1.本发明属于政策效果预测领域,具体是基于“政策-舆论-购买”双阶深度学习的销量预测方法。
背景技术:
2.在政策对消费购买行为的影响过程中,网络舆论起到非常重要的影响作用。一方面,随着互联网技术的发展,人们能够及时获取最新的政策,并在互联网上发表舆论和展开讨论,这些内容一定程度上能够反映和影响消费者的消费意愿,从而对商品的销量产生一定的影响,因此,以政策为切入点,研究政策相关的网络舆论,并结合历史数据对商品的销量预测准确性提升具有重要意义。
3.在预测技术方面,随着人工智能及大数据技术的普及,相对于传统计量模型来说,人工智能的方法具有处理数据量大、处理数据维度多以及预测准确率高等优点,因此,利用人工智能的技术进行政策的市场效果预测具有一定优势。但是现有人工智能预测没有从政策引发网络舆论的角度对产品购买销量进行预测。首先,现有解决方案有一些是政策对引发舆论的预测、有一些是舆论对销量的预测,多为分离的两个预测环节,很少将两个预测环节进行结合,没有实现“政策-舆论-销量”的全过程预测。其次,上述两个环节预测的现有解决方案,也存在其各自的问题。
4.在舆情预测方面,现有专利多对舆情的热点及其发展趋势进行预测,而对于多维度衡量舆情发展的具体属性指标却有较少预测。例如中国专利申请号cn112364164a,申请公布日为2021年2月12日,发明创造名称为面向特定社会群体的网络舆情主题发现及趋势预测方法。该方案对面向特定人群的舆论文档进行分类,建立lda主题模型并进行情感极性分析,在此基础上建立主题预测模型,但该研究只集中于主题分布,而忽略了舆论的关注度等指标的未来发展趋势,对舆论的预测不够完全。
5.而在销量预测方面,现有的销量预测多从历史销量数据出发,数据维度单一。其销量预测的准确性依然有待提升。例如中国专利申请号cn111932292a,申请公布日为2020年 11月13日,发明创造名称为:一种基于深度神经网络的卷烟产品销量预测方法及装置。该方案构建卷烟产品预测的神经网络模型,将卷烟产品的销售时序特征和销量统计特征等作为神经元的输入,并进行模型训练从而对卷烟销量进行预测,但该研究只从产品的历史销量出发,未考虑到政策及舆论的影响力。并且,其数据维度只限于销售时序和销量统计特征,未结合商品自身特有的属性,数据维度不够丰富。
6.现有技术的缺陷包括:
7.1.“政策-舆论”预测及“舆论-销量”预测环节多处于分离孤立的状态,不能将其进行结合,从政策引发舆论角度对销量进行预测。
8.2.舆情预测方面,对舆情的预测多集中在主题和热点的预测,而忽略了对舆情的关注度、情感指数等舆论属性的预测,舆情预测的全面性有待完善。
9.3.在销量预测方面,多基于历史销售数据,用于预测的数据维度过于单一
10.4.在预测方法方面,较少结合商品自身的属性,对于原始数据中的属性特征提取也缺乏完整性,预测模型的性能有待提升。
技术实现要素:
11.为克服上述现有技术的不足,本发明提供基于“政策-舆论-购买”双阶深度学习的销量预测方法,用以解决上述至少一个技术问题。
12.本发明是通过以下技术方案予以实现的:
13.基于“政策-舆论-购买”双阶深度学习的销量预测方法,包括以下步骤:
14.s1,在相关政府网站和政策数据库采集目标领域政策文本;
15.s2,对采集的政策文本进行预处理;
16.s3,识别政策文本标题中的实体,提取政策文本正文中的关键词,根据识别出的实体和提取出的关键词确定政策舆论检索关键词,同时计算政策效果指标,并依据政策舆论检索关键词和计算出的政策效果指标形成政策文本特征;
17.s4,在相关网络舆论平台搜索政策舆论检索关键词,获取舆情数据并进行指标量化,形成舆情数据特征;
18.s5,构建bp神经网络预测模型,以s2中的政策文本特征作为输入变量,以s3中的舆情数据特征作为输出变量,对预测模型进行训练,得到训练好的预测模型,并将新发布的政策文本特征输入训练好的模型,得到舆情预测数据。
19.s6,构建svr模型并引入果蝇算法进行优化,得到优化后的svr模型,并将s5中的舆情数据输入优化后的svr模型,得到销量预测数据。
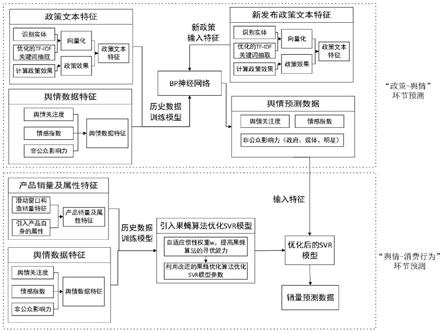
