1.本发明涉及巡航决策技术领域,尤其是一种自适应巡航决策系统、方法、计算机设备和计算机可读存储介质。
背景技术:
2.近年来,高科技技术蓬勃发展,驱动汽车由单纯交通运输工具逐步向智能移动空间转变的新一代汽车。智能驾驶的行为中,车道内自适应巡航行为是最基础的,负责从出发地点到目的地,给出合适的速度控制指令,由控制层执行,从而引导车辆的行驶。
3.智能车行驶过程中,为了向乘客提供舒适的驾驶体验,并使周围的驾驶员能够更好地理解本车的行为,自适应巡航算法的驾驶风格应接近人类驾驶员。
4.从现有的技术来看,自适应巡航控制算法主要分为基于规则的自适应巡航控制算法,仅有少数专利基于学习的自适应巡航控制算法,且算法设计考虑较简单。基于规则的自适应巡航系统的控制策略总是在固定的框架中,策略不能通过不同的驾驶员偏好和不同驾驶员的驾驶风格而改变,这降低了基于规则的自适应巡航控制算法的适应性和驾驶员接受程度。
5.在基于学习的自适应巡航控算法设计中,大部分研究者采用单层深度强化学习算法搭建自适应巡航算法,并使用专家估计法设计奖励函数,由于单层强化学习算法不符合人类“决策-执行”的行为模式,且专家估计法设计的奖励函数没有基于真实驾驶数据对奖励函数进行拟人化改进,因此基于这种方法很难进行拟人化的自适应巡航控制算法设计。
6.因此,对自适应巡航的行为进行合理算法设计,给出安全、舒适的驾乘感受具有重要的现实意义。
技术实现要素:
7.发明目的:提供一种能够满足驾乘人员对智能驾驶车辆类人驾驶风格及拟人化体验需求的系统、方法、计算机设备和计算机可读存储介质。
8.技术方案:一种自适应巡航决策系统,适用于自车相对前车的自适应巡航,包括:决策模型建立模块,用于建立网络决策模型,该网络决策模型包括上层决策网络、底层执行网络、奖励函数,奖励函数包括安全性奖励函数、舒适性奖励函数以及跟随性奖励函数;初始化模块,用于初始化环境参数:两车间距、自车速度、两车速度差、自车加速度、两车加速度变化量绝对值;子目标集goals={goal0,goal1,goal2,...,goali,...,goaln},动作集actions={a0,a1,a2,...,ai,...,am};用于获取环境的初始外部状态s
0meta
、初始内部状态s
0controller
;决策执行模块,用于根据输入的外部状态参数s
imeta
,选择初始子目标参数goali,用于获取初始化奖励参数r
imeta
,其中,i为从1至n的整数;用于判断子目标条件是否完成,完成子目标条件为:本车与前车之间的距离小于预设最小值或大于预设最大值,自车速度为0;若未完成子目标条件,用于根据输入的内部状态参数s
jcontroller
,选择初始动作aj,并使初
始动作aj与环境交互,以获得内部状态参数s
j 1controller
,并用于获得与环境交互完成后输出的奖励参数r
jcontroller
,j为动作与环境交互次数,以及用于获得存储记忆{s
jcontroller
,aj,rj,s
j 1controller
,goali};用于使r
imeta
=r
imeta
r
j 1controller
,以获取完成子目标期间奖励函数的累计和;用于使i从1开始循环,到n结束,遍历执行,直至完成子目标条件时结束;用于获得存储记忆{s
imeta
,goali,r
imeta
,s
i 1meta
}。
9.进一步的,在上层决策网络中,s
meta
={egov,dis,δv};goals={-10m,-5m,-2m,-1m,0m,1m,2m,5m,10m}。
10.进一步的,在底层决策网络中,s
controller
={dis,egov,δv,egoa,|ego
at-ego
at 1
|};actions={-3,-2,-1,-0.8,-0.6,-0.4,-0.2,0,0.2,0.4,0.6,0.8,1,2,3},单位为m/s2。
11.进一步的,安全性奖励函数记为r
safe
,r
safe
=min(r
safe1
,r
safe 2
);其中,当自车速度大于前车时,安全性奖励r
safe1
使用ttc-1
作为指标评估安全性,
[0012][0013][0014]
当自车速度小于等于前车且两车间距较小时,安全性奖励r
safe2
使用安全车距d
safe
作为指标评估安全性,
[0015][0016][0017]dsafe
