一种适用于高斯平滑的neon优化方法
技术领域
1.本发明涉及图像处理技术领域,尤其涉及一种适用于高斯平滑的neon优化方法。
背景技术:
2.1、高斯平滑:
3.平滑是低频增强的空间域滤波技术,是一项简单且使用频率很高的图像处理方法。它的目的有两类:一类是模糊;另一类是消除噪音。高斯平滑是一种线性平滑滤波技术,使用于消除噪声,广泛应用于图像处理的减噪过程。通俗的讲,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。
4.2、neon:
5.simd(single instruction multiple data):一种并行处理技术,一条指令可以并行处理多个数据,相比于一条指令处理一个数据,运算速度大大提高。许多程序需要处理大量的数据集,而且很多都是由少于32bits的位数来存储的。比如在视频、图形、图像处理中的8-bit像素数据等。在诸如上述情形中,很可能充斥着大量简单而重复的运算,且少有控制代码的出现,simd就擅长为这类程序提供更高的性能。neon:neon就是一种基于simd思想的arm技术,相比于armv6或之前的架构,neon结合了64-bit和128-bit的simd指令集,提供128-bit宽的向量运算(vector operations)。neon技术从armv7开始被采用,目前可以在arm cortex-a和cortex-r系列处理器中采用。现有的高斯平滑算法没有有效利用neon寄存器,还是传统的c方式进行处理,效率低。
技术实现要素:
6.鉴于目前图像处理技术领域存在的高斯平滑处理时效率低的问题,本发明提供一种适用于高斯平滑的neon优化方法,能够高效利用neon寄存器,效率提升。
7.为达到上述目的,本发明的实施例采用如下技术方案:
8.一种适用于高斯平滑的neon优化方法,所述方法包括以下步骤:
9.执行高斯平滑算法;
10.将每个点的权值系数读取到neon寄存器中;
11.将一预设的待乘值读取到neon寄存器中并向量化;
12.按行读取待计算点及其邻近域数据;
13.对待计算点及邻近域数据进行计算时,先乘以待乘值再进行移位操作。
14.依照本发明的一个方面,所述高斯平滑算法为5
×
5高斯平滑算法,是以待计算点及其邻近域共计25个点的y分量值分别乘上相应的权值后相加,再平均后得出待计算点最终结果。
15.依照本发明的一个方面,所述5
×
5高斯平滑算法的待乘值设为78,需要先将78读
取到寄存器中并做向量化。
16.依照本发明的一个方面,所述向量化为16位向量化。
17.依照本发明的一个方面,所述对待计算点及邻近域数据进行计算时,先乘以待乘值再进行移位操作包括:将sum=sum/52转换为sum=sum*78》》12。
18.依照本发明的一个方面,所述按行读取待计算点及其邻近域数据包括:至少需要读取5次数据,考虑到neon的寄存器个数,选择每行每次读取24字节。
19.依照本发明的一个方面,每次读取数据可以计算出20个点。
20.依照本发明的一个方面,所述方法包括以下步骤:进行寄存器拼接处理,并将结果存放至内存中。
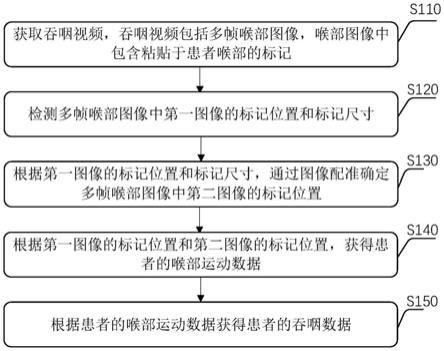
21.依照本发明的一个方面,所述将结果存放至内存中包括:基于neon寄存器,需将结果分多次存储。
22.依照本发明的一个方面,所述方法包括以下步骤:将不需要参与计算的数据权值设成0,计算同行的下一个数据,只需将权值数据滚动一下即可。
23.本发明实施的优点:
24.1、高效利用了neon寄存器(32个d寄存器全部都有使用到);
25.2、相比于传统的c方式,效率提升100% 。
26.在neon有限的寄存器下(32个64bit寄存器),在计算5x5高斯平滑时每计算20个点值只需要需要取5次数据,存3次数据。
27.预先读取每个点的权值系数进neon寄存器,避免反复读取同样的数据,每张图只需要读取一次。
附图说明
28.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
29.图1为本发明所述的一种适用于高斯平滑的neon优化方法示意图;
30.图2为本发明所述的5
×
5高斯平滑算法权重示意图;
31.图3至图7为本发明实施例所述的计算过程示意图。
具体实施方式
32.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
33.如图1、图2、图3、图4、图5、图6和图7所示,一种适用于高斯平滑的neon优化方法,所述方法包括以下步骤:
34.步骤s1:执行高斯平滑算法;
35.在本实施例中,所述高斯平滑算法为5
×
5高斯平滑算法,如图2所示,是以待计算
点及其邻近域共计25个点的y分量值分别乘上相应的权值后相加,再平均后得出待计算点最终结果。
36.步骤s2:将每个点的权值系数读取到neon寄存器中;
37.如图2所示,5
