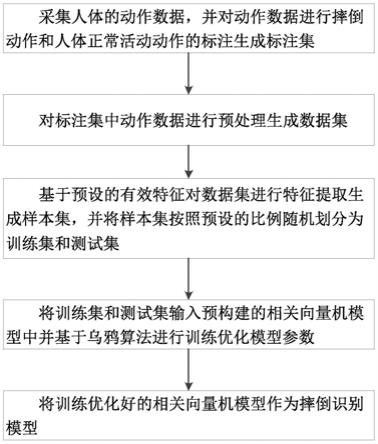
1.本发明属于石油工况诊断技术领域,具体涉及一种基于元迁移学习的小样本有杆泵井工况诊断方法。
背景技术:
2.能源在现代生活中扮演着重要的角色,被称为“工业血液”。它不仅是人们日常生活的需要,也是国民经济持续快速发展的基础支撑。因此,不断提高油气田勘探开发技术具有重要的现实意义。抽油井工况诊断技术以抽油杆柱作为井下性能的传输线,下端的泵作为发射器,上端的功率计作为接收器。井下泵的工况以声波的速度沿杆柱以应力波的形式传播到地表。对地面记录的数据进行数学处理后,可以定量推断泵的工作状况。传统方法计算较为复杂,效率较低。
3.随着近年来人工智能技术的发展,凭借智能、自动化、简单、高效的优势,利用机器学习方法解决传统工程问题越来越流行。人工神经网络具有良好的并行学习和问题处理能力,能够在解决故障诊断问题中取得良好的分类效果。而传统机器学习方法网络参数冗余,导致所需示功图样本数量过多,且诊断效率低。
技术实现要素:
4.针对传统机器学习方法网络参数冗余导致所需示功图样本数量过多的问题,本发明提出了一种基于元迁移学习的小样本有杆泵井工况诊断方法,结合迁移学习和元学习,减少运行时间,提高计算效率。
5.本发明的技术方案如下:一种基于元迁移学习的小样本有杆泵井工况诊断方法,包括以下步骤:s1.确定油田示功图任务总分布p(t)和相应的数据集d,初始化学习率和;s2.随机初始化特征提取器参数、基础学习器参数,以及缩放和位移参数;s3.进行迁移学习的预训练阶段,对数据集d中的训练样本进行误差损失验证,反向传播并优化特征提取器参数和基础学习器参数;s4.设定缩放、位移参数初始值,将设置为0,将设置为1;针对小样本数据集,重新设置基础学习器参数,进行随机初始化处理;再设定一个空数据集{m
*
}用来放置后续处理失败的任务;s5.进行元学习阶段,随机选择抽油井示功图总分布p(t)中的k个任务集;对于这k个任务,对每个任务中的样本数据进行训练,通过误差损失来优化参数,数学描述如下所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)式中,涉及多个类别,每次在新的少样本设置中进行分类;对应一个临时分类器,只适用于当前数据集,并由前几个数据集优化的初始化;为损失对的梯度求导;为在训练任务上的损失值;s6.优化缩放和位移参数,以及对学习器参数进行更新,数学描述如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)式中,为测试任务损失对进行梯度求导更新参数,i分别为1和2;根据与上述公式相同的学习率更新和优化:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)式中,为在测试任务上的损失值;s7.对参数和进行元梯度正则化处理,减少过往经验的损失与遗忘;s8.对于示功图数据集{1~m}中的第m个类别,进行分类任务识别并计算准确率;s9.进行困难任务的挑选,将失败的任务类别m
*
加入到集合{m
*
}中,将此任务集组成的新类别进行训练分析,以此来继续优化参数,和;s10.判断是否满足停止准则中规定的循环次数,如果循环迭代次数达到了设定的次数则停止迭代,并输出工况诊断最终准确率以及最优参数,否则,返回步骤s5;s11.输出训练完成具有最优参数的模型,实时监测并采集有杆泵井的数据,利用该模型进行工况的实时诊断。
6.进一步地,元迁移学习方法利用转移预训练权重的思想,利用缩放和位移操作进行传递,定义一个明确的元学习者来提取和应用预训练的有用知识来处理具有挑战性的小样本示功图分类任务;具体原理为:假设给定一个训练好的参数,对于包含k个神经元的第l层,有k对参数,分别是权重和偏差,表示为{(w
l, k
, b
l, k
