1.本技术涉及智能医疗技术领域,更具体地涉及一种病历质检方法、 装置和存储介质。
背景技术:
2.drgs(diagnosis related groups,疾病诊断相关分组)付费是医 保支付改革的重要手段,其基本思路是根据住院病历的病案首页中的 主要诊断、其他诊断、主要手术、其他手术以及患者的基本信息,为 疾病分到诊断相关分组。根据每个组预设的权重系数,乘上预先制定 的费率,就是医保报销的金额。
[0003][0004][0005]
针对诊断多写的质检问题,现有的主流方法是依靠人工质检,原 因是该任务整体上还是比较难的,需要对各类疾病的症状、检查检验、 用药、手术等情况都有基本的认识,还需要翻阅整本住院病历,核查 前后情况,才能得出结论。因此现行质检手段基本是通过科室内三级 诊疗法内部检查,即主治医师、主任医师或副主任医师、科室主任逐 级检查,或者是医院质检科的质检人员进行专门核查。
[0006]
人工质检的缺点是显而易见的,首先因为住院病历内容非常多, 因此平均执行一份病历的诊断多写质检大概需要20分钟;其次是需 要质检人对各个科室的疾病都能有基本的了解和认识,因为合并症和 并发症可能脱离于患者所住科室,因此需要质检人员对全科疾病都有 基本认识;最后人工质检容易造成相互包庇的行为,例如若医院主导 的质检,很有可能医生到科室到质检员层级都会有纵容包庇的行为, 反而不客观真实。
技术实现要素:
[0007]
为了解决上述问题而提出的了本技术。根据本技术一方面,提供 了一种病历质检方法,所述方法包括:获取待检病历,所述待检病历 包括病历内容和诊断结果,所述诊断结果包括至少一种疾病的名称; 针对所述病历内容提取特征,得到第一特征;针对所述诊断结果中包 括的每种疾病,获取所述疾病对应的典型病历的特征,得到第二特征; 针对所述诊断结果中包括的每种疾病,将所述疾病对应的典型病历的 所述第二特征与所述第一特征进行相似度计算,以确定所述疾病是否 与所述病历内容相关,从而确定所述诊断结果中是否包括与所述病历 内容不相关的疾病名称。
[0008]
在本技术的一个实施例中所述获取所述疾病对应的典型病历的 特征,得到第二特征,包括:获取所述疾病对应的多个典型病历各自 的特征,得到多个第二特征;所述将所述疾病对应的典型病历的所述 第二特征与所述第一特征进行相似度计算,以确定所述疾病是否与所 述病历内容相关,包括:将所述第一特征与每个所述第二特征进行相 似度计算,得到多个相似度得分;计算所述多个相似度得分的平均值 和/或获取所述多个相似度得分中的最大值;当所述平均值大于第一 阈值和/或所述最大值大于第二阈值时,确定所
述疾病与所述病历内 容相关。
[0009]
在本技术的一个实施例中所述方法是基于训练好的神经网络来 执行的,所述神经网络为自监督学习和有监督学习联合训练的端到端 框架,所述自监督学习包括典型病历的特征学习,所述有监督学习包 括典型病历与非典型病历之间的特征相似度学习。
[0010]
在本技术的一个实施例中所述神经网络采用焦点损失函数(focalloss)来实现所述联合训练,其中所述焦点损失函数是基于所述自监 督学习和所述有监督学习这两者各自的损失函数和这两者各自的性 能指标而设计的。
[0011]
在本技术的一个实施例中所述自监督学习的训练集包括原始样 本、正样本和负样本,其中:所述原始样本包括典型病历样本;所述 正样本包括所述典型病历样本的复制样本;所述负样本包括与所述典 型病历样本对应不同疾病的其他典型病历样本的随机采样样本。
[0012]
在本技术的一个实施例中,所述原始样本与所述正样本构成正相 关表证对,所述原始样本与所述负样本构成负相关表正对;所述自监 督学习的损失函数是基于如下原则设计的:使得所述正相关表证对的 表征距离越来越近,所述负相关表征对的表征距离越来越远;所述自 监督学习的性能指标包括所述原始样本与所述正样本的相似度得分 减去所述原始样本与所述负样本的相似度得分的结果。
[0013]
在本技术的一个实施例中所述神经网络为带随机丢弃(dropout) 机制的神经网络,所述典型病历样本和所述典型病历样本的复制样本 分别输入到所述神经网络,基于所述随机丢弃机制,得到所述原始样 本和所述正样本。
[0014]
在本技术的一个实施例中所述非典型病历对应多种疾病,作为多 个标签,所述有监督学习将所述多种疾病中每种疾病对应的所述典型 病历的原始样本与所述非典型病历的样本进行特征相似性计算,得到 所述非典型病历的样本对应的疾病类型的预测结果;所述有监督学习 的损失函数是基于如下原则设计的:针对所述多个标签中的每个标签: 当所述预测结果正确时,生成第一损失函数值;当所述预测结果错误 时,生成第二损失函数值,所有损失函数值加权求和以用于更新所述 神经网络的参数,其中所述第一损失函数值小于所述第二损失函数值。
[0015]
在本技术的一个实施例中所述神经网络为图神经网络,所述图神 经网络基于如下方式为所述病历内容构图:预处理得到所述病历内容 的特征单词,将特征单词表示为节点,将所述特征单词之间的共现关 系表示边,通过点互信息计算得到边上权重,从而得到所述病历内容 的带权图。
