1.本技术涉及数据分析技术领域,尤其涉及一种气体排放溯源确定方法、装置、设备与存储介质。
背景技术:
2.大气污染已经成为人们关注的重点问题,有效监测和减少大气污染物的排放已经成为一项重点任务。为关注和控制区域内污染物及有害气体排放,部分城市率先布设了便携式大气污染物监测站点,从而实现移动监测。在城市企业聚集地,该监测站点的布设密度甚至达到了1km
×
1km。这对企业污染排放起到了有效监督作用。
3.目前尽管已加密布设了监测站点,但是如何通过这些监测站点监测到的污染气体浓度值去定位污染源头,仍是亟待解决的问题。
技术实现要素:
4.基于此,有必要针对上述技术问题,提供一种气体排放溯源确定方法、装置、设备与存储介质,能够高效精准定位排放目标气体的目标站点。
5.第一方面,本技术提供一种气体排放溯源确定方法,所述方法包括:
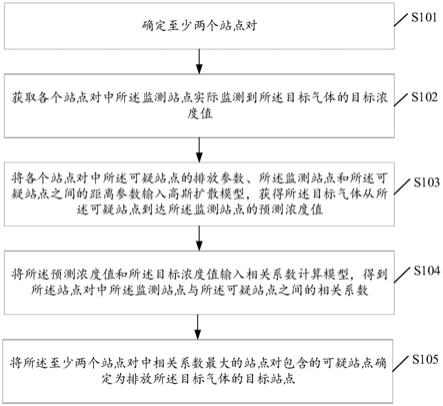
6.确定至少两个站点对,每个站点对包括用于对目标气体进行监测的监测站点和排放所述目标气体的可疑站点,所述监测站点的地理位置和所述可疑站点的地理位置之间满足目标位置关系;
7.获取各个站点对中所述监测站点实际监测到所述目标气体的目标浓度值;
8.将各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得所述目标气体从所述可疑站点到达所述监测站点的预测浓度值;
9.将所述预测浓度值和所述目标浓度值输入相关系数计算模型,得到所述站点对中所述监测站点与所述可疑站点之间的相关系数;
10.将所述至少两个站点对中相关系数最大的站点对包含的可疑站点确定为排放所述目标气体的目标站点。
11.结合第一方面,在一些实施例中,所述获取各个站点对中所述监测站点实际监测到所述目标气体的目标浓度值,包括:
12.获取在目标时间段内多个时间点中各个时间点所监测的所述目标气体的原始浓度值;
13.将所述目标时间段划分为至少两个子时间段,每个子时间段包括至少一个原始浓度值;
14.分别获取各个子时间段所对应的浓度值,所述子时间段对应的浓度值为所述子时间段中的所述至少一个原始浓度值的累加浓度值或平均浓度值;
15.将所述至少两个时间段中各个时间段对应的浓度值确定为所述目标浓度值。
16.结合第一方面,在一些实施例中,所述将所述至少两个时间段中各个时间段对应的浓度值确定为所述目标浓度值之后,还包括:
17.获取所述至少两个子时间段中各个子时间段所对应的时间点,所述时间点为所述子时间段的中间时间点或起始时间点;
18.所述将各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得所述目标气体从所述可疑站点到达所述监测站点的预测浓度值,包括:
19.将所述至少两个子时间段中各个子时间段所对应的时间点、所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得在所述各个子时间段对应时间点的浓度值,将各个子时间段对应时间点的浓度值确定为所述预测浓度值。
20.结合第一方面,在一些实施例中,所述目标气体包括至少两种第一污染气体;所述将所述至少两个站点对中相关系数最大的站点对中的可疑站点确定为排放所述目标气体的目标站点之后,还包括:
21.通过爬虫技术从网络平台获取与所述目标站点关联的第一文本;
22.根据所述第一文本,获得所述目标站点关联的产品类别;
23.根据所述产品类别,确定所述目标站点产生所述至少两种第一污染气体中的目标污染气体。
24.结合第一方面,在一些实施例中,所述根据所述第一文本,获得所述目标站点关联的产品类别,包括:
25.对所述第一文本进行分词,获得至少一个分词;
26.将所述至少一个分词组成的词序列输入预先训练好的fasttext模型进行分类处理,获得所述目标站点关联的产品类别。
27.结合第一方面,在一些实施例中,所述根据所述产品类别,确定所述目标站点产生所述至少两种第一污染气体中的目标污染气体,包括:
28.确实生产所述产品类别的产品所产生的至少两种排放气体;