为前车突然减速为0时自车为了不撞车需要保持的车距,t0为人类反应时间,egov0为当前自车速度,a
max
为自车最大减速度;
[0018]
舒适性奖励函数记为
[0019][0020][0021]
跟随性奖励的值为两种跟随奖励的最小值,记为r
follow
=min(r
follow1
,r
follow2
),
[0022][0023]
其中d
safe
为安全距离,d
max
为最大跟车距离,取d
max
=80m;
[0024][0025]
其中δv=aim
v-egov。
[0026]
本发明还提供一种自适应巡航决策算法,适用于自车相对前车的自适应巡航,包括以下步骤:
[0027]
(1)建立网络决策模型,该网络决策模型包括上层决策网络、底层执行网络、奖励函数,奖励函数包括安全性奖励函数、舒适性奖励函数以及跟随性奖励函数;
[0028]
(2)初始化环境参数:两车间距、自车速度、两车速度差、自车加速度、两车加速度变化量绝对值;子目标集goals={goal0,goal1,goal2,...,goali,...,goaln},动作集actions={a0,a1,a2,...,ai,...,am};
[0029]
获取环境的初始外部状态s
0meta
、初始内部状态s
0controller
;
[0030]
(3)根据输入的外部状态参数s
imeta
,选择初始子目标参数goali,初始化奖励参数r
imeta
,其中,i为从1至n中的任一整数;判断是否完成子目标条件:本车与前车之间的距离小于预设最小值或大于预设最大值,自车速度为0;若否,进入第(4)步;
[0031]
(4)根据输入的内部状态参数s
jcontroller
,选择初始动作aj,使初始动作aj与环境交互,获得内部状态参数s
j 1controller
,并获得与环境交互完成后输出的奖励参数r
jcontroller
,j为动作与环境交互次数;
[0032]
(5)获得存储记忆{s
jcontroller
,aj,rj,s
j 1controller
,goali};
[0033]
(6)使r
imeta
=r
imeta
r
j 1controller
,获取完成子目标期间奖励函数的累计和;
[0034]
(7)遍历执行步骤(2)~步骤(6),直至满足(3)的条件结束;
[0035]
(8)获得存储记忆{s
imeta
,goali,r
imeta
,s
i 1meta
}。
[0036]
进一步的,s
meta
={egov,dis,δv};goals={-10m,-5m,-2m,-1m,0m,1m,2m,5m,10m};
[0037]
进一步的,s
controller
={dis,egov,δv,egoa,|ego
at-ego
at 1
|};actions={-3,-2,-1,-0.8,-0.6,-0.4,-0.2,0,0.2,0.4,0.6,0.8,1,2,3},单位为m/s2。
[0038]
进一步的,安全性奖励函数记为r
safe
,r
safe
=min(r
safe1
,r
safe 2
);其中,当自车速度大于前车时,安全性奖励r
safe1
使用ttc-1
作为指标评估安全性,
[0039][0040][0041]
当自车速度小于等于前车且两车间距较小时,安全性奖励r
safe2
使用安全车距d
safe
作为指标评估安全性,
[0042]
[0043][0044]dsafe
为前车突然减速为0时自车为了不撞车需要保持的车距,t0为人类反应时间,ego
v0
为当前自车速度,a
max
为自车最大减速度;
[0045]
舒适性奖励函数记为
[0046][0047][0048]
跟随性奖励的值为两种跟随奖励的最小值,记为r
follow
=min(r
follow1
,r
follow2
),
[0049][0050]
其中d
safe
为安全距离,d
max
为最大跟车距离,取d
max
=80m;
[0051][0052]
其中δv=aim
v-egov。
[0053]
本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述方法的步骤。
[0054]
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
[0055]
