肤状态图像进行分类。相比于传统的统计和机器学习方法,深度学习模型能更好地从复杂的高维数据中学习非线性表示,捕获数据中的复杂结构信息。在图像分类、语义分割、目标检测和目标定位等方面已经有了非常出色地表现。但由于深度学习的复杂性和低透明性,“黑匣子”的话题一直是深度学习在医疗领域应用的一个争议。即深度学习仅能够识别出皮肤状态图像中皮肤状态的类别,但不具备可解释性,即无给出确定皮肤状态图像的类别时依据的特征,(类别包括健康状态和非健康状态中的多种皮肤病状态)造成用户难以信服,对于高精度的模型,如果无法判断模型是否抓住了皮肤病图像的“正确特征”,难以真正地被认可。可以说,模型的可解释性和精度是同等重要的。
技术实现要素:
3.本发明的目的是提供一种皮肤状态图像的类别识别和特征确定方法及系统,能够确定出识别皮肤状态类别依据的特征,提高了皮肤状态图像类别的识别精度和可解释性。
4.为实现上述目的,本发明提供了如下方案:
5.一种皮肤状态图像的类别识别和特征确定方法,包括:
6.获取待识别皮肤状态图;
7.将所述待识别皮肤状态图输入到类别识别模型中,识别待识别皮肤状态图的类别;所述类别识别模型是根据历史皮肤状态图,对卷积神经网络进行训练后得到的;
8.在待识别皮肤状态图的类别为非健康状态时,根据所述待识别皮肤状态图上每个像素点的像素值,利用shapley值法确定识别结果依据的特征。
9.可选的,在所述获取待识别皮肤状态图之前,还包括:
10.获取多张历史皮肤状态图;
11.对多张所述历史皮肤状态图的种类进行标注,得到多张历史皮肤状态标注图作为训练集;
12.以所述训练集为输入,以所述训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型。
13.可选的,所述以所述训练集为输入,以所述训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型,具体包括:
14.构建卷积神经网络为第0阶类别识别模型;
15.令迭代次数m等于1;
16.将所述训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张
历史皮肤状态伪标注图;
17.根据所述训练集和多张所述历史皮肤状态伪标注图,利用公式根据所述训练集和多张所述历史皮肤状态伪标注图,利用公式确定第m次迭代的损失函数;
18.判断第m次迭代的损失函数是否小于损失函数阈值,得到判断结果;
19.若所述判断结果为否,则根据多张所述历史皮肤状态伪标注图更新所述训练集,令迭代次数m的数值增加1,并返回步骤“将所述训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张历史皮肤状态伪标注图”;
20.若所述判断结果为是,则确定第m阶类别识别模型为类别识别模型;
21.式中,loss为损失函数;n为样本数量;x为第m次迭代时训练集中的图片;y为训练中集图片的标注结果;a为第m-1阶类别识别模型的识别结果。
22.可选的,所述根据多张所述历史皮肤状态伪标注图更新所述训练集,具体包括:
23.确定预测精度大于预测精度阈值的多张历史皮肤状态伪标注图为备用集;
24.确定所述训练集中每种皮肤状态种类对应的图片的数量;
25.按照对应的图片的数量对多种皮肤状态种类进行升序排列;
26.确定前第一预设个数个皮肤状态种类为待更新皮肤状态种类;
27.在所述备用集中选取每种待更新皮肤状态种类对应的多张历史皮肤状态伪标注图添加到所述训练集中。
28.可选的,所述在待识别皮肤状态图的类别为非健康状态时,根据所述待识别皮肤状态图上每个像素点的像素值,利用shapley值法确定识别结果依据的特征,具体包括:
29.构建加权线性回归模型和优化函数;
30.根据所述待识别皮肤状态图上每个像素点的像素值,利用所述优化函数对所述加权线性回归模型进行优化,确定所述优化函数最小时对应的估计系数组为所述待识别皮肤状态图上每个像素点的shapley值;
31.确定shapley值不等于0的像素点的像素值为识别结果依据的特征;
32.其中,
33.所述加权线性回归模型为:
34.所述优化函数为
35.其中,g(.)为加权线性回归模型,即解释模型;z'为示性函数;z'∈{0,1}m;m为最大联盟的规模;φ0为shapley值的平均数;φj为第j个像素点的shapley值;z'j为第j个像素点的示性函数值,z'j为1表示第j个像素点的像素值大于0,z'j为0表示第j个像素点的像素值等于0;l(.)为优化函数,优化函数的估计系数组为g(.)中j取1到m时对应的多个φj的取值;f(.)表示被解释模型的预测值,h(.)表示映射函数,即将示性函数z'映射到要解释的像素点x的像素值;π