[0016]
根据本技术另一方面,提供了一种病历质检方法,所述方法包括: 获取待检病历,并将所述待检病历输入到训练好的神经网络,其中, 所述待检病历包括病历内容和诊断结果,所述诊断结果包括至少一种 疾病的名称;所述神经网络为自监督学习和有监督学习联合训练的端 到端框架,所述自监督学习包括典型病历的特征学习,所述有监督学 习包括典型病历与非典型病历之间的特征相似度学习;基于所述神经 网络针对所述病历内容提取特征,并针对所述诊断结果中包括的每种 疾病,将所述疾病对应的典型病历的特征与所述病历内容的特征进行 相似度计算,以确定所述疾病是否与所述病历内容相关,从而确定所 述诊断结果中是否包括与所述病历内容不相关的疾病名称。
[0017]
在本技术的一个实施例中,所述神经网络采用焦点损失函数 (focal loss)来实
现所述联合训练,其中所述焦点损失函数是基于所 述自监督学习和所述有监督学习这两者各自的损失函数和这两者各 自的性能指标而设计的。
[0018]
根据本技术再一方面,提供了一种病历质检装置,所述装置包括: 病历获取模块,用于获取待检病历,所述待检病历包括病历内容和诊 断结果,所述诊断结果包括至少一种疾病的名称;特征提取模块,用 于针对所述病历内容提取特征,得到第一特征;相似性计算模块,用 于针对所述诊断结果中包括的每种疾病,获取所述疾病对应的典型病 历的特征,得到第二特征;并针对所述诊断结果中包括的每种疾病, 将所述疾病对应的典型病历的所述第二特征与所述第一特征进行相 似度计算,以确定所述疾病是否与所述病历内容相关,从而确定所述 诊断结果中是否包括与所述病历内容不相关的疾病名称。
[0019]
根据本技术又一方面,提供了一种病历质检装置,所述装置包括: 输入模块,用于获取待检病历,并将所述待检病历输入到训练好的神 经网络,其中,所述待检病历包括病历内容和诊断结果,所述诊断结 果包括至少一种疾病的名称;所述神经网络为自监督学习和有监督学 习联合训练的端到端框架,所述自监督学习包括典型病历的特征学习, 所述有监督学习包括典型病历与非典型病历之间的特征相似度学习; 输出模块,用于基于所述神经网络针对所述病历内容提取特征,并针 对所述诊断结果中包括的每种疾病,将所述疾病对应的典型病历的特 征与所述病历内容的特征进行相似度计算,以确定所述疾病是否与所 述病历内容相关,从而确定所述诊断结果中是否包括与所述病历内容 不相关的疾病名称。
[0020]
根据本技术再一方面,提供了一种病历质检装置,所述装置包括 存储器和处理器,所述存储器上存储有由所述处理器运行的计算机程 序,所述计算机程序在被所述处理器运行时,使得所述处理器执行上 述病历质检方法。
[0021]
根据本技术又一方面,提供了一种存储介质,所述存储介质上存 储有计算机程序,所述计算机程序在运行时,执行上述病历质检方法。
[0022]
根据本技术实施例的病历质检方法和装置以待检病历中的原始 诊断结果为依据,获取原始诊断结果中包括的疾病的典型病历,将其 与待检病历上的病历内容进行相似性比对,根据比对结果能够确定原 始诊断结果中包括的疾病是否与病历内容相关,从而能够自动判断诊 断多写情况。
附图说明
[0023]
通过结合附图对本技术实施例进行更详细的描述,本技术的上述 以及其他目的、特征和优势将变得更加明显。附图用来提供对本技术 实施例的进一步理解,并且构成说明书的一部分,与本技术实施例一 起用于解释本技术,并不构成对本技术的限制。在附图中,相同的参 考标号通常代表相同部件或步骤。
[0024]
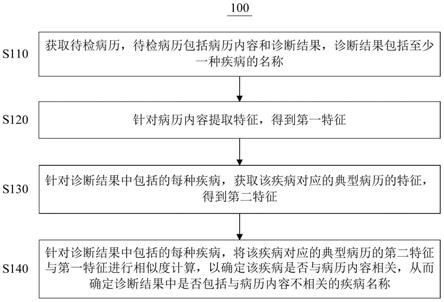
图1示出根据本技术一个实施例的病历质检方法的示意性流程 图。
[0025]
图2示出根据本技术实施例的病历质检方法中采用的神经网络 的训练过程示意图。
[0026]
图3示出采用根据本技术实施例的病历质检方法对病历进行质 检后得到的结果示意图。
[0027]
图4示出根据本技术另一个实施例的病历质检方法的示意性流 程图。
[0028]
图5示出根据本技术一个实施例的病历质检装置的示意性结构 框图。
[0029]
图6示出根据本技术另一个实施例的病历质检装置的示意性结 构框图。
[0030]
图7示出根据本技术再一个实施例的病历质检装置的示意性结 构框图。
具体实施方式
[0031]
为了使得本技术的目的、技术方案和优点更为明显,下面将参照 附图详细描述根据本技术的示例实施例。显然,所描述的实施例仅仅 是本技术的一部分实施例,而不是本技术的全部实施例,应理解,本 申请不受这里描述的示例实施例的限制。基于本技术中描述的本技术 实施例,本领域技术人员在没有付出创造性劳动的情况下所得到的所 有其他实施例都应落入本技术的保护范围之内。
[0032]
首先,参照图1描述根据本技术一个实施例的病历质检方法。图 1示出了根据本技术一个实施例的病历质检方法100的示意性流程图。 如图1所示,病历质检方法100可以包括如下步骤:
[0033]
在步骤s110,获取待检病历,待检病历包括病历内容和诊断结 果,诊断结果包括至少一种疾病的名称。
[0034]