20.上述技术方案充分利用网络信息,以政府政策为切入点,建立一个“政策-舆论”及“舆论-消费行为”双环节预测模型,首先对政府的历史政策及其相关评论进行采集,并基于历史数据采用bp神经网络的方法,建立政策-舆论的预测模型,对舆论的关注度、情感指数等指标进行预测,并输出预测值。第二环节利用第一环节的舆论相关属性预测值,结合商品自身属性,利用特征工程对原始数据进行最大限度的属性提取,一定程度上丰富了特征的维度,采用支持向量回归(svr)算法建立舆论-销量预测模型,并引入果蝇算法对svr算法模型进行参数优化,进而提高模型整体的预测性能和预测效果,为政府优化政策制定,为企业提高销量预测准确率,降低成本,提高利润提供决策支持。
21.作为进一步的技术方案,s1进一步包括:
22.s11,确定数据源,包括相关政府网站及政策数据库;
23.s12,利用网络爬虫工具,根据自定义采集规则采集政策文本数据;
24.s13,对s12中采集的政策文本数据进行随机抽样,将抽样数据与s11中的源数据进行匹配校验,剔除因爬取过程出错而造成的不完整数据或错误数据;
25.s14,在确保爬取数据通过校验的情况下,将采集到的政策文本数据作本地持久化存储。
26.具体而言,s13中,对s12中采集的政策文本数据进行随机抽样,如抽取50条左右的政策,将抽取的政策结果分别与s11数据源中所对应的政策内容进行匹配校验,剔除因爬取过程出错而造成的不完整数据或错误数据。
27.作为进一步的技术方案,s2进一步包括:对采集到的政策文本数据进行去重、去噪
和文本短句删除。该技术方案主要是数据清洗,即重复值、无效值、空值的处理,以及对清洗完的数据进行分词和去除停用词。
28.s2具体包括:
29.s21,去重,即删除文本数据中的重复数据,减少冗余信息的干扰。
30.s22,去噪,将政策文本数据内的网址等特殊字符删除,让文本特征更集中于词汇和语义本身。
31.s23,文本短句删除,是指删除政策文本数据中字数过于少的数据。
32.作为进一步的技术方案,s3进一步包括:
33.s31,利用python调用hanlp中的ner模块来识别政策文本标题中的实体;
34.s32,利用改进的tf-idf对政策文本正文进行关键词提取,去除停用词后按照关键词权重进行排序,选取权重最高的若干个关键词;
35.s33,将识别出的实体与选取出的若干个关键词组合作为政策舆论检索关键词;
36.s34,从政策力度、政策目标和政策措施三个维度计算政策效果指标;
37.s35,依据政策舆论检索关键词和计算出的政策效果指标形成政策文本特征。
38.具体而言,s32中,考虑到公文正文第一段的说明性文字包含许多重要信息,因此对全文的首段和各个段落的首句给予较大的权重,形成改进的tf-idf对政策文本正文进行关键词提取,并在去除停用词后按照关键词权重进行排序,选取权重最高的若干个关键词。
39.作为进一步的技术方案,s4进一步包括:
40.s41,舆论搜索及爬取:根据s3提取的政策舆论检索关键词在形成有全网搜索指数的网络平台中进行搜索,确定舆论活跃期,将该舆论活跃期作为评论文本爬取的时间区间,爬取的数据包括与政策关键词相匹配的网络舆论发布者的文章评论内容、评论量、点赞量、转发量;
41.s42,舆情关注度计算:统计与政策相关的总评论数以及当期所有评论数据,以前者与后者的比值来计算消费者的舆情关注度;
42.s43,情感指数计算:采取自然语言处理技术,对爬取的评论从情感方面进行量化,计算情感指数得分;
43.s44,非公众影响力计算:首先计算出政府、媒体和明星三个群体的群体影响力,依据政策关键词获取政府、媒体和明星的相关文章后,对三个群体的评论量、转发量和点赞量分别进行统计,单个群体影响力为评论量、转发量和点赞量三个变量的线性组合,组合系数采用熵值法确定;其次计算非公众影响力,非公众影响力为三个群体的各自群体影响力的线性组合,组合系数同样采取熵值法确定。
44.作为进一步的技术方案,s43进一步包括:
45.s431,对每条评论文档分词,找出文档中的情感词、否定词以及程度副词;
46.s432,否定词与程度副词处理:判断每个情感词之前是否有否定词或程度副词,若有否定词或程度副词,则将情感词与之前的否定词或程度副词划分为一个组,并将情感词的情感得分乘以这一个组对应的权重系数;否定词的权重系数设置为-1,程度副词根据语义设置不同的权重系数;
