1.本发明属于人工智能领域,尤其涉及一种量刑标准知识增强的数值感知的智能法律判决方法。
背景技术:
2.近年来,法律人工智能引起了学术界和工业界的广泛关注。早期的工作通常利用数学和统计算法来分析现有的法律案件。受到深度学习的巨大成功的启发,一些研究者使用外部法律条款或法律原理图知识作为特征来区分混淆的案件。一些研究者注意到了 法律判决预测(ljp, legal judgment prediction)的子任务之间的依赖关系,并提出了基于多任务学习的框架,在ljp 的两个子任务上取得了出色的表现,即对罪名和法律条款的预测。然而,很少有方法关注数值 ljp,即罚金和刑期的预测。一些研究者提出了一种基于罪名的刑期预测模型,该模型采用深度门控网络为特定罪名选择细粒度特征。
3.调查表明,数值 ljp 的最佳f1 分别为 39.76 和 40.43,远低于罪名和法律条款预测的性能(90.89 和 88.75)。主要原因是它们忽略了事实描述中的数字,其模型不具有数值推理能力。
4.数值推理涉及到广泛的任务,如信息提取、检索、数学单词问题和表征学习。在机器阅读理解由研究人员上提出了一种数字感知模型,对数字进行多重运算,如计数、加法和减法。还有研究者提出了一个数值推理网络,构建了一个具有比较感知能力的gnn 来推理数字之间的相对信息。由于之前的方法不能识别不同的数字类型,有研究人员引入了一个异构有向图来整合类型和实体信息,以进行数值推理。
5.尽管数值推理已经有一定研究,但尚未被用于解决法律判决尤其是数值法律判决任务。因此非常有必要设计合适的模型和方法将其用于数值法律判决领域。
技术实现要素:
6.本发明目的在于提供一种量刑标准知识增强的数值感知的智能法律判决方法,以解决对文本数值缺乏感知能力带来的罚金和刑期预测不准确的技术问题。
7.为解决上述技术问题,本发明的具体技术方案如下:一种量刑标准知识增强的数值感知的智能法律判决方法,包括以下步骤:步骤1、使用预训练语言模型(ptlm, pre-trainedlanguagemodel)在海量法律文本上进行二阶段预训练,以获得领域内和任务内的语义知识,随后在任务数据集文本上进一步预训练,使用得到的模型对事实描述编码,得到文本编码和;以roberta(一种预训练模型)为例,在大量法律文本上进行掩码语言建模(mlm, masked language model),随后在任务数据集文本上进一步预训练,使用得到的模型对事实描述编码,得到文本编码和;步骤2、使用基于对比学习的量刑标准知识选择,根据上面的文本编码选择正确量刑标准知识。
8.量刑标准知识示例如下:“犯盗窃罪的,涉案金额1000元以上不满2500元的,处管制、拘役、有期徒刑六个月或单处罚金;2500元以上不满4000元的,处有期徒刑六个月至一年;4000元以上不满7000元的,处有期徒刑一年至二年;7000元以上不满10000元的,处有期徒刑二年至三年。”根据得到的犯罪事实描述编码,选择正确的量刑标准知识,作为一个损失,同时引入对比学习损失。”步骤3、使用与步骤1中同样经过两阶段预训练的另一个ptlm对量刑标准知识编码,同时利用掩码数值预测(mnp,masked numeral prediction)学习数值意义,得到量刑标准知识编码。
9.mnp示例如下:输入:[cls]诈骗公共和私人财产达到人民币[mask]元以上的,处6个月监禁。
[0010]
输出:10000步骤4、对文本数值和量刑标准知识数值构建异构有向数值图,进行数值推理。构建一个异构图,其中节点代表事实描述和量刑标准知识中的数值,边代表数值之间的大小关系。
[0011]
在图网络中,遵循图神经网络推理的一般范式,做迭代地消息传播,最终得到具有数值理解的表征。
[0012]
步骤5、联合量刑标准知识和犯罪事实中数值推理的结果,同时预测刑期和罚金。
[0013]
步骤6、通过小批量梯度下降(mini-batch)随机梯度下降的方式来更新模型的参数,进行模型的训练以及优化。具体来讲,采用批量梯度下降就是在每个训练回合中计算所有样本产生的损失,进而计算梯度进行反向传播和参数更新。这样每次都需要所有样本来计算损失,在样本数量非常大的时候会受到计算资源的限制,效率非常低。小批量梯度下降将所有的训练样本划分到b个mini-batch中,每个mini-batch包含
푏푎푡푐
ℎ
_
푠푖푧푒
个训练样本。每个迭代训练过程中计算一个mini-batch中的样本损失,进而进梯度下降和参数更新,这样兼顾了批量梯度下降的准确度和随机梯度下降的更新效率。
