1.本发明涉及个性化预测技术领域,更具体的说是涉及一种基于文本和表情符号特征的用户个性化预测方法。
背景技术:
2.近几年来,随着社交网络的迅猛发展,越来越多的用户通过微博、微信等社交软件进行信息交流。社交网络涵盖以用户社交为核心的所有网络服务形式,互联网是一个能够让用户相互交流、相互参与的互动平台。截止到2020 年,全球社交网络用户规模达到32.3亿人,在互联网用户的比例达到80.70%,用户平均每天在社交网络和即时通讯应用上花费2小时24分钟;因此智能营销策略应运而生。
3.智能营销是通过人的创造性、创新力以及创意智慧将先进的计算机、网络、移动互联网,物联网等科学技术的融合应用于当代品牌营销领域的新思维、新理念、新方法和新工具的创新营销新概念。
4.在智能营销过程中最主要的就是为用户推荐符合其心意的商品,为用户推荐符合其心意的商品就必须对用户进行精确的个性化预测,但是现有技术中对用户的个性化预测精度往往并不是很高,因此提供一种高精确度的用户个性化预测方法是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种基于文本和表情符号特征的用户个性化预测方法,克服了上述的缺陷。
6.为了实现上述目的,本发明提供如下技术方案:
7.一种基于文本和表情符号特征的用户个性化预测方法,具体步骤为:
8.获取基础数据:在社交网络系统中获取基础数据;
9.特征提取:将基础数据按类别分别进行特征提取,构建训练数据库;
10.训练预测模型:基于训练数据库中的数据对预测模型进行训练;
11.用户个性化预测:根据预测模型对用户进行个性化预测。
12.可选的,训练数据库的构建步骤为:
13.将基础数据进行筛选;
14.将筛选后的基础数据按照不同的类别进行特征提取;
15.根据各个特征的权重,确定预测指标体系;
16.根据预测指标体系,构建训练数据库。
17.可选的,基础数据包括个人数据和交互数据。
18.可选的,个人数据包括用户的身份信息、认证类型、微博内容。
19.可选的,交互数据包括用户的认证信息、身份信息、互动内容以及评论用户的性别。
20.可选的,特征提取的类别包括文本特征和表情符号特征。
21.可选的,个人数据的文本特征提取步骤为:
22.获取个人数据中各个文本一元词的频率;
23.根据各个文本一元词的频率获得文本词特征;
24.获取个人数据中文本情感词的分类以及各个类型文本情感词的数量;
25.根据各个类型文本情感词的数量以及各个类型文本情感词的数量获得文本情感词特征;
26.根据文本词特征和文本情感词特征获取个人数据的文本特征。
27.可选的,个人数据的表情符号特征提取步骤为:
28.获取个人数据中的表情符号;
29.获取各个表情符号的使用频率;
30.根据各个表情符号的使用频率提取表情词特征;
31.对各个表情符号进行分类并统计各个类别的表情符号的数量;
32.根据表情符号的类别数与各个类别的表情符号的数量获得表情情感特征;
33.结合表情词特征以及表情情感特征得到个人数据的表情符号特征。
34.可选的,交互特征提取步骤为:
35.获取交互数据中的一元词;
36.通过信息增益的特征选择方法计算每个一元词的ig值;
37.对ig值进行排序,选择预设阈值内的一元词作为交互数据的文本特征;
38.获取交互文本中的表情符号和用户性别组合;
39.通过信息增益的特征选择方法计算每个表情符号和用户性别组合的ig 值;
40.对ig值进行排序,选择预设阈值内的表情符号和用户性别组合作为交互数据的表情符号特征;
41.结合交互数据的文本特征和表情符号特征,获得交互数据的交互特征。交互特征中还包括f-measure特征,计算公式为:
[0042][0043]
其中,freq.noun、freq.adj、freq.prep、freq.art、freq.pron、freq.verb、freq.adv、 freq.int分别表示文本中名词、形容词、介词、冠词、代词、动词、副词和感叹词的频率。