47.s433,特殊句式处理:判断评论文档中的每一句话是否是感叹句或反问句,若是则增加情感得分值;
48.s434,将该条评论文档中所有情感得分加起来,即为最终该条评论文档的情感分析得分。
49.作为进一步的技术方案,s5进一步包括:
50.s51,将政策文本特征和舆情数据特征进行归一化处理,形成数据集;
51.s52,将数据集按照7:3的比例划分为训练集和测试集;
52.s53,利用bp神经网络建立预测模型,将s2识别出的实体、确定出的政策舆论检索关键词以及计算出的政策效果指标作为输入变量,将舆情关注度、情感指数、非公众影响力作为输出变量;
53.s54,利用s42的训练集和测试集分别对预测模型进行训练和测试,并依据测试结果优化预测模型参数,得到训练好的预测模型;
54.s55,利用训练好的预测模型进行舆情数据预测。
55.作为进一步的技术方案,s6进一步包括:
56.s61,获取产品销量数据和舆情数据,并进行预处理;
57.s62,引入产品自身的属性,从产品销量数据、舆情数据、产品自身属性数据三个维度构建数据集;
58.s63,将数据集按照7:3的比例划分训练集和测试集;
59.s64,特征提取和特征构造,确定销量预测特征;
60.s65,以产品销量数据、舆情数据、产品自身属性数据作为输入变量,以确定的销量预测特征作为输出变量,利用s63的训练集和测试集对svr模型进行训练和验证,得到训练好的svr模型。
61.作为进一步的技术方案,s6进一步包括引入果蝇算法优化svr模型,具体如下:
62.a,初始化果蝇群体位置x
axis
和y
axis
;
63.b,随机寻找食物的方向和距离:
[0064][0065][0066]
w为自适应惯性权重,w的计算公式为:g为当前迭代次数, maxgen为最大迭代次数;
[0067]
c,计算此时位置与原点距离
[0068]
d,计算味道浓度判别值
[0069]
e,将味道浓度判别值代入味道浓度判定函数来求出该果蝇个体的味道浓度smelli,使用rmse作为味道浓度判断函数,
[0070][0071]
其中ti为训练集样本的真实值,yi为训练集样本的预测值;
[0072]
f,寻找该果蝇群体中味道浓度最好的果蝇个体,选择rmse最小的作为最佳味道浓
度值对应的果蝇个体:[bestsmell bestindex=min(smell)];
[0073]
g,保留最佳味道浓度值及其位置坐标,果蝇群体前往该位置:
[0074]
smell best=bestsmell
[0075]
x
axis
=x(bestindex)
[0076]yaxis
=y(bestindex);
[0077]
h,迭代寻优,重复执行步骤b-f,判断味道浓度是否大于上一次的结果,若是则执行步骤g,当满足精度要求或达到最大迭代次数,则执行步骤i;
[0078]
i,将参数代入svr模型进行预测。
[0079]
与现有技术相比,本发明的有益效果在于:
[0080]
(1)本发明将“政策-舆论”与“舆论-消费行为”两个预测环节打通,通过舆论的量化指数,将两个环节进行结合,从而实现了“政策-舆论-消费行为”的全过程预测。
[0081]
(2)本发明在政策文本特征的构建过程中,将政策的实体、政策内容关键词结合政策效力作为输入参数,并在提取关键词时对传统的tf-idf进行优化,解决其无法体现词位置信息的问题。
[0082]
(3)本发明在舆情预测方面,从舆论关注度、舆论情感指数和舆论中非公众群体的影响力三个方面,对于政策引发的舆论进行预测,对于舆论预测相对较为全面。
[0083]
(4)本发明在销量预测方面,数据维度包括历史数据、商品自身属性、舆论预测指标三个方面,丰富了进行预测的数据指标维度。
[0084]
(5)本发明在预测方法上,两个环节采取了不同的预测算法,在舆情预测环节结合政策本身属性使用bp神经网络对舆情进行预测,在销量预测环节使用引进自适应惯性权重系数的改进版果蝇优化算法对svr模型参数进行优化,提高了模型预测的准确性。
附图说明
[0085]
图1为本发明第一实施例的基于“政策-舆论-购买”双阶深度学习的销量预测方法的流程示意图;
[0086]
图2为本发明第一实施例中步骤s1政策文本采集的流程示意图;
[0087]
图3为本发明第一实施例中步骤s3政策内容分析的流程示意图;
[0088]