在步骤s120,针对病历内容提取特征,得到第一特征。
[0035]
在步骤s130,针对诊断结果中包括的每种疾病,获取该疾病对 应的典型病历的特征,得到第二特征。
[0036]
在步骤s140,针对诊断结果中包括的每种疾病,将该疾病对应 的典型病历的第二特征与第一特征进行相似度计算,以确定该疾病是 否与病历内容相关,从而确定诊断结果中是否包括与病历内容不相关 的疾病名称。
[0037]
在本技术的实施例中,待检病历包括病历内容和诊断结果。其中, 病历内容诸如包括病人性别、年龄、主诉信息、现病史、体格检查信 息、辅助检查信息等方面的信息(如稍后结合图3描述的示例中的病 历内容部分的信息);诊断结果是医生根据病历内容作出的原始诊断, 包括病历内容将病人诊断为某种疾病或某多种疾病(如稍后结合图3 描述的示例中原始诊断部分的信息)。针对这样的待检病历,在本申 请的实施例中,以病历中的诊断结果为依据来进行质检。由于诊断结 果中包括至少一种疾病的名称,因此可以依据此来获取每种疾病的典 型病历的特征(或者也可以获取每种疾病的典型病历,然后对其提取 特征),将每种疾病的典型病历的特征依次与当前待检病历中病历内 容部分的特征进行相似性比对,即可根据相似性比对结果确定当前待 检病历中的病历内容是否符合诊断结果中每种疾病对应的典型病历 内容。例如,对于诊断结果中的一种疾病,当该种疾病的典型病历的 特征与当前待检病历中病历内容的特征相似度较高时,可认为当前待 检病历中的病历内容确实有极大概率是由该种疾病导致的,也即诊断 结果中给出的该种疾病是正确的诊断,不是误写的、多写的诊断。反 之,对于诊断结果中的一种疾病,当该种疾病的典型病历的特征与当 前待检病历中病历内容的特征相似度较低时,可认为当前待检病历中 的病历内容不太可能是由该种疾病导致的,也即诊断结果中给出的该 种疾病是误写的或者多写的诊断,可认为是诊断多写。因此,经过上 述质检过程,可判断当前待检病历中是否存在诊断多写的情况,如果 存在,可给出质检结果(例如原始诊断中某某疾病属于诊断多写情况), 还可给出诊断推荐结果(例如将诊断多写的疾病去除后保留其他诊断 结果)。
[0038]
因此,总体上,根据本技术实施例的病历质检方法以待检病历中 的原始诊断结果为依据,获取原始诊断结果中包括的疾病的典型病历, 将其与待检病历上的病历内容进行相似性比对,根据比对结果能够确 定原始诊断结果中包括的疾病是否与病历内容相关,从而能够自动判 断诊断多写情况,具有合理性高、检查速度快的优势,能够解决质检 人工少、检查速度慢的现状,开展大范围高效质检,无论是对于医保 局或卫健委等质检主导部门,还是对医院等被质检部门,都有很大的 需求,能为他们的工作开展带来大幅效率提升。
[0039]
在本技术的实施例中,可以基于训练好的神经网络来执行上述方 法100,其中,该神经网络可以为自监督学习和有监督学习联合训练 的端到端框架。自监督学习包括典型病历的特征学习,有监督学习包 括典型病历与非典型病历之间的特征相似度学习。也就是说,在本申 请的实施例中,采用一种端到端的框架,将自监督学习与有监督学习 联合训练。针对于典型病历的特征学习,采用自监督对比技术,旨在 更好的把握、刻画病历特征;针对于待检病历与典型病历之间的相关 关系,采用有监督多标签训练,两种训练方式联合开展和优化,使得 模型具有更好的表征能力和性能表现。下面分别描述该神经网络的自 监督学习和有监督学习。
[0040]
在本技术的实施例中,自监督学习任务旨在为典型病历获取更好 的特征表示,使得每份典型病历的特征都能很好地代表该典型病历对 应的疾病,这样待检病历与典型病历进行相似度计算的效果才能更准 确,以相似度高的典型病历的疾病作为待检病历的疾病预测结果,可 信度才会更高。此外,自监督训练的方法也能够提升模型建模病历文 本的能力,使得模型整体上能够具有更强的病历文本表征刻画的表现。 最后,自监督训练的方式可以是自动生成正负样本的,不需要大量人 工标注,节约人力资源。下面分别描述自监督学习中样本的构建、模 型的设计和损失函数的构建。
[0041]
首先要基于典型病历构建用于自监督对比学习的训练集。对比学 习需要针对一份病历,构造出它的正样本和负样本,才是一条完整的 可用于对比学习的样本。在本技术的实施例中,自监督学习的训练集 包括原始样本、正样本和负样本,其中:原始样本包括典型病历样本; 正样本包括典型病历样本的复制样本;负样本包括与典型病历样本对 应不同疾病的其他典型病历样本的随机采样样本。这样的方式可以自 动生成正负样本的,不需要大量人工标注,节约人力资源。
[0042]
其中,在本技术的实施例中,待训练的神经网络可以为带随机丢 弃(dropout)机制的神经网络;基于此,典型病历样本和典型病历样 本的复制样本可以分别输入到神经网络,基于神经网络的随机丢弃机 制,得到原始样本和正样本。
[0043]