[0014]
进一步的,所述步骤1中,使用ptlm在海量法律文本上进行二阶段预训练,以获得领域内和任务内的语义知识。使用预训练模型作为犯罪事实的编码器可以从海量未标注的法律文本上学习法律语言本身的知识,可以为使下游任务更好地获取特定领域的知识。以roberta(一种预训练模型)为例,在大量法律文本上进行掩码语言建模(mlm, masked language model),随后在任务数据集文本上进一步预训练,使用得到的模型对事实描述编码,得到文本编码和;;其中为句子级的表征,为所有词语的表征矩阵,为标识符。
[0015]
进一步的,所述步骤2中,根据文本表征选择合适的量刑标准知识,同时引入对比学习的损失,来区分不同的量刑标准知识,得到量刑标准知识选择任务的损失函数和对比学习的损失函数,具体如下:
;;其中,是调整权重的超参,是softmax函数的温度超参,是一个训练批次大小,和 分别指第i个样本第m个量刑标准知识类别正确的标签和预测的概率,指量刑标准知识的数量。、、 表示一个训练批次中第个样本的表征。
[0016]
进一步的,所述步骤3中,对所选择的量刑标准知识文本进行编码,同时使用mnp任务使模型理解量刑标准知识以及其中数值,具体公式如下:其中,表示量刑标准知识的句子级表征,表示量刑标准知识的所有词语的表征矩阵,得到掩码数字预测mnp任务的损失函数定义为:;其中表示第 个量刑标准知识中的数值数量,表示数值词典的大小, 分别表示第个量刑标准知识第个数值预测中某一个类别的正确标签和预测概率。
[0017]
进一步的,所述步骤4中,对文本数值和量刑标准知识数值构建异构有向数值图,进行数值推理。构建一个异构图,其中节点代表事实描述和量刑标准知识中的数值,边代表数值之间的大小关系。预训练模型尽管效果显著,但是被证明无法学习数值常识,不具有数值推理能力。这里通过图网络可以使模型理解数值规模。
[0018]
在图网络中,遵循图神经网络推理的一般范式,做迭代地消息传播,最终得到具有数值理解的表征。整个过程可以概括如下:;其中代表图网络的推理,是一个可学习的参数矩阵,将和 拼接,得到具有数值感知的表征矩阵,其计算方式如下:
;其中表示矩阵拼接,表示事实描述和量刑标准知识中数值的位置,是一个可学习的参数矩阵。该步骤可以帮助模型有效地学习到文本中的数值和量刑标准知识中的数值对比关系。此外,由于文本中的数值间接学习到了犯罪事实的语义信息,可以帮助模型更好地学习到量刑标准知识和犯罪事实之间的联合表征。
[0019]
进一步的,所述步骤5中,联合量刑标准知识和犯罪事实中数值推理的结果,同时预测刑期和罚金:其中,是罚金预测的损失函数,是一个批次中样本的数量,是罚金等级的数量,分别是第批次中第个样本的真实罚金标签和预测标签,是刑期预测的损失函数,分别是第批次中第个样本的真实刑期标签和预测标签,分别是第批次中第个样本的真实刑期长度和预测长度,当时,表示当前刑期为死刑或无期,该损失函数的特征在于,首先很好地区分了死刑和无期这两种特殊情况;其次相比传统基于交叉熵损失的方法,可以让模型即使在预测的结果和真实结果有差异时也可以使得结果更接近于正确结果。这里为了符合使得对刑期的预测更符合时间的特性,添加了一个损失,其中对数差可以使得模型更加看重刑期较小时的预测误差。
[0020]
最终,完整的训练损失为:,即:量刑标准知识选择损失,对比学习损失,掩码数字预测损失,为不同损失的权重。
[0021]
由该训练损失通过mini-batch 梯度下降的方式,以最小化函数的方式,更新所有的参数。将量刑标注知识选择、掩码数字预测和量刑预测三个任务联合训练,具有如下优势:(1)多个模型共用一套编码器,有效降低显存占用;(2)多个模型的的计算同时进行前向
传播,可以提高模型的计算效率;(3)多个任务间相辅相成,通过信息共享可以提升彼此的性能表现。
[0022]