29.根据所述至少两种排放气体和所述至少两种第一污染气体,确定所述目标污染气体,所述目标污染气体是所述至少两种排放气体和所述至少两种第一污染气体的交集。
30.结合第一方面,在一些实施例中,根据所述产品类别,确定所述目标站点产生所述至少两种第一污染气体中的目标污染气体之后,还包括:
31.获取与所述目标站点关联的通讯标识,并向所述通讯标识对应的用户发送包括预设文本的提示消息,所述预设文本用于描述对所述目标污染气体进行污染处理的处理方式。
32.第二方面,本技术提供一种气体排放溯源确定装置,该装置包括:
33.第一确定单元,用于确定至少两个站点对,每个站点对包括用于对目标气体进行监测的监测站点和排放所述目标气体的可疑站点,所述监测站点的地理位置和所述可疑站点的地理位置之间满足目标位置关系;
34.第一获取单元,用于获取各个站点对中所述监测站点实际监测到所述目标气体的目标浓度值;
35.第二获取单元,用于将各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得所述目标气体从所述可疑站点到达所述监测站点的预测浓度值;
36.第三获取单元,用于将所述预测浓度值和所述目标浓度值输入相关系数计算模型,得到所述站点对中所述监测站点与所述可疑站点之间的相关系数;
37.第二确定单元,用于将所述至少两个站点对中相关系数最大的站点对包含的可疑站点确定为排放所述目标气体的目标站点。
38.结合第二方面,在一些实施例中,所述第一获取单元具体用于:
39.获取在目标时间段内多个时间点中各个时间点所监测的所述目标气体的原始浓度值;
40.将所述目标时间段划分为至少两个子时间段,每个子时间段包括至少一个原始浓度值;
41.分别获取各个子时间段所对应的浓度值,所述子时间段对应的浓度值为所述子时间段中的所述至少一个原始浓度值的累加浓度值或平均浓度值;
42.将所述至少两个时间段中各个时间段对应的浓度值确定为所述目标浓度值。
43.结合第二方面,在一些实施例中,所述装置还包括:
44.第四获取单元,用于获取所述至少两个子时间段中各个子时间段所对应的时间点,所述时间点为所述子时间段的中间时间点或起始时间点;
45.所述第二获取单元具体用于将所述至少两个子时间段中各个子时间段所对应的时间点、所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得在所述各个子时间段对应时间点的浓度值,将各个子时间段对应时间点的浓度值确定为所述预测浓度值。
46.结合第二方面,在一些实施例中,所述目标气体包括至少两种第一污染气体;所述装置还包括:
47.第五获取单元,用于通过爬虫技术从网络平台获取与所述目标站点关联的第一文本;
48.第六获取单元,用于根据所述第一文本,获得所述目标站点关联的产品类别;
49.第三确定单元,用于根据所述产品类别,确定所述目标站点产生所述至少两种第一污染气体中的目标污染气体。
50.结合第二方面,在一些实施例中,所述第六获取单元具体用于:
51.对所述第一文本进行分词,获得至少一个分词;
52.将所述至少一个分词组成的词序列输入预先训练好的fasttext模型进行分类处理,获得所述目标站点关联的产品类别。
53.结合第二方面,在一些实施例中,所述第三确定单元具体用于:
54.确实生产所述产品类别的产品所产生的至少两种排放气体;
55.根据所述至少两种排放气体和所述至少两种第一污染气体,确定所述目标污染气体,所述目标污染气体是所述至少两种排放气体和所述至少两种第一污染气体的交集。
56.结合第二方面,在一些实施例中,所述装置还包括:
57.发送单元,用于获取与所述目标站点关联的通讯标识,并向所述通讯标识对应的
用户发送包括预设文本的提示消息,所述预设文本用于描述对所述目标污染气体进行污染处理的处理方式。
58.第三方面,本技术提供一种气体排放溯源确定设备,包括处理器、存储器以及通信接口,该处理器、存储器和通信接口相互连接,其中,该通信接口用于接收和发送数据,该存储器用于存储程序代码,该处理器用于调用该程序代码,执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
