1.本发明涉及智能电网异常设备检测技术领域,尤其涉及基于kmeans的电网异常设备检测方法及装置。
背景技术:
2.由于信息化和智能化的需要,传统的电网物理系统在向智能电网演化的过程中,人们引进计算、通信、控制3c(computing、communication、control)技术,以实现智能电网系统的自我感知、精确控制、远程协作与优化调度,使系统更加灵活、高效、经济与智能,导致电网物理系统与信息系统的紧密融合,进而使得智能电网系统的运行环境由封闭和隔离变得开放和互联。智能电网信息系统与物理系统的有机融合,在改善智能电网运行效率的同时,同样为攻击者提供了新的攻击渠道,使得智能电网更有可能面临来自恶意内部人员或敌对国家竞争对手的攻击。近年来的一系列信息安全事件充分证实了智能电网的脆弱性,亟需一种新的智能电网异常设备检测方法,基于智能电网设备量测数据,检测存在异常的电网设备,为智能电网防御安全攻击,提供帮助。现有的k-means及其改进方法,只是简单依据点与簇中心的最大相似度,决定该点所属的簇,因此,现有技术存在针对异常设备的检测效率低和检测结果不精准的问题。
技术实现要素:
3.本发明提供一种基于kmeans的电网异常设备检测方法及装置,提高了针对异常智能电网设备的精准检测。
4.本发明一实施例提供一种基于kmeans的电网异常设备检测方法,包括以下步骤:
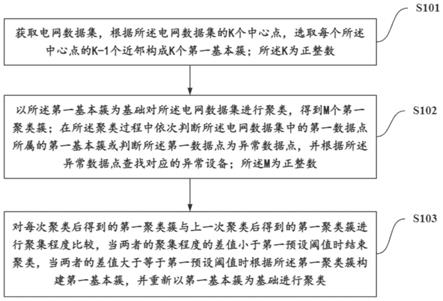
5.获取电网数据集,根据所述电网数据集的k个中心点,选取每个所述中心点的k-1个近邻构成k个第一基本簇;所述k为正整数;
6.以所述第一基本簇为基础对所述电网数据集进行聚类,得到m个第一聚类簇;在所述聚类过程中依次判断所述电网数据集中的第一数据点所属的第一基本簇或判断所述第一数据点为异常数据点,并根据所述异常数据点查找对应的异常设备;所述m为正整数;
7.对每次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇进行聚集程度比较,当两者的聚集程度的差值小于第一预设阈值时结束聚类,当两者的差值大于等于第一预设阈值时根据所述第一聚类簇构建第一基本簇,并重新以第一基本簇为基础进行聚类。
8.进一步的,以所述第一基本簇为基础对所述电网数据集进行聚类,包括以下步骤:
9.根据所述k个第一基本簇构建k个基础点集;
10.针对所述电网数据集中的第一数据点,依次计算各个所述第一数据点相对于各个第一基本簇的预测选择率,并将所述预测选择率最大的第一基本簇记为第二基本簇;
11.计算所述第二基本簇的平均相似度和所述第一数据点相对于各个基础点集属于所述第二基本簇的第二概率的平均值,所述平均相似度为第二基本簇的中心点和所述第二
基本簇的其他数据点之间的平均相似度;
12.根据所述平均相似度和第二概率的平均值判断所述第一数据点属于第二基本簇或判断所述第一数据点为异常数据点。
13.进一步的,根据所述平均相似度和第二概率的平均值判断所述第一数据点是否为异常数据点,具体为:
14.判断所述平均相似度是否小于等于所述第二概率的平均值的预设倍数,若是,则判断所述第一数据点属于所述第二基本簇;若否,则判断所述第一数据点为异常数据点。
15.进一步的,根据所述k个第一基本簇构建k个基础点集,具体为:
16.每次从所述k个基本簇中各选取一个第二数据点,并使得本次选取的各个第二数据点之间的距离最大,将每次选取的k个第二数据点组合形成一个基础点集,共选取k次,得到k个基础点集。
17.进一步的,依次计算各个所述第一数据点相对于各个第一基本簇的预测选择率,具体为:
18.每次从当前电网数据集中选择一个第一数据点,计算所述第一数据点相对于每个基础点集属于各个第一基本簇的第一概率;所述电网数据集为本次聚类后删除所述各个第一基本簇的数据后得到的当前电网数据集;
19.根据所述第一概率的计算结果,统计使得所述第一概率最大的基础点集的数量;
20.根据所述第一概率和数量,计算所述第一数据点属于各个第一基本簇的预测选择率。
21.进一步的,根据公式计算所述第一数据点相对于每个基础点集属于各个第一基本簇的第一概率;式中x
t
为所述第一数据点,cj{j=1,2,
…
,k}为所述第一基本簇,gs(s=1,2,
…
