1.本发明涉及人工智能中自然语言处理技术领域,具体而言涉及一种基于混合格自注意力网络的命名实体识别方法和装置。
背景技术:
2.命名实体识别(ner)也叫实体抽取,最早是在muc-6会议上提出,它是信息抽取技术中从文本抽取实体的技术。早期的实体识别采用基于规则和基于统计等方法,由于这些传统方法过于依赖人工的设计,且识别的覆盖率小、识别精度低,早已经被深度学习方法取代。在基于深度学习的方法中,实体识别模型分为基于字的模型(character-based)和基于词的模型(word-based),英文等其他一些语言通常采用基于字的模型,因为每个单词都有明确的含义;汉语中字的含义是模糊的,而词的含义是具体的,所以中文ner方法中采用基于词的模型。为了更好的表示中文中每个字向量,后来有学者提出了基于表示学习的方法,它是一种将人类语言信息转换为机器能识别的特征的学习方式,能够提升机器学习中语义表达的准确性。
3.在命名实体识别方法中,外部的词汇信息能够有效的提升识别的精度,但是这些方法依赖于融合算法的性能。例如,专利号为cn113836930a的发明中提出一种中文危险化学品命名实体识别方法,在bilstm-crf模型的基础上,利用预训练语言模型bert获取危险化学品领域的文本字符级别编码,得到基于上下文信息的字向量,然后引入注意力机制,增强模型挖掘文本的全局和局部特征的能力。专利号为cn113128232a的发明中提出一种基于albert与多重词信息嵌入的命名实体识别方法,可以有效的表征字的多义性,提升实体识别的效率。专利号为cn111310470a的发明公开了一种融合字词特征的中文命名实体识别方法,通过综合分析后得到的结果数据加强了模型对文本的理解,提高了模型识别任务中的f1值。
4.虽然现有的方法在融合词特征向量上已经取得了不错的效果,但现有的技术手段中存在的问题有:1)字词特征融合方法没有考虑到不同模型训练的字词向量在语义表达上存在差异性,直接空洞地将二者进行融合,不能有效的增强字向量的词级特征;2)在基于学习词权重的词汇增强方法中,只考虑了每个字特征的匹配词对字语义表示的影响,忽略了全局词汇信息的作用。
技术实现要素:
5.本发明针对现有技术中的不足,提供一种基于混合格自注意力网络的命名实体识别方法和装置,基于表示学习的思想,所提出的模型能够融合词汇信息,以此来增强字向量的特征表示,使得生成的字向量中包含了更多的实体边界信息,从而能够提升ner任务的准确性。
6.为实现上述目的,本发明采用以下技术方案:
7.一种基于混合格自注意力网络的命名实体识别方法,所述命名实体识别方法包括
以下步骤:
8.s1,在词典中查找输入句子中由连续个字组成的词,通过位置交替映射合并成一个单独的多维向量,采用混合字词格编码的方式将字词对表示的句子特征向量编码为一个维度固定的矩阵,得到相应的混合格结构的字词向量表示;
9.s2,基于步骤s1中生成的混合格结构的字词向量,构造相应的自注意力网络以捕获该向量中词向量对字向量的影响,以此来增强每个字向量的特征表示;
10.s3,在bert的embedding层融合词特征,通过微调学习过程,学习得到更好的字向量表示;依据bilstm-crf网络实现实体识别中的实体序列标注任务和解码过程,通过该网络完成对融合后字特征的建模,构建完成基于混合格自注意力网络的实体识别模型;
11.s4,在数据集上对基于混合格自注意力网络的实体识别模型进行训练。
12.为优化上述技术方案,采取的具体措施还包括:
13.进一步地,步骤s1中,采用混合字词格编码的方式将字词对表示的句子特征向量编码为一个维度固定的矩阵,得到相应的混合格结构的字词向量表示的过程包括以下步骤:
14.s11,给定一个句子sc={c1,c2,
…
,cn},通过加载预训练的bert权重,得到句子sc的字特征向量表示其中ci表示sc中的第i个字,n表示s的字数长度,eb表示bert预训练字向量的查找表;
15.s12,给定一个中文词典l,构造trie字典树,遍历该树的节点,得到每个字所匹配到的词汇;
16.s13,将所有匹配到的词汇按照bmes标记分组,即对于字符ci,词集b(ci)由以它开头的匹配词组成,集合m(ci)由ci为其内部字的匹配词组成,集合e(ci)由以ci结尾的匹配词组成,集合s(ci)由ci的单字符词组成;句子sc中每个字ci的词集wi表示为:
17.wi={ew(b(ci)),ew(m(ci)),ew(e(ci)),ew(s(ci))};
18.其中ew表示预训练的词向量查找表;
19.s14,设置两层可学习的非线性全连接层将wi的维度升至和字向量一致,bert在微调的时候,对这两层权重进行学习,使预训练的词特征向量映射到bert的语义特征空间;处理后的词特征向量表示如下:
[0020][0021]
其中w1∈(dc×
dc),w2∈(dc×dw
)是可学习的权重矩阵,b1和b2是对应的偏置,dc表示bert字向量的维度,dw表示预训练词向量的维度;
[0022]
s15,将转换后的词特征向量作为特征融合模型的输入,按照字和词集的对应关系,将每个字-词对特征表示为:
[0023][0024]
s16,将字-词对的特征表示如下:
[0025][0026]
其中表示向量拼接符。
[0027]
进一步地,步骤s2中,基于步骤s1中生成的混合格结构的字词向量,构造相应的自
注意力网络以捕获该向量中词向量对字向量的影响,以此来增强每个字向量的特征表示的过程包括以下步骤:
[0028]
s21,设计mixed-lattice自注意力网络来捕获字词特征间的关联,自注意力网络将混合字词编码向量v
me
和词位置屏蔽矩阵m作为增强网络的输入,通过该自注意力网络对全局的词向量和字向量的建模,使模型学习到词和字间的词义相关性权重,q、k、v矩阵的计算如下:
[0029]
[q,k,v]=[w
qvme
,w
kvme
,w
vvme
];
[0030]
其中是可学习的权重矩阵,且de=dc dw;q、k、v矩阵分别为查询项矩阵、查询项对应的键项矩阵和待加权平均的值项矩阵;de表示mixed-lattice向量的维度、dc表示字向量的维度、dw词向量的维度;
[0031]
s22,将点积运算作为相似性分数的计算公式:
[0032][0033]fatt
=softmax(s
att
εm)v;
[0034]
其中m是静态的词位置屏蔽矩阵,ε是一个值为无穷小的矩阵,是自注意力网络的输出;其中s
att
表示归一化后的注意力得分、k
t
表示矩阵k的转置;
[0035]
s23,将词特征信息作为残差加入到bert预训练字向量中,得到的词汇增强字特征向量为:
[0036]c′
=c g(f
att
);
[0037]
其中表示bert的预训练字向量特征,函数g(*)用于移除self-attention网络中的词向量通道来保证c和f
att
向量维度的一致性,得到词汇增强后的字嵌入向量c
′
。
[0038]
进一步地,步骤s3中,构建完成基于混合格自注意力网络的实体识别模型的过程包括以下步骤:
[0039]
s31,给定一个长度为n的句子序列sc={c1,c2,
…
,cn},经过词汇增强后的字向量表示为c
′
={c
′1,c
′2,
…
,c
′n},在bert模型中微调字向量c
′
,词汇增强后的bert字嵌入向量表示为:
[0040]e′i=c
′i es(i) e
p
(i);
[0041]
其中es和e
p
分别表示分隔向量和位置向量查找表;i表示长度为n的字符序列sc中的第i个字符;
[0042]
s32,将得到的e
′
输入到bert中,每个transformer块的计算公式如下:
[0043]
d=ln(h
k-1
mha(h
k-1
);
[0044]hk
=ln(ffn(d) d);
[0045]
其中hk表示第k层的隐状态输出,h0=e
′
表示底层的字向量;ln是层归一化函数;mha是多头自注意力模块;ffn表示两层的前馈神经网络;d表示多头注意力模块归一化后的输出向量;
[0046]
s33,获得最后一层transformer的隐状态输出向量将输入到一个双向的lstm网络中,分别从句子的左到右和右到左捕捉语义信息;前向的lstm网络
的隐状态输出表示为后向的lstm网络的输出为bi-lstm网络的输出是sequence-labeling层的输出,表示为:
[0047][0048]
其中hi表示第i个bi-lstms神经元的级联隐状态输出,用来表示ci的字符级上下文语义表示;
[0049]
s34,使用标准的crf层来预测ner标签,给定网络最后一层的隐状态输出向量h={h1,h2,
…
