1.本发明涉及双录质检技术领域,尤其涉一种智能双录质检方法和系统。
背景技术:
2.在金融行业中,在购买一款金融理财产品的时候,为了更准确的让投资人知晓这款金融理财产品的风险,会要求投资人做一个风险揭示双录,双录包含录制音频和录制视频,录制音频内容为用户朗读预设的文字,录制视频内容为人物上半身包含头部。为了保证双录数据的有效性及可用性,需要对双录数据进行质检。
3.现有技术主要采用人工质检,这种方式不仅效率低,而且十分浪费人力资源,人力质检的强主观性也导致检测结果存在较大偏差。
技术实现要素:
4.鉴于上述的分析,本发明实施例旨在提供一种智能双录质检方法和系统。用以解决现有双录质检采用人工质检效率低并且结果不准确的问题。
5.一方面,本发明实施例提供了一种智能双录质检方法,包括以下步骤:
6.实时获取每段双录视频流和对应的体征数据;
7.对每段双录视频流进行解码获得视频数据和音频数据;基于所述视频数据进行人脸识别检测,得到人脸识别检测结果;基于所述视频数据、音频数据和所述体征数据进行胁迫检测,得到胁迫检测分数;
8.将所有视频流的音频文件拼接为双录音频文件,对所述双录音频文件进行语音识别得到语音文本,基于所述语音文本进行话术检测得到话术检测分数;
9.基于人脸识别检测结果、胁迫检测分数,以及所述话术检测分数得到双录质检结果。
10.基于上述技术方案的进一步改进,
11.基于所述视频数据进行人脸识别检测,得到人脸识别检测结果,包括:基于第一段视频流的视频数据进行人脸识别检测,得到人脸识别检测结果;
12.基于所述视频数据、音频数据和所述体征数据进行胁迫检测,得到胁迫检测分数,包括:
13.基于第二段至最后一段视频流的视频数据、音频数据和对应的体征数据进行胁迫检测,得到胁迫检测分数。
14.进一步地,所述基于人脸识别检测结果、胁迫检测分数,以及所述话术检测分数到双录质检结果,包括:
15.当人脸识别检测结果为不通过,则双录质检结果为不通过;
16.当人脸识别检测结果为通过,则根据公式z=α1x4 β1x5计算双录质检分数;其中,x4表示胁迫检测分数,α1表示胁迫检测的权重,x5表示话术检测分数,β1表示话术检测的权重;
17.若所述双录质检分数低于第一阈值,则双录质检不通过;否则双录质检通过。
18.进一步地,基于第一段视频流的视频数据进行人脸识别检测,得到人脸识别检测结果,包括:
19.提取所述视频数据中的多张关键帧图像;
20.对于每张关键帧图像,基于预设的人脸识别模型在所述关键帧图像中提取人脸图像;根据人脸图像在所述关键帧图像中的位置,采用相似度匹配算法对人脸图像和目标人脸图像进行相似度匹配,得到所述关键帧图像的相似度匹配结果;根据所述多张关键帧的相似度匹配结果得到人脸识别检测结果。
21.进一步地,根据人脸图像在所述关键帧图像中的位置,采用相似度匹配算法对人脸图像和目标人脸图像进行相似度匹配,得到所述关键帧图像的相似度匹配结果;根据所述多张关键帧的相似度匹配结果得到人脸识别检测结果,包括:
22.在每张关键帧图像中,计算每张人脸的中心位置与所述关键帧图像的中心位置的距离;
23.从最靠近关键帧图像中心位置的人脸图像开始到最远离关键帧图像中心位置的人脸图像为止,依次采用相似度匹配算法与目标人脸图像进行相似度匹配,若当前人脸图像与目标人脸图像相似,则匹配结束,该关键帧图像为合规图像;否则继续的提取下一张人脸图像与目标人脸图像进行相似度匹配;
24.若当前关键帧图像中不存在与目标人脸图像的相似的人脸图像,则判断该关键帧图像不合规;
25.根据合规关键帧图像的数量与所述关键帧图像总数量的比值,得到人脸识别检测结果。
26.进一步地,基于第二段至最后一段视频流的视频数据、音频数据和对应的体征数据进行胁迫检测,得到胁迫检测分数,包括:
27.对于第二段至最后一段视频流的每段视频流,基于所述视频数据、音频数据和对应的体征数据进行胁迫检测,得到每段视频流的胁迫概率;
28.对第二段至最后一段视频流的每段视频流的胁迫概率取平均得到平均胁迫概率;基于平均胁迫概率,得到胁迫检测分数。
29.进一步地,对于第二段至最后一段视频流的每段视频流,基于所述视频数据、音频数据和对应的体征数据进行胁迫检测,得到每段视频流的胁迫概率,包括:
30.在所述视频数据中提取目标用户人脸图像,将所述目标用户人脸图像输入训练好的图像情绪识别模型中进行情绪识别,得到图像情绪识别结果;
31.对所述音频数据进行特征提取,将提取的特征输入训练好的语音情绪识别模型进行情绪识别,得到语音情绪识别结果;
32.基于所述图像情绪识别结果、语音情绪识别结果和所述体征数据得到每段视频流的胁迫概率。
33.进一步地,基于所述图像情绪识别结果、语音情绪识别结果和所述体征数据得到每段视频流的胁迫概率,包括:
34.根据所述图像情绪识别结果、语音情绪识别结果以及每种情绪对应的胁迫概率,分别计算所述图像情绪识别结果和语音情绪识别结果对应的胁迫概率;
35.所述体征数据包括心跳数据,根据平均心跳得到体征数据的胁迫概率;
36.根据公式y=α2x1 β2x2 γ2x3计算得到每段视频流的胁迫概率,其中x1表示图像情绪识别结果对应的胁迫概率,x2表示语音情绪识别结果对应的胁迫概率,x3表示体征数据对应的胁迫概率,α2表示图像情绪识别的权重,β2表示语音情绪识别的权重,γ2表示体征的权重。
37.进一步地,基于所述语音文本进行话术检测得到该段视频流的话术检测结果,包括:
38.获取话术关键词,所述话术关键词包括必用关键词和禁用关键词,采用正则表达式检测所述必用关键是否在所述语音文本中,以及所述禁用关键词是否在所述语音文本中,根据以下计算得到话术检测分数:
39.其中α3表示必用关键词的权重,β3表示禁用关键词的权重,n1表示所述语音文本包含的必用关键词的数量,n1表示话术关键词包含的必用关键词的数量;n2表示所述语音文本包含的禁用关键词的数量,n2表示话术关键词包含的禁用关键词的数量。
40.与现有技术相比,本发明通过采用机器自动进行双录质检,提高了工作效率,节约了人力成本,并且检测结果更客观,避免出现因人工检测漏检或强主观性而出现偏差。当视频图像中有多人张人脸图像时通过根据人脸图像在关键帧图像的位置进行检测,提高了检测效率。通过结合胁迫检测和话术检测,使质检更全面。
41.另一方面,本发明实施例提供了一种智能双录质检系统,包括以下模块:
42.数据获取模块,用于实时获取每段双录视频流和对应的体征数据;
43.人脸识别和胁迫检测模块,用于对每段双录视频流进行解码获得视频数据和音频数据;基于所述视频数据进行人脸识别检测,得到人脸识别检测结果;基于所述视频数据、音频数据和所述体征数据进行胁迫检测,得到胁迫检测分数;
44.话术检测模块,用于将所有视频流的音频文件拼接为双录音频文件,对所述双录音频文件进行语音识别得到语音文本,基于所述语音文本进行话术检测得到话术检测分数;
45.质检结果获取模块,用于基于人脸识别检测结果、胁迫检测分数,以及所述话术检测分数得到双录质检结果。
46.本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
47.附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
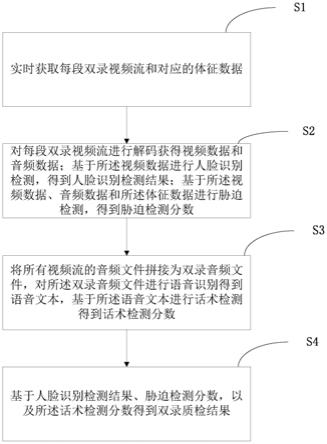
48.图1为本发明实施例智能双录质检方法的流程图;
49.图2为本发明实施例智能双录质检系统的框图。
具体实施方式
50.下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
51.本发明的一个具体实施例,公开了一种智能双录质检方法,如图1所示,包括以下步骤:
52.s1、实时获取每段双录视频流和对应的体征数据;
53.s2、对每段双录视频流进行解码获得视频数据和音频数据;基于所述视频数据进行人脸识别检测,得到人脸识别检测结果;基于所述视频数据、音频数据和所述体征数据进行胁迫检测,得到胁迫检测分数;
54.s3、将所有视频流的音频文件拼接为双录音频文件,对所述双录音频文件进行语音识别得到语音文本,基于所述语音文本进行话术检测得到话术检测分数;
55.s4、基于人脸识别检测结果、胁迫检测分数,以及所述话术检测分数得到双录质检结果。
56.通过进行人脸识别检测、胁迫检测和话术检测,使得质检更全面,采用机器检测避免了人工检测的效率低及检测结果不准确的问题,可以快速而准确的进行双录质检。
57.具体的,步骤s1中,当用户端开始进行录制时,服务器端实时获取用户端传输的视频流数据。实施时,录制也可采用直播的形式进行,用户端将录制的视频流发送至直播服务器,服务端通过拉流的形式从直播服务器中拉流获取视频流数据,实时获取固定大小的视频流段,以及当前视频流段对应的体征数据。
58.实施时,体征数据可通过手环等设备获取。实施时,体征数据包括心跳数据。
59.获取视频流后,对视频流进行解码获得视频数据和音频数据。实施时,视频流通常采用二进制格式存储,通过解析二进制数据获得数据流的相关信息,根据不同的数据封装格式进行解复用,分别获得h.264视频数据和aac音频数据,使用硬解码(系统的api)或软解码(ffmpeg)来解压音视频数据;经过解码后得到原始的视频数据(yuv)和音频数据(aac)。具体过程为现有技术,此处不再赘述。
60.具体的,步骤s2中,基于第一段视频流的视频数据进行人脸识别检测,得到人脸识别检测结果;基于第二段至最后一段视频流的视频数据、音频数据和对应的体征数据进行胁迫检测,得到胁迫检测分数。
61.具体的,步骤s2基于第一段视频流的视频数据进行人脸识别检测,得到人脸识别检测结果,包括s21~s22:
62.s21、提取所述视频数据中的多张关键帧图像。
63.实施时,由于i帧,即intra-coded picture(帧内编码图像帧),所占信息量大,解码时仅有i帧即可完整重构图像,因此可以提取i帧关键帧,得到多张关键帧图像。
64.s22、对于每张关键帧图像,基于预设的人脸识别模型在所述关键帧图像中提取人脸图像;根据人脸图像在所述关键帧图像中的位置,采用相似度匹配算法对人脸图像和目标人脸图像进行相似度匹配,得到所述关键帧图像的相似度匹配结果;根据所述多张关键帧的相似度匹配结果得到人脸识别检测结果。
65.实施时,可采用现有人脸识别技术在关键帧中提取人脸图像。双录视频中可能会有多张人脸,通常目标用户的人脸会在画面的中心位置,因此,根据人脸图像在关键帧图像
中的位置,依次与目标人脸图像进行相似度匹配,从而提高检测的效率。实施时,目标人脸图像可以是目标用户的身份证图像。通过关键帧中的人脸图像与目标人脸图像进行相似度匹配,从而检测目标用户的身份是否合法。
66.具体的,步骤s22,包括步骤s221~s224:
67.s221、在每张关键帧图像中,计算每张人脸的中心位置与所述关键帧图像的中心位置的距离。
68.通过现有的人脸识别技术提取人脸图像后,获得人脸图像在关键帧图像的位置信息,计算每张关键帧图像中每张人脸图像的中心位置与关键帧图像的中心位置的距离,用于判断哪张人脸图像最接近关键帧图像的中心,越靠近中心,其为目标用户的概率越大。
69.s222、从最靠近关键帧图像中心位置的人脸图像开始到最远离关键帧图像中心位置的人脸图像为止,依次采用相似度匹配算法与目标人脸图像进行相似度匹配,若当前人脸图像与目标人脸图像相似,则匹配结束,该关键帧图像为合规图像;否则继续提取下一张人脸图像与目标人脸图像进行相似度匹配;