x
(.)为核函数,
36.一种皮肤状态图像的类别识别和特征确定系统,包括:
37.待识别皮肤状态图获取模块,用于获取待识别皮肤状态图;
38.图像类别识别模块,用于将所述待识别皮肤状态图输入到类别识别模型中,识别待识别皮肤状态图的类别;所述类别识别模型是根据历史皮肤状态图,对卷积神经网络进行训练后得到的;
39.特征确定模块,用于在待识别皮肤状态图的类别为非健康状态时,根据所述待识别皮肤状态图上每个像素点的像素值,利用shapley值法确定识别结果依据的特征。
40.可选的,所述系统,还包括:
41.历史皮肤状态图获取模块,用于获取多张历史皮肤状态图;
42.标注模块,用于对多张所述历史皮肤状态图的种类进行标注,得到多张历史皮肤状态标注图作为训练集;
43.类别识别模型构建模块,用于以所述训练集为输入,以所述训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型。
44.可选的,所述类别识别模型构建模块,具体包括:
45.第0阶类别识别模型构建单元,用于构建卷积神经网络为第0阶类别识别模型;
46.迭代次数赋值单元,用于令迭代次数m等于1;
47.训练单元,用于将所述训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张历史皮肤状态伪标注图;
48.损失函数计算单元,用于根据所述训练集和多张所述历史皮肤状态伪标注图,利用公式确定第m次迭代的损失函数;
49.判断单元,用于判断第m次迭代的损失函数是否小于损失函数阈值,得到判断结果;若所述判断结果为否,则调用训练集更新单元;若所述判断结果为是,则调用类别识别模型确定单元;
50.训练集更新单元,用于根据多张所述历史皮肤状态伪标注图更新所述训练集,令迭代次数m的数值增加1,并调用所述训练单元;
51.类别识别模型确定单元,用于确定第m阶类别识别模型为类别识别模型;
52.式中,loss为损失函数;n为样本数量;x为第m次迭代时训练集中的图片;y为训练中集图片的标注结果;a为第m-1阶类别识别模型的识别结果。
53.可选的,所述训练集更新单元,具体包括:
54.备用集确定子单元,用于确定预测精度大于预测精度阈值的多张历史皮肤状态伪标注图为备用集;
55.数量确定子单元,用于确定所述训练集中每种皮肤状态种类对应的图片的数量;
56.排序子单元,用于按照对应的图片的数量对多种皮肤状态种类进行升序排列;
57.待更新皮肤状态种类确定子单元,用于确定前第一预设个数个皮肤状态种类为待更新皮肤状态种类;
58.训练集更新子单元,用于在所述备用集中选取每种待更新皮肤状态种类对应的多张历史皮肤状态伪标注图添加到所述训练集中。
59.可选的,所述特征确定模块,具体包括
60.模型构建单元,用于构建加权线性回归模型和优化函数;
61.shapley值确定单元,用于根据所述待识别皮肤状态图上每个像素点的像素值,利用所述优化函数对所述加权线性回归模型进行优化,确定所述优化函数最小时对应的估计系数组为所述待识别皮肤状态图上每个像素点的shapley值;
62.识别结果依据特征确定单元,用于确定shapley值不等于0的像素点的像素值为识别结果依据的特征;
63.其中,
64.所述加权线性回归模型为:
65.所述优化函数为
66.其中,g(.)为加权线性回归模型,即解释模型;z'为示性函数;z'∈{0,1}m;m为最大联盟的规模;φ0为shapley值的平均数;φj为第j个像素点的shapley值;z'j为第j个像素点的示性函数值,z'j为1表示第j个像素点的像素值大于0,z'j为0表示第j个像素点的像素值等于0;l(.)为优化函数,优化函数的估计系数组为g(.)中j取1到m时对应的多个φj的取值;f(.)表示被解释模型的预测值,h(.)表示映射函数,即将示性函数z'映射到要解释的像素点x的像素值;π
x
(.)为核函数,
67.根据本发明提供的具体实施例,本发明公开了以下技术效果:
68.本发明中利用训练卷积神经网络训练得到类别识别模型以识别皮肤状态类别,并在待识别皮肤状态图的类别为非健康状态时,利用shapley值法确定识别结果依据的特征,提高了皮肤状态图像类别的识别精度和可解释性。
附图说明