也即,针对于一个典型病历的正样本的构建,可以采用将原始病 历直接复制,然后通过带有dropout机制的网络模型的方法。dropout 是指在深度学习网络的训练过程中,按照一定的概率随机将一部分神 经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦 的网络,进行网络的训练的方法,主要用于防止网络过拟合。这里我 们将一个典型病历及它的复制版本分别送入带dropout机制的网络结 构,由于每次dropout都会随机丢弃小部分神经元,所以通过网络后, 向量表征会因丢弃神经元的不同产生略微不一致的结果,而这样的结 果刚好可以一个作为原始样本,一个作为原始样本的正样本来使用。
[0044]
针对于典型病历负样本的构建,可以根据任务导向,在与典型病 历具有不同诊断
的其他疾病典型病历中,每次随机抽取一个作为该典 型病历的负样本,然后通过模型网络(即前文所述的带dropout机制 的网络模型)后,将获取的表征作为负样本结果。
[0045]
基于此,可以为已经有的所有典型病历自动快速构造出对应的正 样本和负样本,用于对比学习训练。
[0046]
在本技术的实施例中,采用的神经网络(网络模型)可以基于图 神经网络结构,图神经网络可以基于如下方式为典型病历构图:预处 理得到典型病历的特征单词,将特征单词表示为节点(节点的嵌入用 单词特征初始化),将特征单词之间的共现关系表示边(通过滑动窗 口来确定词之间的共现关系),通过点互信息(pmi)计算得到边上 权重,从而得到典型病历的带权图。然后,使用图神经网络(诸如门 控图神经网络)来学习单词节点的嵌入。节点可以从其相邻邻居接收 信息,然后与自己的表示合并以进行更新。当图层在第一阶邻居上运 行时,可以将t层堆叠t次以实现高阶特征交互,其中一个节点可以 到达距离为t的另一个节点,这里我们设置t=2,即每个节点最远可 以与自己的二阶邻居传递信息。针对于典型病历的自监督学习任务, 可以将每条样本,包含典型病历的原始样本、正样本、负样本分别构 建为图,然后为每个图都进行图卷积计算(诸如两层的图卷积计算), 分别获取典型病历的原始样本、正样本和负样本的特征表示。
[0047]
在本技术的实施例中,典型病历的原始样本与正样本构成正相关 表证对,原始样本与负样本构成负相关表正对;损失函数的设计需要 实现约束病历表征对的相关性,使得正相关表征对的表征距离越来越 近,负相关表征对的表征距离越来越远。基于此,在一个示例中,设 计如下损失函数:
[0048][0049]
其中表示这对句子表征的相似度,例如可以采用余弦相 似度公式来计算,г表示超参,表示数值缩放比例。该损失函数能够 保证:当该向量表征对越相关,损失函数越小;当向量表征对越不相 关,损失函数越大,符合我们的模型训练目标。
[0050]
以上自监督学习的描述。基于上述训练,神经网络能够很好地提 取待检病历的特征,以用于与典型病历的特征进行相似度比对,如下 文将描述的。
[0051]
在本技术的实施例中,针对于待检病历的疾病列表预测,我们采 用的方式是使待检病历与疾病对应的所有典型病历进行特征相似度 比较。在一个示例中,可以针对诊断结果中的每种疾病获取多个典型 病历,然后针对诊断结果中的每种疾病,计算待检病历的特征与该中 疾病所有典型病历的相似度得分的平均值和/或最大值。若得分越高, 说明该待检病历与该疾病对应的典型病历越相似,越倾向于该典型病 历组对应的疾病。可以通过提前制定阈值的方式,灵活把控相关度, 将高于平均阈值(可称为第一阈值,采用前述的相似度得分平均值与 其比较)或最大阈值(可称为第二阈值,采用前述的相似度得分最大 值与其比较)的疾病都作为该待检病历的可能疾病,从而组成预测疾 病列表。
[0052]
也就是说,对于前文所述的方法100中的步骤130中的获取该疾 病对应的典型病历的特征,得到第二特征,可以包括:获取该疾病对 应的多个典型病历各自的特征,得到多个第二特征。相应地,对于前 文所述的方法100中的步骤140中的将该疾病对应的典型病历
的第二 特征与第一特征进行相似度计算,以确定该疾病是否与病历内容相关, 可以包括:将第一特征与每个第二特征进行相似度计算,得到多个相 似度得分;计算多个相似度得分的平均值和/或获取多个相似度得分 中的最大值;当平均值大于第一阈值和/或最大值大于第二阈值时, 确定该疾病与病历内容相关。
[0053]
前面已经描述,在本技术的实施例中,待训练的神经网络可以为 自监督学习和有监督学习联合训练的端到端框架。自监督学习包括典 型病历的特征学习,有监督学习包括典型病历与非典型病历之间的特 征相似度学习。待检病历即为非典型病历。在训练阶段,可以采用前 文所述的图神经网络对非典型病历进行构图后经过图卷积网络(诸如 两层的图神经网络),获取该非典型病历的特征表示。之后,例如可 以利用余弦相似度方法分别计算出该非典型病历与其诊断列表对应 所有典型病历的相似度得分。
[0054]
其中,基于有监督训练进行相似度计算学习。具体地,是将非典 型病历与典型病历进行相似度计算,最终以相似度高的典型病历对应 的诊断作为非典型病历的预测诊断。因此,本质上来说还是判断非典 型病历的疾病列表(诊断结果)是否能被正确预测,所以可以看做是 多标签分类任务(非典型病历中的疾病列表中每种疾病即为一个标签, 一般典型病历对应于一种疾病,而非典型病历通常对应于多种疾病, 当然也不排除对应于单种疾病的情况)。在计算单标签分类的时候, 可以采用交叉熵损失函数,因此针对于多标签分类,可以将单标签分 类的交叉熵损失函数进行扩展,计算方法如下公式