,k)为所述基础点集,为基础点集gs中的相应数据点,表示x
t
和之间归一化的相似性。
22.进一步的,根据公式计算所述第一数据点属于各个第一基本簇的预测选择率;式中#{p(cj|gs)|s=1,2,
…
,k}为使得所述第一概率最大的基础点集的数量,k表示所述第一基本簇或基础点集的数量,p(cj|gi)为所述第一概率,cj{j=1,2,
…
,k}为所述第一基本簇,gs(s=1,2,
…
,k)为所述基础点集。
23.进一步的,根据所述电网数据集的k个中心点,选取每个所述中心点的k-1个近邻构成k个第一基本簇,具体为:
24.生成第一基本簇:计算当前电网数据集的均值点,从所述当前电网数据集选取一个与所述均值点最近的数据点作为中心点,再从所述当前电网数据集中选取所述中心点的k-1个近邻和所述中心点一起形成第一基本簇,从所述当前电网数据集中删除所述第一基本簇中的电网数据;
25.重复执行所述生成第一基本簇的过程,直到得到k个第一基本簇。
26.进一步的,以所述k个第一基本簇为基础对所述电网数据集进行聚类时,对各个第一基本簇的元素数量进行判断,当所述第一基本簇的元素数量少于第二预设阈值时,将所述第一基本簇的各个数据点设置为第一数据点,并将所述第一数据点分配至其他第一基本簇或将所述第一数据点判断为异常数据点,再删除所述第一基本簇,得到m个第一聚类簇。
27.本发明另一实施例提供了一种基于kmeans的电网异常设备检测装置,包括基本簇构建模块、异常检测模块和聚类结果检测模块;
28.所述基本簇构建模块用于获取电网数据集,根据所述电网数据集的k个中心点,选取每个所述中心点的k-1个近邻构成k个第一基本簇;
29.所述异常检测模块用于以所述第一基本簇为基础对所述电网数据集进行聚类,得到m个第一聚类簇;在所述聚类过程中依次判断所述电网数据集中的第一数据点所属的第一基本簇或判断所述第一数据点为异常数据点,并根据所述异常数据点查找对应的异常设备;所述k和m为正整数;
30.所述聚类结果检测模块用于对每次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇进行聚集程度比较,当两者的聚集程度的差值小于第一预设阈值时结束聚类,当两者的差值大于等于第一预设阈值时根据所述第一聚类簇构建第一基本簇,并重新以第一基本簇为基础进行聚类。
31.本发明的实施例,具有如下有益效果:
32.本发明提供了一种基于kmeans的电网异常设备检测方法及装置,该方法通过依次选取k个相互欧式距离最远的数据点为簇中心,再依次选取与簇中心最近的k-1个近邻,构成k个基本簇。然后从基本簇中依次选取相互距离最远的k个点构成基础点集,再计算其它数据点与k个基础点集中点的相似度,进而得到该数据点属于各个簇的概率,将其进行有机融合,综合该点与各个簇的相似度,确定该数据点所属的簇。现有的k-means及其改进方法,只是简单依据点与簇中心的最大相似度,决定该点所属的簇。相比于现有k-means及其改进方法,本发明综合了数据点与多个簇的多个点的相似度来确定该数据点所属的簇,可以得到较为准确的聚类结果,提高了检测异常电网设备的准确率。
附图说明
33.图1是本发明一实施例提供的基于kmeans的电网异常设备检测方法的流程示意图;
34.图2是本发明一实施例提供的基于kmeans的电网异常设备检测装置的结构示意图。
具体实施方式
35.下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.如图1所示,本发明一实施例提供的一种基于kmeans的电网异常设备检测方法,包
括:
37.步骤s101:获取电网数据集,根据所述电网数据集的k个中心点,选取每个所述中心点的k-1个近邻构成k个第一基本簇。
38.作为其中一种实施例,步骤s101包括以下子步骤:
39.子步骤s1011:生成第一基本簇:计算当前电网数据集的均值点,从所述当前电网数据集选取一个与所述均值点最近的数据点作为中心点,再从所述当前电网数据集中选取所述中心点的k-1个近邻和所述中心点一起形成第一基本簇,从所述当前电网数据集中删除所述第一基本簇中的电网数据。
40.子步骤s1012:重复执行所述生成第一基本簇的过程,直到得到k个第一基本簇。