70.具体的,在一张关键帧图像中,从最靠近关键帧图像中心到最远离关键帧图像中心,依次对每张人脸图像与目标人脸图像进行相似度匹配,若相似,则匹配结束,即在该关键帧图像中检测到目标用户,不再继续进行匹配,否则继续匹配直到找到目标用户或者匹配完该关键帧图像中的所有人脸图像。若在关键帧图像中匹配到目标用户,则该张关键帧图像合规,否则该张关键帧不合规。
71.实施时,进行人脸相似度匹配时,提取人脸的关键位置,例如眉毛、眼睛、鼻子、嘴巴、脸颊等信息,对人脸图像进行特征点定位,得到人脸特征向量数据。通过特征提取算法提取人脸特征向量,人脸特征提取算法可以采用主成分分析算法、局部纹理特征算法、支持向量机算法和gabor滤波特征提取算法等中任意一种。利用特征提取算法将人脸图像中各像素点的灰度值转换成人脸特征值,从而形成所述人脸特征向量。
72.可采用欧式距离或向量余弦距离进行相似度计算。
73.欧氏距离法的相似度计算公式为:
[0074][0075]
其中,x为关键帧图像中人脸图像的特征向量,y为目标人脸图像的特征向量,n为向量空间维度。欧氏距离计算的是空间中两个点的绝对距离,距离越小,特征越相似。实施时,可设置具体的阈值,用于判断是否相似,当计算结果小于该阈值时判断为相似人脸,否则为不相似人脸。
[0076]
余弦距离法的相似度计算公式为:
[0077][0078]
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
[0079]
当两个向量直接的夹角θ趋向0时,两个向量越接近,差异就越小。此时cosθ=1,即越接近1值时,说明人脸越相似。实施时,可设置具体的阈值,例如阈值取0.9,用于判断是否相似,当计算结果大于该阈值时判断为相似人脸,否则为不相似人脸。
[0080]
s223、若当前关键帧图像中不存在与目标人脸图像的相似的人脸图像,则判断该关键帧图像不合规;
[0081]
s224、根据合规关键帧图像的数量与所述关键帧图像总数量的比值,得到人脸识别检测结果。
[0082]
根据合规关键帧图像的数量与该段视频流中关键帧图像的总数量的比值,确定人脸识别检测结果。实施时,例如比值大于预设的阈值时,判断人脸识别检测结果通过,否则判断人脸识别检测不通过。示例性的,阈值设置为0.9。
[0083]
通过仅对第一段视频流进行人脸识别,从而提高质检效率,如第一段视频流的人脸识别检测结果不通过,即用户身份不合法,则不必进行后续的检测,则直接得到质检不通过结果。只有当人脸识别检测即用户身份检测通过后才进行后续的胁迫和话术检测。
[0084]
具体的,步骤s2基于第二段至最后一段视频流的视频数据、音频数据和对应的体征数据进行胁迫检测,得到胁迫检测分数,包括:
[0085]
s23、对于第二段至最后一段视频流的每段视频流,基于所述视频数据、音频数据和对应的体征数据进行胁迫检测,得到每段视频流的胁迫概率;
[0086]
s24、对第二段至最后一段视频流的每段视频流的胁迫概率取平均得到平均胁迫概率;基于平均胁迫概率,得到胁迫检测分数。
[0087]
通过对每段视频流进行胁迫检测得到每段视频流的胁迫概率,根据平均胁迫概率得到整体的胁迫检测分数,从而使胁迫检测更加准确。
[0088]
具体的,步骤s23包括:
[0089]
s231、在所述视频数据中提取目标用户人脸图像,将所述目标用户人脸图像输入训练好的图像情绪识别模型中进行情绪识别,得到图像情绪识别结果。
[0090]
目标用户人脸图像为步骤s22中与目标人脸图像相似的人脸图像。
[0091]
具体的,情绪类型包括高兴、惊讶、中性、悲伤、厌恶和恐惧等情绪。
[0092]
具体的,图像情绪识别模型可采用深度神经网络模型,例如卷积神经网络、lstm等,预先通过足够大的带情绪标记的图像数据集对图像情绪识别模型进行训练,得到训练好的图像情绪识别模型。为了使模型更准确,每种情绪类型在训练集中的数量应相同。
