1.本发明属于计算机存储系统技术领域,具体涉及在分布式键值存储系统(distributed kv stores)中,基于主-从副本数据解耦来构建差异化的副本数据存储机制,并在此基础上设计有序度可动态调整的副本数据管理方案,实现高性能和读写性能可调整的分布式键值存储方法。
背景技术:
2.为了适应海量非结构化数据的存储与访问需求,并克服传统关系型数据库、文件存储在可扩展性与性能等方面的不足,键值存储(简称为kv存储)系统提供了很好的解决方案,比如谷歌公司的leveldb、脸书公司的rocksdb等单机键值存储系统,以及为支持大规模数据存储而衍生出的分布式键值存储系统,如pingcap公司的tikv,亚马逊公司的dynamodb,以及阿帕奇基金会的cassandra。上述主流键值存储系统均采用日志结构合并树(lsm-tree)来管理键值数据(key-value pairs),该架构将磁盘上的数据组织成多层有序形式,数据在内存排序后追加写入,优点是可以将随机写转换为顺序写,从而获得高效的写入性能,缺点是需要对相邻层间的数据做频繁的合并操作,由此造成严重的读写放大问题。
3.另一方面,为了保证数据的高可靠并提供数据容错,多副本容错机制被广泛应用在分布式键值存储系统中,即每个键值数据被复制成多份并存储在多个节点(当一个节点的数据丢失后,可以从其他节点进行数据恢复)。然而,现有分布式键值存储系统的多副本管理方案并未考虑日志结构合并树(lsm-tree)架构自身存在的读写放大问题,简单地在每个节点上采用一个日志结构合并树(lsm-tree)对所有副本数据进行统一存储。
4.因此,多副本机制下日志结构合并树(lsm-tree)中存储的数据量成倍增长,且在执行读写操作时不同副本数据之间会相互干扰,从而进一步加剧日志结构合并树(lsm-tree)的读写放大问题。
技术实现要素:
5.本发明是为了解决上述现有技术存在的不足之处,提出一种基于主从副本数据解耦的高性能分布式键值存储方法,以期能提升分布式键值系统的整体性能,并提供可根据应用的性能需求动态调整读写性能的机制,从而解决现有分布式键值存储系统中统一的多副本数据管理方案加剧系统读写放大的关键问题。
6.本发明为达到上述发明目的,采用如下技术方案:
7.本发明一种基于主从副本数据解耦的高性能分布式键值存储方法的特点是应用于包含若干个节点的存储集群中,若任一节点第i次接收到键值数据,则对第i个键值数据进行解耦操作和差异化存储操作;
8.所述解耦操作包括:
9.对所接收到的第i个键值数据中的键进行哈希计算得到第i个哈希值,然后根据第i个哈希值和一致性哈希环计算得到所述第i个键值数据中的键所映射到的一个节点编号;
如果计算得到的节点编号等于当前接收到第i个键值数据的节点编号,则将所述第i个键值数据识别为主副本;否则,将所述第i个键值数据识别为从副本;
10.所述差异化存储操作包括:
11.若所述第i个键值数据为主副本,则将所述第i个键值数据写入节点的日志结构合并树中进行存储和管理;
12.若所述第i个键值数据为从副本,则将所述第i个键值数据写入一个两层日志架构中进行存储和管理。
13.本发明所述的高性能分布式键值存储方法的特点也在于,所述两层日志架构的写入步骤包括:
14.(i)两层日志架构接收到第i个键值数据时,判断i》nmax是否成立,若成立,则执行步骤(ii),否则,将第i个键值数据写入第一层全局日志中;
15.(ii)对于第一层全局日志中的nmax个键值数据,后台线程计算得到每个键值数据中的键所映射的节点编号;并根据不同的节点编号建立对应的本地日志,且在每个本地日志中均设置有若干个范围组;
16.(iii)分割nmax个键值数据:
17.a、定义变量j并初始化j=1;
18.b、对于第j个键值数据,后台线程计算得到第j个键值数据中的键所映射的节点编号为l,则将其映射到第l个本地日志;并判断在第l个本地日志中,第j个键值数据的键所属于的范围组;然后将第j个键值数据写入第l个本地日志中对应的范围组中;
19.c、将j 1赋值给j后,判断j》nmax是否成立,若成立,则表示将nmax个键值数据都分别写入不同本地日志的不同范围组中,并将每个范围组内所写入的若干个键值数据保存在一个文件内,以形成每个范围组所对应的有序段;否则,返回步骤b执行。
20.对两层日志架构中的键值数据按如下步骤进行有序度可调操作:
21.若所述高性能分布式键值存储方法应用于读密集型的存储系统中,则增加范围组内有序段间的合并操作,即当一个范围组内有序段的个数超过阈值δ1时,则将相应范围组内所有的有序段合并为一个有序段,使得范围组内有序段的个数维持在阈值δ1内;
22.若所述高性能分布式键值存储方法应用于写密集型的存储系统中,则减少范围组内有序段间的合并操作,即当一个范围组内有序段的个数超过δ2时,将相应范围组内所有的有序段合并为一个有序段,从而将范围组内有序段的个数维持在阈值δ2内;δ1<δ2。
23.对故障节点中的键值数据按如下步骤进行并行数据恢复操作:
24.(i)使用两个线程并行地从每个节点上的日志结构合并树和两层日志中读取数据,并根据读取的键值数据,计算每个键值数据的哈希值,并将其存储在梅克尔树的各个结点中,从而构建每个节点上的梅克尔树;
25.(ii)将故障节点上构建的梅克尔树分别与其他节点构建的梅克尔树依次进行比较,判断故障节点和其他梅克尔树在相同位置的结点的值是否相同;若相同,则表示相应结点所对应的键值数据未丢失,并结束流程,否则,表示相应结点所对应的键值数据已丢失;
26.(iii)在非故障节点上使用两个线程并行地从日志结构合并树和两层日志中读取丢失数据所在的结点上对应的键值数据作为恢复数据,并发送到故障节点;
27.(iv)所述故障节点收到所述恢复数据后,使用两个线程并行地向日志结构合并树
和两层日志中写入所述恢复数据。
28.与现有技术相比,本发明的有益技术效果体现在:
29.1、轻量级的主从副本数据解耦:本发明采用哈希计算并结合一致性哈希环来对主-从副本数据进行解耦操作,使得主从副本解耦操作是轻量级、低开销的,且不影响存储系统上层的数据分布机制及一致性协议。
30.2、主-从副本数据的差异化存储:本发明将解耦出的主副本采用日志结构合并树存储,将解耦出的从副本采用两层日志架构进行存储,从而有效地避免了执行读写操作时主从副本数据之间的相互干扰影响,克服了现有分布式键值存储系统中统一的多副本管理方案加剧系统读写放大的关键问题;并且两层日志架构设计也提升了从副本的写入和读取性能。
31.3、两层日志有序度可调:本发明设计了数据存储的有序度可调机制,可动态调整两层日志架构的有序程度,可以将两层日志调整为利于写或者利于读,实现了可根据应用的不同性能需求来调整两层日志的有序度,从而实现了不同场景下都能提升系统性能。
32.4、数据并行恢复:本发明在恢复丢失的数据时,使用多线程并行地从日志结构合并树和两层日志中读写数据,加速了数据恢复操作,从而缩短了数据恢复的时间。
33.综上所述,本发明通过提出轻量级的主-从副本数据解耦操作,主-从副本数据的差异化存储技术,有序度可调机制及数据并行恢复技术,较好地解决了分布式键值系统中统一多副本管理方案加剧系统读写放大的问题,极大地提升了分布式键值系统的整体读写性能,以及数据恢复性能,同时保证了系统的高可靠性。
附图说明
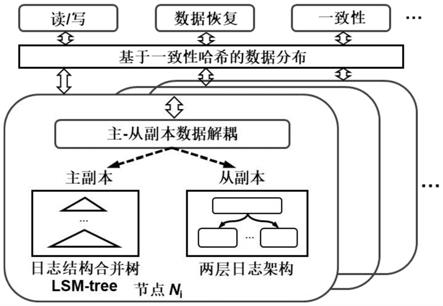
34.图1是本发明基于主从副本数据解耦的高性能分布式键值存储方法的整体架构图;
35.图2是本发明主从副本数据的解耦流程示意图;
36.图3是本发明两层日志架构的示意图;
37.图4是本发明本地日志中基于范围的数据分组示意图;
38.图5是本发明数据存储的有序度可调示意图;
39.图6是本发明数据并行恢复的示意图。
具体实施方式
40.在本实施例中,如图1所示,一种基于主从副本数据解耦的高性能分布式键值存储方法,包括主-从副本数据的解耦、主-从副本数据的差异化存储、存储的有序度调整和并行的数据恢复。本发明采用哈希计算并结合一致性哈希环来对主-从副本数据进行解耦,使得主从副本解耦操作是轻量级、低开销的,且不影响上层的数据分布机制及一致性协议;此外,本发明通过两层日志架构将从副本数据首先批量追加到第一层全局日志,然后后台线程将其分割到第二层的多个本地日志中,从而保证高效的从副本写入性能,以及良好的从副本读取和恢复性能;其次,本发明设计数据存储的有序度可调技术,可将两层日志调整为利于写或利于读,从而用户可根据不同的性能需求来调整两层日志的有序度,以在不同场景下都能提升键值存储系统的整体性能;最后,在恢复丢失数据时,本发明使用多线程并行