[0055][0056]
其中m表示总的疾病个数,代表第i个样本在第j个疾病下 的真实值,代表第i个样本第j个类别下的输出经过softmax函数 处理后的结果。该公式表示,令预测结果与所有标签进行计算,生成 对应的损失函数值,再进行加权。针对于每个标签,若预测正确,则 产生较小的损失,否则,产生较大的损失函数值,再将结果加在一起。 该公式整体约束模型参数,使得模型尽量朝着所有正确标签的方向训 练,不断更新参数,获取最优模型结果。
[0057]
也就是说,在本技术的实施例中,非典型病历对应多种疾病,作 为多个标签,有监督学习将多种疾病中每种疾病对应的典型病历的原 始样本与非典型病历的样本进行特征相似性计算,得到非典型病历的 样本对应的疾病类型的预测结果。有监督学习的损失函数是基于如下 原则设计的:针对多个标签中的每个标签:当预测结果正确时,生成 第一损失函数值;当预测结果错误时,生成第二损失函数值,所有损 失函数值加权求和以用于更新神经网络的参数,其中第一损失函数值 小于第二损失函数值。
[0058]
现在描述自监督学习和有监督学习这两个任务的联合训练。
[0059]
多任务的自动训练主要是依赖损失函数的设计,而传统的多任务 联合损失函数一般是直接为每个任务的损失函数预设权重。这样虽然 能解决两个任务的损失函数不在一个量级上的问题,但是不能解决不 同任务优化速度不一致的问题。例如,若两个任务损失函数的取值范 围差异很大,一个在0-1之间,另一个在0-1000之间,通过权重预 设后,虽然表面上可以将两个损失函数的量级拉到一个水平,但是没 有考虑到不同任务优化速度差异的问题。假设一个任务的损失(loss) 很快就能降低到0-0.2之间,而另一个任务则需
要很多轮迭代loss才 能降低到0.5-0.9之间,那么虽然有预设权重,但是损失函数大的任 务仍然会对模型训练起到持续性主导作用,即模型会一直朝着这个任 务更新参数,而另一个任务得不到训练。
[0060]
基于此,在本技术的实施例中,采用焦点损失函数(focal loss) 来实现联合训练,其中focal loss是基于自监督学习和有监督学习这 两者各自的损失函数和这两者各自的性能指标而设计的。对于有监督 学习任务来说,可以将非典型病历的样本对应的疾病类型的预测结果 与其诊断列表中的疾病标签的重叠率作为性能指标。对于自监督学习 任务来说,可以将典型病历的原始样本与正样本的平均相似度减去典 型病历的原始样本与负样本的平均相似度作为性能指标,因为若典型 病历的原始样本与正样本越相关,典型病历的原始样本与负样本越不 相关,两者之间平均值的差值就会越大,符合我们的期望。获取了两 个任务分别的损失函数值和性能指标值后,可以计算focal loss,例如 通过如下公式来计算:
[0061]
fl(ki)=-((1-ki)
gamma
×
log(ki))
[0062]
loss=sum(fl(ki)
×
lossi)
[0063]
其中ki表示任务i的性能值,gamma表示超参数,例如设置为2, lossi表示任务i的损失函数值。这个公式巧妙地利用了损失函数和性 能之间的关系,即若任务的性能好,则损失函数会更小,若任务的性 能差,则损失函数会更大。通过对任务性能表现动态评估出一个损失 函数的权值,然后乘上对应的损失函数,最终将多任务加权作为最终 损失函数,实现动态量化两个任务的优化方向。若任务i的性能越好, 则其损失函数值在最终损失中的占比就越小,使得参数尽量不朝着这 个方向优化;而若任务i的性能越不好,则其在最终损失函数中的占 比就越大,使得参数朝着这个方向优化。
[0064]
通过focal loss,我们实现使用一个模型(神经网络),同时支持 典型病历的自监督对比学习以及典型病历与非典型病历的有监督学 习。通过对任务的性能和损失函数同步估算,动态决定每次迭代优先 训练哪个任务,使得两个任务能够自动同步训练,找到全局最优的模 型参数。
[0065]
以上描述了本技术中神经网络的训练过程,可结合图2来更好地 理解前文所述。
[0066]
基于上述自监督对比学习与有监督多标签分类模型同步训练的 端到端框架,在训练好实际使用时,不需要完全执行这两个目标。可 以将训练阶段最好的模型结果保存,并将最好模型参数下各个疾病的 典型病历的表征提取并保存出来。然后对于待检病历,只需要将它经 过图网络模型,然后将表征(即前文方法100中所述的第一特征)提 取出来,与典型病历的表征(即前文方法100中所述的第二特征)进 行比较即可。这种空间换时间的方法,可以使得实际应用速度更快, 而且丝毫不损失准确率。对于待检病历的诊断结果中的每种疾病,将 待检病历与该种疾病的所有典型病历的相似度结果计算后,计算出平 均值和最大值,并令他们分别与平均值阈值与最大值阈值比较,若某 一个大于阈值,则认为该典型病历对应的疾病应加入到待检病历的诊 断结果的疾病列表中;若两个指标都分别不大于相应阈值,则认为该 组典型病历对应的疾病不应加到诊断结果的疾病列表中,属于诊断多 写的情况。
