1.本发明属于电子系统故障诊断技术领域,更为具体地讲,涉及一种考虑测试不确定性的电路测点优选方法。
背景技术:
2.随着信息技术的发展,电子系统复杂程度越来越高,通过选取最优化的测点来满足复杂的测试需求,是当前故障诊断领域的重要内容。然而,由于实际测试环境中存在各种干扰等外界因素,会造成测试数据的不完全可靠,导致实际测试数据带有很多不确定性,给系统的测试性设计与分析带来了极大困难,如何针对测试不确定条件下进行测点的最优选取成为故障诊断领域的难题之一。
3.当前,针对测试可靠条件下的测试优选方案已经研究了很多,但在考虑测试不确定条件下的测点优选,目前还没有深入的研究。在满足隔离率和检测率的条件下,如何尽可能优选测点以减小测试代价、虚警率以及漏检率,从而以最可靠和最经济的方式满足装备系统的测试诊断需求,是本方法需要解决的问题。
技术实现要素:
4.本发明的目的在于克服现有技术的不足,提供一种考虑测试不确定性的电路测点优选方法,在满足隔离率和检测率的条件下,获得多组优选后的测点。
5.为实现上述发明目的,本发明为一种考虑测试不确定性的电路测点优选方法,其特征在于,包括以下步骤:
6.(1)、构建测试不确定性的多信号模型h={f,t,d,p,c,pf};
7.其中,f表示待测电路出现的各种故障集,f={f1,f2,
…
,fi,
…
,fm},fi表示第i中故障,m为故障总数;t表示待测电路的所有可用测点集,t={t1,t2,
…
,tj,
…
,tn},tj表示第j个可用测点,n为可用测点总数;p表示待测电路发生某个故障的先验概率集,p={p1,p2,
…
,pi,
…
,pm},pi表示出现故障si的先验概率;c表示与t对应的测试代价集,c={c1,c2,
…
,cj,
…
,cn},cj表示测试tj的代价;d为测点存在不确定性下的依赖矩阵,具体表示为:
[0008][0009]
其中,d
ij
表示故障fi在可用测点tj下的测试信息,d
ij
=0或d
ij
=1,当d
ij
=0时,表示待测电路中发生故障fi时不能通过可用测点tj检测出来;当d
ij
=1时,表示待测电路中发生故障fi时能够通过可用测点tj检测出来;
[0010]
pf为测点测试的虚警率矩阵,具体表示为:
[0011][0012]
其中,pf
ij
表示测点tj对于故障tj的测试虚警率;
[0013]
(2)、利用基于拥挤距离排序的多目标粒子群算法对测试不确定性模型进行测点优选;
[0014]
(2.1)、设置多目标粒子群算法中粒子k的位置表示为(2.1)、设置多目标粒子群算法中粒子k的位置表示为的取值0或1,当时,代表测点tj被选中,当时,代表测点tj未被选中,其中j∈[1,n];
[0015]
(2.2)、构建由测试成本、漏检率和虚警率构成的优化目标函数;
[0016]
测试成本:
[0017]
漏检率:
[0018]
虚警率:
[0019]
(2.3)、构建由检测率和隔离率构成的约束条件;
[0020]
检测率:
[0021]
隔离率:
[0022]
设置最低检测率λ0和隔离率λ1,则检测率ψ
fd
(x)≥λ0,隔离率ψ
fi
(x)≥λ1;
[0023]
(2.4)、基于拥挤距离排序的多目标粒子群算法对待测电路进行测点优选;
[0024]
(2.4.1)、初始化一个由q个粒子组存的粒子群p,每个粒子的维度均为n维,每个粒子的初始速度为0,其中,第k个粒子的速度表示为:第k个粒子的初始位置表示为k∈[1,q],j∈[1,n];
[0025]
设置多目标粒子群算法的最大迭代次数t,当前迭代次数t∈[1,t],初始化t=1;
[0026]
设置外部存档库rep,其大小为r,r>q;初始化rep为空集;
[0027]
设置数组pbest,大小为q
×
n,pbest的每一行用于记录每次迭代后各粒子的历史最优值对应位置,其中,第t次迭代后第k行记为:
pbest存储每个粒子的历史最优值对应位置;
[0028]
设置数组gbest,大小为1
×
n,用于记录每次迭代后粒子群的全局最优值对应位置,其中,第t次迭代后的全局最优值记为g为q个粒子中历史最优值最优对应的粒子;
[0029]
(2.4.2)、更新第t次迭代后各粒子的速度及位置;
[0030]
更新各粒子的速度:
[0031]vk
(t)=w
×vk
(t-1) r1a1(pk(t-1)-xk(t-1)) a2r2(pg(t-1)-xk(t-1))
[0032]
其中,w为惯性因子,r1,r2为(0,1)范围内变化的随机数,a1,a2是加速因子;