图4为本发明第一实施例中步骤s4舆情数据量化指标计算的流程示意图;
[0089]
图5为本发明第一实施例中步骤s4中子步骤s44情感指数计算的流程示意图;
[0090]
图6为本发明第一实施例中步骤s5舆情数据预测的流程示意图;
[0091]
图7为本发明第一实施例中步骤s6销量预测的流程示意图;
[0092]
图8为本发明第一实施例中步骤s6中子步骤s641所述果蝇优化算法确定svr核心参数流程示意图。
具体实施方式
[0093]
以下将结合附图对本发明各实施例的技术方案进行清楚、完整的描述,显然,所描述发实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施例,都属于本发明所保护的范围。
[0094]
如图1所示,本实施例提供了基于“政策-舆论-购买”双阶深度学习的销量预测方法,本例以分析新能源汽车政策舆论效应,预测新能源汽车销量为例,包括以下步骤:
[0095]
s1,在相关政府网站和政策数据库采集新能源汽车相关政策文本。
[0096]
s2,对收集的政策文本数据进行预处理。
[0097]
s3,识别政策标题中的实体,提取政策文本正文中的关键词,根据识别出的实体和提取的关键词确定为政策舆论检索关键词,同时计算政策效果指标,并依据政策舆论检索关键词和计算出的政策效果指标形成政策文本特征。
[0098]
s4,在相关网络舆论平台搜索政策舆论检索关键词,获取舆情数据并进行指标量化,形成舆情特征数据。
[0099]
s5,构建bp神经网络预测模型,以s2中的政策文本特征作为输入变量,以s3中的舆情数据特征作为输出变量,对预测模型进行训练,得到训练好的预测模型,并将新发布的政策文本特征输入训练好的预测模型,得到舆情预测数据。
[0100]
s6,构建svr模型并引入果蝇算法进行优化,得到优化后的svr模型,并将s5中的舆情预测数据输入优化后的svr模型,得到销量预测数据。
[0101]
具体地,步骤s1如图2所示,具体包含:
[0102]
s11,确定数据源,本文所涉及政策数据源为中国工业信息网、工信部等相关政府网站及以北大法意为代表的政府政策数据库。
[0103]
s12,利用python编写网络爬虫程序或者使用后羿采集器、八爪鱼等采集工具,自定义采集规则,采集新能源汽车政策文本数据。
[0104]
s13,对采集来源进行随机抽样,并与爬取到的数据进行匹配校验,剔除因爬取过程出错而造成的不完整数据或错误数据。对s12中采集的政策文本数据进行随机抽样,抽取 50条左右的政策,将抽取的政策结果分别与s11数据源中所对应的政策内容进行匹配校验,剔除因爬取过程出错而造成的不完整数据或错误数据。
[0105]
s14,在确保爬取数据通过校验的情况下,将采集到的数据作本地持久化存储。
[0106]
具体地,步骤s2数据预处理主要包括数据清洗,即去重、去噪、文本短句删除。s2 具体步骤包括:
[0107]
s21,去重,即删除文本数据中的重复数据,减少冗余信息的干扰。
[0108]
s22,去噪,将政策文本数据内的网址等特殊字符删除,让文本特征更集中于词汇和语义本身。
[0109]
s23,文本短句删除,是指删除政策文本数据中字数过于少的数据。
[0110]
具体地,步骤s3主要采用实体识别、关键词抽取等深度学习的方法对政策文本数据进行处理。具体步骤s3如图3所示,具体包含:
[0111]
s31,利用python调用hanlp中的ner模块提取政策标题中的实体。hanlp是一个开源的自然语言处理工具包,可以利用其轻松实现机构名、人名、地名等实体的识别。
[0112]
s32,考虑到公文正文第一段的说明性文字包含许多重要信息,因此对全文的首段和各个段落的首句给予较大的权重,形成改进的tf-idf,并利用改进的tf-idf对政策正文进行关键词提取,去除停用词后按照关键词权重进行排序,选取权重最高的前3个关键词。
[0113]
s33,将识别出的实体与提取出的关键词组合作为政策舆论检索关键词。
[0114]
s34,计算政策效果。
[0115]
s341,从政策力度、政策目标和政策措施三维度进行打分,分值划分成不同等级,具体分类和分值划分参照相关文献或专利并结合自身收集的政策进行分类。
[0116]