59.第四方面,本技术提供一种计算机可读存储介质,该计算机可读存储介质中存储有计算机程序;当该计算机程序在一个或多个处理器上运行时,使得该终端设备执行如第一方面以及第一方面中任一可能的实现方式描述的方法。
60.本技术实施例中,可以确定至少两个站点对,每个站点对中包含监测站点和排放目标气体的可疑站点,通过每个站点对中的可疑站点的排放参数、监测站点和可疑站点的距离参数以及监测站点监测到的目标气体的目标浓度值,确定各个站点对中两个站点之间的相关系数,从而将最大系数的可疑站点确定为排放目标气体的目标站点,并向目标站点关联的通讯标识对应的用户发送提示消息,本技术能够通过通过构建站点对的方式,得到站点对中两个站点之间的相关系数,从而确定最相关的两个站点,找到目标站点,实现目标站点的高效精准定位。
附图说明
61.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍。
62.图1为本技术实施例提供的一种气体排放溯源确定方法的流程示意图;
63.图2为本技术实施例提供的可疑站点和监测站点的位置关系示意图;
64.图3为本技术实施例提供的一种气体排放溯源确定装置的示意图;
65.图4为本技术实施例提供的一种气体排放溯源确定设备的示意图。
具体实施方式
66.下面结合附图对本发明作进一步详细描述。
67.本技术以下实施例中所使用的术语只是为了描述特定实施例的目的,而并非旨在作为对本技术的限制。如在本技术的说明书和所附权利要求书中所使用的那样,单数表达形式“一个”、“一种”、“所述”、“上述”、“该”和“这一”旨在也包括复数表达形式,除非其上下文中明确地有相反指示。
68.在本技术中,“至少一个(项)”是指一个或者多个,“多个”是指两个或两个以上,“至少两个(项)”是指两个或三个及三个以上,“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系,例如,“a和/或b”可以表示:只存在a,只存在b以及同时存在a和b三种情况,其中a,b可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”。
69.本技术实施例提供了一种气体排放溯源确定方法,为了更清楚地描述本技术的方案,下面对本技术涉及的一些附图作进一步介绍。
70.请参阅图1,图1为本技术实施例提供的一种气体排放溯源确定方法的流程示意图。如图1所示,所述方法包括以下步骤:
71.s101,确定至少两个站点对,每个站点对包括用于对目标气体进行监测的监测站点和排放所述目标气体的可疑站点,所述监测站点的地理位置和所述可疑站点的地理位置之间满足目标位置关系;
72.本技术实施例中,可以在监测站点设置用于监测目标气体浓度的监测传感器,该目标气体可以是大气污染物,可以理解的是,目标气体还可以是其他需要进行监测的气体,本技术不作限定,目标气体可以包含一种或多种气体。
73.示例性的,可以将监测站点的上风向的企业确定为可疑站点,该监测站点即是架设监测工具进行浓度监测的地点,在监测过程中,监测地点可以是移动的,即可以在预设范围内进行移动监测,每个监测的地点称为监测站点,分别确定与各个监测站点关联的可疑污染企业,作为可疑站点,即可确定例如e1,e2,e3,
…
,en共n个可疑污染企业,每个可疑污染企业与各个监测站点关联,从而获得至少两个站点对,每个站点对包括一个监测站点和一个可疑站点,该可疑站点的地理位置和监测站点的地理位置之间满足目标位置关系,该目标位置关系可以包括:该可疑站点的地理位置在监测站点的地理位置的上风向,如图2所示,可疑站点的地理位置在监测站点的地理位置的正上风向的位置。
74.具体可选的,若监测到某个地点的污染物浓度值大于预设阈值,则可以是以此地点为基准,确定预设范围,比如,以该地点为圆心,r为半径确定一个圆形区域作为预设范围,或者,还可以是以该地点为中心,确定一个矩形区域作为预设范围。
