基于改进轻量型cnn与迁移学习的裂缝自动检测方法
技术领域
1.本发明涉及裂缝检测技术领域,特别涉及基于改进轻量型cnn与迁移学习的裂缝自动检测方法。
背景技术:
2.随着经济的快速发展,各种各样的建筑的建造速度也越来越快,如:楼房、桥梁,堤坝以及各种工业建筑,同时,这些建筑在长期的使用过程中,也会出现破损和老化,因此,需要定期对建筑进行检测和修复,以防发生安全事故,目前,最常见的做法是基于视觉的人工监测方法,采用肉眼检查、手工描绘等方式来识别建筑的裂缝并记录其分布及形状,然而,人工检查时效性低,性价比低,需要投入大量人力物力,不易及时发现建筑存在的安全隐患,且检查结果的有很大的主观性,不同工程人员对同个结构的判断也存在差异性,准确率较低。
3.因此,如何提供一种准确率高的裂缝检测方法,是本领域技术人员亟待解决的问题。
技术实现要素:
4.本技术实施例提供了基于改进轻量型cnn与迁移学习的裂缝自动检测方法,旨在解决现有裂缝识别技术准确率低的问题。
5.第一方面,本技术提供了基于改进轻量型cnn与迁移学习的裂缝自动检测方法,包括:
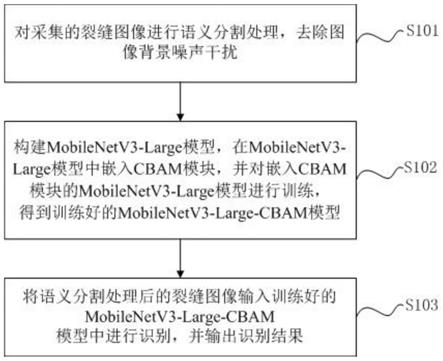
6.对采集的裂缝图像进行语义分割处理,去除图像背景噪声干扰;
7.构建mobilenetv3-large模型,在mobilenetv3-large模型中嵌入cbam模块,并对嵌入cbam模块的mobilenetv3-large模型进行训练,得到训练好的mobilenetv3-large-cbam模型;
8.将语义分割处理后的裂缝图像输入训练好的mobilenetv3-large-cbam模型中进行识别,并输出识别结果。
9.第二方面,本技术还提供了基于改进轻量型cnn与迁移学习的裂缝自动检测系统,该系统包括:
10.语义分割单元,用于对采集的裂缝图像进行语义分割处理,去除图像背景噪声干扰
11.模型训练单元,用于构建mobilenetv3-large模型,在mobilenetv3-large模型中嵌入cbam模块,并对嵌入cbam模块的mobilenetv3-large模型进行训练,得到训练好的mobilenetv3-large-cbam模型;
12.裂缝识别单元,用于将语义分割处理后的裂缝图像输入训练好的mobilenetv3-large-cbam模型中进行识别,并输出识别结果。
13.第三方面,本技术还提供了一种计算机设备,其包括存储器、处理器及存储在所述
存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时,实现上述第一方面所述的基于改进轻量型cnn与迁移学习的裂缝自动检测方法。
14.第四方面,本技术还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时使所述处理器执行上述第一方面所述的基于改进轻量型cnn与迁移学习的裂缝自动检测方法。
15.本技术提出的基于改进轻量型cnn与迁移学习的裂缝自动检测方法,采用vgg16-u-net对图像集进行语义分割预处理,实现将裂缝与从复杂的图片背景的中快速分离出来,能有效降低图像背景噪声的影响;同时利用迁移学习fine-tuning技术提高了模型泛化能力;该模型在满足轻量化的前提下,集成损伤函数focal loss,提高模型的识别效率和准确率,提升网络提取复杂裂缝图像特征的能力;此外该模型较小,容易实现移动端的集成,对实现裂缝自动化检测和识别具有实际的工程应用价值。
附图说明
16.为了更清楚的说明本技术实施例技术方案,下面将对实施例描述中所需要使用的附图作简单的介绍,显而易见的,下面的描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
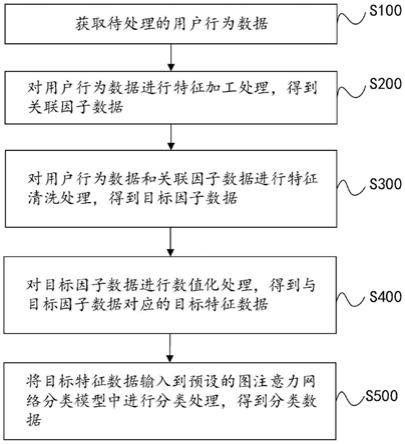
17.图1为本技术实施例提供的基于改进轻量型cnn与迁移学习的裂缝自动检测方法流程图;
18.图2为本技术实施例提供的vgg16-u-net模型结构图;
19.图3为本技术实施例提供的mobilenetv3-large模型结构图;
20.图4为本技术实施例提供的通道注意力模块的工作原理图;
21.图5为本技术实施例提供的空间注意力模块的工作原理图。
具体实施方式