×
5高斯平滑算法对应的权重分布,可以看出5行对应三种系数,需要将这三种系数先读取到neon寄存器中,避免重复读取。
38.步骤s3:将一预设的待乘值读取到neon寄存器中并向量化;
39.如图3所示,对除运算也做个优化,变成先乘再移位操作(sum=sum/52
‑‑
》sum=sum*78》》12),所以也需要将78这个值也先读取到neon寄存器中并做向量化,考虑到8bit数据乘以系数之后可能溢出,这里需要做16bit向量化。注:/52是因为5x5矩阵的权重和为52,具体通过如下代码实现:
[0040][0041]
步骤s4:按行读取待计算点及其邻近域数据;
[0042]
步骤s5:对待计算点及邻近域数据进行计算时,先乘以待乘值再进行移位操作。
[0043]
在本实施例中,由于每个点计算所要用到的5x5的数据分别来自不连续的5行,所以至少需要读取5次数据,这里考虑到neon的寄存器个数,选择每行每次读取24byte。具体通过如下代码实现:
[0044][0045]
如图4所示,每次读取都可以计算出20个点;
[0046]
使用的d8,d11,d14,d17,d20可以计算出图4中标注1的四个点,计算结果如图5存放再d24中,计算过程如下:
[0047][0048][0049]
经过简单的寄存器拼接处理,可以将d8,d11,d14,d17,d20中的数据变成如图6所示,计算过程如下:
[0050][0051]
通过同样的处理,可以将图6中的4个数据放在d25,再将d24,d25(q12)一起存入内存,具体如下:
[0052]
"vmovn.u16
ꢀꢀꢀꢀꢀꢀ
d24,q12
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
\n\t"
[0053]
"vst1.u8
ꢀꢀꢀꢀꢀꢀꢀꢀ
{d24},[%0]!
ꢀꢀꢀꢀꢀꢀ
\n\t"
[0054]
d9,d10,d12,d13,d15,d16,d18,d19,d21,d22,可以经过上述同样的步骤,最终将结果存放至内存中。这里因为neon寄存器紧张,故将20个结果分三次store,分别为:1,2存一次;3,4存一次;4,5存一次。
[0055]
如图7所示,每次读取5行各24个数据可以算出20个点,即每次算20个点需要取5次数据,存3次数据。
[0056]
在实际应用中,所述方法还包括以下步骤:将不需要参与计算的数据权值设成0,计算同行的下一个数据,只需将权值数据滚动一下即可。具体如下实现:
[0057]
每个neon 64bit寄存器可以存储8个8bit数据,但是5x5 neon优化每行只需要5个8bit数据进行计算,由于源数据有5行,所以这里避免操作源数据,采取在权值数据上做手脚,也即不需要参与计算的数据权值设成0,如下:
[0058]
unsigned char shift_5x5[32]={1,1,2,
[0059]
1,2,4,
[0060]
2,4,8,
[0061]
1,2,4,
[0062]
1,1,2,
[0063]
0,0,0,
[0064]
0,0,0,
[0065]
0,0,0};
[0066]
计算同行的下一个数据,只需将权值数据滚动一下,如下:
[0067]
{0,0,0,
[0068]
1,1,2,
[0069]
1,2,4,
[0070]
2,4,8,
[0071]
1,2,4,
[0072]
1,1,2,
[0073]
0,0,0,
[0074]
0,0,0}。
[0075]
在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种
编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
[0076]
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
[0077]
类似地,应当理解,为了精简本公开并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
[0078]
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
[0079]
此外,本领域的技术人员能够理解,尽管在此的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
[0080]
应该注意的是上述实施例对本发明进行说明而不是对本发明进行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
[0081]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域技术的技术人员在本发明公开的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。