41.步骤s102:以所述第一基本簇为基础对所述电网数据集进行聚类,得到m个第一聚类簇;在所述聚类过程中依次判断所述电网数据集中的第一数据点所属的第一基本簇或判断所述第一数据点为异常数据点,并根据所述异常数据点查找对应的异常设备;所述k和m为正整数。
42.作为其中一种实施例,步骤s102包括以下子步骤:
43.子步骤s1021:根据所述k个第一基本簇构建k个基础点集。
44.作为其中一种实施例,子步骤s1021具体为:每次从所述k个基本簇中各选取一个第二数据点,并使得本次选取的各个第二数据点之间的距离最大,将每次选取的k个第二数据点组合形成一个基础点集,共选取k次,得到k个基础点集。
45.子步骤s1022:针对所述电网数据集中的第一数据点,依次计算各个所述第一数据点相对于各个第一基本簇的预测选择率,并将所述预测选择率最大的第一基本簇记为第二基本簇。
46.作为其中一种实施例,依次计算各个所述第一数据点相对于各个第一基本簇的预测选择率,具体为:
47.每次从当前电网数据集中选择一个第一数据点,计算所述第一数据点相对于每个基础点集属于各个第一基本簇的第一概率;所述电网数据集为本次聚类后删除所述各个第一基本簇的数据后得到的当前电网数据集;
48.根据所述第一概率的计算结果,统计使得所述第一概率最大的基础点集的数量;
49.根据所述第一概率和数量,计算所述第一数据点属于各个第一基本簇的预测选择率。
50.作为其中一种实施例,根据公式计算所述第一数据点相对于每个基础点集属于各个第一基本簇的第一概率;式中x
t
为所述第一数据点,cj{j=1,2,
…
,k}为所述第一基本簇,gs(s=1,2,
…
,k)为所述基础点集,为基础点集gs中的相应数据点,表示x
t
和之间归一化的相似性。
51.作为其中一种实施例,根据公式计算所述第一
数据点属于各个第一基本簇的预测选择率;式中#{p(cj|gs)|s=1,2,
…
,k}为使得所述第一概率最大的基础点集的数量,k表示所述第一基本簇或基础点集的数量,p(cj|gi)为所述第一概率,cj{j=1,2,
…
,k}为所述第一基本簇,gs(s=1,2,
…
,k)为所述基础点集。
52.子步骤s1023:计算所述第二基本簇的平均相似度和所述第一数据点相对于各个基础点集属于所述第二基本簇的第二概率的平均值,所述平均相似度为第二基本簇的中心点和所述第二基本簇的其他数据点之间的平均相似度。
53.子步骤s1024:根据所述平均相似度和第二概率的平均值判断所述第一数据点属于第二基本簇或判断所述第一数据点为异常数据点。具体地,判断所述平均相似度是否小于等于所述第二概率的平均值的预设倍数,若是,则判断所述第一数据点属于所述第二基本簇;若否,则判断所述第一数据点为异常数据点。
54.步骤s103:对每次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇进行聚集程度比较,当两者的聚集程度的差值小于第一预设阈值时结束聚类,当两者的差值大于等于第一预设阈值时根据所述第一聚类簇构建第一基本簇,并重新以第一基本簇为基础进行聚类。
55.作为其中一种实施例,以所述k个第一基本簇为基础对所述电网数据集进行聚类时,对各个第一基本簇的元素数量进行判断,当所述第一基本簇的元素数量少于第二预设阈值时,将所述第一基本簇的各个数据点设置为第一数据点,并将所述第一数据点分配至其他第一基本簇或将所述第一数据点判断为异常数据点,再删除所述第一基本簇,将完成聚类的第一基本簇记为第一聚类簇,即得到m个第一聚类簇。
56.作为其中一种详细的实施例,包括以下步骤:
57.步骤a101:将获取的电网数据集记为x={x1,x2,
…
,xn}
t
,计算x的均值点在x中首先选取与所述均值点欧式距离最近的数据点作为中心点,再在x中选取与所述中心点欧式距离最近的k-1个近邻,构成一个第一基本簇bc1。
58.每构建一个第一基本簇后,从所述电网数据集中移除与所述第一基本簇的数据点相同的数据点,得到当前电网数据集即x=x-{bc1},再重复上述构建第一基本簇的过程,直至构建k个第一基本簇。
59.步骤a102:从构建的第一基本簇bcj(j=1,2,
…
,k)中任选一点使得与已经从第一基本簇中选取的其它点的欧式距离和最大,令迭代此过程,获得基础点集