[0067]
图3示出采用根据本技术实施例的病历质检方法对病历进行质 检后得到的结果示意图。如图3所示,给出了一个诊断多写质检的样 例。我们将待检病历输入到模型中,将
医生给出的四个诊断的典型病 历(失血性贫血、贵溃疡、消化道出血、十二指肠炎)抽取出来,令 待检病历与这些疾病的典型病历分别进行相似度计算,我们发现,待 检病历与失血性贫血、胃溃疡和消化道出血的典型病历都有较高的相 似性,但与十二指肠炎这一疾病的典型病历比较后,发现相似度都非 常低。基于此,我们认为十二指肠炎这一诊断为诊断多写情况,存在 质量问题(该结果经过医生验证),并给出了质检结果和诊断推荐。
[0068]
基于上面的描述,根据本技术实施例的病历质检方法以待检病历 中的原始诊断结果为依据,获取原始诊断结果中包括的疾病的典型病 历,将其与待检病历上的病历内容进行相似性比对,根据比对结果能 够确定原始诊断结果中包括的疾病是否与病历内容相关,从而能够自 动判断诊断多写情况。
[0069]
此外,根据本技术实施例的病历质检方法提出一种针对于诊断多 写自动质检的端到端计算框架,该框架利用待检病历与原始诊断对应 的典型病历比对的方法,通过综合评判,实现诊断多写的自动质检, 能够很好地替代人工进行诊断多写自动质检。因为本质上是基于多个 典型病历的相似度计算,所以整体上不会给出离谱错误的情况,所有 的预测结果都有典型病历作为证据支撑,具有一定的可解释性和性能 保证性。
[0070]
此外,根据本技术实施例的病历质检方法提出将典型病历的自监 督对比学习和非典型病历与典型病历的有监督学习联合训练,使得模 型具有更好的捕获病历中语义特征的能力,将病历的特征刻画的更好, 从而获取更好的性能结果。相比于采用两阶段实施(非联合训练)的 方法,具有避免错误传导,性能更好、速度更快的优势。
[0071]
此外,根据本技术实施例的病历质检方法提出利用dropout方法 生成典型病历的正样本的表征,该方法利用dropout机制的随机性, 巧妙地生成与原始病历高度相似的正样本,简单而有效,非常巧妙地 避免了生成正样本所面临的不合适、不恰当、效果不好的问题,dropout 天然的随机性以及比例的可调节性,使得生成的正样本更符合任务需 求,带来的性能也更好。
[0072]
此外,根据本技术实施例的病历质检方法提出运用focal-loss机 制联合训练自监督和有监督任务,使得自监督与有监督两个任务训练 的时候,能够自动平衡任务间的训练目标和方向,每次都自动朝着性 能更差的那个任务去优化,逐步迭代,最终获得两个任务的最优解而 不是单个任务的最优解,具有很好的自动纠偏能力。也即,该机制将 每个任务的性能与损失结合起来,通过性能表现导向损失函数的值, 使得性能更差的任务自动动态获得更大的损失函数,得到更针对性的 训练,避免了加权loss无法应对的多任务训练速度不一致、多任务损 失函数量级不一致的问题,能够根据不同任务的性能,动态的调节每 次训练的方向,支撑端到端的技术框架。
[0073]
此外,根据本技术实施例的病历质检方法中在有监督训练过程中, 将医生给出的诊断结果中的疾病列表作为多标签分类的真实标签,能 够避免多标签分类面临的选择标签个数的困扰;在应用于质检阶段, 将待检病历诊断结果中的疾病列表对应的典型病历内容与待检病历 文本内容进行相似度计算比对,不存在计算损失函数或性能值,因此 也不会受到无法确定标签个数的困扰。现有某些多标签分类技术中针 对每个病历样本不参考诊断结果而直接预测病历对应的疾病种类,即 存在分类个数不确定的问题,因为有些样本可能只有一个类别标签 (疾病),有些样本的类别标签可能高达十几个,如何自动确定,是 一个难点;此外,类别标签之间相互依赖难以学习到,以疾病之间关 系举例,如高血压发展
严重时会引起眼部等多个部位的并发症,因此, 如何解决类标之间的依赖性也是一个难点。而本技术的方案中不存在 这样的困扰,因为本技术的方案将医生给出的诊断结果中的疾病列表 作为多标签分类的真实标签,能够避免多标签分类面临的选择标签个 数的困扰;此外,本技术的方案中将医生给出的诊断结果中的疾病列 表作为多标签分类的真实标签,标签已经确定,无需学习标签之间的 依赖性。
[0074]
以上示例性地描述根据本技术一个实施例的病历质检方法。下面 结合图4描述根据本技术另一个实施例的病历质检方法。图4示出了 根据本技术另一个实施例的病历质检方法400的示意性流程图。如图 4所示,病历质检方法400可以包括如下步骤:
[0075]
在步骤s410,获取待检病历,并将待检病历输入到训练好的神 经网络,其中,待检病历包括病历内容和诊断结果,诊断结果包括至 少一种疾病的名称;神经网络为自监督学习和有监督学习联合训练的 端到端框架,自监督学习包括典型病历的特征学习,有监督学习包括 典型病历与非典型病历之间的特征相似度学习。
[0076]