[0044]
经由上述的技术方案可知,与现有技术相比,本发明公开了一种基于文本和表情符号特征的用户个性化预测方法,通过文本和表情符号特征的融合,提高了用户个性化预测的准确率,以实现高效的智能化营销。
附图说明
[0045]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0046]
图1(a)为本发明实施例中男性用户不同种类表情使用占比示意图;图 1(b)为本发明实施例中女性用户不同种类表情使用占比示意图;
[0047]
图2(a)为本发明实施例中各类别特征相关性分析结果示意图;图2(b) 为本发明实施例中各类别特征的重要性分数排序结果示意图;
[0048]
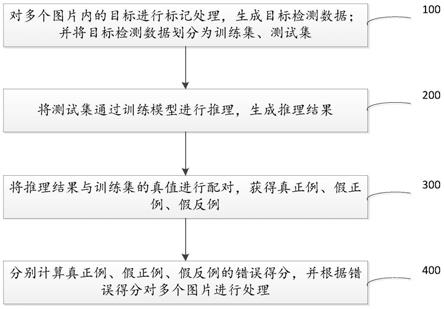
图3为本发明的方法流程示意图;
[0049]
图4为本发明实施例中不同性别用户使用频率前十的表情符号示意图;
[0050]
图5为本发明实施例中对表情符号按照情绪划分的分类示意图;
[0051]
图6为本发明实施例中用户交互时表情符号和性别组合特征样例。
具体实施方式
[0052]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0053]
本发明实施例公开了一种基于文本和表情符号特征的用户个性化预测方法,如图3所示,具体为:
[0054]
步骤1、收集基础数据
[0055]
本实施例中的数据来自新浪微博微热点大数据研究院提供的单个用户微博数据集和用户交互数据集。单个用户微博数据集的用户多为明星用户以及粉丝量多的大v用户,如黄渤、何炅等,微博内容大多是对生活的分享;用户交互数据集中的用户基本是粉丝较少的普通用户,且微博内容多是某些话题的讨论。单个用户微博数据集共有226.3万条微博数据。为了保证实验的准确性,去除原始数据中的重复微博内容以及使用表情数量较少的用户,最终选取男性用户和女性用户各550个,每个用户的微博数量为1000条,单个用户数据中包含用户姓名、认证类型、用户性别、微博内容等属性。用户交互数据集共有174.7万条数据,过滤后选取19000个男性用户和19000个女性用户,用户交互数据包括原创微博用户名、用户认证类型、原创微博用户性别、微博转发评论内容以及评论用户的性别等。新浪微博将用户分为“普通用户”、“橙 v用户”、“蓝v用户”、“达人用户”和“金v用户”,“普通用户”是指没有经过认证的个人用户和企业用户,为保证实验结果的可靠性,本实施例数据中使用的所有微博用户数据都是经过新浪微博官方认证的个人用户数据。
[0056]
步骤2、特征提取
[0057]
步骤21、基于个人数据的文本特征提取
[0058]
步骤211、分析用户的微博文本,获取文本中有高区分性的词语作为用户个性化的预测的特征,因此,本实施例计算微博文本中每个词的使用频次作为文本词特征的提取依据,并根据每个文本词特征的出现频率作为特征权重。
[0059]
步骤212、不同用户在微博中表达的情感存在着差异,根据采集的数据可以看出女性用户使用情绪词的数量以及表达正向情绪的频率都高于男性用户,且女性比男性表达某种情感更加强烈。因此,本实施例使用大连理工大学的情感词汇本体库和情感词典统计用户微博文本中使用的情感词种类个数以及乐、好、哀、怒、惧、恶、惊七类情感每类情感词的个数作为特征,并把七类情感词分为积极情感和负面情感两大类,按照下列公式计算微博
文本的情感词多样性。
[0060]
ttr=v/n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1);
[0061][0062][0063]
其中,v和n分别代表一个用户微博文本中出现的情绪词种类个数和情绪词总个数,x.aggvalue表示某类情感词相对频率,xwords表示文本中某类情感词的个数,awords表示微博文本单词总长度,postoallratio代表文本中积极情绪与所有情绪的比率,pos.aggvalue为积极情绪种类个数;neg.aggvalue为所有情绪词的个数;pos.aggvalue和neg.aggvalue均由公式(2)给出。