75.进一步,从该预设范围中选取至少一个监测站点,比如,可以是在该预设范围内确定一个横坐标,一个纵坐标,然后,在该预设范围内绘制函数sinx曲线,并以横坐标上的一定预设间隔选取曲线上的点作为监测站点,比如,可以选择π/6为间隔,从绘制的曲线中选取至少一个监测站点,可以理解的是,还可以是其他函数,本技术不作限定。
76.当确定至少一个监测站点之后,可以进一步确定与各个监测站点关联的可疑污染企业,作为可疑站点,具体确定方法可以是,以该监测站点上风向一定角度范围内的企业确定为与该监测站点关联的可疑污染企业,作为可疑站点。可以理解的是,与一个监测站点关联的可疑污染企业可以包括一个或多个,即多个站点对中包括同一个监测站点,但是包括不同的可疑站点。可选的,与各个监测站点关联的可疑站点之间可以不重复。
77.s102,获取各个站点对中所述监测站点实际监测到所述目标气体的目标浓度值;
78.s103,将各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得所述目标气体从所述可疑站点到达所述监测站点的预测浓度值;
79.s104,将所述预测浓度值和所述目标浓度值输入相关系数计算模型,得到所述站点对中所述监测站点与所述可疑站点之间的相关系数;
80.本技术实施例中,获取各个站点对中可疑站点的排放参数、监测站点和可疑站点之间的距离参数以及监测站点监测到目标气体的目标浓度值,从而确定各个站点对中监测站点与可疑站点之间的相关系数,可以理解的是,一个站点对可以对应一个相关系数。
81.具体可选的,下面以计算一个站点对中监测站点与可疑站点之间相关系数作为举例,将可疑站点的排放参数、监测站点和可疑站点之间的距离参数输入高斯扩散模型,获得
预测浓度值。将该预测浓度值和在监测站点监测到的目标浓度值输入相关系数计算模型,得到站点对中监测站点与可疑站点之间的相关系数。
82.获取监测站点的目标浓度值的获取方式可以是,具体可选的,通过监测站点的浓度监测传感器获取目标时间段内多个时间点中每个时间点所监测的目标气体的原始浓度值,可以将该各个时间点所对应的原始浓度值作为目标浓度值。可选的,由于时间点比较多,因此可能会导致后续计算量比较大。一种可选的实施方式中,可以将该目标时间段内各个时间点划分为至少两个子时间段,每个子时间段包括至少一个时间点的原始浓度值,可以计算每个子时间段所对应的浓度值,子时间段对应的浓度值为该子时间段中至少一个原始浓度值的平均浓度值或累加浓度值,目标时间段内各个时间段对应的浓度值确定为目标浓度值。可选的,可以是对子时间段内的各个时间点的原始浓度值进行累加,将累加值作为该子时间段的浓度值。本技术实施例中,目标浓度值可以是一个浓度值序列{a1,a2,a3,
…
,at},该浓度值序列中包括多个浓度值。
83.获取与目标浓度值对应的预测浓度值,其中,与目标浓度值对应的预测浓度值可以理解为时间点上的对应,如果目标浓度值包括各个时间点的原始浓度值,则预测浓度值包括的浓度值序列中各个浓度值的时间点即是该各个原始浓度值所对应的时间点,如果目标浓度值包括各个子时间段对应的浓度值,则预设浓度值包括的浓度值序列中各个浓度值的时间点可以是各个子时间段的中间时间点、或起始时间点、或结束时间点等等。
84.具体可选的,运用高斯扩散模型计算出某一家企业(可疑站点)的污染排放到达监测站点处时的预测浓度值c,该预测浓度值可以是时间上连续的扩散浓度值序列{c1,c2,c3,
…
,ct}。根据高斯扩散模型,将点源(可疑站点)在有效高度h及下风向空间点(x,y,z)处造成的污染物浓度表示为c(x,y,z,h),单位为g/m3,当z=0时表示点源在地面处造成的浓度,其公式为:
[0085][0086]
其中,c是任意点处的预测浓度(g/m3),q为企业排放源强度(g/s),σy和σz分别为侧向和垂直方向扩散系数,是距离x的函数,为排口处的风速(m/s),它是一个随时间变化的量,h为排口有效高度(m),x表示污染源排放点(可疑站点)至下风向上任一点的距离(m),y表示排口的中心轴在直角水平方向上到任意点的距离(m),z表示从地表到任意点的高度(m),t表示时间(小时),如图2所示,可以为x和y的一种示意图,以监测站点在可疑站点的正下风向为x轴,以与风向垂直的方向为y轴方向,可以理解的是,还可以是其他表示方式。