69.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
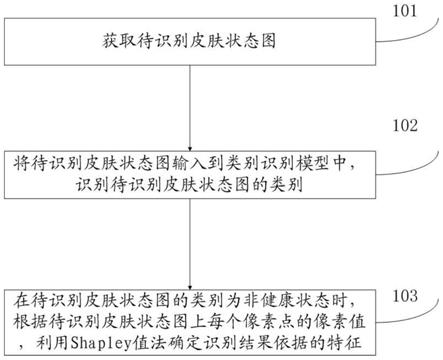
70.图1为本发明实施例中皮肤状态图像的类别识别和特征确定方法流程图;
71.图2为本发明实施例中技术方案总框架示意图;
72.图3为本发明实施例中皮肤病智能诊断系统设计图;
73.图4为本发明实施例中算法流程图;
74.图5为本发明实施例中模型roc曲线及auc指标示意图;
75.图6本发明实施例中皮肤病图像shap值解释例图。
具体实施方式
76.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
77.本发明的目的是提供一种皮肤状态图像的类别识别和特征确定方法及系统,能够确定出识别皮肤状态类别依据的特征,提高了皮肤状态图像类别的识别精度和可解释性。
78.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
79.传统的深度学习模型应用于皮肤病智能辅助诊断仍存在以下问题:(1)缺乏足够的临床数据样本,限制了深度学习在皮肤病诊断中的广泛应用,尽管可以从公开皮肤病数据集和网站上获得大量的无标记数据,但皮肤状态种类的标记工作需要专业医学知识,操作难度大,成本高;(2)样本类别不平衡问题导致模型的预测结果偏向多数类,而造成模型的识别精度低。(3)深度学习模型的高精度预测依赖于复杂的网络模型,庞大的参数量使模型在训练和使用过程中并不高效。如图1,本发明提供了一种皮肤状态图像的类别识别和特征确定方法,包括:
80.步骤101:获取待识别皮肤状态图;
81.步骤102:将待识别皮肤状态图输入到类别识别模型中,识别待识别皮肤状态图的类别;类别识别模型是根据历史皮肤状态图,对卷积神经网络进行训练后得到的;
82.步骤103:在待识别皮肤状态图的类别为非健康状态时,根据待识别皮肤状态图上每个像素点的像素值,利用shapley值法确定识别结果依据的特征。
83.在步骤101之前,还包括:
84.获取多张历史皮肤状态图;
85.对多张历史皮肤状态图的种类进行标注,得到多张历史皮肤状态标注图作为训练集;
86.以训练集为输入,以训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型。
87.其中,以训练集为输入,以训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型,具体包括:
88.构建卷积神经网络为第0阶类别识别模型;
89.令迭代次数m等于1;
90.将训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张历史皮肤状态伪标注图;
91.根据训练集和多张历史皮肤状态伪标注图,利用公式根据训练集和多张历史皮肤状态伪标注图,利用公式确定第m次迭代的损失函数;
92.判断第m次迭代的损失函数是否小于损失函数阈值,得到判断结果;
93.若判断结果为否,则根据多张历史皮肤状态伪标注图更新训练集,令迭代次数m的数值增加1,并返回步骤“将训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张历史皮肤状态伪标注图”;
94.若判断结果为是,则确定第m阶类别识别模型为类别识别模型;
95.式中,loss为损失函数;n为样本数量;x为第m次迭代时训练集中的图片;y为训练中集图片的标注结果;a为第m-1阶类别识别模型的识别结果。
96.具体的,根据多张历史皮肤状态伪标注图更新训练集,具体包括:
97.确定预测精度大于预测精度阈值的多张历史皮肤状态伪标注图为备用集;
98.确定训练集中每种皮肤状态种类对应的图片的数量;
99.按照对应的图片的数量对多种皮肤状态种类进行升序排列;
100.确定前第一预设个数个皮肤状态种类为待更新皮肤状态种类;
101.在备用集中选取每种待更新皮肤状态种类对应的多张历史皮肤状态伪标注图添加到训练集中。
102.此外,本发明提供的皮肤状态图像的类别识别和特征确定方法,步骤103,具体包括:
103.构建加权线性回归模型和优化函数;
104.根据待识别皮肤状态图上每个像素点的像素值,利用优化函数对加权线性回归模型进行优化,确定优化函数最小时对应的估计系数组为待识别皮肤状态图上每个像素点的shapley值;
105.确定shapley值不等于0的像素点的像素值为识别结果依据的特征;