)} ;基于元迁移学习,对k对标量进行学习;假设x是输入,将应用于(w, b)的数学描述如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)式中,表示元素式乘法。
7.进一步地,数据集d中,指标图主要类型分为以下几种:气体和充不满的影响;漏失的影响;柱塞卡住;井喷;抽油杆折断,部分悬吊物丢失,上下载重线不重合;其他情况,包括油井打蜡、出砂、活塞在泵筒内放置不当造成的影响。
8.进一步地,元梯度正则化处理的具体过程如下:
每个训练集部署一种简单有效的元梯度正则化方法,应用正则化来更新和;令q为当前数据集的索引;假设第r个数据集的损失值为;数学描述如下:
ꢀꢀꢀꢀꢀ
(5)
ꢀꢀꢀ
(6)式中,和是两个温度标量,用于衡量平衡当前阶段和过去阶段的元梯度的权重。
9.进一步地,步骤s8的具体过程为:使用数据之前,选择min-max标准化方法对数据集进行归一化;该方法是对原始数据进行线性变换,使结果落入区间[0,1],转换函数如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)式中,x为样本数据矩阵,max为样本数据的最大值,min为样本数据的最小值。
[0010]
进一步地,困难任务挑选阶段是对抽取训练过程中分类准确率较低的类型进行重组,得到更为复杂和困难的新数据集来强化训练效率;其具体过程如下:s901.在元训练阶段中,选择每一数据集中的失败案例,并将它们重新组合成更困难的事件以进行再训练;s902.给定一个n-way、k-shot样本任务数据集,其中一个元批次数据包含两个分割部分测试任务和训练任务,分别用于基础学习和测试;s903.基本学习器通过训练任务损失进行优化;s904.然后通过测试任务损失一次性优化ss参数;在计算损失的过程中,得到n类的识别准确率;s905.然后选择最小的准确率值acc来确定当前数据集中最困难的类;s906.在当前元批次中从数据集中选择所有失败的类{m
*
}后,从{m
*
}索引的数据中重新采样;具体来说,假设是任务分布,然后采样“困难”数据集;s907.判断新的困难任务的分类准确率是否达到设定数值,是则进行下一步,否则返回s905进行重新选择。
[0011]
进一步地,对于学习如何选择困难的任务m
*
,是通过对类级别的准确性进行排序来选择每个事件中的故障类m
*
。
[0012]
进一步地,对于使用m*处理困难任务有两种方法:直接选择当前数据集的第m*类的样本,或者间接使用索引m*绘制一个新的该类别的样本。
[0013]
本发明所带来的有益技术效果:
本发明提供了结合迁移学习和元学习两者优点的元迁移学习算法框架,用来解决实际油田小样本背景下有杆泵井工况诊断问题,将模型的网络参数量大大减小,实现梯度快速下降,减少模型训练运行时间,并提高模型的计算效率;利用训练好的模型进行实时工况判断,实现科学合理地诊断油井生产问题,从而显著改善油藏开发效果;本发明使用元梯度正则化策略和困难任务样本选取方法,适用于实际油田井数多但可用带诊断标签少的情况,更贴近实际油田现场的油井故障诊断情况。
附图说明
[0014]
图1是本发明有杆泵井工况诊断方法的过程流程图;图2是本发明中困难任务挑选阶段的流程图;图3是本发明实施例中利用本发明所提方法得到的工况诊断准确率曲线图;图4是本发明实施例中利用经典的densenet算法得到的工况诊断准确率曲线图;图5是本发明实施例中得到的整个类别示功图的p-r曲线图;图6是本发明实施例中得到的整个类别示功图的roc曲线图;图7是本发明实施例中得到的缩放参数-频数曲线图;图8是本发明实施例中得到的位移参数-频数曲线图。
具体实施方式
[0015]