[0087]
将获取的企业排口源强值q、评价风速排口高度h、监测站点和可疑站点之间的距离x代入以上高斯扩散模型,并令y取0,在图2所示建坐标方式才是y=0,如果其他方式y不一定等于0,z取监测站点距离地面高度,即可求出可疑站点的污染排放到达监测站点处时的预测浓度值c。
[0088]
获取同一目标时间段内在各个监测站点处监测到的污染物的目标浓度值{a1,a2,a3,
…
,at},将该目标浓度值与计算得出的预测浓度值{c1,c2,c3,
…
,ct}做皮尔森相关系数计算,获得该监测站点与该可疑站点的皮尔森相关系数。
[0089]
其中,{a1,a2,a3,
…
,at}和{c1,c2,c3,
…
,ct}做皮尔森相关系数计算公式为:
[0090][0091]
s105,将所述至少两个站点对中相关系数最大的站点对包含的可疑站点确定为排放所述目标气体的目标站点;
[0092]
本技术实施例中,计算每个站点对中监测站点与可疑站点的皮尔森相关系数,获得至少两个皮尔森相关系数,找出相关系数较大的站点对,并将该最大站点对中的可疑站点确定为排放目标气体的目标站点。
[0093]
可选的,该目标气体可以包括至少两种第一污染气体,通常通过污染物浓度监测传感器只能监测到排放了该目标气体,但是无法确定目标站点排放了具体哪种污染气体,本技术通过文本处理过程可以确定该目标站点排放了该至少两种第一污染气体中的目标污染气体。
[0094]
具体可选的,可以是通过网络爬虫技术从网络平台获取与该目标站点关联的第一文本,可选的,该第一文本可以包括目标站点所指示目标企业的企业名称、经营范围等内容,还可以是与目标企业关联的新闻文本或财经文本等等。进一步,将该第一文本输入预先训练好的分类模型,从而得到该目标站点关联的产品类别。该分类模型用于对输入文本进行特征提取,并基于所提取的特征进行产品分类。
[0095]
示例性的,该分类模型可以是fasttext模型,可以使用分词工具对该第一文本进行分词,并去除文本中的标点符号等无意义的符号,获得至少一个分词,并将该至少一个分词组成词序列。将所得到的词序列输入预先训练好的fasttext模型,获得目标站点关联的产品类别,fasttext模型输入为一个词序列(一段文本或者一句话分词后的词序列),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fasttext模型通过softmax函数将输出层的值归一化到0-1分布,将神经元输出构造成概率分布,从而确定目标企业与各个产品分类的关联概率,并将概率最大的产品类别作为目标站点所关联的产品分类。该实施方式中,预先训练好的fasttext模型能够挖掘企业名称、经营范围等与企业相关的文本与产品分类之间的对应关系。
[0096]
进一步,可以获取生产该产品类别的产品所产生的至少两种排放气体,比如,可以预先在字典中存储各种产品类别的产品与排放气体之间的对应关系,从而获取目标站点所关联的产品类别所对应的至少两种排放气体。根据该至少两种排放气体和目标气体中的至少两种第一污染气体,确定目标污染气体,该目标污染气体是所述至少两种排放气体和所述至少两种第一污染气体的交集。
[0097]
进一步可选的,当确定排放目标气体的目标站点之后,可以进一步获取与目标站点关联的通讯标识,该通讯标识可以是该目标站点所指示目标企业的负责人的电话号码或即时通讯账号等,向通讯标识对应的用户发送提示消息。
[0098]
可选的,当确定目标站点排放目标污染气体时,还可以获取与目标污染气体对应的预设文本,该预设文本用于描述对目标污染气体进行污染处理的处理方式。向目标站点关联的通讯标识对应的用户发送包括该预设文本的提示消息。
[0099]
示例性的,可以预设各种污染气体对应的预设文本,该预设文本是用于描述处理该污染气体的处理方式。比如,通过上述模型分类,获得目标企业关联的产品类别是塑料,即该目标企业生产塑料相关的产品,则由于塑料在生产时会产生的大气污染物是苯乙烯,该预设文本即是描述如何对苯乙烯进行处理的文本。