106.其中,
107.加权线性回归模型为:
108.优化函数为
109.其中,g(.)为加权线性回归模型,即解释模型;z'为示性函数;z'∈{0,1}m;m为最大联盟的规模;φ0为shapley值的平均数;φj为第j个像素点的shapley值;z'j为第j个像素点的示性函数值,z'j为1表示第j个像素点的像素值大于0,z'j为0表示第j个像素点的像素值等于0;l(.)为优化函数,优化函数的估计系数组为g(.)中j取1到m时对应的多个φj的取值;f(.)表示被解释模型的预测值,h(.)表示映射函数,即将示性函数z'映射到要解释的像素点x的像素值;π
x
(.)为核函数,
110.如图2-4,本发明共分为七个部分:数据获取、数据预处理、teachermodel(教师模型)的构建与训练、无标签样本伪标注、增强训练、模型评估和最终模型解释。
111.(一)数据预处理
112.本发明需要通过医疗站点的接入,获取皮肤病图像样本数据,并对皮肤病图像进行标注,具体包括:
113.1.记录保存皮肤病图像的dicom,png或jpeg格式的数据。2.对已经获得的皮肤病图像,由皮肤病专家进行标注。以下9种皮肤病为例ak(日光性角化)标记为0,bcc(基底细胞癌)标记为1,bkl(良性角化样病变)标记为2,df(皮肤纤维瘤)标记为3,mel(黑色素瘤)标记为4,nv(黑色素细胞痣)标记为5,scc(鳞状细胞癌)标记为6,unknown(未知或不确定)标记
为7,vasc(血管病变)标记为8。各类皮肤病的全称、简写、疾病名称及对应的标注符号如表1所示:
114.表1皮肤状态图像标注
[0115][0116][0117]
(二)数据预处理
[0118]
根据标注将皮肤病图像划分为不同皮肤病集合,再将数据划分为训练集和测试集。具体包括,根据标注将图像划分为若干集合,同时将所有类型的图像80%作为训练集,20%作为测试集对模型进行评估,且此后模型的评估均基于测试集和训练集的综合考量。将无标注图像单独划分至无标注皮肤病图像数据集合,作为之后数据增强数据集使用。
[0119]
(三)teachermodel的构建与训练
[0120]
model scaling(模型扩展)一直以来都是提高卷积神经网络效果的重要方法,本发明试图基于高效的efficientnet神经网络架构建teachermodel。在较高准确率的teacher model的基础上,对大量无标注皮肤病图像标注伪标签,并在此基础上以特定概率分布将不同类别的皮肤病样本加入到训练集中继续训练,最终得到高精度的皮肤病预测模型。具体包括:
[0121]
1.建立训练样本集
[0122]
2.建立模型,基于神经网络初始模型,模型架构基于mbconv(小基准卷积)包括:32个3
×
3卷积核的卷积层,16个mbconv6,k3
×
3,24个mbconv6,k3
×
3,40个mbconv6,k5
×
5,80个mbconv6,k3
×
3,112个mbconv6,k5
×
5,192个mbconv6,k5
×
5,320个mbconv6,k3
×
3,1280个1
×
1卷积核的卷积层(conv1
×
1),一个平均池化层(pooling)以及一个输出为9的全连接层(fc),efficientnet神经网络结构和mobile-size baseline结构分别如如表2和表3所示,其中每个mobile-size baseline的参数k参照表2中channels数值。
[0123]
表2 efficientnet结构
[0124][0125][0126]
表3 mobile-size baseline结构
[0127][0128]
3.构造模型输出a与样本标签y的损失函数:
[0129][0130]
4.基于训练样本,使用rmsprop优化器求解模型的最优参数,同时在迭代训练过程
中使用验证集对模型从auc指标、准确率指标、损失函数值等指标对模型效果进行评估;
[0131]
5.选取训练过程中表现最优的模型作为teacher model对无标注皮肤病图像标注伪标签;
[0132]
6.将带伪标签的皮肤病图像样本以概率入训练集中:其中,α为自定义参数,n
l
为伪标签数据集中第l类疾病的样本数量(各类疾病按样本数量降序排序);n1为最大类别样本量,n
l
为最小最少类别的样本量,此处下标即为降序排列后所处的索引。
[0133]
7.在步骤6扩展后的数据集上继续训练模型,直到模型准确率上升趋势不在明显为止(即达到收敛),保存较高准确率模型权重备选。