,hn},假如y={y1,y2,
…
,yn}表示标签序列,对于一个句子s={s1,s2,
…
,sn},其对应的标签序列的概率定义如下:
[0050][0051]
其中y
′
表示所有标签序列中任意一个标签序列;表示对应于yi的网络中可学习的权重参数;表示对应于y
i-1
和yi之间的偏置量;同样地,分别表示在任意可能的标签y
′
下的模型权重参数和偏置量;
[0052]
s35,将负对数似然损失作为模型的损失函数,表示为:
[0053][0054]
基于前述命名实体识别方法,本发明提出一种基于混合格自注意力网络的命名实体识别装置,所述命名实体识别装置包括混合格结构编码模块、词汇增强模块、序列标注和解码模块,以及模型训练模块;
[0055]
所述混合格结构编码模块用于在词典中查找输入句子中由连续个字组成的词,通过位置交替映射合并成一个单独的多维向量,采用混合字词格编码的方式将字词对表示的句子特征向量编码为一个维度固定的矩阵,得到相应的混合格结构的字词向量表示;
[0056]
所述词汇增强模块用于基于生成的混合格结构的字词向量,构造相应的自注意力网络以捕获该向量中词向量对字向量的影响,以此来增强每个字向量的特征表示;
[0057]
所述序列标注和解码模块用于在bert的embedding层融合词特征,通过微调学习过程,学习得到更好的字向量表示;依据bilstm-crf网络实现实体识别中的实体序列标注任务和解码过程,通过该网络完成对融合后字特征的建模,构建完成基于混合格自注意力网络的实体识别模型;
[0058]
所述模型训练模块用于在数据集上对基于混合格自注意力网络的实体识别模型进行训练。
[0059]
本发明的有益效果是:
[0060]
本发明的基于混合格自注意力网络的命名实体识别方法和装置,通过构建融合网络,捕获了全局的词汇信息,生成了语义丰富的字向量表示,在多个数据集上提升了中文命名实体识别的精度。相比于未使用词汇增强网络的bert基准模型,该发明在四个数据集上分别有4.55%、0.54%、1.82%和0.91%的性能提升,这说明通过词汇增强技术提升字向量的特征表示是一种有效提升中ner性能的方法。同时对比于其他词汇增强方法,本发明所提出的特征融合框架(melsn)能够有效的融合更丰富的词汇语义特征,借助预训练模型bert
的微调机制,词汇增强后的字特征表示包含更多的词汇语义。对比实验结果表明,本发明可以更好地利用字-词格结构实现词汇增强,也说明本发明提出的方法在中文命名实体识别任务上的高效性。
附图说明
[0061]
图1是本发明的基于混合格自注意力网络的命名实体识别装置的结构示意图。
具体实施方式
[0062]
现在结合附图对本发明作进一步详细的说明。
[0063]
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
[0064]
本发明提及一种基于混合格自注意力网络的命名实体识别方法,该命名实体识别方法包括以下步骤:
[0065]
s1,在词典中查找输入句子中由连续个字组成的词,通过位置交替映射合并成一个单独的多维向量,采用混合字词格编码的方式将字词对表示的句子特征向量编码为一个维度固定的矩阵,得到相应的混合格结构的字词向量表示。
[0066]
s2,基于步骤s1中生成的混合格结构的字词向量,构造相应的自注意力网络以捕获该向量中词向量对字向量的影响,以此来增强每个字向量的特征表示。
[0067]
s3,在bert的embedding层融合词特征,通过微调学习过程,学习得到更好的字向量表示;依据bilstm-crf网络实现实体识别中的实体序列标注任务和解码过程,通过该网络完成对融合后字特征的建模,构建完成基于混合格自注意力网络的实体识别模型。
[0068]
s4,在数据集上对基于混合格自注意力网络的实体识别模型进行训练。
[0069]
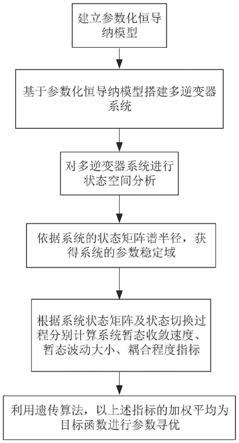
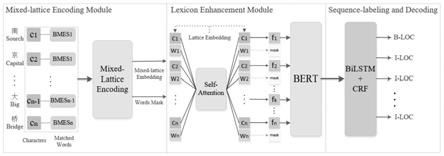