下面结合附图以及具体实施方式对本发明作进一步详细说明:人工神经网络具有良好的并行学习和问题处理能力,能够在解决故障诊断问题中取得良好的分类效果。本发明公开的元迁移学习方法结合了迁移学习和元学习的优点,可以很好地处理小样本学习任务。根据采集到的油田实际指标图曲线数据,对模型进行训练和验证。许多油田数据可以归类为小样本,通过机器学习方法解决这一任务,是未来研究的方向。该方法由三个主要训练阶段组成,以获得具有少量样本的有效分类器。首先,模型在大数据集上训练深度神经网络,然后将卷积层固定为特征提取器。其次,在元迁移学习阶段,本元迁移学习了特征提取器神经元的缩放和位移参数,使其快速适应小样本集。为了提高整体学习效率,网络在元训练阶段应用了混合元批处理和元梯度正则化。
[0016]
在预训练期间,模型将所有数据d结合起来,并使用交叉熵函数来训练多样本多类模型。该模型由特征提取器和多类分类器组成。参数在接下来的元训练和元测试阶段保持不变。多类分类器被丢弃,因为小样本数据集包含不同的分类目标。这里元迁移学习仅通过困难的元批量训练来优化元操作的缩放和转移。ss(缩放和位移)操作的参数表示为和,在学习过程中不改变冻结层神经网络参数,而微调(ft)改变了所有的参数。
[0017]
典型的指标图是指对某一因素影响非常明显的指标图,其形状代表了该因素影响下的基本特征;本数据集中指标图的主要类型分为以下几种:气体和充不满的影响,这种情况是由于明显的气体影响或下沉太小,供油不足,使液体无法充满工作缸;漏失的影响,包括消除部分漏失和吸入部分漏失;柱塞卡住,指柱塞卡在泵筒内某一位置,使柱塞不能移动,抽油杆受拉变形;
井喷,指具有井喷能力的抽油井在抽油过程中,液柱载荷不能加到悬浮点的情况;抽油杆折断,部分悬吊物丢失,上下载重线不重合;其他情况,包括油井打蜡、出砂、活塞在泵筒内放置不当造成的影响。
[0018]
本发明所提出的元迁移学习方法利用了转移预训练权重的思想,利用缩放和位移操作进行传递,与传统微调ft方法不同,本方法定义了一个明确的元学习者来提取和应用预训练的有用知识来处理具有挑战性的小样本示功图分类任务。具体原理为:假设给定一个训练好的参数,对于包含k个神经元的第l层,有k对参数,分别是权重和偏差,可以表示为{(w
l, k
, b
l, k
)} ;基于元迁移学习,对k对标量进行学习。假设x是输入,将应用于(w, b)的数学描述如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)式中,表示元素式乘法。
[0019]
如图1所示,一种基于元迁移学习的小样本有杆泵井工况诊断方法,包括以下步骤:s1.确定油田示功图任务总分布p(t)和相应的数据集d,初始化学习率和;s2.随机初始化特征提取器参数、基础学习器参数,以及缩放和位移参数;s3.首先进行迁移学习的预训练阶段,对数据集d中的训练样本进行误差损失验证,反向传播并优化特征提取器参数和基础学习器参数;s4.随后设定缩放、位移参数初始值,选择将设置为0,将设置为1;针对小样本数据集,重新设置基础学习器参数,进行随机初始化处理;再设定一个空数据集{m
*
}用来放置后续处理失败的任务,称为困难任务集;s5.接着进行元学习阶段,随机选择抽油井示功图总分布p(t)中的k个任务集;对于这k个任务,对每个任务中的样本数据进行训练,通过误差损失来优化参数,数学描述如下所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)式中,涉及多个类别,例如5个类别,每次在新的少样本设置中进行分类;对应一个临时分类器,它只适用于当前数据集,并由前几个数据集优化的初始化;为损失对的梯度求导;为在训练任务上的损失值;s6.优化缩放和位移参数,以及对学习器参数进行更新,数学描述如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