[0093]
在关键帧图像中提取目标用户的人脸图像,将人脸图像输入训练好图像情绪识别模型中,得到该人脸图像对应的情绪分类结果。
[0094]
s232、对所述音频数据进行特征提取,将提取的特征输入训练好的语音情绪识别模型进行情绪识别,得到语音情绪识别结果。
[0095]
具体的,对所述音频数据进行特征提取包括韵律特征、音质特征、频谱特征和声纹特征。
[0096]
其中,韵律特征,又叫超音质特征或者超音段特征,是指语音中除音质特征之外的音高、音长和音强方面的变化,具体包括基音频率、发音持续时间、发音振幅和发音语速。
[0097]
音质特征包括共振峰f1-f3、频带能量分布、谐波信噪比和短时能量抖动。
[0098]
频谱特征,又称振动谱特征,是指将复杂振荡分解为振幅不同和频率不同的谐振
荡,这些谐振荡的幅值按频率排列形成的图形。频谱特征与韵律特征和音质特征相融合,以提高特征参数的抗噪声效果。实施时,采用梅尔频率倒谱系数。
[0099]
声纹特征(即i-vector特征)是与说话人相关的特征,其与其他语音特征结合,在语音识别过程中可更有效提高识别的准确率。
[0100]
提取上述语音特征后,将特征数据输入训练好的语音情绪识别模型得到语音情绪识别结果。
[0101]
具体的,语音情绪识别模型可采用深度神经网络模型,例如卷积神经网络、lstm等,预先通过足够大的带情绪标记的语音数据集,提取语音特征,对图像情绪识别模型进行训练,得到训练好的图像情绪识别模型。为了使模型更准确,每种情绪类型在训练集中的数量应相同。
[0102]
通过采用情绪识别模型对语音特征进行智能识别,以获取情绪识别结果,其识别过程处理效率高,可实现对说话人对应的待测语音数据进行及时且全面抽检,无需人工干预,有利于节省人工成本。
[0103]
s233、基于所述图像情绪识别结果、语音情绪识别结果和所述体征数据得到每段视频流的胁迫概率。
[0104]
具体的,步骤s233包括:
[0105]
s2331、根据所述图像情绪识别结果、语音情绪识别结果以及每种情绪对应的胁迫概率,分别计算所述图像情绪识别结果和语音情绪识别结果对应的胁迫概率;
[0106]
例如,图像情绪识别结果:高兴、惊讶、中性、悲伤、厌恶和恐惧分别为0.6、0.02、0.1、0.2、0.03、0.05;即该图像的情绪识别结果为高兴的概率为0.6,惊讶的概率为0.02、中性的概率为0.1、悲伤的概率为0.2、厌恶的概率为0.03、恐惧的概率为0.05。
[0107]
语音情绪识别结果:高兴、惊讶、中性、悲伤、厌恶和恐惧分别为0.5、0.03、0.1、0.2、0.05、0.03,即该音频数据的情绪识别结果为高兴的概率为0.5,惊讶的概率为0.03、中性的概率为0.1、悲伤的概率为0.2、厌恶的概率为0.05、恐惧的概率为0.03。
[0108]
例如,高兴对应的胁迫概率为0、惊讶对应的胁迫概率为0.2、中性对应的胁迫概率为0.01、悲伤对应的胁迫概率为0.3、厌恶对应的胁迫概率为0.2、恐惧对应的胁迫概率为0.9等,根据各类情绪对应的胁迫概率,计算图像情绪识别结果对应的胁迫概率为:
[0109]
0.116=0.6
×
0 0.02
×
0.2 0.1
×
0.01 0.2
×
0.3 0.03
×
0.2 0.05
×
0.9
[0110]
语音情绪识别结果对应的胁迫概率为:
[0111]
0.104=0.5
×
0 0.03
×
0.2 0.1
×
0.01 0.2
×
0.3 0.05
×
0.2 0.03
×
0.9。
[0112]
s2332、所述体征数据包括心跳数据,根据平均心跳得到体征数据的胁迫概率;
[0113]
具体的,根据不同的平均心跳等级确定对应的胁迫概率,例如表1所示的等级。
[0114]