22.下面结合附图对本发明的具体实施方式作进一步说明。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。
23.参见图1实施例所示基于改进轻量型cnn与迁移学习的裂缝自动检测方法流程图,包括:
24.s101、采用vgg16-u-net对采集的裂缝图像进行语义分割处理,去除图像背景噪声干扰。
25.裂缝图像存在着大量背景噪声,如何高效处理这些噪声是自动识别裂缝的关键。本技术采用了vgg16-u-net来对图像语义分割去除图像背景噪声。语义分割是深度学习计算机视觉的一个重要分支,与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。u-net具有卷积编码与卷积解码完全对称的模型结构,该模型较浅层用来解决像素定位问题,较深层用来解决像素分类问题。
26.在本技术中,u-net的编码器采用vgg16的前15层,在解码器中,使用反卷积层对图像进行上,将特征逐步恢复到图像的原始大小。在解码器后连接一个带有sigmoid激活函数的1
×
1卷积层,生成图像中每个像素的预测。编码器和解码器之间通过跳跃连接,最终构建
vgg16-u-net全卷积神经模型,实现裂缝与复杂的图片背景的快速分离。该模型由编码层、解码层及最终卷积层3个部分组成,模型结构如图2所示。vgg16-u-net通过对每个像素进行预测、推断、分类,将图像中不同像素分类,将属于背景噪声的像素用黑色部分表示,属于裂缝的像素用白色部分表示。
27.s102、构建mobilenetv3-large模型,在mobilenetv3-large模型中嵌入cbam模块,并对嵌入cbam模块的mobilenetv3-large模型进行训练,得到训练好的mobilenetv3-large-cbam模型;
28.mobilenetv3-large为2019年采用神经网络架构搜索(nas)算法得到的轻量级神经网络,其具体结构如图3所示,并引入squeeze and excitation(se)轻量级注意力模块。
29.mobilenetv3综合了三种思想:可分离卷积、具有线性瓶颈的逆残差结构,squeeze and excitation结构,mobilenetv3由一个1*1的卷积层、三个3*3的benck模块,八个5*5的bneck模块,一个1*1的卷积层,一个7*7的池化层,两个1*1的卷积层按顺序构成。一个k*k的bneck模块由一个1*1的卷积层(包含relu6激活函数和batch normalization),一个3*3的深度可分离卷积层(包含relu6激活函数和batch normalization),一个se模块,一个1*1的卷积层按顺序构成。
30.与其他卷积神经网络相比,mobilenetv3-large模型具有轻量级、运行速度快的优势,在imagenet上具有更高的分类准确率。imagenet是计算机视觉系统识别项目,目前是世界上最大的图像识别数据集之一。因此本专利选择了mobilenetv3-large,参数量少,网络效率高。
31.在一实施例中,cbam模块中包含了通道注意力模块和空间注意力模块。
32.本专利将cbam嵌入mobilenetv3-large,可在不增加模型参数体积的前提下,提升网络模型提取获取图像裂缝特征的性能。
33.参见图4实施例所示的通道注意力模块结构图;
34.在通道注意力模块中采用了平均池化层和最大池化层,并在池化层后连接一个两层的神经网络来对输入特征进行处理;然后使用sigmoid]激活函数获得权重系数。最后,将获得的权重系数和输入的特征相乘便可获得通道特征。
35.参见图5实施例所示的空间注意力模块结构图;
36.在空间注意力模块中,将平均池化层和最大池化层拼接在一块儿,后接一个激活函数为sigmoid的7
×
7、激活函数为sigmoid的卷积层。将特征输入空间注意力模块,可获得权重。最后,将权重和输入的特征相乘便可得到空间特征。
37.本技术的模型的训练一般需要循环多次,每次包含前向传播和反向传播两个过程,图像输入模型经过输入层、bneck等多个模块,最终输出结果,将连同图像真实标签计算得出focal损失,将得到的focal损失反向传播至模型,并且采用随机梯度下降方式更新模型中各层的参数权重,之后重新开始新的一次训练。在训练时,不断调整学习率,并在模型训练完成后测试模型性能,待损失完全收敛不再增加时,停止训练,将在测试集上性能最好的模型保存下来。
