一种眼底视网膜octa图像融合方法及系统
技术领域
1.本发明涉及计算机视觉技术领域,尤其涉及一种眼底视网膜octa图像融合方法及系统。
背景技术:
2.光学相干断层成像血管造影(octa)是一种无创成像方法,无需静脉注射染料,通过检测视网膜内血流的运动对比,对视网膜微血管三维成像。octa比荧光素血管造影(fa)具有更高的对比度和更好的分辨率显示视网膜微血管。octa图像的高对比度和高分辨率使得定量评价视网膜微血管,包括血管密度和无灌注区域,比fa图像更有效。在octa成像中由于眼动和血管内红细胞多次散射等原因,会产生伪影信号,给临床诊断带来很大不确定性。octa伪影(即眼动伪影)容易降低octa图像质量,即使在正常人群中也无法准确解释和定量分析octa图像。因此,提高octa图像质量的方法非常重要。
3.随着信息技术的发展,数字图像被广泛适用于各种场景中。图像融合是复杂探测系统的关键问题之一,图像融合可以将同一场景的多张图像所包含的信息整合成一张信息更全面的复合图像。当前采用的主要图像融合方法是基于多尺度分解的方法,需要依据先验知识选择适合的多尺度分解方法和融合策略,不利于工程化的应用。
4.为了解决上述问题,亟待设计通过计算机通过深度卷积网络来对图像进行融合的方案。
技术实现要素:
5.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种眼底视网膜octa图像融合方法及系统,以解决现有技术的不足。
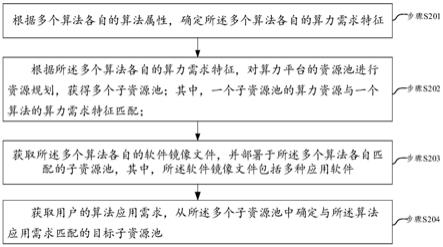
6.为实现上述目的,本发明提供了一种眼底视网膜octa图像融合方法,其特征在于,包括以下步骤:
7.步骤1,采集眼底视网膜octa图像数据,对同一只眼睛同一区域采集10组数据,然后对图像进行预处理,包括:图像直方图匹配、运动伪影的检测以及样条分离、样条图像配准、样条图像拼接融合;利用预处理后的图像数据,构建深度学习的训练数据集;
8.步骤2,搭建深度卷积神经网络模型,对深度卷积神经网络模型进行训练,将输入的单张低质量图像输出为高质量融合图像;
9.步骤3,构建混合损失函数,通过所述混合损失函数对octa图像的小血管进行提取,利用混合损失函数计算小血管图像的多尺度结构相似性和平均绝对误差l1来训练深度卷积神经网络,获得网络模型参数;
10.步骤4,利用训练后的深度卷积神经网络模型对测试集图像进行预测,网络输出即为融合后的高质量图像。
11.进一步的,所述步骤1中运动伪影的检测以及样条分离的具体步骤如下:首先计算图像中每一列的像素的平均值以及全图所有像素的平均值,其中均值大于1.5倍得到全图
像素平均值的列被认为是运动伪影,根据检测出的运动伪影的位置,将对应得到图像分成多个没有运动伪影的样条图像。
12.进一步的,所述步骤1中样条图像配准的具体步骤如下:获得10张图像的样条图像后,通过基于相位相关的配准算法对大血管进行粗配准,再通过基于非刚性配准算法对小血管进行细配准。
13.进一步的,所述步骤1中样条图像拼接融合的具体步骤如下:将配准后的样条图像按照重叠区域大小来进行融合,采用的融合算法是小波融合算法。
14.进一步的,所述步骤1中构建深度学习的训练数据集的具体步骤如下:将预处理后多张融合的图像作为训练的标签图像,该数据集中包含成对的单张图像和标签图像。
15.进一步的,所述步骤2中,搭建深度卷积神经网络模型具体为:以步骤1生成的训练数据集中的成对的单张图像和标签图像作为输入,构建一个深度卷积神经网络模型,该深度卷积神经网络采用17层的网络结构,分为三个部分:第一部分是由一个卷积层和激活函数组成,第二部分是由卷积层、批量归一化和激活函数组成,第三部分是一个卷积层。
16.进一步的,所述步骤3中构建混合损失函数,具体包括:
17.构建多尺度结构相似性ms-ssim为:
[0018][0019]
其中是区域中间像素值;
[0020]
构建l1损失函数为:
[0021][0022]
其中p是像素值,x(p)是预测图像的像素值,y(p)是标签图像的像素值;
[0023]
构建优化目标函数,该优化目标函数为混合损失函数:
[0024][0025]
其中α是权重系数,是计算ms-ssim中的第m个尺度的高斯核;
[0026]
利用反向传播算法,求解目标函数关于系数的偏导数,同时对深度卷积神经网络各层参数利用随机梯度下降进行参数更新学习。
[0027]
本发明还提供一种眼底视网膜octa图像融合系统,包括:
[0028]
图像采集和预处理模块,用于采集眼底视网膜octa图像数据,对同一只眼睛同一区域采集10组数据,然后对图像进行预处理;
[0029]
深度卷积神经网络模型构建模块,用于搭建深度卷积神经网络模型,对深度卷积神经网络模型进行训练;
[0030]
混合损失函数构建模块,用于构建混合损失函数,通过所述混合损失函数对octa图像的小血管进行提取,利用混合损失函数计算小血管图像的多尺度结构相似性和平均绝对误差l1来训练深度卷积神经网络,获得网络模型参数;