式中,为测试任务损失对进行梯度求导更新参数,i分别为1和2;在接下来的步骤中,根据与上述公式相同的学习率更新和优化:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)式中,为在测试任务上的损失值;能够发现上面的来自于基本学习器的最后一个迭代过程;本方法所采用的缩放和位移参数ss与传统微调不同,单独设定一个学习器学习预训练所得良好初始化参数;s7.对参数和进行元梯度正则化处理,减少过往经验的损失与遗忘;元梯度正则化处理具体如下:为了进一步减少“灾难性遗忘”问题,每个训练集部署了一种简单有效的元梯度正则化方法,应用正则化来更新和;令q为当前数据集的索引;假设第r个数据集的损失值为;数学描述如下:
ꢀꢀꢀꢀ
(5)
ꢀꢀꢀ
(6)式中,和是两个温度标量,用于衡量平衡当前阶段和过去阶段的元梯度的权重。
[0020]
s8.对于示功图数据集{1~m}中的第m个类别,进行分类任务识别并计算准确率;具体实现为:使用数据之前,对数据集进行归一化,这里选择min-max标准化方法;该方法是对原始数据进行线性变换,使结果落入区间[0,1],转换函数如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)式中,x为样本数据矩阵,max为样本数据的最大值,min为样本数据的最小值。
[0021]
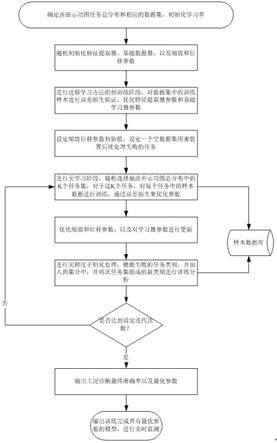
s9.进行困难任务的挑选,即将失败的任务类别m
*
加入到集合{m
*
}中,将此任务集组成的新类别进行训练分析,以此来继续优化参数,和;困难任务挑选阶段的过程如图2所示,其实质是对抽取训练过程中分类准确率较低的类型进行重组,得到更为复杂和困难的新数据集来强化训练效率;其具体实施步骤为:s901.传统的元批次是由随机采样的数据集组成,其中随机性也意味着随机性很难;在元训练阶段中,选择每一数据集中的失败案例,并将它们重新组合成更困难的事件以进行再训练;s902.给定一个n-way、k-shot样本任务数据集,其中一个元批次数据包含两个分割部分测试任务和训练任务,分别用于基础学习和测试;
s903.基本学习器通过训练任务损失(在多次迭代中)进行优化;s904.然后通过测试任务损失一次性优化ss参数;在计算损失的过程中,可以得到n类的识别准确率;s905.然后选择最小的准确率值acc来确定当前数据集中最困难的类(也称为失败类);s906.在当前元批次中从数据集中选择所有失败的类{m
*
}后,从{m
*
}索引的数据中重新采样;具体来说,假设是任务分布,然后采样“困难”数据集;s907.判断新的困难任务的分类准确率是否达到设定数值,是则进行下一步,否则返回s905进行重新选择。
[0022]
关于困难任务数据集的抽样方法,给出两个重要的细节说明如下:对于学习如何选择困难的任务m
*
,本发明不是固定阈值,而是通过对类级别的准确性进行排序来选择每个事件中的故障类m
*
。在像这样的动态在线环境中,基于排序选择困难任务而不是提前设置阈值更为明智;对于使用m
*
处理困难任务有两种方法。假设困难任务为假设困难任务为,选择{m
*
},可以通过以下方式对进行重采样:直接选择当前数据集的第m
*
类的样本,或者间接使用索引m
*
绘制一个新的该类别的样本。本方法认为第m
*
个类别包含更多的数据方差。
[0023]
s10.判断是否满足停止准则中规定的循环次数,如果循环迭代次数达到了设定的次数则停止迭代,并输出工况诊断最终准确率以及最优参数,否则,返回步骤s5。
[0024]
s11.输出训练完成具有最优参数的模型,实时监测并采集有杆泵井的数据,利用该模型进行工况的实时诊断。
[0025]
实施例为了证明本发明所提方法的可行性与优越性,以某油田实际示功图数据为例对所提出的技术方案进行测试,并与流行的机器学习模型densenet进行对比分析。选择基准数据集miniimagenet和油田指标图曲线数据作为实验数据集进行实验。其中,miniimagenet广泛应用于机器学习相关工作中,具有普遍性;而油田实际指标图曲线数据结合现场生产情况,从油田一线数据中采样,具有实用性。miniimagenet 是专门为评估less-shot学习而提出的。它包含100个类别,共60000张彩色图片,每张图片有600个样本,每张图片的大小为84