[0033]
更新各粒子的位置:
[0034][0035]
当xk(t)中的时,则否则rand()产生一个(0,1)之间的随机数;
[0036]
(2.4.3)、计算第t次迭代后的适应度值和约束值;
[0037]
将第t次迭代后每个粒子的位置带入目标函数c(x)、l(x)、a(x),得到各个粒子的适应度值,其中,第k个粒子的适应度值记为适应度值,其中,第k个粒子的适应度值记为分别对应c(x)、l(x)、a(x)得到计算值;
[0038]
将第t次迭代后每个粒子的位置代入约束条件ψ
fd
(x)、ψ
fi
(x),得到各个粒子的约束值,其中,第k个粒子的约束值记为束值,其中,第k个粒子的约束值记为分别对应ψ
fd
(x)、ψ
fi
(x)得到计算值;
[0039]
(2.4.4)、更新第t次迭代后各粒子的历史最优值位置及粒子群的全局最优值位置;
[0040]
更新各粒子的历史最优值位置:将各粒子在第t次迭代后的适应度值fk(t)与pbest中存储的位置对应的历史最优适应度值进行比较,如果fk(t)大于历史最优适应度值,则对pbest中对应的历史最优值位置进行替换,否则保持不变;
[0041]
更新粒子群的全局最优值位置:第t次迭代后,在各粒子中选取最大的适应度值,记为fg(t),再与gbest存储的位置对应的全局最优值进行比较,如果fg(t)大于全局最优值,则对gbest中全局最优值位置进行替换,否则保持不变;
[0042]
(2.4.5)、拥挤距离的计算;
[0043]
(2.4.5.1)、提取第t次迭代后各粒子的适应度值然后对同一目标函数下得到的q组适应度值进行降序排列;
[0044]
(2.4.5.2)、计算第t次迭代后各粒子的拥挤距离distk(t);
[0045][0046]
其中,第k个粒子在目标函数c(x)下得到的拥挤距离为其中,第k个粒子在目标函数c(x)下得到的拥挤距离为和同理可得;
[0047]
(2.4.6)、对各粒子进行存档;
[0048]
提取外部存档库rep中存储的各粒子,再与第t次迭代后的各粒子按照拥挤距离大小进行降序排列;然后再读取外部存档库rep的内存大小,判断外部存档库rep剩余的内存大小是否大于粒子总数量q,如果大于,则将排序后的各粒子按序存储在外部存档库rep中;否则,选取拥挤距离最大的r个粒子并按序存储在外部存档库rep中;
[0049]
(2.4.7)、输出优选测点;
[0050]
判断当前迭代次数t是否达到最大迭代次数t,如果t<t,则将当前迭代次数t加1,再返回步骤(2.4.2),继续下一轮迭代;否则退出循环,从外部存档rep中输出r个粒子,每个粒子的位置代表一个优选测点。
[0051]
本发明的发明目的是这样实现的:
[0052]
本发明一种考虑测试不确定性的电路测点优选方法,通过构建测试不确定性的多信号模型,并给出该模型下由隔离率、检测率、测试代价、虚警率以及漏检率的优化目标函数和约束条件,然后利用多目标粒子群算法以测试代价,虚警率,漏检率作为优化目标,检测率、隔离率作为约束条件进行多目标优化,最终得到多组优选后的测点选择方案。
[0053]
同时,本发明一种考虑测试不确定性的电路测点优选方法还具有以下有益效果:
[0054]
(1)、本发明在进行优化是以测试代价、虚警率以及漏检率为目标函数,以隔离率、检测率为约束条件,使得优选的测点不会出现虚警率以及漏检率高的情况,更符合实际应用。
[0055]
(2)、本发明利用基于拥挤距离的二进制多目标粒子群算法进行不可靠测试条件下的测点优选,采用拥挤距离进行存档,使得该方法不容易陷入局部最优,而能够尽可能多的找到全局最优的方案;
[0056]
(3)、对比其它优化算法如nsga
‑ⅱ
、模拟退火粒子群算法,本发明优化结果更优,更有利于找到最优的测试方案。
附图说明
[0057]
图1是本发明一种考虑测试不确定性的电路测点优选方法流程图;
[0058]
图2基于拥挤距离排序的多目标粒子群算法对待测电路进行测点优选的流程图;
[0059]
图3是优选测点的示意图。
具体实施方式
[0060]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0061]
实施例
[0062]
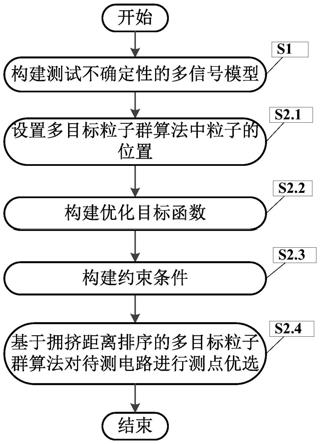
图1是本发明一种考虑测试不确定性的电路测点优选方法流程图。
[0063]
在本实施例中,如图1所示,本发明一种考虑测试不确定性的电路测点优选方法,包括以下步骤:
[0064]