[0031]
图像融合模块,用于利用训练后的深度卷积神经网络模型对测试集图像进行预测,网络输出即为融合后的高质量图像。
[0032]
本发明的有益效果是:
[0033]
本发明通过深度卷积网络来对图像进行融合,将同一场景的多张图像所包含的信
息整合成一张信息更全面的复合图像,图像处理质量好。
[0034]
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
[0035]
图1为本发明基于深度学习的眼底视网膜octa图像融合方法流程图。
[0036]
图2为本发明步骤1中的预处理方法流程图。
[0037]
图3为本发明深度卷积神经网络模型结构图。
具体实施方式
[0038]
如图1所示的一种基于深度学习的眼底视网膜octa图像融合方法,包括以下步骤;
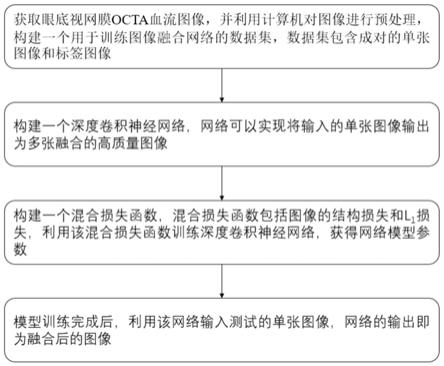
[0039]
步骤1:采集眼底视网膜octa图像数据,然后对图像进行预处理,包括:图像直方图匹配、运动伪影的检测以及样条分离、样条图像配准、样条图像拼接融合;利用预处理后的图像数据,构建深度学习的训练数据集;
[0040]
具体地,预处理方法参见图2,在步骤1中包括如下内容:
[0041]
图像直方图匹配的具体步骤如下:由于采集的眼底视网膜octa图像数据采集的是时间不同会导致每组图像的亮度分布不同,为避免对后面的处理结果造成影响,采用图像直方图匹配的方法来调整每组图像集的亮度,使每组图像的亮度分布一致;
[0042]
运动伪影的检测以及样条分离的具体步骤如下:首先计算图像中每一列的像素的平均值以及全图所有像素的平均值,其中均值大于1.5倍得到全图像素平均值的列被认为是运动伪影,根据检测出的运动伪影的位置,将对应得到图像分成对个没有运动伪影的样条图像;
[0043]
样条图像配准的具体步骤如下:按照上述步骤,在获得10张图像的样条图像后,通过基于相位相关的配准算法对大血管进行粗配准,再通过基于非刚性配准算法对小血管进行细配准;
[0044]
样条图像拼接融合的具体步骤如下:完成上述步骤后,将配准后的样条图像按照重叠区域大小(先大后小)来进行融合,采用的融合算法是小波融合算法;
[0045]
构建深度学习的训练数据集具体如下:将预处理后多张融合的图像作为训练的标签图像,该数据集中包含成对的单张图像和标签图像;
[0046]
步骤2:搭建深度卷积神经网络模型,对深度卷积神经网络模型进行训练,该网络可以实现将输入的单张低质量图像输出为高质量融合图像;
[0047]
在本实施方式中,该深度卷积神经网络采用17层的网络结构,分为三个部分:第一部分是由一个卷积层和激活函数组成,第二部分是由卷积层、批量归一化和激活函数组成,第三部分是一个卷积层;
[0048]
具体地,深度卷积神经网络模型参见图3;
[0049]
步骤3:构建一个混合损失函数,该损失函数包括图像的多尺度结构相似性(ms-ssim)和平均绝对误差l1,并且该损失函数对octa图像的小血管进行提取,利用混合损失函数计算小血管图像的多尺度结构相似性(ms-ssim)和平均绝对误差l1来训练深度卷积神经网络,获得网络模型参数;
[0050]
具体地,在步骤3中包括如下步骤:
[0051]
构建多尺度结构相似性ms-ssim为:
[0052][0053]
其中是区域中间像素值;
[0054]
构建l1损失函数为:
[0055][0056]
其中p是像素值,x(p)是预测图像的像素值,y(p)是标签图像的像素值;
[0057]
构建优化目标函数,该优化目标函数为混合损失函数:
[0058][0059]
其中α是权重系数,是计算ms-ssim中的第m个尺度的高斯核;
[0060]
利用反向传播算法,求解目标函数关于系数的偏导数,同时对深度卷积神经网络各层参数利用随机梯度下降进行参数更新学习;
[0061]
步骤4:利用训练后的深度卷积神经网络模型对所述测试集进行预测,网络输出即为融合后的高质量图像。
[0062]
在本实施方式中,模型训练完成后,通过输入测试图像,网络对测试图像进行计算,输出为高质量融合图像。
[0063]
本发明还提供一种眼底视网膜octa图像融合系统,包括:
[0064]
图像采集和预处理模块,用于采集眼底视网膜octa图像数据,对同一只眼睛同一区域采集10组数据,然后对图像进行预处理;
[0065]
深度卷积神经网络模型构建模块,用于搭建深度卷积神经网络模型,对深度卷积神经网络模型进行训练;
[0066]
混合损失函数构建模块,用于构建混合损失函数,通过所述混合损失函数对octa图像的小血管进行提取,利用混合损失函数计算小血管图像的多尺度结构相似性和平均绝对误差l1来训练深度卷积神经网络,获得网络模型参数;
[0067]
图像融合模块,用于利用训练后的深度卷积神经网络模型对测试集图像进行预测,网络输出即为融合后的高质量图像。
[0068]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。