38.在一实施例中,对嵌入cbam模块的mobilenetv3-large模型进行训练,包括:
39.将采集的裂缝数据集分为训练集、验证集和测试集三个部分,使用训练集对嵌入cbam模块的mobilenetv3-large模型进行训练。
40.具体为:使用采集的裂缝数据集训练cbam mobilenetv3-large,将裂缝数据集分为训练集、验证集、测试集三个部分,比例分别为6:2:2,训练集的作用是用来训练mobilenetv3-large cbam自动识别裂缝;验证集的作用是为了观察模型在训练过程中识别裂缝的准确率;测试集不参与训练过程,为最终测试模型的性能。
41.在一实施例中,在训练时,不断调整学习率,包括:
42.在训练时,使用余弦退火的随机梯度下降不断调整学习率,防止陷入局部最优点。
43.面向实际工程结构的裂缝识别分类问题,模型的泛化能力也非常重要。泛化能力是指模型对不同场景下的数据集的适应能力,即泛化能力强的模型在不同数据集上表现同样优异,迁移学习可有效提升模型的泛化能力以及在小数据集下的性能。因此在训练过程中采用迁移学习的fine-tuning技术,每个模型均使用了在imagenet上进行的预训练权重,并冻结除最后一层卷积层和全连接层外的权重,用新的学习速率训练最后一层卷积层和全连接层,达到降低训练成本的作用。使模型能够适应不同的场景,如桥梁,公路。
44.在实际工程中,存在着较难识别的场景,如复杂形状的裂缝相比简单的裂缝来说更难以识别,focal loss为2017年提出的损失函数,可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,因此本文选择focal loss损失函数。
45.fl(p
t
)=-(1-p
t
)
γ
log(p
t
)
46.p
t
:样本属于t类别的概率
47.γ:集中参数,γ>=0
48.在训练过程中,模型容易陷入局部最优点,而余弦退火的随机梯度下降算法可以在一定的时间内调整学习率使得模型跳出局部最优点到达全局最优点,因此本专利采用余弦退火的随机梯度下降算法;
[0049][0050]
其中,i为重启的次数;和分别为学习率的最大值和最小值,t
cur
为当前执行的epochs,ti为第i次的重启中总的epochs。
[0051]
s103、将语义分割处理后的裂缝图像输入训练好的mobilenetv3-large-cbam模型中进行识别,并输出识别结果。
[0052]
在得到练好的mobilenetv3-large-cbam模型后,即可通过训练好的模型来完成对裂缝图像的自动识别,并得到识别结果。
[0053]
在一实施例中,本技术还提供了基于改进轻量型cnn与迁移学习的裂缝自动检测系统,该系统包括:
[0054]
语义分割单元,用于对采集的裂缝图像进行语义分割处理,去除图像背景噪声干扰
[0055]
模型训练单元,用于构建mobilenetv3-large模型,在mobilenetv3-large模型中嵌入cbam模块,并对嵌入cbam模块的mobilenetv3-large模型进行训练,得到训练好的mobilenetv3-large-cbam模型;
[0056]
裂缝识别单元,用于将语义分割处理后的裂缝图像输入训练好的mobilenetv3-large-cbam模型中进行识别,并输出识别结果。
[0057]
在一实施例中,本技术还提供了一种计算机设备,其包括存储器、处理器及存储在存储器上并可在所述处理器上运行的计算机程序,处理器执行所述计算机程序时,实现上述任一实施例所述的基于改进轻量型cnn与迁移学习的裂缝自动检测方法。
[0058]
在一实施例中,本技术还提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时使所述处理器执行上述任一实施例所述的基于改进轻量型cnn与迁移学习的裂缝自动检测方法。
[0059]
以上结合附图对本发明的实施方式作了详细说明,但本发明不限于所描述的实施方式。对于本领域的技术人员而言,在不脱离本发明原理和精神的情况下,对这些实施方式进行多种变化、修改、替换和变型,仍落入本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。