地从日志结构合并树和两层日志中读写数据,以加速数据恢复操作。下面针对每个操作具体展开说明。
41.本实施例中,该基于主从副本数据解耦的高性能分布式键值存储方法是应用于包含若干个节点的存储集群中,若任一节点第i次接收到键值数据,则对第i个键值数据进行解耦操作和差异化存储操作;
42.解耦操作包括:
43.对所接收到的第i个键值数据中的键进行哈希计算得到第i个哈希值,然后根据第i个哈希值和一致性哈希环计算得到第i个键值数据中的键所映射到的一个节点编号;如果计算得到的节点编号等于当前接收到第i个键值数据的节点编号,则将第i个键值数据识别为主副本;否则,将第i个键值数据识别为从副本;
44.图2给出了本实施例中主-从副本数据的解耦流程示意图。每个节点在区分接收到的键值数据是主副本还是从副本后,首先将键值数据写入对应的先写日志和内存缓存中,然后通知客户端该键值数据写入成功。当缓存存满时,则将其批量写入日志结构合并树或两层日志架构中。主-从副本数据的解耦操作是轻量级的,因为每个节点只需在i/o路径中执行一次额外的哈希计算。实验表明,解耦操作的时间开销小于数据总写入时间的0.4%。此外,主-从副本数据的解耦操作在每个节点上独立执行,不需要跨节点同步。
45.差异化存储操作包括:
46.若第i个键值数据为主副本,则将第i个键值数据写入节点的日志结构合并树中进行存储和管理;以保留日志结构合并树高效的读取、写入和范围扫描的设计特性,但以更轻量级的方式,因为日志结构合并树中不包含从副本后,日志结构合并树的大小显著减少。
47.若第i个键值数据为从副本,则将第i个键值数据写入一个两层日志架构中进行存储和管理;以支持快速的从副本写入性能、以及高效的数据恢复性能。
48.具体实施中,两层日志架构的写入步骤包括:
49.(i)两层日志架构接收到第i个键值数据时,判断i》nmax是否成立,若成立,则执行步骤(ii),否则,将第i个键值数据写入第一层全局日志中;图3给出了本实施例中两层日志架构的示意图,为了实现键值数据的快速写入,每个节点将接收到的键值数据首先写入内存缓存并排序,当缓存满后,将其批量追加写入第一层全局日志的头部,形成一个段文件。由于全局日志不维护任何额外的索引结构,所以全局日志设计可以保证键值数据的高写入性能。然而,虽然将所有键值数据存储在全局日志可实现高写入性能,但会导致数据恢复性能下降。对于全局日志中的键值数据,它们对应的主副本可能存储在不同节点上,当一个节点发生数据丢失时,只需要读取全局日志中的部分键值数据(即对应主副本位于故障节点的这类键值数据)进行恢复。因此,恢复操作只会访问全局日志中的部分数据,从而导致大量随机i/o去搜索全局日志。为了保证高效的数据恢复性能,维护一个后台线程不断地将全局日志中的数据分割到多个本地日志中,见步骤(ii)。
50.(ii)对于第一层全局日志中的nmax个键值数据,后台线程计算得到每个键值数据中的键所映射的节点编号;并根据不同的节点编号建立对应的本地日志,且在每个本地日志中均设置有若干个范围组;图4给出了本实施例中每个本地日志内基于范围的数据分组示意图,每个本地日志被进一步划分为多个范围组,每个范围组对应于一致性哈希环中的一个范围。注意,每个本地日志中的不同范围组在键上没有重叠,因此可以独立管理不同范
围组。例如,附图4中的节点n2,它拥有的本地日志log0存储一类键值数据,其对应的主副本驻留在节点n0。由于节点n0有两个范围[0,10]和[51,60],因此节点n2的本地日志log0包含两个范围组,分别保存[0,10]和[51,60]这两个范围的键值数据。
[0051]
(iii)分割nmax个键值数据:
[0052]
a、定义变量j并初始化j=1;
[0053]
b、对于第j个键值数据,后台线程计算得到第j个键值数据中的键所映射的节点编号为l,则将其映射到第l个本地日志;并判断在第l个本地日志中,第j个键值数据的键所属于的范围组;然后将第j个键值数据写入第l个本地日志中对应的范围组中;为确定每个键值数据所属的范围组,可将键值数据的键与一致性哈希环中每个范围的边界值进行比较,以找到相应的范围组。由于每个本地日志只保留同一类的从副本数据(其对应的主副本存储在同一个节点),且每个本地日志内部进一步采用基于范围的数据分组,因此,数据恢复操作仅需访问与故障节点对应的本地日志中相应范围组的键值数据,无需访问所有本地日志和所有范围组,从而避免大量无效的随机i/o操作;