60.每次从所述k个基本簇bcj(j=1,2,
…
,k)中各选取一个第二数据点并使得本次选取的各个第二数据点之间的欧式距离最大(即欧氏距离和最大),将每次选取的k个第二数据点组合形成一个基础点集,共选取k次,得到k个基础点集
61.根据所述第一基本簇和基础点集构建以下矩阵:
[0062][0063]
步骤a103:判断是否为空,若为空则表示所述电网数据集中的所有数据点均完成聚类。若不为空,则针对所述电网数据集中的第一数据点,依次计算各个所述第一数据点相对于各个第一基本簇的预测选择率,并将所述预测选择率最大的第一基本簇记为第三基本簇,所述第一数据点为所述电网数据中删除各个第一基本簇的数据点后选取的数据点。
[0064]
步骤a1031:选取第一数据点x
t
,计算x
t
与各个第一基本簇bcj(j=1,2,
…
,k)中的点之间的相似性,记为其中1≤s≤k。将计算得到相似性进行归一化,即将第一基本簇bcj{j=1,2,
…
,k}记为cj。
[0065]
步骤a1032:基于x
t
与基础点集gs(s=1,2,
…
,k)中点的相似性,计算x
t
属于第一基本簇cj{j=1,2,
…
,k}的归一化相似性,即计算所述第一数据点相对于每个基础点集属于各个第一基本簇的第一概率计算结果如下表所示:
[0066] c1c2…cj
…ck
g1p(c1|g1)p(c2|g1)
…
p(cj|g1)p(ck|g1)g2p(c1|g2)p(c2|g2)p(cj|g2)p(ck|g2)gsp(c1|gs)p(c2|gs)p(cj|gs)
…
p(ck|gs)
………………gk
p(c1|gk)p(c2|gk)
…
p(cj|gk)
…
p(ck|gk)
[0067]
式中,表示x
t
与之间归一化的相似性。
[0068]
若所述第一数据点x
t
相对于基础点集gs属于第一基本簇c1的点的第一概率(即归一化相似性)计算为:0.125、0.25、0.375、0.5、0.625、0.75、0.875,则第一数据点x
t
相对于基础点集gs属于簇c1的第一概率(即归一化相似性)计算为:同理对每一个基础点集gs(s=1,2,
…
,k)相对于每一个第一基本簇cj{j=1,2,
…
,k},计算并计算
#{p(cj|gs)|s=1,2,
…
,k}为使得所述第一概率最大的基础点集的数量。
[0069]
步骤a1033:根据公式计算所述第一数据点x
t
属于各个第一基本簇的预测选择率ps(cj)。
[0070]
例如,第一数据点相对于基础点集gs(s=1,2,3)属于第一基本簇cj{j=1,2,3}的第一概率(即归一化相似性)如下表所示:
[0071] c1c2c3最大值g10.10000.40000.50000.500g20.15380.38460.46150.4615g30.18750.43750.37500.4375
[0072]
则p(c1)=0;
[0073]
ps(c1)=0,
[0074]
将所述预测选择率最大的第一基本簇记为第二基本簇。
[0075]
步骤a104:计算所述第三基本簇的中心点与其它点之间的平均相似度,记为计算第一数据点相对于各个基础点集属于所述第三基本簇的第二概率的平均值as,即计算第一数据点与所述第二基本簇中点的归一化相似性的平均值为第二基本簇。
[0076]
步骤a105:根据所述平均相似度和第二概率的平均值判断所述第一数据点属于第二基本簇或判断所述第一数据点为异常数据点。具体地,当判断所述平均相似度是否小于等于所述第二概率的平均值的预设倍数,若是,则判断所述第一数据点属于所述第二基本簇;若否,则判断所述第一数据点为异常数据点。即若成立则所述第一数据点属于所述第二基本簇,若不成立则x
t
为异常数据点。
[0077]
步骤a106:对所有的第一数据点完成判断后,对聚类得到的各个第一基本簇中的元素数量进行判断,当所述第一基本簇的元素数量少于第二预设阈值时,将所述第一基本簇的各个数据点设置为第一数据点,并将所述第一数据点分配至其他第一基本簇或将所述第一数据点判断为异常数据点,再删除所述第一基本簇。将剩下的所述第一基本簇记为第一聚类簇,即得到m个第一聚类簇。
[0078]