有益效果:本发明与现有技术相比,其具有的优点:该自适应巡航决策系统,分为上层决策网络、底层执行网络、奖励函数三个独立的部分,上层决策网络用于确定子目标作为值函数,底层执行网络用于确定算法与环境交互的具体动作作为值函数,最终满足上层决策网络的子目标,通过综合考虑驾驶过程中上层决策与底层执行,比采用单层强化学习算法设计的自适应巡航控制算法拟人化程度更高;并且针对自适应巡航目标要求,奖励函数设计为安全性奖励函数、舒适性奖励函数以及跟随性奖励函数;通过对奖励函数的安全性、舒适性、跟随性系数的迭代修正,得到拟人化的奖励函数,使用拟人化奖励函数训练可以得到拟人化自适应巡航控制算法。从而该自适应巡航决策系统,能够满足驾乘人员对智能驾驶车辆类人驾驶风格及拟人化体验需求,使周围的人类驾驶员能够更好地理解和预测自车行为,能够在保证安全性、舒适性的同时提供拟人的乘车感受。
附图说明
[0056]
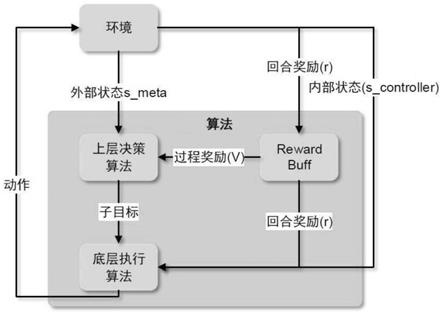
图1为本发明基于分层的自适应巡航系统的结构示意图;
[0057]
图2为基于距离的跟随性奖励计算示意图;
[0058]
图3为自适应巡航算法运行过程示意图。
具体实施方式
[0059]
以下结合附图,对本发明提供的技术方案做详细说明。
[0060]
如图1所示,本发明所述的一种自适应巡航决策系统,适用于自车相对前车的自适应巡航,包括:决策模型建立模块、初始化模块、决策执行模块。
[0061]
该决策模型建立模块用于建立网络决策模型,该网络决策模型包括上层决策网络、底层执行网络、奖励函数,奖励函数包括安全性奖励函数、舒适性奖励函数以及跟随性奖励函数。
[0062]
在该上层决策网络中,为了提高算法在各种条件下的适应能力,上层决策算法根据环境信息决策两车车距变化量δdis,其输入状态为自车速度,两车间距和两车速度差,即该上层决策网络用以根据自车与前车的速度差、自车与前车的两车间距及两车速度差的第一组合集,以选取两车间距变化量δdis作为子目标集,其中,第一组合集记为s
meta
,s
meta
={egov,dis,δv}
ꢀꢀ
(1);结合上层决策网络训练计算量和实际情况,子目标集记为goals,goals={-10m,-5m,-2m,-1m,0m,1m,2m,5m,10m}
ꢀꢀ
(2)。
[0063]
该底层执行网络基于子目标与环境交互以完成子目标,该底层执行网络用以根据两车间距、自车速度、两车速度差、自车加速度以及自车加速度变化量的绝对值的第二组合集,以获取自车加速度作为动作集,第二组合集记为s
controller
,动作集记为action,s
controller
={dis,egov,δv,egoa,|ego
at-ego
at 1
|}
ꢀꢀ
(3);actions={-3,-2,-1,-0.8,-0.6,-0.4,-0.2,0,0.2,0.4,0.6,0.8,1,2,3}
ꢀꢀ
(4),单位为m/s2;第二组合集元素作为输入状态,动作集元素作为输出动作。
[0064]
该自适应巡航控制系统结合跟驰过程中的安全性,舒适性和跟随性设计了如下安全性奖励函数、舒适性奖励函数及跟随性奖励函数:
[0065]
所述安全性奖励函数记为r
safe
,r
safe
=min(r
safe1
,r
safe2
)
ꢀꢀ
(5);其中,当自车速度大于前车时,安全性奖励r
safe1
使用ttc-1
作为指标评估安全性,
[0066][0067][0068]
上式(6)和(7),不适应于自车速度小于或等于自车前车时出现的危险工况,例如两车小间距等速行驶;当自车速度小于等于前车且两车间距较小时,安全性奖励r
safe2
使用安全车距d
safe
作为指标评估安全性,
[0069][0070][0071]dsafe
为前车突然减速为0时自车为了不撞车需要保持的车距,t0为人类反应时间,ego
v0
为当前自车速度,a
max
为自车最大减速度。
[0072]
所述舒适性奖励函数记为所述舒适性奖励函数记为
[0073][0074][0075]
其中,根据iso 15622(2018)标准,自车加速度允许最大值ego
amax
在车速小于5m/s时为4m/s2,在车速大于20m/s时为2m/s2,车速在5m/s和20m/s时均匀变化;自车减速度允许最大值ego
amin