基于前述方法,本实施例还提及一种基于混合格自注意力网络的命名实体识别装置。图1是本发明的基于混合格自注意力网络的命名实体识别装置的结构示意图。整个架构分为三个部分:混合格结构编码模块(mixed-lattice encoding module)、词汇增强模块(lexicon enhancement module)、序列标注和解码模块(sequence-labeling and decoding)。在第一个模块完成字-词对向量的编码,即搜索词典树中所有的词,并加载预训练的字、词向量,然后将字-词对向量编码成混合格嵌入向量(mixed-lattice embedding),和该阶段生成的词遮盖向量(words mask)一同传送到下一个模块;第二个模块中通过提出的自注意力模型实现词汇增强过程,增强后的字向量表示被传入bert模型中进行微调;最后一个模块根据增强和微调后的字向量进行建模,完成每个字向量的标签预测和解码过程。
[0070]
本发明提出了一种基于词汇增强的命名实体识别方法,模型是基于bert-bilstm-crf网络改进的,该方法在bert的embedding层增加了基于attention网络的词汇增强模块;我们对于字词对向量进行编码,设计了一种交差排列的字词向量编码方式,通过attention网络完成词汇增强后,融合特征进行归一化之后以残差的方式加入原来的bert字向量。本发明的具体实施过程如下:
[0071]
步骤1:混合格结构的字词向量构造
[0072]
混合字词格(mixed-lattice)编码的作用是将字词对表示的句子特征向量编码为一个维度固定的矩阵。首先在词典中查找输入句子中由连续个字组成的词,然后再通过位置交替映射合并成一个单独的多维向量。
[0073]
具体的,给定一个句子sc={c1,c2,
…
,cn},通过加载预训练的bert权重,可以直接得到句子sc的字特征向量表示其中ci表示sc中的第i个字,n表示s的字数长度,eb表示bert预训练字向量的查找表。给定一个中文词典l,首先构造trie字典树,遍历该树的节点,可以得到每个字所匹配到的词汇。将所有匹配到的词汇按照“bmes”标记分组,即对于字符ci,词集b(ci)由以它开头的匹配词组成。类似地,集合m(ci)由ci为其内部字的匹配词组成,集合e(ci)由以ci结尾的匹配词组成,集合s(ci)由ci的单字符词组成,所以句子sc中每个字ci的词集wi可以表示为:
[0074]
wi={ew(b(ci)),ew(m(ci)),ew(e(ci)),ew(s(ci))};
[0075]
其中ew表示预训练的词向量查找表。为了保证向量维度的一致,设置了两层可学习的非线性全连接层将wi的维度升至和字向量一致,bert在微调的时候,对这两层权重进行学习,能够使预训练的词特征向量映射到bert的语义特征空间。处理后的词特征向量表示如下:
[0076][0077]
其中w1∈(dc×
dc),w2∈(dc×dw
)是可学习的权重矩阵,b1和b2是对应的偏置。dc表示bert字向量的维度、dw表示预训练词向量的维度。在我们的特征融合方法中,转换后的词特征向量作为特征融合模型的输入。按照字和词集的对应关系,可以将每个字-词对特征表示为:
[0078][0079]
目前很多基于词汇融合的ner方法直接将字-词对特征ii作为词汇增强网络的输入,这种方法只能融合局部的词汇信息,在实验中我们发现在句子sc中,其他字的匹配词也包含着丰富的词汇语义,为了使模型能够捕获全局的词级特征,本实施例提出了一种新的字-词对编码方式,即字-词混合格编码(mixed-lattice embedding),字-词对的特征表示如下:
[0080][0081]
其中表示向量拼接符,基于该编码方法,字词向量交叉编码成一个固定维度的特征向量,在该方法中,词向量排列越近,与字的关联性越高,这也与实际相符合。在下一阶段,本实施例构造了基于attention机制的融合网络,来对字-词对特征表示v
me
进行建模。
[0082]
步骤2:词特征融合网络的计算过程
[0083]
词汇增强网络的作用是建模字-词特征表示向量v
me
,用词特征来增强序列中字向量的特征表示。基于vaswani等人提出的注意力机制的设计思想,设计了mixed-lattice self-attention的网络来捕获字词特征间的关联。在前一阶段,我们已经得到了编码字词对的混合格向量表示v
me
,这种lattice的结构将字和词向量紧密的组织成一个多维度向量。字和词特征交叉分布在该embedding中,self-attention网络将v