s1、构建测试不确定性的多信号模型h={f,t,d,p,c,pf};
[0065]
其中,f表示待测电路出现的各种故障集,f={f1,f2,
…
,fi,
…
,fm},fi表示第i中故障,m为故障总数;t表示待测电路的所有可用测点集,t={t1,t2,
…
,tj,
…
,tn},tj表示第j个
可用测点,n为可用测点总数;p表示待测电路发生某个故障的先验概率集,p={p1,p2,
…
,pi,
…
,pm},pi表示出现故障si的先验概率;c表示与t对应的测试代价集,c={c1,c2,
…
,cj,
…
,cn},cj表示测试tj的代价;d为测点存在不确定性下的依赖矩阵,具体表示为:
[0066][0067]
其中,d
ij
表示故障fi在可用测点tj下的测试信息,d
ij
=0或d
ij
=1,当d
ij
=0时,表示待测电路中发生故障fi时不能通过可用测点tj检测出来;当d
ij
=1时,表示待测电路中发生故障fi时能够通过可用测点tj检测出来;
[0068]
pf为测点测试的虚警率矩阵,具体表示为:
[0069][0070]
其中,pf
ij
表示测点tj对于故障tj的测试虚警率;
[0071]
在本实施例中,测试数据来源于:翟禹尧、史贤俊、杨帅、秦玉峰;不可靠测试条件下基于nsga
‑ⅱ
的多目标测试优化选择[j].北京航空航天大学学报,2021,47(04):792-801.);共计m=15种故障、n=20个测点,各个参数如表1-表4所示;
[0072]
表1:故障的先验故障概率
[0073][0074]
表2:测点测代价
[0075]
测点t1t2t3t4t5t6t7t8t9t
10
成本606612060529050602036测点t
11
t
12
t
13
t
14
t
15
t
16
t
17
t
18
t
19
t
20
成本718368030604592030
[0076]
表3:测点不完全可靠下的电路可靠概率(%)
[0077][0078][0079]
表4:测试不可靠下的测点虚警率表(%)
[0080][0081][0082]
s2、利用基于拥挤距离排序的多目标粒子群算法对测试不确定性模型进行测点优选;
[0083]
s2.1、设置多目标粒子群算法中粒子k的位置表示为s2.1、设置多目标粒子群算法中粒子k的位置表示为的取值0或1,当时,代表测点tj被选中,当时,代表测点tj未被选中,其中j∈[1,n];
[0084]
s2.2、构建由测试成本、漏检率和虚警率构成的优化目标函数;
[0085]
测试成本:
[0086]
漏检率:
[0087]
虚警率:
[0088]
s2.3、构建由检测率和隔离率构成的约束条件;
[0089]
检测率:
[0090]
隔离率:
[0091]
设置最低检测率λ0和隔离率λ1,则检测率ψ
fd
(x)≥λ0,隔离率ψ
fi
(x)≥λ1;
[0092]
s2.4、基于拥挤距离排序的多目标粒子群算法对待测电路进行测点优选,如图2所示,具体步骤如下:
[0093]
s2.4.1、初始化一个由q=500个粒子组存的粒子群p,每个粒子的维度均为n维,每个粒子的初始速度为0,其中,第k个粒子的速度表示为:第k个粒子的初始位置表示为k∈[1,q],j∈[1,n];
[0094]
设置多目标粒子群算法的最大迭代次数t=100,当前迭代次数t∈[1,t],初始化t=1;
[0095]
设置外部存档库rep,其大小为r=500,r>q;初始化rep为空集;
[0096]
设置数组pbest,大小为q
×
n,pbest的每一行用于记录每次迭代后各粒子的历史最优值对应位置,其中,第t次迭代后第k行记为:pbest存储每个粒子的历史最优值对应位置;
[0097]
设置数组gbest,大小为1
×
n,用于记录每次迭代后粒子群的全局最优值对应位置,其中,第t次迭代后的全局最优值记为g为q个粒子中历史最优值最优对应的粒子;
[0098]
s2.4.2、更新第t次迭代后各粒子的速度及位置;
[0099]
更新各粒子的速度:
[0100]vk
(t)=w
×vk
(t-1) r1a1(pk(t-1)-xk(t-1)) a2r2(pg(t-1)-xk(t-1))
[0101]
其中,w为惯性因子,取值为0.4;r1、r2为(0,1)范围内变化的随机数;a1、a2为加速系数,取值都为2;
[0102]
更新各粒子的位置:
[0103][0104]
当xk(t)中的时,则否则rand()产生一个(0,1)之间的随机数;
[0105]