在步骤s420,基于神经网络针对病历内容提取特征,并针对诊 断结果中包括的每种疾病,将疾病对应的典型病历的特征与病历内容 的特征进行相似度计算,以确定疾病是否与病历内容相关,从而确定 诊断结果中是否包括与病历内容不相关的疾病名称。
[0077]
根据本技术实施例的病历质检方法400与前文所述的根据本申 请实施例的病历质检方法100大体上类似,只是更强调了是由同一个 神经网络来执行方法中的步骤。前文所述的病历质检方法100可以不 是必需如此,而是只要能够实现方法100的各步骤即可,不限定是否 采用神经网络以及采用几个神经网络。本领域技术人员可以结合前文 所述理解病历质检方法400的具体操作和细节,为了简洁,此处不再 赘述。
[0078]
下面结合图5到图7描述根据本技术另一方面提供的病历质检装 置500、600和700。其中,病历质检装置500可以用于执行前文所 述的病历质检方法100;病历质检装置600可以用于执行前文所述的 病历质检方法400;病历质检装置700可以用于执行前文所述的病历 质检方法100或400。下面逐一简要描述。
[0079]
图5示出根据本技术一个实施例的病历质检装置500的示意性结 构框图。如图5所示,病历质检装置500包括病历获取模块510、特 征提取模块520和相似性计算模块530。其中,病历获取模块510用 于获取待检病历,待检病历包括病历内容和诊断结果,诊断结果包括 至少一种疾病的名称;特征提取模块520用于针对病历内容提取特征, 得到第一特征;相似性计算模块530用于针对诊断结果中包括的每种 疾病,获取疾病对应的典型病历的特征,得到第二特征;并针对诊断 结果中包括的每种疾病,将疾病对应的典型病历的第二特征与第一特 征进行相似度计算,以确定疾病是否与病历内容相关,从而确定诊断 结果中是否包括与病历内容不相关的疾病名称。根据本技术实施例的 病历质检装置500可以用于执行前文所述的病历质检方法100,本领 域技术人员可以结合前文所述理解其结构和操作,为了简洁,此处不 再赘述。
[0080]
图6示出根据本技术另一个实施例的病历质检装置600的示意性 结构框图。如图6所示,病历质检装置600包括输入模块610和输出 模块620。其中,输入模块610用于获取待检病历,并将待检病历输 入到训练好的神经网络,其中,待检病历包括病历内容和诊断结果, 诊断结果包括至少一种疾病的名称;神经网络为自监督学习和有监督 学习联合训练的端到端框架,自监督学习包括典型病历的特征学习, 有监督学习包括典型病历与非典型
病历之间的特征相似度学习。输出 模块620用于基于神经网络针对病历内容提取特征,并针对诊断结果 中包括的每种疾病,将疾病对应的典型病历的特征与病历内容的特征 进行相似度计算,以确定疾病是否与病历内容相关,从而确定诊断结 果中是否包括与病历内容不相关的疾病名称。根据本技术实施例的病 历质检装置600可以用于执行前文所述的病历质检方法400,本领域 技术人员可以结合前文所述理解其结构和操作,为了简洁,此处不再 赘述。
[0081]
图7示出根据本技术再一个实施例的病历质检装置的示意性结 构框图。如图7所示,病历质检装置700可以包括存储器710和处理 器720,存储器710存储有由处理器720运行的计算机程序,所述计 算机程序在被处理器720运行时,使得处理器720执行前文所述的根 据本技术实施例的病历质检方法100或400。本领域技术人员可以结 合前文所述的内容理解根据本技术实施例的病历质检装置700的具 体操作,为了简洁,此处不再赘述具体的细节。
[0082]
此外,根据本技术实施例,还提供了一种存储介质,在所述存储 介质上存储了程序指令,在所述程序指令被计算机或处理器运行时用 于执行本技术实施例的病历质检方法的相应步骤。所述存储介质例如 可以包括智能电话的存储卡、平板电脑的存储部件、个人计算机的硬 盘、只读存储器(rom)、可擦除可编程只读存储器(eprom)、便携式 紧致盘只读存储器(cd-rom)、usb存储器、或者上述存储介质的任 意组合。所述计算机可读存储介质可以是一个或多个计算机可读存储 介质的任意组合。
[0083]
基于上面的描述,根据本技术实施例的病历质检方法和装置以待 检病历中的原始诊断结果为依据,获取原始诊断结果中包括的疾病的 典型病历,将其与待检病历上的病历内容进行相似性比对,根据比对 结果能够确定原始诊断结果中包括的疾病是否与病历内容相关,从而 能够自动判断诊断多写情况。
[0084]
尽管这里已经参考附图描述了示例实施例,应理解上述示例实施 例仅仅是示例性的,并且不意图将本技术的范围限制于此。本领域普 通技术人员可以在其中进行各种改变和修改,而不偏离本技术的范围 和精神。所有这些改变和修改意在被包括在所附权利要求所要求的本 申请的范围之内。
[0085]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描 述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和 电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行, 取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每 个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不 应认为超出本技术的范围。