本发明的一种量刑标准知识增强的数值感知的智能法律判决方法,相较现有技术,具有以下优点:1)使用预训练模型作为犯罪事实的编码器可以从海量未标注的法律文本上学习法律语言本身的知识,可以为使下游任务更好地获取特定领域的知识。同时,作为多任务之间的公共编码器,让不同任务之间不相关的部分相互作用,有助于让模型脱离局部极小值的限制;2)采用基于对比学习的量刑知识选择能够有效缓解易混淆罪名的挑战。对比学习具有强大的表示能力,在监督学习场景中,它能够有效区分不同类别的样本。在判决预测的实际应用中,能够有根据地选择正确的量刑标准知识是至关重要的一步。在本方案中,模型能够学习到易混淆样本之间的微小差异;3)将图网络用于分类问题的数值推理,使得模型具有数值感知能力,相较于传统的将所有数值视作统一词汇或不同词汇的方法,考虑了数值的实际大小及其对比关系,可以有效提高量刑预测的精度;4)引入量刑标准知识作为先验,将量刑标准知识数值作为锚点加入图网络,让模型能够更容易找到判决的参照点,从而保证训练的有效性和鲁棒性,同时量刑标准知识作为模型预测的基础,进一步提高了预测的准确率。同时将量刑标准知识中的数值作为锚点加入图网络,在图网络中进行数值推理,可以为模型的预测提供有效的解释,增强了量刑预测的可解释性;5)采用掩码数值预测模块能够让模型学习到量刑标准中的法律常识,即提供不同罪名之间数字关系的常识性理解;6)我们的目标是研究ptlms是否能够捕获数字常识性知识,即提供对实体之间数字关系的理解的常识性知识,最有可能预测的数值排名可以呈现出该模块捕捉数值常识的能力。
附图说明
[0023]
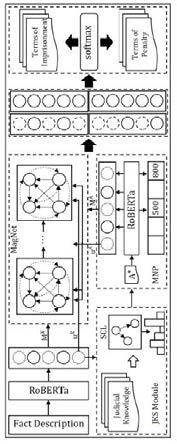
图1为本发明的模型概念图;图2为本发明的流程图。
具体实施方式
[0024]
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种量刑标准知识增强的数值感知的智能法律判决方法做进一步详细的描述。
[0025]
实施例:本发明所涉及的技术术语解释如下ptlm(pre-trained language model):预训练语言模型mnp(masked numeral prediction):掩码数值预测jks(judicial knowledge selection):司法判决知识选择如图1所示,本发明由四个主要模块组成:即jks模块、基于mnp任务的法律数字意义获取模块、图网络推理模块和判断预测模块。
[0026]
首先通过基于对比学习的分类器选择给定犯罪事实对应的量刑标准知识。该模块是整个模型的基石,它模仿了法官的量刑实践。只有运用正确的量刑标准知识,才能作出准确的判断。然后,该模型通过掩码数值预测(mnp)任务,从上一步中选择的量刑标准知识中获得法律数值意义。量刑标准知识包含了犯罪行为的定量标准,在本文中称为数值锚点。这些锚点可以作为模型进行数值推理的参考点。在判断预测模块中,我们整合数字表示、事实描述和量刑标准知识,共同预测判断结果。
[0027]
本发明的一种量刑标准知识增强的数值感知的智能法律判决方法,包括以下步骤:步骤1、使用预训练语言模型(ptlm)对事实描述编码,得到文本编码和;使用ptlm获得文本表征,以roberta为例:;其中为句子级的表征,为所有词语的表征矩阵,为标识符。
[0028]
步骤2)使用基于对比学习的量刑标准知识选择,根据上面的文本编码选择正确量刑标准知识。
[0029]
根据文本表征选择合适的量刑标准知识,同时引入对比学习的损失,来区分不同的量刑标准知识,得到量刑标准知识选择任务的损失函数和对比学习的损失函数,具体如下:;;其中,是调整权重的超参,是softmax函数的温度超参,是一个训练批次大小,和 分别指第i个样本第m个量刑标准知识类别正确的标签和预测的概率,指量刑标准知识的数量。、、 分别表示一个训练批次中第个样本的表征。
[0030]
步骤3)使用ptlm对量刑标准知识编码,同时利用mnp学习数值意义。
[0031]
对所选择的量刑标准知识文本进行编码,同时使用mnp任务使模型理解量刑标准知识以及其中数值,具体地:,其中,表示量刑标准知识的句子级表征,表示量刑标准知识的所有词语的表征矩阵,
得到掩码数字预测mnp任务的损失函数定义为:;其中表示第 个量刑标准知识中的数值数量,表示数值词典的大小, 分别表示第个量刑标准知识第个数值预测中某一个类别的正确标签和预测概率。
[0032]
步骤4)对文本数值和量刑标准知识数值构建异构有向数值图,进行数值推理,获得具有数值理解能力的表征。
[0033]
进一步的,所述步骤4中,对文本数值和量刑标准知识数值构建异构有向数值图,进行数值推理。构建一个异构图,其中节点代表事实描述和量刑标准知识中的数值,边代表数值之间的大小关系。
[0034]
在图网络中,遵循图神经网络推理的一般范式,做迭代地消息传播,最终得到具有数值理解的表征。整个过程可以概括如下:;其中代表图网络的推理,是一个可学习的参数矩阵,将和 拼接,得到具有数值感知的表征:;其中表示矩阵拼接,表示事实描述和量刑标准知识中数值的位置,是一个可学习的参数矩阵。该步骤可以帮助模型有效地学习到文本中的数值和量刑标准知识中的数值对比关系。此外,由于文本中的数值间接学习到了犯罪事实的语义信息,可以帮助模型更好地学习到量刑标准知识和犯罪事实之间的联合表征。