[0064]
本实施例中采用的单个用户的文本特征如表1所示。其中,文本词特征指的是利用信息增益的特征选择方法计算文本中每个一元词的ig值,ig值反映了一个特征对整个分类的重要程度,词特征ig值越大表示这个词特征越重要,本实施例选取ig值最高的前1000个一元词作为文本词特征。
[0065]
表1单个用户文本特征
[0066][0067]
其中,一元词就是对文本分词后经过筛选留下的的每个词语。
[0068]
步骤22、个人数据的表情符号特征
[0069]
计算数据中不同性别用户中使用频率前十的表情符号,如图4所示,可以发现女性用户和男性用户在使用表情符号的喜好上有所不同,男性用户更喜欢使用“奸笑”和“得意”等表情符号,女性用户喜欢在微博中使用“玫瑰”和“示爱”等表情符号。因此,通过不同性别用户使用表情符号的差异可以用来对未知用户个性化预测,以便进行智能营销,本实施例计算每个表情符号的使用频率作为特征识别用户性别。
[0070]
从用户微博所表达的情感方面考虑,表情符号能生动形象地表达用户的情绪,用户在表达自己积极的情绪时,往往使用“爱心”和“赞”等表示积极意义的表情符号。目前学界普遍将表情符号情绪划分为正面(高兴、喜爱、惊讶)、负面(悲伤、愤怒、恐惧、厌恶)、中性和其他情绪,如图5所示。
[0071]
本实施例统计了单个用户数据中不同性别用户每类情感的表情符号使用数量,如表2所示,可以看出女性用户比男性用户使用积极表情符号数量多,男性用户使用消极、中性和其他三类表情符号的数量比女性用户多。图1(a) 表明男性用户使用的表情符号中积极表情占58.5%,消极表情、中性表情和其他表情分别占了26.2%、8.6%和6.7%,图1(b)表明女性用户使用积极表情占比达到81.1%,远远超过其他三类表情的使用率。因此,本实施例计算每个用户微博中使用的表情符号种类个数以及积极、消极、中性、其他四类表情每类表情符号的个数作为特征。根据文本情感词丰富性的计算公式,计算 ttr.emoji、x.emojiaggvalue表示表情符号情感丰富性,计算公式如下所示:
[0072]
ttr.emoji=vemoji/nemoji
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4);
[0073][0074]
其中,vemoji和nemoji分别代表一个用户微博中出现表情符号种类个数和表情符号总个数,xemojis表示微博中某类表情符号的个数,awemojis表示微博中使用的表情符号总个数,x.emojiaggvalue表示某类表情符号相对频率。
[0075]
表2不同性别用户表情符号使用情况
[0076]
性别积极表情消极表情中性表情其他表情男119782537411752713733女24884237713135616738
[0077] 本实施例采用的单个用户的表情符号特征如表3所示。其中,表情词特征指的是利用信息增益的特征选择方法计算微博中每个表情符号的ig值,选取 ig值最高的前100个表情符号作为表情词特征。
[0078]
表3单个用户表情符号特征
[0079][0080]
步骤23、交互特征提取
[0081]
由于用户在社交网络中不是单个存在的,交互是社交最本质的核心。因此,微博提供了转发、评论和@等机制让用户之间进行交流沟通。多个用户在交互时会产生交互文本,这些交互文本会提供一些重要信息来对用户进行个性化预测。例如,一名女性用户说:“周末快乐,准备出去看电影了”,一名男性用户评论:“一起去呀,美女”。仅通过单个用户微博并不容易判断发博用户的性别,而通过评论中的“美女”则可以判断出发博用户性别为女性。因此,本实施例将提取交互文本的词特征对用户个性化预测的依据。