s342,tpe=(goal method)*power,其中tpe为政策效力,goal为政策目标的分值, method为政策措施的分值,power为政策力度的分值。
[0117]
具体地,步骤s32所述对tf-idf算法进行改进方法为考虑到政策公文具有高度规范性,公文正文第一段的说明性文字包含许多重要信息,因此对全文的首段和各个段落的首句给予较大的权重,解决tf-idf算法无法体现词位置信息的问题。
[0118]
具体地,s4步骤的舆论挖掘方法为基于政策相关舆论进行文本挖掘,根据用户身份进行划分,在不同类别的用户中挖掘评论数据,计算评论其关注度、情感指数以及群体影响力等指数,从而对挖掘的文本数据进行多维度的量化。具体步骤s4如图4所示。
[0119]
s41,舆论搜索及爬取
[0120]
政府政策的发布,会引起消费者对于所涉及商品的广泛讨论,其表现之一为全网搜索量的上升,而百度指数则会记录特定搜索词的日搜索量,可根据s3步骤提取的关键词在百度指数中进行搜索,从而确定舆论活跃期,也即评论文本爬取的时间区间。按照网络舆论发布者自身属性的不同,可分为政府、媒体、明星和民众四类,爬取的评论来源主要为新浪微博、汽车之家、小红书等网络舆论发布网站。爬取的数据主要包括,与政策关键词相匹配的网络舆论发布者的文章评论内容、评论量、点赞量、转发量。
[0121]
s42,消费者关注度计算
[0122]
统计与政策相关的总评论数以及当期所有评论数据,以前者与后者的比值来计算消费者关注度。
[0123]
s43,情感指数计算
[0124]
采取自然语言处理技术,对爬取的评论从情感方面进行量化,计算其情感指数得分。本发明基于情感词典进行文本情感倾向分析,s43具体步骤如图5所示,具体包括:
[0125]
s431,在做情感分析前需先对文档(每条评论)分词,找出文档中的情感词、否定词以及程度副词。
[0126]
s432,程度词与否定词处理。判断每个情感词之前是否有否定词或程度副词,将它之前的否定词或程度副词划分为一个组,如果有否定词将情感词的情感权值乘以-1,如果有程度副词就乘以程度副词的程度值。
[0127]
s433,特殊句式处理。判断是否是感叹句或是反问句,判断句尾标点符号是否为感叹号或问号,若有则增加一定情感得分值。
[0128]
s434,将该条评论中所有词的情感得分加起来,即为最终该评论的情感分析得分。
[0129]
s44,非公众影响力计算,具体地,s44步骤如下:
[0130]
s441,首先计算出三个群体(政府、媒体和明星)的群体影响力,依据政策关键词获取政府、媒体和明星的相关微博后,对三个群体的评论量、转发量和点赞量分别进行统计。群体影响力为以上三个变量的线性组合,组合系数采用熵值法确定。
[0131]
s442,非公众影响力为三个群体的群体影响力的线性组合,其组合系数同样采取熵值法确定。
[0132]
具体地,步骤s5主要是建立预测模型,将政策文本特征作为输入,舆论相关预测指标作为输出,具体步骤如图6所示。
[0133]
s51,将步骤s3所识别的政策实体和关键词使用word2vec向量化,与计算出的政策效果构建政策文本特征,并结合舆情特征指标,并对数据做归一化处理,形成数据集。
[0134]
s52,将数据集按照7:3的比例划分为训练集和测试集,其中训练集用于训练bp神经网络模型优化参数,测试集用于验证模型预测效果。
[0135]
s53,利用bp神经网络建立预测模型,将政策实体、政策关键词以及政策效力作为输入变量,将舆情关注度、情感指数、影响力作为输出变量。
[0136]
s54,参数调整。先默认激活函数使用sigmoid函数,优化方法使用adam算法,并且设置不同的训练次数,比较不同训练次数下不同的学习率对模型预测效果的影响。确定好最佳学习率后再比较不同激活函数和优化方法组合的预测效果,从而优化模型参数。
[0137]
s55,利用模型实现对政策引发的舆情关注度等舆情数据的预测。
[0138]
具体地,步骤s6主要是基于历史销售数据、商品自身属性以及舆论预测指标三个维度对商品销量进行预测,流程如图7所示,具体包含以下步骤:
[0139]
s61,数据预处理。对于销售数据,在数据处理前需对其进行空值和异常值的检测,用平均值对空值或异常值进行填充。之后将数值数据进行归一化处理。对于用户评论的文本数据,则主要是去重、去除文本短句、分词、去除停用词、词频统计、计算评论情感得分等。