me
和词位置屏蔽矩阵m作为增强网络的输入,通过该自注意力网络的建模,模型能够学习到词和字间的词义相关性权
重。给定一句话的混合字词编码向量v
me
和m矩阵,q、k、v矩阵的计算如下:
[0084]
[q,k,v]=[w
qvme
,w
kvme
,w
vvme
];
[0085]
其中是可学习的权重矩阵,且de=dc dw,然后将点积运算作为相似性分数的计算公式:
[0086][0087]fatt
=softmax(s
att
εm)v;
[0088]
其中m是静态的词位置屏蔽矩阵,ε是一个值为无穷小的矩阵,是self-attention网络的输出。将m点乘一个无穷小的矩阵来屏蔽所以词位置上得到的注意力得分。经过softmax函数的计算,词位置的概率全为零,而字符所在的位置包含了每个词的权重分数。在self-attention网络中利用词位置mask的方法完成字词特征的融合。
[0089]
经过以上的过程,能够实现词特征的融入,词特征信息作为残差加入到bert预训练字向量中,最终得到的词汇增强字特征向量为:
[0090]c′
=c g(f
att
);
[0091]
其中表示bert的预训练字向量特征,使用函数g(*)来移除self-attention网络中的词向量通道来保证c和f
att
向量维度的一致性,从而得到了词汇增强后的字嵌入向量c
′
。
[0092]
基于以上的过程,对字-词对向量进行了重新编码、利用特殊的自注意力网络对全局的词向量和字向量进行建模,得到了融合后的字特征向量,实现了全局词特征信息的融合。
[0093]
步骤3:构造命名实体识别模型
[0094]
1)bert结构的计算过程
[0095]
本实施例是基于bert-bilstm网络的改进,对bert的embedding层做了特征增强,提出了embedding层融入词特征的机制。在步骤2中,得到了经过词汇增强后的字向量表示c
′
,给定一个长度为n的句子序列sc={c1,c2,
…
,cn},接下来在bert模型中微调字向量c
′
,词汇增强后的bert字嵌入向量可以表示为:
[0096]e′i=c
′i es(i) e
p(i)[0097]
其中es和e
p
分别表示分隔向量和位置向量查找表,然后将得到的e
′
输入到bert中,每个transformer块的计算公式如下:
[0098]
d=ln(h
k-1
mha(h
k-1
)
[0099]hk
=ln(ffn(d) d)
[0100]
其中hk表示第k层的隐状态输出(h0=e
′
表示底层的字向量);ln是层归一化函数;mha是多头自注意力模块;ffn表示两层的前馈神经网络。最后获得了最后一层transformer的隐状态输出向量将该向量输出到后续的序列标注和解码任务。
[0101]
2)lstm网络的计算过程
[0102]
微调后混合格嵌入向量已经包含了词级别的语义信息,由于在字词融合过程中,更关注于字与词之间的词义信息关联,为了捕捉句子中字与字之间的全局语义信息,更好的提升ner的性能,采用大多数ner模型常用的做法,即用bilstm作为本实施例模型的序列
标注层。给定一个句子sc={c1,c2,
…
,cn},在前述步骤,已经得到了词汇增强后的字符特征表示c
′
={c
′1,c
′2,
…
,c
′n},和经过bert微调后的隐状态输出矩阵将输入到一个双向的lstm网络中,这种网络能够分别从句子的左到右和右到左捕捉语义信息。
[0103]
前向的lstm网络的隐状态输出可以表示为同样的后向的lstm网络的输出为因此bi-lstm网络的输出的就是sequence-labeling层的输出,它可以表示为:
[0104][0105]
其中hi表示第i个bi-lstms神经元的级联隐状态输出,我们用它来表示ci的字符级上下文语义表示。
[0106]
3)crf网络的解码过程
[0107]
在模型经过序列标注层的计算之后,使用标准的crf层来预测ner标签。给定网络最后一层的隐状态输出向量h={h1,h2,
…
,hn},假如y={y1,y2,
…
,yn}表示标签序列,对于一个句子s={s1,s2,
…
,sn},其对应的标签序列的概率定义如下:
[0108][0109]
其中y
′
表示所有标签序列中任意一个标签序列;表示对应于yi的网络中可学习的权重参数;表示对应于y