[0082]
多用户的交互文本形成了简短的对话,f-measure特征已经被证实可以应用于区分两性在上下文表达中的差异。因此,在交互中对男性用户和女性用户具有较好的区分度,本实施例将f-measure特征加入交互特征空间。该特征可以根据如下公式来获得:
[0083][0084]
其中,freq.noun、freq.adj、freq.prep、freq.art、freq.pron、freq.verb、freq.adv、 freq.int分别表示文本中名词、形容词、介词、冠词、代词、动词、副词和感叹词的频率。
[0085]
表情符号是用户交互中常用的符号,对于人际交流有重要的作用。研究表明,用户与不同性别的用户交互中使用的表情符号存在差异。例如,男性用户在交互时经常使用“哈士奇”和“得意”等表情符号,而女性用户在交互时更喜欢使用“ok”和“抱拳”等表情符号。此外,评论用户的性别也是帮助个性化预测的重要信息,为了更好地挖掘不同性别用户交互中表情符号使用的差异,提高用户个性化预测的性能,本实施例将提取用户交互信息中的表情符号和评论用户的性别进行组合作为特征来识别用户性别。图6给出了提取表情符号和性别进行组合作为特征的例子。
[0086]
本实施例采用的多用户之间的交互特征如表4所示。交互文本特征指的是利用信息增益的特征选择方法计算交互文本中每个一元词的ig值,选取ig值最高的前1000个一元词作为交互文本特征,表情符号 性别特征指的是利用信息增益的特征选择方法计算每个表情符号与性别组合的ig值,选取ig值最高的前100个组合作为表情符号 性别特征。
[0087]
表4多用户交互特征
[0088][0089][0090]
其中,ig值是信息增益的简称;信息增益(kullback
–
leiblerdivergence) 又称informationdivergence,informationgain,relativeentropy或者klic。
[0091]
在概率论和信息论中,信息增益是非对称的,用以度量两种概率分布p 和q的差异。信息增益描述了当使用q进行编码时,再使用p进行编码的差异。通常p代表样本或观察值的分布,也有可能是精确计算的理论分布。q 代表一种理论,模型,描述或者对p的近似。
[0092]
本实施例中的ig值就是计算得到的每个词的信息增益值,一个词的ig 值越大代表这个值对用户个性化预测作用越大。
[0093]
ig值的计算公式为:
[0094][0095]
其中,x指的是随机变量,p(x)表示随机变量x取xi的概率;
[0096][0097]
信息增益通过信息熵减去条件熵来计算,它的概念是在一个条件下,某个变量不确定性减少的程度。信息增益的计算公式如下:
[0098]
ig(x;y)=h(y)-h(y|x)
ꢀꢀꢀꢀꢀꢀ
(9);
[0099]
其中,h(y)由公式(7)给出,h(y|x)由公式(8)给出。
[0100]
步骤3、训练预测模型
[0101]
从筛选后的数据中,选取数据的80%为训练数据集,20%为测试数据集,然后基于xgboost算法训练模型,通过训练的模型在测试集进行个性化预测。
[0102]
其中,提取到特征后会得到一个表,每一行代表一个用户,每一列代表一个特征,
这是训练特征集,训练结果集表是每一行为一个用户,列为个性化结果。将这两个表放入到xgboost分类模型里进行自动训练。
[0103]
测试特征集表形式跟训练特征集一样,将测试特征集放入到分类模型跑出一个预测结果,用预测结果与测试结果集中的用户个性化结果比较得到准确率。
[0104]
步骤4、用户个性化预测
[0105]
使用xgboost算法对中文微博用户进行个性化预测,xgboost在传统的 gbdt基础上加以改进,具有可容错、可移植、性能好等优点。采用jieba分词工具对文本进行分词处理,并根据停用词典去除文本中的停用词,使用正则表达式对微博中的表情符号进行提取。然后基于xgboost算法训练模型,通过训练的模型在测试集进行用户个性化预测。实验结果的评测指标选用准确率、精准率、召回率、f-score。