[0035]
进一步的,所述步骤5中,联合量刑标准知识和犯罪事实中数值推理的结果,同时预测刑期和罚金:
,其中,是罚金预测的损失函数,是一个批次中样本的数量,是罚金等级的数量,分别是第批次中第个样本的真实罚金标签和预测标签,是刑期预测的损失函数,分别是第批次中第个样本的真实刑期标签和预测标签,分别是第批次中第个样本的真实刑期长度和预测长度,当时,表示当前刑期为死刑或无期,该损失函数的特征在于,首先很好地区分了死刑和无期这两种特殊情况;其次相比传统基于交叉熵损失的方法,可以让模型即使在预测的结果和真实结果有差异时也可以使得结果更接近于正确结果。这里为了符合使得对刑期的预测更符合时间的特性,添加了一个损失,其中对数差可以使得模型更加看重刑期较小时的预测误差。
[0036]
最终,完整的训练损失为:由该训练损失通过mini-batch 梯度下降的方式,以最小化函数的方式,更新所有的参数。将量刑标注知识选择、掩码数字预测和量刑预测三个任务联合训练,具有如下优势:(1)多个模型共用一套编码器,有效降低显存占用;(2)多个模型的的计算同时进行前向传播,可以提高模型的计算效率;(3)多个任务间相辅相成,通过信息共享可以提升彼此的性能表现。
[0037]
步骤6)模型的训练以及优化。通过小批量梯度下降(mini-batch)随机梯度下降的方式来更新模型的参数,进行模型的训练以及优化。具体来讲,采用批量梯度下降就是在每个训练回合中计算所有样本产生的损失,进而计算梯度进行反向传播和参数更新。这样每次都需要所有样本来计算损失,在样本数量非常大的时候会受到计算资源的限制,效率非常低。小批量梯度下降将所有的训练样本划分到b个mini-batch中,每个mini-batch包含
푏푎푡푐
ℎ
_
푠푖푧푒
个训练样本。每个迭代训练过程中计算一个mini-batch中的样本损失,进而进梯度下降和参数更新,这样兼顾了批量梯度下降的准确度和随机梯度下降的更新效率。
[0038]
传统的梯度下降,每次梯度下降都是对所有的训练数据进行计算平均梯度,这种梯度下降法叫做full-batch梯度下降法。考虑一种情况,当训练数据量在千万级别时,一次迭代需要等待多长时间,会极大的降低训练速度。如果选择介于合适的bath size数据量进行训练,称为mini-batch 梯度下降。
[0039]
随机梯度下降的劣势在于每次训练的不能保证使用的是同一份数据,所以每一个batch不能保证都下降,整体训练loss变化会有很多噪声,但是整体趋势是下降的,随后会
在最优值附近波动,不会收敛。
[0040]
在训练过程中,需要一个指标来标示训练是否收敛。这里需要一个数据集,称为验证集,用来在每轮训练结束后观察,当前训练的模型是否已经收敛。由于验证集上的数据没有在训练中出现,所以模型在验证集上的效果可以衡量模型是否收敛。这样可以有效的进行合适的训练,避免训练时间过长导致的模型过拟合。
[0041]
在训练的过程中,可以选择不同的超参数,比如词向量的维度。本实施采用如下的参数设计:词向量维度{50,100,200,300},学习速率{0.001,0.01,0.02,0.1}。batch的大小b={32,64,128},同样我们采用dropout=0.5的设置来避免过拟合。
[0042]
本实施例使用了如下指标进行评估:f1: 通过使用macro precision 和macro recall 以及macro f1 来测试分类器的性能。precision 是指分类器判断为正例的数据中真正属于正例的数据的比例,反应了分类器在判断正例时是否准确。recall 是指真实的全部正例数据中分类器判断为正例数据的比例,反应了分类器能够将全部正例数据检索到的能力。f1 得分同时兼顾了 precision 和 recall,其计算公式是。macro指在多分类情况下各类的均值。
[0043]
为了验证本发明的效果,在若干个司法判决数据集上进行了实验,结果如下:为了验证本发明的效果,在若干个司法判决数据集上进行了实验,结果如下:本发明在若干个法律判决数据集的刑期和罚金预测上都取得了当前最佳的精度。相较于其他方法,有较大的性能提升。
[0044]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。