×
84。一般来说,这个数据集的训练集和测试集占比为8:2。对于指标图的图像类别,模型选择 miniimagenet 数据集中的非动物图像作为预训练数据集,以学习更好的预训练参数。
[0026]
选取某油田的实际抽油井数据,包括该井的相关数据、光杆位移、负荷随时间变化、日产液量、最大负荷等,找到对应的指标图曲线数据点,选为样本,共得到8134个样本。初步筛选可以获得8000个可用样本。编写程序,将每个工况问题的样本进行分离,可以得到30种类型的样本。
[0027]
接下来给出特征提取器参数、具有缩放和移位(ss)参数、和元迁移基本学习器(分类器)参数的元学习器的网络架构。对于,模型采用了两种更深层次的架构:resnet-18、resnet-25和wrn-28-10。网络使用resnet-25和wrn-28-10来实现非常高的性能。具体来说,4conv由4层3
×
3卷积和32个滤波器组成,然后进行批量归一化、relu非线性处理、2
×
2最大池化。
[0028]
然后按照下面的步骤进行油田工况诊断方案的制定。
[0029]
s1:收集实际示功图数据集d共8000个样本,对应分布p(t)类别数为5类。设定初始学习率和为0.01,神经网络最大循环迭代次数为100次;s2:随机初始化特征提取器,基础学习器,默认值为0,设计(基本学习器的参数)的架构,单个fc层(作为)比多层训练更快,并且分类也更有效,而更改为多层时性能下降。对于和的架构,它们是根据的架构生成的;s3:进行预训练阶段,模型由adam优化器训练。优化器的学习率初始化为0.1,每30次迭代衰减20%,直到小于0.005;将损失的保留概率设置为0.9,批量大小为64;对于超参数,随机选择5个样本作为训练集,其余作为验证集。在网格搜索超参数之后,开始修改,然后混合所有样本(48个类,每类600个样本)进行最终的预训练。这些图像样本数量可以通过水平翻转等方式增加;s4:设置缩放与位移参数和,其中设为0,设为1。重置基础学习器参数,并设置元学习器,即神经网络来学习初期预训练初始化成果,由adam优化器进行优化。它的学习率初始化为 0.001,每千次迭代衰减一半,直到0.0001。由于内存限制,元匹配的大小设置为2批次集。设定空数据集{m
*
}以回收后续处理失败的任务样本;s5:进行元训练阶段,这是一个任务级别的训练,其中将任务中的基本学习视为优化基础学习器的训练步骤,然后是优化元学习器的验证步骤。基础学习器通过批量梯度下降进行优化,由每个训练任务中的训练样本损失反向传播来优化参数;s6:优化缩放和位移参数,并对基础学习器参数进行更新。两者都是通过测试任务数据集对各自参数进行梯度迭代优化,并且学习率都为,数值等于0.01;s7:进行参数和的元梯度正则化处理,每次模型部署前8批次集来计算元梯度并将温度标量和设置为1.0;s8:示功图数据集{1~m}中的第m个类别,计算相应类别准确率。根据收集得到的示功图曲线数据,需要提取关键特征点来绘制真实的井下指标图。根据给定的散点位置进行判断,找出位于四个顶角的点作为上下死点和关键点位,保证曲线闭合得到曲线数据。使用数据之前进行归一化处理,选择min-max标准化。该方法是对原始数据进行线性变换,使结果落入区间[0,1];s9:进行困难任务的挑选。设置困难任务示功图各类别样本选取方式,每次运行10个元批次处理后,就会对困难任务进行采样,即用于困难任务采样的失败类别来自20个批
次集合,因为每个元批处理包含2个批次。通过验证选择不同设置的困难任务数量:在miniimagenet 数据集上,分别选择10和4个困难任务进行1次和5次实验。将失败的任务类别m
*
加入到集合{m
*