[0100]
本技术实施例中,可以确定至少两个站点对,每个站点对中包含监测站点和排放目标气体的可疑站点,通过每个站点对中的可疑站点的排放参数、监测站点和可疑站点的距离参数以及监测站点监测到的目标气体的目标浓度值,确定各个站点对中两个站点之间的相关系数,从而将最大系数的可疑站点确定为排放目标气体的目标站点,并向目标站点关联的通讯标识对应的用户发送提示消息,本技术能够通过通过构建站点对的方式,得到站点对中两个站点之间的相关系数,从而确定最相关的两个站点,找到目标站点,实现目标站点的高效精准定位。
[0101]
请参见图3,为本技术实施例提供了一种气体排放溯源确定装置的结构示意图。如图3所示,该气体排放溯源确定装置可以包括:
[0102]
第一确定单元10,用于确定至少两个站点对,每个站点对包括用于对目标气体进行监测的监测站点和排放所述目标气体的可疑站点,所述监测站点的地理位置和所述可疑站点的地理位置之间满足目标位置关系;
[0103]
第一获取单元11,用于获取各个站点对中所述监测站点实际监测到所述目标气体的目标浓度值;
[0104]
第二获取单元12,用于将各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得所述目标气体从所述可疑站点到达所述监测站点的预测浓度值;
[0105]
第三获取单元13,用于将所述预测浓度值和所述目标浓度值输入相关系数计算模型,得到所述站点对中所述监测站点与所述可疑站点之间的相关系数;
[0106]
第二确定单元14,用于将所述至少两个站点对中相关系数最大的站点对包含的可疑站点确定为排放所述目标气体的目标站点。
[0107]
在一种可能的设计中,所述第一获取单元11具体用于:
[0108]
获取在目标时间段内多个时间点中各个时间点所监测的所述目标气体的原始浓度值;
[0109]
将所述目标时间段划分为至少两个子时间段,每个子时间段包括至少一个原始浓度值;
[0110]
分别获取各个子时间段所对应的浓度值,所述子时间段对应的浓度值为所述子时间段中的所述至少一个原始浓度值的累加浓度值或平均浓度值;
[0111]
将所述至少两个时间段中各个时间段对应的浓度值确定为所述目标浓度值。
[0112]
在一种可能的设计中,所述装置还包括:
[0113]
第四获取单元,用于获取所述至少两个子时间段中各个子时间段所对应的时间点,所述时间点为所述子时间段的中间时间点或起始时间点;
[0114]
所述第二获取单元具体用于将所述至少两个子时间段中各个子时间段所对应的时间点、所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数输入高斯扩散模型,获得在所述各个子时间段对应时间点的浓度值,将各个子时间段对应时间点
的浓度值确定为所述预测浓度值。
[0115]
在一种可能的设计中,所述目标气体包括至少两种第一污染气体;所述装置还包括:
[0116]
第五获取单元,用于通过爬虫技术从网络平台获取与所述目标站点关联的第一文本;
[0117]
第六获取单元,用于根据所述第一文本,获得所述目标站点关联的产品类别;
[0118]
第三确定单元,用于根据所述产品类别,确定所述目标站点产生所述至少两种第一污染气体中的目标污染气体。
[0119]
在一种可能的设计中,所述第六获取单元具体用于:
[0120]
对所述第一文本进行分词,获得至少一个分词;
[0121]
将所述至少一个分词组成的词序列输入预先训练好的fasttext模型进行分类处理,获得所述目标站点关联的产品类别。
[0122]
在一种可能的设计中,所述第三确定单元具体用于:
[0123]
确实生产所述产品类别的产品所产生的至少两种排放气体;
[0124]
根据所述至少两种排放气体和所述至少两种第一污染气体,确定所述目标污染气体,所述目标污染气体是所述至少两种排放气体和所述至少两种第一污染气体的交集。
[0125]
在一种可能的设计中,所述装置还包括:
[0126]