i-1
和yi之间的偏置量。将负对数似然损失作为模型的损失函数,其可以表示为:
[0110][0111]
步骤4:模型学习过程
[0112]
本实施例所提出的方法在四个公开数据上分别训练,模型通过优化上述的负对数似然损失来使模型收敛。模型使用了warmup的学习率更新策略,bert模型参数使用了1e-5的学习率,微调过程很小的学习率就能使模型快速收敛;对于lstm模型的参数,使用了1e-3的学习率,此外对其他所有的参数设置了1e-4的学习率。四个数据集上,模型在20个epoch内均能收敛。在msra数据集上使用了v100显卡进行实验的,其他数据集均在1080ti显卡上进行。在实验中发现,不同的机器上的结果存在一定的差异,所以实验结果是取多次实验结果的平均值。
[0113]
本实施例在四个公开的中文命名实体识别数据集上进行评测,与其他模型进行效果比较,通过表格展示数据来说明发明的效果。
[0114]
数据集介绍:
[0115]
weibo数据集是从新浪微博网站收集的社交媒体公开数据集,包含四种实体类型:地名、人名、组织和政治相关的实体名。resume数据集同样来自新浪社交媒体数据,是关于财务简历数据。msra和ontonotes4数据集来源于公众新闻领域,包含训练数据的真实标签。这些数据集的统计信息如表1所示。
[0116]
表1数据集的统计信息表
[0117][0118]
度量指标:
[0119]
这里使用分类模型常用的衡量指标,即f1值来比较其他模型和本发明的识别准确率。首先介绍计算f1值的一些前置条件:tp,即true positives,表示样本被分为正样本且分配正确;tn,即true negatives,表示样本被分为样本且分配正确;fp,即false positives,表示样本被分为正样本但分配错误;fn,即false negatives,表示样本被分为负样本但分配错误。precision,即精度,表示被正确分配的正样本数占总分配的正样本数的比例,公式为:
[0120][0121]
recall,即召回率,表示被正确分配的正样本数占总正样本数的比例,公式为:
[0122][0123]
f1-score又称f1分数,是分类问题的一个衡量指标,常作为多分类问题的最终指标,它是精度和召回率的调和平均数。对于单个类别的f1分数,可使用如下公式计算
[0124][0125]
效果说明:
[0126]
四个数据上的f1值如下表所示。本实施例不仅对比了使用bert预训练字向量的方法,也对比了其他的经典词汇增强sota方法。在保证使用同样的预训练字向量和词向量的基础上,本实施例所提出的方法在四个公开数据集weibo、resume、msra、ontonote4上的f1值分别达到了71.88%、96.22%、95.72%和81.75%的表现。与经典中文ner模型lattice-lstm、lr-cnn和flat上的表现相比,本实施例提出的方法在四个数据集上分别取得了8.46%、0.69%、5%和1.37%的提升。相比于使用bert预训练字向量的ner模型,如softlexicon-bert、flat-bert、lebert等模型,在resume、msra和onnote4数据集上,本实施例所提出的方法实现了0.28%、0.12%和0.41%的轻微改进,但是在weibo数据集上的f1分数显著优于softlexicon bert模型,提高了1.64%。本实施例是基于bert-bilstm改进的,相比于未使用词汇增强网络的bert基准模型,本实施例在四个数据集上分别有4.55%、0.54%、1.82%和0.91%的性能提升,这说明通过词汇增强技术提升字向量的特征表示是一种有效提升中ner性能的方法。同时对比于其他词汇增强方法,本实施例所提出的特征融合框架(melsn)能够有效的融合更丰富的词汇语义特征,借助预训练模型bert的微调机制,词汇增强后的字特征表示包含更多的词汇语义。参见表2,对比实验结果表明,本实施例可以更好地利用字-词格结构实现词汇增强,也说明本实施例提出的方法在中文命名实体识别任务上的高效性。
[0127]
表2对比实验结果表
[0128][0129]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。