在车速小于5m/s时为5m/s2;在车速大于20m/s时为3.5m/s2;车速在5m/s和20m/s时均匀变化;自车加速度变化率允许最大值jerk
max
在车速小于5m/s时为5m/s3;在车速大于20m/s时为2.5m/s3;车速在5m/s和20m/s时均匀变化。
[0076]
跟驰过程中自车的跟随性主要体现正在距离跟随性和速度跟随性,将跟随性奖励分为基于距离跟随的奖励r
follow1
和基于速度跟随奖励的r
follow2
,如图2所示,所述跟随性奖励的值为两种跟随奖励的最小值,记为r
follow
=min(r
follow1
,r
follow2
),
[0077][0078]
其中d
safe
为安全距离,d
max
为最大跟车距离,取d
max
=80m;
[0079][0080]
其中δv=aim
v-egovꢀꢀ
(15)。
[0081]
该初始化模块用于初始化环境参数:两车间距、自车速度、两车速度差、自车加速度、两车加速度变化量绝对值;子目标集goals={goal0,goal1,goal2,...,goali,...,goaln},动作集actions={a0,a1,a2,...,ai,...,am}。
[0082]
为了实现对上层决策网络、底层执行网络的调用,该初始化模块还用于初始化上层决策网络参数的初始化,及用于底层执行网络参数的初始化,其中,需要初始化的上层决策网络参数包括:神经网络参数θ
metaeval
,θ
metatarget
,贪婪系数∈,贪婪系数变化量δ∈,折扣因子γ
meta
,记忆库d
meta
,记忆库容量l
meta
,子目标个数n
goals
,状态向量维度n
feature meta
;需要初始化的底层执行网络参数包括:神经网络参数θ
controllereval
,θ
controllertarget
,贪婪系数向量[∈1,∈2,...,∈n],贪婪系数变化量向量[δ∈1,δ∈2,...,δ∈n],折扣因子γ
controller
,记忆库d
controller
,记忆库容量l
controller
,动作个数n
action
,状态向量维度n
featurecontroller
;
[0083]
此外,该初始化模块还用于获取环境的初始外部状态s
0meta
、初始内部状态s
0controller
。
[0084]
该决策执行模块用于根据输入的外部状态参数s
imeta
,选择初始子目标参数goali,用于获取初始化奖励参数r
imeta
,其中,i为从1至n的整数;用于判断子目标条件是否完成,完成子目标条件为:本车与前车之间的距离小于预设最小值或大于预设最大值,自车速度为0,其中,预设最小值为1m,预设最大值为80m;若未完成子目标条件,用于根据输入的内部状态参数s
jcontroller
,选择初始动作aj,并使初始动作aj与环境交互,以获得内部状态参数sj 1controller
,并用于获得与环境交互完成后输出的奖励参数r
jcontroller
,j为动作与环境交互次数,以及用于获得存储记忆{s
jcontroller
,aj,rj,s
j 1controller
,goali};用于在controller达到真实驾驶数据的期望特征与模型期望特征的差异最小的学习条件时,进行controller学习;用于在meta达到真实驾驶数据的期望特征与模型期望特征的差异最小的学习条件时,进行meta学习;用于使r
imeta
=r
imeta
r
j 1controller
,以获取完成子目标期间奖励函数的累计和;用于使i从1开始循环,到n结束,遍历执行,直至完成子目标条件时结束;用于获得存储记忆{s
imeta
,goali,r
imeta
,s
i 1meta
}。
[0085]
所述的自适应巡航决策系统,在算法结构中的上层决策与底层执行不是同步的,上层算法的决策频率远低于下层算法的决策频率,只在下层算法完成子目标之后才会决策一次;但由于dqn算法的学习利用的是记忆库中的已有记忆,因此二者的学习频率是一样的,都是在循环的每一步使用从记忆库取样得到的记忆学习。
[0086]
本发明还提供一种自适应巡航决策方法,包括以下步骤:
[0087]
(1)建立网络决策模型,该网络决策模型包括上层决策网络、底层执行网络、奖励函数,奖励函数包括安全性奖励函数、舒适性奖励函数以及跟随性奖励函数;
[0088]