[0140]
s62,引入产品自身的特有属性,本实施例以新能源汽车销量为例,引入了新能源汽车均价、平均续驶里程、平均百里耗电量等属性。
[0141]
s63,将数据按照7:3的比例划分训练集和测试集,训练集用于训练预测模型,测试集用于检验模型的预测效果。
[0142]
s64,特征工程。通过特征工程最大限度地从原始数据中选出一些与预测值相关的属性,减少数据维度,从而减少模型训练时间。主要涉及到特征的提取和构造,具体步骤如下:
[0143]
s641,特征提取。在步骤s51已对数据进行预处理,此处可直接使用。利用python 调用scipy库计算pearson相关系数来计算出数据属性和预测值的相关性,进而筛选出与预测值相关性较强的属性。
[0144]
s642,构造特征。本文利用滑动窗口构造特征。将选取的月度销量之前的前1、2、3 个月以及去年同月的销售数据作为预测销量的特征之一。
[0145]
s65,模型训练及预测。具体步骤包含:
[0146]
s651,参数确定。svr模型需要确定核函数、惩罚因子以及核系数。核函数kernel 选择用性能较好的径向基函数(radial basis function,rbf)。惩罚因子c及核系数γ的优化通过引进自适应惯性权重系数的改进版果蝇优化算法进行确定。确定好核心参数后,使用python的scikit-learn机器学习库搭建模型。
[0147]
s652,在测试集上利用已训练好的模型进行预测,得到预测结果。
[0148]
步骤s651中所述果蝇优化算法是基于果蝇觅食行为的仿生学原理而推演出的全局优化方法。具体步骤如图8所示,主要包含以下步骤:
[0149]
a,初始化果蝇群体位置x
axis
和y
axis
。
[0150]
b,随机寻找食物的方向和距离:
[0151]
xi=x
axis
w*random value
[0152]
yi=y
axis
w*random value;
[0153]
其中,引入了自适应惯性权重w,提高算法的寻优能力。w的计算公式为:g为当前迭代次数,maxgen为最大迭代次数。迭代初期,权重较大,加强全局寻优能力,在迭代后期权重较小,可以加强局部寻优能力。
[0154]
c,计算此时位置与原点距离
[0155]
d,计算味道浓度判别值
[0156]
e,将味道浓度判别值代入味道浓度判定函数来求出该果蝇个体的味道浓度smelli。本发明使用rmse作为味道浓度判断函数。
[0157][0158]
其中ti为训练集样本的真实值,yi为训练集样本的预测值。
[0159]
f,寻找该果蝇群体中味道浓度最好的果蝇个体。由于rmse计算结果越小说明模型拟合效果越好,此处应选择rmse最小的作为最佳味道浓度值对应的果蝇个体:
[0160]
[bestsmell bestindex=min(smell)]。
[0161]
g,保留最佳味道浓度值及其位置坐标,果蝇群体前往该位置:
[0162]
smell best=bestsmell
[0163]
x
axis
=x(bestindex)
[0164]yaxis
=y(bestindex)。
[0165]
h,迭代寻优,重复执行步骤b-f,判断味道浓度是否大于上一次的结果,若是则执行步骤g。当满足精度要求或达到最大迭代次数,则执行步骤i。
[0166]
i,将参数代入svr模型进行预测,得到新能源汽车销量预测值。
[0167]
本发明以政府政策为切入点,建立“政策-舆论”及“舆论-消费行为”的双环节预测模型。第一环节采用bp神经网络的方法,结合历史政策及评论数据,建立政策-舆论的预测模型,预测输出值为舆论的关注度、情感指数等指标。第二环节利用第一环节的舆论相关属性预测值,结合商品自身属性,利用特征工程对原始数据进行最大限度的属性提取,采用支持向量回归(svr)算法建立舆论-销量预测模型,并使用引进自适应惯性权重系数的改进版果蝇优化算法对svr算法模型进行全局优化,进而提高模型整体的预测性能和预测效果。进而提高模型整体的预测性能和预测效果,为企业提高销量预测准确率,降低成本,提高利润提供实质性建议。
[0168]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。