[0054]
c、将j 1赋值给j后,判断j》nmax是否成立,若成立,则表示将nmax个键值数据都分别写入不同本地日志的不同范围组中,并将每个范围组内所写入的若干个键值数据保存在一个文件内,以形成每个范围组所对应的有序段;否则,返回步骤b执行。
[0055]
本实施例中,对两层日志架构中的键值数据按如下步骤进行有序度可调操作:
[0056]
首先,由于每个本地日志的每个范围组可能包含多个有序段,并且范围组内有序段之间的键值数据没有完全排序。因此,从范围组中读取数据时需要从最新的有序段开始,逐个检查每个有序段,直到找到查询的数据。如果范围组包含太多的有序段,则对两层日志的读性能将会降低。因此,按照如下步骤来调整每个范围组内的有序段个数,图5显示了范围组内有序度可调方案的示意图:
[0057]
若高性能分布式键值存储方法应用于读密集型的存储系统中,则增加范围组内有序段间的合并操作,即当一个范围组内有序段的个数超过阈值δ1时,本实施例中,将δ1设置为10,则将相应范围组内所有的有序段合并为一个有序段,使得范围组内有序段的个数维持在阈值δ1内;
[0058]
若高性能分布式键值存储方法应用于写密集型的存储系统中,则减少范围组内有序段间的合并操作,即当一个范围组内有序段的个数超过δ2时,本实施例中,将δ2设置为100,则将相应范围组内所有的有序段合并为一个有序段,从而将范围组内有序段的个数维持在阈值δ2内;δ1<δ2。
[0059]
范围组内有序段间的合并操作与日志结构合并树中的合并操作类似,包括以下步骤:(i)从范围组中读取出所有的有序段;(ii)将范围组中的所有有序段进行排序,如果在不同有序段中存在多个具有相同键的键值数据,则只保留最新有序段中的那个键值数据,丢弃其它有序段中对应的键值数据;(iii)将合并后的有效键值数据写回相应范围组。
[0060]
通过上述在范围组内进行数据有序度调整操作,使得本发明在不同工作负载及不同系统配置下都能提升分布式键值存储系统的读写性能,实验验证本发明提出的有序度可调的两层日志设计可将分布式键值存储系统的读写性能分别提升1.4倍和2.5倍。
[0061]
本实施例中,对故障节点中的键值数据按如下步骤进行并行数据恢复操作,图6给出了本实施例中数据并行恢复操作的示意图,假设恢复故障节点n0上丢失的数据:
[0062]
(i)使用两个线程并行地从每个节点上的日志结构合并树和两层日志中读取数据,并根据读取的键值数据,计算每个键值数据的哈希值,并将其存储在梅克尔树的各个结点中,从而构建每个节点上的梅克尔树;图6中节点n0和n1分别使用两个线程并行地从每个节点上的日志结构合并树和两层日志中读取数据,并根据读取的数据在节点n0和n1上分别构建梅克尔树;
[0063]
(ii)将故障节点上构建的梅克尔树分别与其他节点构建的梅克尔树依次进行比较,判断故障节点和其他梅克尔树在相同位置的结点的值是否相同;若相同,则表示相应结点所对应的键值数据未丢失,并结束流程,否则,表示相应结点所对应的键值数据已丢失;图6中分别比较节点n0和n1上构建的梅克尔树,由于节点n0中的数据全部丢失,所以节点n0上构建的梅克尔树为空,将其与节点n1上构建的梅克尔树比较后,检测到节点n0上已经丢失的键值数据;
[0064]
(iii)在非故障节点上使用两个线程并行地从日志结构合并树和两层日志中读取丢失数据所在的结点上对应的键值数据作为恢复数据,并发送到故障节点;图6中非故障节点n1使用两个线程并行地从日志结构合并树和两层日志中读取出步骤(ii)中检测到的节点n0上丢失的键值数据,如范围在[11,20],[21,30]的键值数据,并将其发送给故障节点n0;
[0065]
(iv)故障节点收到恢复数据后,使用两个线程并行地向日志结构合并树和两层日志中写入恢复数据;图6中故障节点n0从非故障节点n1接收到恢复的数据[11,20],[21,30]后,使用两个线程并行地向日志结构合并树和两层日志中分别写入范围为[11,20]和[21,30]的键值数据。
[0066]
本发明通过设计上述并行数据恢复操作,极大地提升了数据恢复性能,实验表明本发明设计的并行数据恢复操作可将数据恢复时间减少一半左右。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。