在该上层决策网络中,为了提高算法在各种条件下的适应能力,上层决策算法根据环境信息决策两车车距变化量δdis,其输入状态为自车速度,两车间距和两车速度差,即该上层决策网络用以根据自车与前车的速度差、自车与前车的两车间距及两车速度差的第一组合集,以选取两车间距变化量δdis作为子目标集,其中,第一组合集记为s
meta
,s
meta
={egov,dis,δv}
ꢀꢀ
(1);结合上层决策网络训练计算量和实际情况,子目标集记为goals,goals={-10m,-5m,-2m,-1m,0m,1m,2m,5m,10m}
ꢀꢀ
(2)。
[0089]
由于上层决策算法在训练中获取的样本相对底层执行算法较少,且输入变量和输出变量维度较低,从而上层决策算法使用大小为10*10*10的神经网络作为估值网络和目标网络以降低训练难度。
[0090]
该底层执行网络基于子目标与环境交互以完成子目标,该底层执行网络用以根据两车间距、自车速度、两车速度差、自车加速度以及自车加速度变化量的绝对值的第二组合集,以获取自车加速度作为动作集,第二组合集记为s
controller
,动作集记为action,s
controller
={dis,egov,δv,egoa,|ego
at-ego
a t 1
|}
ꢀꢀ
(3);actions={-3,-2,-1,-0.8,-0.6,-0.4,-0.2,0,0.2,0.4,0.6,0.8,1,2,3}
ꢀꢀ
(4),单位为m/s2;第二组合集元素作为输入状态,动作集元素作为输出动作。
[0091]
底层执行算法相比上层决策算法有更高的状态维度、更多的动作选择、更复杂的环境信息,以及更丰富的交互样本,因此需要使用更大的神经网络作为估值网络和目标网络,该底层执行算法的网络大小为10*20*50*20*10。
[0092]
该自适应巡航控制系统的算法设计中需要考虑三个重要指标:安全性、舒适性以及跟随性,其中安全性指避免自车和前车发生碰撞的能力;舒适性指自适应巡航算法运行过程中乘员舒适程度的度量;跟随性指自车保持对前车跟随的能力。这三个指标在自适应巡航算法运行过程中会相互影响:提高安全性意味着加大两车间距,这会在一定程度上降低跟随性,而调整车距过程中的加速度和加速度变化率又会降低乘员舒适性,基于此,该自适应巡航控制系统结合跟驰过程中的安全性,舒适性和跟随性设计了如下安全性奖励函数、舒适性奖励函数及跟随性奖励函数:
[0093]
安全性奖励函数记为r
safe
,r
safe
=min(r
safe1
,r
safe 2
)
ꢀꢀ
(5);其中,当自车速度大于前车时,安全性奖励r
safe1
使用ttc-1
作为指标评估安全性,
[0094][0095][0096]
当自车速度小于等于前车且两车间距较小时,安全性奖励r
safe2
使用安全车距d
safe
作为指标评估安全性,
[0097][0098][0099]dsafe
为前车突然减速为0时自车为了不撞车需要保持的车距,t0为人类反应时间,ego
v0
为当前自车速度,a
max
为自车最大减速度;
[0100]
舒适性奖励函数记为
[0101][0102][0103]
其中,自车加速度允许最大值ego
amax
在车速小于5m/s时为4m/s2,在车速大于20m/s时为2m/s2,车速在5m/s和20m/s时均匀变化;自车减速度允许最大值ego
amin
在车速小于5m/s时为5m/s2;在车速大于20m/s时为3.5m/s2;车速在5m/s和20m/s时均匀变化;自车加速度变化率允许最大值jerk
max
在车速小于5m/s时为5m/s3;在车速大于20m/s时为2.5m/s3;车速在5m/s和20m/s时均匀变化;
[0104]
跟随性奖励的值为两种跟随奖励的最小值,记为r
follow
=min(r
follow1
,r
follow2
)
ꢀꢀ
(12),
[0105][0106]
其中dsafe为安全距离,dmax为最大跟车距离,取dmax=80m;
[0107][0108]
其中δv=aim
v-egovꢀꢀ
(15)。
[0109]
(2)初始化环境参数:两车间距、自车速度、两车速度差、自车加速度、两车加速度
变化量绝对值;子目标集goals={goal0,goal1,goal2,...,goali,...,goaln},动作集actions={a0,a1,a2,...,ai,...,am};获取环境的初始外部状态s