[0086]
在本技术所提供的几个实施例中,应该理解到,所揭露的设备和 方法,可以通过其他的方式实现。例如,以上所描述的设备实施例仅 仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分, 实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或 者可以集成到另一个设备,或一些特征可以忽略,或不执行。
[0087]
在此处所提供的说明书中,说明了大量具体细节。然而,能够理 解,本技术的实施例可以在没有这些具体细节的情况下实践。在一些 实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说 明书的理解。
[0088]
类似地,应当理解,为了精简本技术并帮助理解各个发明方面中 的一个或多个,
在对本技术的示例性实施例的描述中,本技术的各个 特征有时被一起分组到单个实施例、图、或者对其的描述中。然而, 并不应将该本技术的方法解释成反映如下意图:即所要求保护的本申 请要求比在每个权利要求中所明确记载的特征更多的特征。更确切地 说,如相应的权利要求书所反映的那样,其发明点在于可以用少于某 个公开的单个实施例的所有特征的特征来解决相应的技术问题。因此, 遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其 中每个权利要求本身都作为本技术的单独实施例。
[0089]
本领域的技术人员可以理解,除了特征之间相互排斥之外,可以 采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公 开的所有特征以及如此公开的任何方法或者设备的所有过程或单元 进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘 要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替 代特征来代替。
[0090]
此外,本领域的技术人员能够理解,尽管在此所述的一些实施例 包括其他实施例中所包括的某些特征而不是其他特征,但是不同实施 例的特征的组合意味着处于本技术的范围之内并且形成不同的实施 例。例如,在权利要求书中,所要求保护的实施例的任意之一都可以 以任意的组合方式来使用。
[0091]
本技术的各个部件实施例可以以硬件实现,或者以在一个或者多 个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的 技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器 (dsp)来实现根据本技术实施例的一些模块的一些或者全部功能。 本技术还可以实现为用于执行这里所描述的方法的一部分或者全部 的装置程序(例如,计算机程序和计算机程序产品)。这样的实现本 申请的程序可以存储在计算机可读介质上,或者可以具有一个或者多 个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载 体信号上提供,或者以任何其他形式提供。
[0092]
应该注意的是上述实施例对本技术进行说明而不是对本技术进 行限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下 可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参 考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权 利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排 除存在多个这样的元件。本技术可以借助于包括有若干不同元件的硬 件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权 利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。 单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词 解释为名称。
[0093]
以上所述,仅为本技术的具体实施方式或对具体实施方式的说明, 本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在 本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申 请的保护范围之内。本技术的保护范围应以权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。