[0106]
基于单个用户文本和表情符号特征的预测结果分析
[0107]
表5中给出了使用文本特征和表情符号特征个性化预测的结果,可以看出文本词特征的准确率为81.0%,而文本情感特征的准确率为77.1%,比文本词特征低了3.9个百分点,一方面因为情感特征的维数比较少,情感词典无法包含所有的情感词。另一方面中文有其自己的特殊性,不同情感词在不同的中文语境里有不同的含义,进而影响了预测的准确率。文本的情感特征 词特征的准确率达到82.1%,比只使用文本词特征提高了1.1个百分点。
[0108]
表情符号情感特征 词特征的准确率达到了79.7%,仅比使用文本特征低了2.4个百分点,说明根据表情符号特征进行个性化预测是一种有效的方法。在融合表情符号特征后,用户个性化预测准确率达到了85.5%,比只使用文本特征提升了3.4个百分点,精确率、召回率、f-score三个评价指标均有上升,精确率上升了3个百分点,召回率和f-score分别上升了3.3和3.4个百分点,这说明表情符号特征对用户个性化预测性能是有较大帮助的。
[0109]
表5单个用户数据融合文本和表情符号特征的用户个性化预测效果
[0110][0111]
[0112]
基于多用户交互信息的个性化预测结果分析
[0113]
表6中给出了通过交互特征进行个性化预测的结果,可以看出利用交互文本特征对用户个性化预测的准确率为65.9%,交互表情符号特征对用户个性化预测准确率为69.5%,交互文本特征 交互情感特征对用户个性化预测的准确率为72.2%,用户个性化预测结果比单独使用交互文本特征或者交互情感特征好,再次证明融合表情符号特征能提高用户个性化预测的准确性。在单个用户特征的基础上,融合交互特征后用户个性化预测的各项评价指标都有提高,准确率提高了4.2个百分点,说明融合多用户的交互特征能有效提升用户个性化预测的准确性。
[0114]
表6交互数据融合交互特征的用户个性化预测效果
[0115][0116][0117]
为了进一步探究文本和表情符号特征在个性化预测中的具体作用,通过 t-sne特征降维方法将文本词特征和表情词特征分别降到3维,将文本情感特征和表情情感特征分别降到2维,然后对各类别特征进行特征相关性分析和特征重要性分析,结果如图2(a)-图2(b)所示。
[0118]
图2(a)为各类别特征相关性分析结果,可以发现文本词特征text_freq2和表情符号词特征emoji_freq1之间具有一定的相关性,主要由于某些文本词常和固定表情符号连用。表情符号词特征emoji_freq2和表情符号情感特征 emoji_emotion1之间也有一定的相关性,是因为用户通常使用表情符号来表达自己的某种情感。总的来说,文本特征和表情符号特征之间相关性较小,说明这些特征之间几乎是相互独立的。
[0119]
图2(b)为各类别特征的重要性分数排序结果,横坐标为特征的重要性分数,可以发现文本词特征得分最多,对用户个性化预测影响力最大,主要是由于文本词特征维度较大,对用户个性化预测的效果最好。表情符号词特征和表情符号情感特征影响力相对较小,
主要是由于表情符号个数较少,导致不同性别用户使用某些表情符号的差异较小。此外,文本情感特征的影响力最小,主要是因为某些词语在不同语境中表达不同的情感,导致与情感词典中标注的情感不同,从而降低用户个性化预测的效果。
[0120]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本实施例中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本实施例所示的这些实施例,而是要符合与本实施例所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。