0meta
、初始内部状态s
0controller
;在本步骤(2)中,为了实现调用网络决策模型的上层决策网络、底层执行网络,还包括对上层决策网络参数初始化,以及对底层执行网络参数初始化的步骤,其中需要初始化的上层决策网络参数包括:神经网络参数θ
metaeval
,θ
metatarget
,贪婪系数∈,贪婪系数变化量δ∈,折扣因子γ
meta
,记忆库d
meta
,记忆库容量l
meta
,子目标个数n
goals
,状态向量维度n
feature meta
;需要初始化的底层执行网络参数包括:神经网络参数θ
controllereval
,θ
controllertarget
,贪婪系数向量[∈1,∈2,...,∈n],贪婪系数变化量向量[δ∈1,δ∈2,...,δ∈n],折扣因子γ
controller
,记忆库d
controller
,记忆库容量l
controller
,动作个数n
action
,状态向量维度n
featurecontroller
;
[0110]
(3)根据输入的外部状态参数s
imeta
,选择初始子目标参数goali,初始化奖励参数r
imeta
,其中,i为从1至n中的任一整数;判断是否完成子目标条件:本车与前车之间的距离小于预设最小值或大于预设最大值,自车速度为0,其中预设最小值为1m,预设最大值为80m;若否,进入第(4)步;
[0111]
(4)根据输入的内部状态参数s
jcontroller
,选择初始动作aj,使初始动作aj与环境交互,获得内部状态参数s
j 1controller
,并获得与环境交互完成后输出的奖励参数r
jcontroller
,j为动作与环境交互次数;
[0112]
(5)获得存储记忆{s
jcontroller
,aj,rj,s
j 1controller
,goali};
[0113]
(6)在controller达到真实驾驶数据的期望特征与模型期望特征的差异最小的学习条件时,进行controller学习;
[0114]
(7)在meta达到真实驾驶数据的期望特征与模型期望特征的差异最小的学习条件时,进行meta学习;
[0115]
(8)使r
imeta
=r
imeta
r
j 1controller
,获取完成子目标期间奖励函数的累计和;
[0116]
(9)遍历执行步骤(2)~步骤(8),直至满足(3)的条件结束;
[0117]
(10)获得存储记忆{s
imeta
,goali,r
imeta
,s
i 1meta
}。
[0118]smeta
={egov,dis,δv};goals={-10m,-5m,-2m,-1m,0m,1m,2m,5m,10m};
[0119]scontroller
={dis,egov,δv,egoa,|ego
at-ego
at 1
|};actions={-3,-2,-1,-0.8,-0.6,-0.4,-0.2,0,0.2,0.4,0.6,0.8,1,2,3},单位为m/s2。
[0120]
本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述方法的步骤。
[0121]
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
[0122]
在该自适应巡航决策系统、方法、计算机设备和计算机可读存储介质中,该系统分为上层决策网络、底层执行网络、奖励函数三个独立的部分,上层决策网络用于确定子目标作为值函数,底层执行网络用于确定算法与环境交互的具体动作作为值函数,最终满足上层决策网络的子目标,通过综合考虑驾驶过程中上层决策与底层执行,比采用单层强化学习算法设计的自适应巡航控制算法拟人化程度更高;并且针对自适应巡航目标要求,奖励函数设计为安全性奖励函数、舒适性奖励函数以及跟随性奖励函数;通过对奖励函数的安全性、舒适性、跟随性系数的迭代修正,得到拟人化的奖励函数,使用拟人化奖励函数训练
可以得到拟人化自适应巡航控制算法。从而该自适应巡航决策系统,能够满足驾乘人员对智能驾驶车辆类人驾驶风格及拟人化体验需求,使周围的人类驾驶员能够更好地理解和预测自车行为,能够在保证安全性、舒适性的同时提供拟人的乘车感受。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