[0134]
(四)模型验证
[0135]
测试模型在测试集上的预测性能,评估最终模型的泛化能力,具体包括以下两个方面:
[0136]
1.模型验证,基于测试集,对备选模型权重分别从roc曲线、auc、准确率、精确率、召回率、损失函数值几个方面进行模型评估。表4列出了单类皮肤病的预测结果的所有可能性。
[0137]
表4单类皮肤病预测结果实例
[0138][0139]
其中,
[0140]
准确率为:
[0141]
精确率(precision)为:
[0142]
召回率(recall)和true positive rate(tpr,真阳性率)为:rate(tpr,真阳性率)为:
[0143]
false positive rate(fpr,假阳性率)为:
[0144]
传统的准确率指标在模型训练中只能起到参考作用,就具体问题来讲,医学诊断的主要内容是将患有疾病的患者诊断为阳性,此时tpr越大越好。而把未患病的患者误诊为有病的,也就指标fpr要越低越好。因此在皮肤病诊断中召回率、精确率和准确率都是模型评估的重要标准。roc(receiver operating characteristic,受试者工作特征)曲线衡量
了分类模型false positive rate(fpr)和true positive rate(tpr)的相对关系。基于备选的模型,根据其在测试集数据上的表现得到一个tpr和fpr点对,以此来映射成roc平面上的一个点。调整这个分类器分类时候使用的阈值(从0到1),就可以得到一个经过(0,0),(1,1)的roc曲线。auc数值则为该曲线下方的面积,如图5。
[0145]
2.模型选取,根据评估结果,选取备选模型中预测表现最佳的模型作为最终皮肤病智能诊断模型。
[0146]
图5中横坐标为假阳性率,纵坐标为真阳性率,roc为受试者工作特征,aera为对应曲线下方的面积,图中不同曲线代表了在不同阈值分类器下的模型表现下“真阳性率”和“假阳性率”的相对关系,曲线越靠近左上角则代表模型的效果越理想,同时,auc数值则代表了对应roc曲线下的区域面积,数值越靠近1,代表模型对这一类样本的识别能力越强。实例中所有类别皮肤病在测试集下的auc数值都达到了0.99,此时的模型表现能力优异,以此将其作为最终的预测模型。
[0147]
(五)模型解释
[0148]
通过shap(沙普利解释)方法对最优机器学习模型的预测结果进行解释,计算皮肤病图像中各个像素点对预测结果的贡献度。
[0149]
shap将解释定义为:其中,g(.)是解释模型,z'∈{0,1}m是联盟向量,m是最大联盟向量,φj∈r是特征j的特征归因shapley值。
[0150]
同时设定联盟向量,输入1表示相应的特征(即像素点的像素值)存在,而输入0表示不存在,对于感兴趣的实例(即像素点)x,联盟向量x'是全为1的向量,即所有特征值均为存在,该公式简化为:
[0151][0152]
通过shap来计算shapley值,同时建立shap核:
[0153][0154]
其中,m是最大联盟向量,|z
′
|是实例z
′
中当前特征(输入变量)的数量。
[0155]
然后建立加权线性回归模型:
[0156][0157]
通过优化以下优化函数l来训练线性模型g:
[0158][0159]
其中,l(.)为优化函数,f(.)表示被解释模型的预测值,h(.)表示映射函数,即将示性函数z'(0或1)映射到要解释的实例x的对应值;z是训练数据,通过对线性模型进行优化的误差平方和,模型的估计系数φj即为需要求解的shapley值,也即为皮肤病预测模型
输入图像各个像素点对最终结果的贡献率。当需要输入图像各个像素点全局重要性时,根据shapley值的可加性质,我们可以在数据中对每个特征的shapley绝对值取平均值:ij表示平均贡献度。
[0160]
图6中,在给定的四张皮肤病图像下,从左到右依次为可能性最高的前三类疾病预测结果。以第二行四张图片为例,第一张为输入图像,第二张图表明,该图像最大可能是良性角化样病变(bkl),这也是模型的最终预测结果,图像中红色和蓝色像素点表示该像素点对这一结果的shap值,红色表示该像素点对这一结果起到正向的贡献,蓝色表示该像素点最这一结果的贡献是负向的,颜色越深表示贡献率越大,右面两张图也同样解释。对比来看,中间病变区域小块对最终预测值的贡献为负,而这次结果的贡献为正,周围其他泛红的病变皮肤对最终结果贡献为正,这也说明,模型是因为周围泛红的病变皮肤将该皮肤病图片识别为良性角化样病变而不是黑色素细胞痣(nv)。