发送单元,用于获取与所述目标站点关联的通讯标识,并向所述通讯标识对应的用户发送包括预设文本的提示消息,所述预设文本用于描述对所述目标污染气体进行污染处理的处理方式。
[0127]
其中,图3所示装置实施例的具体描述可以参照前述图1所示方法实施例的具体说明,在此不进行赘述。
[0128]
请参照图4,为本技术实施例提供的一种气体排放溯源确定设备的结构示意图,如图4所示,该气体排放溯源确定设备1000可以包括:至少一个处理器1001,例如cpu,至少一个通信接口1003,存储器1004,至少一个通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。通信接口1003可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1004可以是高速ram存储器,也可以是非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器。存储器1004可选的还可以是至少一个位于远离前述处理器1001的存储装置。如图4所示,作为一种计算机存储介质的存储器1004中可以包括操作系统、网络通信单元以及程序指令。
[0129]
在图4所示的气体排放溯源确定设备1000中,处理器1001可以用于加载存储器1004中存储的程序指令,并具体执行以下操作:
[0130]
确定至少两个站点对,每个站点对包括用于对目标气体进行监测的监测站点和排放所述目标气体的可疑站点,所述监测站点的地理位置和所述可疑站点的地理位置之间满足目标位置关系;
[0131]
根据各个站点对中所述可疑站点的排放参数、所述监测站点和所述可疑站点之间的距离参数以及所述监测站点监测到所述目标气体的目标浓度值,确定各个站点对中所述监测站点与所述可疑站点之间的相关系数;
[0132]
将所述至少两个站点对中相关系数最大的站点对包含的可疑站点确定为排放所
述目标气体的目标站点;
[0133]
获取与所述目标站点关联的通讯标识,并向所述通讯标识对应的用户发送提示消息。
[0134]
需要说明的是,具体执行过程可以参见图1所示方法实施例的具体说明,在此不进行赘述。
[0135]
本技术实施例还提供了一种计算机存储介质,所述计算机存储介质可以存储有多条指令,所述指令适于由处理器加载并执行如上述图1所示实施例的方法步骤,具体执行过程可以参见图1所示实施例的具体说明,在此不进行赘述。
[0136]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。该计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行该计算机程序指令时,全部或部分地产生按照本技术实施例该的流程或功能。该计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。该计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,该计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线)或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。该计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。该可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如dvd)、或者半导体介质(例如固态硬盘)等。
[0137]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,该流程可以由计算机程序来指令相关的硬件完成,该程序可存储于计算机可读取存储介质中,该程序在执行时,可包括如上述各方法实施例的流程。而前述的存储介质包括:rom或随机存储记忆体ram、磁碟或者光盘等各种可存储程序代码的介质。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。