等级心跳次数胁迫概率160及以下0260~800.1380~1000.24100~1200.35120及以上0.6
[0115]
表1 平均心跳对应的胁迫概率
[0116]
s2333、根据公式y=α2x1 β2x2 γ2x3计算得到每段视频流的胁迫概率,其中x1表示图像情绪识别结果对应的胁迫概率,x2表示语音情绪识别结果对应的胁迫概率,x3表示体征数据对应的胁迫概率,α2表示图像情绪识别的权重,β2表示语音情绪识别的权重,γ2表示体征的权重。
[0117]
实施时,体征数据的权重比图像情绪识别的权重和语音情绪识别的权重低。
[0118]
获得每段视频流的胁迫概率值后,通过取平均得到平均胁迫概率;基于平均胁迫概率,得到胁迫检测分数。
[0119]
胁迫概率和胁迫检测分数的对应关系可如表2所示。
[0120]
等级胁迫概率分数10-0.210020.2~0.48030.4~0.66040.6~0.84050.8及以上20
[0121]
表2 胁迫概率和胁迫检测分数的对应关系
[0122]
获得所有视频流后,将所有视频流的音频文件拼接为双录音频文件,对所述双录音频文件进行语音识别得到语音文本,基于所述语音文本进行话术检测得到话术检测分数。
[0123]
具体的,步骤s3中基于所述语音文本进行话术检测得到该段视频流的话术检测结果,包括:
[0124]
获取话术关键词,所述话术关键词包括必用关键词和禁用关键词,采用正则表达式检测所述必用关键是否在所述语音文本中,以及所述禁用关键词是否在所述语音文本中,根据以下计算得到话术检测分数:
[0125]
其中α3表示必用关键词的权重,β3表示禁用关键词的权重,n1表示所述语音文本包含的必用关键词的数量,n1表示话术关键词包含的必用关键词的数量;n2表示所述语音文本包含的禁用关键词的数量,n2表示话术关键词包含的禁用关键词的数量。
[0126]
例如必用关键词总数量为20,语音文本中检测到18个,禁用关键词总数量为50,语音文本中检测到1个,必用关键词和禁用关键词的权重均为0.5,则得到话术检测分数为0.94,转为百分制94分。
[0127]
得到胁迫检测分数和话术检测分数后,计算整体分数,得到双录质检结果。
[0128]
具体的,则根据公式z=α1x4 β1x5计算双录质检分数;其中,x4表示胁迫检测分数,α1表示胁迫检测的权重,x5表示话术检测分数,β1表示话术检测的权重;
[0129]
若所述双录质检分数低于第一阈值,则双录质检不通过;否则双录质检通过。
[0130]
实施时,第一阈值可更具实际检测精度确定,例如取80。
[0131]
本发明的一个具体实施例,公开了一种智能双录质检系统,如图2所示,包括以下模块:
[0132]
数据获取模块,用于实时获取每段双录视频流和对应的体征数据;
[0133]
人脸识别和胁迫检测模块,用于对每段双录视频流进行解码获得视频数据和音频数据;基于所述视频数据进行人脸识别检测,得到人脸识别检测结果;基于所述视频数据、音频数据和所述体征数据进行胁迫检测,得到胁迫检测分数;
[0134]
话术检测模块,用于将所有视频流的音频文件拼接为双录音频文件,对所述双录音频文件进行语音识别得到语音文本,基于所述语音文本进行话术检测得到话术检测分数;
[0135]
质检结果获取模块,用于基于人脸识别检测结果、胁迫检测分数,以及所述话术检测分数得到双录质检结果。
[0136]
上述方法实施例和系统实施例,基于相同的原理,其相关之处可相互借鉴,且能达到相同的技术效果。具体实施过程参见前述实施例,此处不再赘述。
[0137]
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
[0138]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。