步骤a107:对每次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇进行聚集程度比较,当两者的聚集程度的差值小于第一预设阈值时结束聚类,当两者的差值大于等于第一预设阈值时根据所述第一聚类簇构建第一基本簇,并重新以第一基本簇为基
础进行聚类。
[0079]
具体地,对聚类得到的m个第一聚类簇c
t
(1≤t≤m),根据公式计算其聚集程度,根据公式wss-wss
′
《α判断本次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇的聚集程度的差值是否小于第一预设阈值;若是,则结束聚类,若否,则对聚类得到的m个第一聚类簇c
t
(1≤t≤m),计算其均值点将第一聚类簇c
t
中与欧式距离最近的点选为簇中心,再在相应的第一聚类簇中选取与所述簇中心欧式距离最近的m-1点作为近邻,构成m个第一基本簇,重复步骤a102-a106,直到wss-wss
′
《α,结束聚类;其中wss
′
为上一次聚类后得到的第一聚类簇的聚集程度,wss为本次聚类后得到的第一聚类簇的聚集程度。所述基本簇为聚类前的簇,所述聚类簇为聚类完成后的簇。
[0080]
本发明实施例综合了数据点与多个簇的多个点的相似度来确定该数据点所属的簇,可以得到较为准确的聚类结果,提高了检测异常电网设备的准确率。本发明实施例通过依次选取k个相互欧式距离最远的数据点为簇中心,再依次选取与簇中心最近的k-1个近邻,构成k个基本簇。然后从基本簇中依次选取相互距离最远的k个点构成基础点集,再计算其它数据点与k个基础点集中点的相似度,进而得到该数据点属于各个簇的概率,将其进行有机融合,综合该点与各个簇的相似度,确定该数据点所属的簇。现有的k-means及其改进方法,只是简单依据点与簇中心的最大相似度,决定该点所属的簇。相比于现有k-means及其改进方法,本发明实施例综合了数据点与多个簇的多个点的相似度来确定该点所属的簇,可以较为准确地确定数据点所属的簇,同时也可发现较为复杂的簇,如密度不同的球星簇等,进而可以精准地检测到异常设备。
[0081]
如图2所示,本发明另一实施例提供了基于kmeans的电网异常设备检测装置,包括基本簇构建模块、异常检测模块和聚类结果检测模块;
[0082]
所述基本簇构建模块用于获取电网数据集,根据所述电网数据集的k个中心点,选取每个所述中心点的k-1个近邻构成k个第一基本簇;
[0083]
所述异常检测模块用于以所述第一基本簇为基础对所述电网数据集进行聚类,得到m个第一聚类簇;在所述聚类过程中依次判断所述电网数据集中的第一数据点所属的第一基本簇或判断所述第一数据点为异常数据点,并根据所述异常数据点查找对应的异常设备;所述k和m为正整数;
[0084]
所述聚类结果检测模块用于对每次聚类后得到的第一聚类簇与上一次聚类后得到的第一聚类簇进行聚集程度比较,当两者的聚集程度的差值小于第一预设阈值时结束聚类,当两者的差值大于等于第一预设阈值时根据所述第一聚类簇构建第一基本簇,并重新以第一基本簇为基础进行聚类。
[0085]
为描述的方便和简洁,本装置实施例的基于kmeans的电网异常设备检测装置包括上述基于kmeans的电网异常设备检测方法实施例中的全部实施方式,此处不再赘述。
[0086]
需说明的是,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本发明提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条或
多条通信总线或信号线。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0087]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
[0088]
本领域普通技术人员可以理解实现上述实施例中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-only memory,rom)或随机存储记忆体(random access memory,ram)等。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。