[0161]
此外,本发明还提供了一种皮肤状态图像的类别识别和特征确定系统,包括:
[0162]
待识别皮肤状态图获取模块,用于获取待识别皮肤状态图;
[0163]
图像类别识别模块,用于将待识别皮肤状态图输入到类别识别模型中,识别待识别皮肤状态图的类别;类别识别模型是根据历史皮肤状态图,对卷积神经网络进行训练后得到的;
[0164]
特征确定模块,用于在待识别皮肤状态图的类别为非健康状态时,根据待识别皮肤状态图上每个像素点的像素值,利用shapley值法确定识别结果依据的特征。
[0165]
此外,本发明提供的皮肤状态图像的类别识别和特征确定系统,还包括:
[0166]
历史皮肤状态图获取模块,用于获取多张历史皮肤状态图;
[0167]
标注模块,用于对多张历史皮肤状态图的种类进行标注,得到多张历史皮肤状态标注图作为训练集;
[0168]
类别识别模型构建模块,用于以训练集为输入,以训练集中多张图片的种类为输出,对卷积神经网络进行训练,得到类别识别模型。
[0169]
具体的,类别识别模型构建模块,具体包括:
[0170]
第0阶类别识别模型构建单元,用于构建卷积神经网络为第0阶类别识别模型;
[0171]
迭代次数赋值单元,用于令迭代次数m等于1;
[0172]
训练单元,用于将训练集为输入到第m-1阶类别识别模型中,得到第m阶类别识别模型和多张历史皮肤状态伪标注图;
[0173]
损失函数计算单元,用于根据训练集和多张历史皮肤状态伪标注图,利用公式确定第m次迭代的损失函数;
[0174]
判断单元,用于判断第m次迭代的损失函数是否小于损失函数阈值,得到判断结果;若判断结果为否,则调用训练集更新单元;若判断结果为是,则调用类别识别模型确定单元;
[0175]
训练集更新单元,用于根据多张历史皮肤状态伪标注图更新训练集,令迭代次数m的数值增加1,并调用训练单元;
[0176]
类别识别模型确定单元,用于确定第m阶类别识别模型为类别识别模型;
[0177]
式中,loss为损失函数;n为样本数量;x为第m次迭代时训练集中的图片;y为训练中集图片的标注结果;a为第m-1阶类别识别模型的识别结果。
[0178]
进一步地,训练集更新单元,具体包括:
[0179]
备用集确定子单元,用于确定预测精度大于预测精度阈值的多张历史皮肤状态伪标注图为备用集;
[0180]
数量确定子单元,用于确定训练集中每种皮肤状态种类对应的图片的数量;
[0181]
排序子单元,用于按照对应的图片的数量对多种皮肤状态种类进行升序排列;
[0182]
待更新皮肤状态种类确定子单元,用于确定前第一预设个数个皮肤状态种类为待更新皮肤状态种类;
[0183]
训练集更新子单元,用于在备用集中选取每种待更新皮肤状态种类对应的多张历史皮肤状态伪标注图添加到训练集中。
[0184]
此外,特征确定模块,具体包括
[0185]
模型构建单元,用于构建加权线性回归模型和优化函数;
[0186]
shapley值确定单元,用于根据待识别皮肤状态图上每个像素点的像素值,利用优化函数对加权线性回归模型进行优化,确定优化函数最小时对应的估计系数组为待识别皮肤状态图上每个像素点的shapley值;
[0187]
识别结果依据特征确定单元,用于确定shapley值不等于0的像素点的像素值为识别结果依据的特征;
[0188]
其中,
[0189]
加权线性回归模型为:
[0190]
优化函数为
[0191]
其中,g(.)为加权线性回归模型,即解释模型;z'为示性函数;z'∈{0,1}m;m为最大联盟的规模;φ0为shapley值的平均数;φj为第j个像素点的shapley值;z'j为第j个像素点的示性函数值,z'j为1表示第j个像素点的像素值大于0,z'j为0表示第j个像素点的像素值等于0;l(.)为优化函数,优化函数的估计系数组为g(.)中j取1到m时对应的多个φj的取值;f(.)表示被解释模型的预测值,h(.)表示映射函数,即将示性函数z'映射到要解释的像素点x的像素值;π
x
(.)为核函数,
[0192]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0193]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上,本说明书内容不应理
解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。