s2.4.3、计算第t次迭代后的适应度值和约束值;
[0106]
将第t次迭代后每个粒子的位置带入目标函数c(x)、l(x)、a(x),得到各个粒子的适应度值,其中,第k个粒子的适应度值记为适应度值,其中,第k个粒子的适应度值记为分别对应c(x)、l(x)、a(x)得到计算值;
[0107]
将第t次迭代后每个粒子的位置代入约束条件ψ
fd
(x)、ψ
fi
(x),得到各个粒子的约束值,其中,第k个粒子的约束值记为束值,其中,第k个粒子的约束值记为分别对应ψ
fd
(x)、ψ
fi
(x)得到计算值;
[0108]
s2.4.4、更新第t次迭代后各粒子的历史最优值位置及粒子群的全局最优值位置;
[0109]
更新各粒子的历史最优值位置:将各粒子在第t次迭代后的适应度值fk(t)与pbest中存储的位置对应的历史最优适应度值进行比较,如果fk(t)大于历史最优适应度值,则对pbest中对应的历史最优值位置进行替换,否则保持不变;
[0110]
更新粒子群的全局最优值位置:第t次迭代后,在各粒子中选取最大的适应度值,记为fg(t),再与gbest存储的位置对应的全局最优值进行比较,如果fg(t)大于全局最优值,则对gbest中全局最优值位置进行替换,否则保持不变;
[0111]
s2.4.5、拥挤距离的计算;
[0112]
s2.4.5.1、提取第t次迭代后各粒子的适应度值然后对同一目标函数下得到的q组适应度值进行降序排列;
[0113]
s2.4.5.2、计算第t次迭代后各粒子的拥挤距离distk(t);
[0114][0115]
其中,第k个粒子在目标函数c(x)下得到的拥挤距离为其中,第k个粒子在目标函数c(x)下得到的拥挤距离为和同理可得;
[0116]
s2.4.6、对各粒子进行存档;
[0117]
提取外部存档库rep中存储的各粒子,再与第t次迭代后的各粒子按照拥挤距离大小进行降序排列;然后再读取外部存档库rep的内存大小,判断外部存档库rep剩余的内存大小是否大于粒子总数量q,如果大于,则将排序后的各粒子按序存储在外部存档库rep中;否则,选取拥挤距离最大的r个粒子并按序存储在外部存档库rep中,采用这种存档方式的好处在于,能够尽可能广的找到可能的优选结果,而不是使得所有的优选结果集中于某一处,即不会陷入局部最优,能够在全局找到尽可能多的优选解;
[0118]
s2.4.7、输出优选测点;
[0119]
判断当前迭代次数t是否达到最大迭代次数t,如果t<t,则将当前迭代次数t加1,再返回步骤s2.4.2,继续下一轮迭代;否则退出循环,从外部存档rep中输出r个粒子,每个粒子的位置代表一个优选测点方案,且拥挤距离最大则对应粒子的位置作为优选测点的优先级越高。
[0120]
最终得到的测试优选结果如图3所示,再从中选取的部分测点优化组合如表5所示:
[0121]
表5优化结果中的四种最优组合
[0122] 测点组合成本漏检率虚警率
成本最优{1,1,0,0,0,0,0,0,1,1,1,1,1,0,1,0,1,1,1,0}3470.12%1.07%漏检率最低{1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,1,1}4420.016%0.98%虚警率最低{1,1,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0}4580.016%0.78%综合最优{1,1,0,0,0,0,0,0,1,1,1,1,1,0,1,1,1,1,0,0}3870.016%0.88%
[0123]
通过表5可以看出,该方法能够在满足检测率和隔离率的前提下,使测试成本、漏检率、虚警率尽可能的低,并优化出多种方案供我们选择。我们可以按需求选择符合要求的测试方案。
[0124]
综述本发明以测试代价、虚警率以及漏检率为目标函数,综合三方面进行优化,使三个目标方向都尽量地的小,通过表5可以发现,即使选择最低成本,漏检率和虚警率也不会过高。
[0125]
通过图3可以发现,本发明的优化结果并没有集中于一个局部,而是较广的分布,这就算采用基于拥挤距离进行存档的好处,使得优化结果不会陷入局部最优。
[0126]
表6三种方法下的综合最优对比
[0127][0128]
从表6中可以看出,对比三种方法的综合最优,本发明具有明显的优势,特别是在漏检率的优化上,本发明比nsga
‑ⅱ
和模拟退火粒子群算法优势更明显。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。