}中,然后组成新的类别,继续优化模型参数;s10:判断是否达到规定的循环次数。如果达到设定的循环次数,那么训练阶段完成,模型将学习新的指标图分类任务,达到少量样本的高效分类的目标,并从准确率、p-r曲线、roc曲线和混淆矩阵等指标来评估实验结果,否则返回s5;s11:最后输出并保存训练的最优参数的模型,在油田实时监测并采集有杆泵系统的载荷和位移数据,并利用最优模型进行工况的实时诊断。
[0030]
图3和图4分别为使用本发明所提出方法(元迁移学习)和现有流行的机器学习模型densenet通过实验进行的应用实例工况诊断准确率结果对比图,横坐标为神经网络循环迭代的次数,纵坐标为当前实验得到的示功图分类准确率(即准确度)。由图3可以看出,本发明在20次迭代训练阶段内,模型准确率上升迅速,梯度下降速度快,在30次循环迭代完成后即达到平衡,最终优化得到的识别准确率高。而由图4可以看出,使用经典的densenet算法优化时收敛缓慢,50次循环迭代后仍未收敛,且相比本发明的优化结果最终得到的准确率明显较低。因此本发明具有较高的运行效率和计算精度来完成油井故障诊断。
[0031]
图5为本发明实验得到的整个类别示功图的p-r曲线图,图6为实验得到的整个类别示功图的roc曲线图。
[0032]
通过实验得到如表1所示的油田有杆泵井工况诊断各类别的混淆矩阵。
[0033]
表1 油田有杆泵井工况诊断各类别的混淆矩阵图7和图8分别为实验得到的缩放、位移参数与频数的关系曲线图。如图5所示,p-r曲线代表分类器将正确样本判断为正样本的概率,说明本发明在设定的迭代次数内拥有很好的区分负样本的能力,从而提高分辨效率。auc是roc曲线下的面积。这个区域的值在0到1之间,可以直观的评价分类器的好坏。auc的值越大,分类器的效果越好。根据图6、表1可以看出,本发明auc的值为0.93,分类器的分类效果相当不错,再加上混淆矩阵明显看出各个类型分类效果,从而大大降低工况诊断有误的概率。如图7和图8所示,通过缩放和位移操作,本发明的神经网络成功将预训练的成果学得,指导后续元学习阶段,效果理想。
[0034]
通过应用实例中采用现有技术优化后的油田实际示功图分类准确率图,与采用流行的卷积神经网络结构效果图,对比可以看出,本发明实验后所得到的故障诊断效果可以很好地改善小样本下识别判定的稳定性,实验准确率和工作效率得到明显提高。
[0035]
目前由于各大油田大都进入到了高含水开发阶段,现场油井数量众多,日常巡检任务困难,而恶劣天气时工况问题更是愈发频繁。怎样减轻油田负担,利用少量监测得到的
油井诊断样本数据解决整个区块工况诊断成为急需解决的问题。检测不准的原因是缺乏先进的机器学习算法来指导现场诊断作业。因此需要通过研究高水平理论方法不断实现分类问题准确率的突破。本发明展示了使用困难元批量学习课程训练的新 mtl 模型在解决抽油杆索引图分类问题时取得了非常好的效果,这表明该模型在处理抽油井故障方面的性能诊断非常好。事实证明,mtl 在预训练的dnn 神经元上的关键操作对于让元学习器体验新的指标图分类任务非常有效。本模型使用miniimagenet标准数据集进行迁移学习,然后使用ss操作学习少量参数的迁移知识,然后进入元学习阶段测试和评估实验效果。在实验过程中,网络通过硬任务元批处理策略对数据进行批处理,并使用元正则化处理。实验结果表明,元迁移学习方法对于解决少量样本下的抽油杆指示图分类问题非常有效,这也说明它对于解决实际油田条件诊断问题具有一定的优势。
[0036]
综上所述,本发明结合迁移学习和元学习两者性能的优点,通过使用在相关数据集上的预训练所得良好的网络初始化参数,再利用元学习特有的超参数自动学习,实现梯度快速下降,减少运行时间,提高计算效率。元迁移学习方法在小样本多任务的设计原则上能够将模型的网络参数量大大减小,从而应对样本量较少的油田故障诊断问题。同时本发明的方法,除了判别有杆泵抽油井问题类型,还可以用于优化井网井位、油藏工作制度调整等。
[0037]
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。