1.本技术涉及数据处理领域,尤其涉及一种程序崩溃分析聚合方法、装置、计算机设备及计算机可读存储介质。
背景技术:
2.随着互联网技术的快速发展,设备上可安装的应用软件越来越多。各平台的差异性使用户在使用应用软件的时候,经常出现线上崩溃的情况,并借助外部平台分析。
3.现有的程序崩溃分析聚合平台,具有以下缺点:(1)数据安全性差;(2)容易受到外部平台的“系统不可用”隐患;(3)问题定位和聚合效率低下且不准确。
技术实现要素:
4.有鉴于此,本技术实施例的目的是提供一种程序崩溃分析聚合方法、装置、计算机设备、计算机可读存储介质,以及程序崩溃分析聚合系统,可以解决上述问题。
5.本技术实施例的一个方面提供了一种程序崩溃分析聚合方法,包括:
6.接收用户设备的程序崩溃信息;
7.过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息;
8.解析过滤后的程序崩溃信息以得到标签;
9.将所述过滤后的程序崩溃信息及所述标签存储到数据库中,以供查询、读取和/或聚合分析。
10.可选的,所述过滤所述用户设备的程序崩溃信息,包括:
11.根据预先设置的多个字段,过滤所述用户设备的程序崩溃信息;
12.其中,所述多个字段包括基础字段和扩展字段;
13.所述扩展字段包括崩溃类型、堆栈信息、崩溃描述、崩溃页面、崩溃时的设备运行状态信息。
14.可选的,所述标签包括第一标签和第二标签,所述过滤后的程序崩溃信息包括堆栈信息和崩溃描述;
15.所述解析过滤后的程序崩溃信息以得到标签,包括:
16.将所述堆栈信息传递至解析层,通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息;
17.根据解析后的堆栈信息生成第一标签;
18.根据所述崩溃描述生成第二标签;
19.将所述第一标签和所述第二标签写入到所述数据库;
20.其中,所述第一标签和所述第二标签在所述数据库均与所述程序崩溃信息相关联。
21.可选的,所述根据解析后的堆栈信息生成第一标签,包括:
22.删除所述解析后的堆栈信息中的无效信息,得到与程序本身关联的有效堆栈信
息;其中,所述无效信息至少包括以下一项或多项:与操作系统关联的信息、数字;及
23.根据与所述程序本身关联的有效堆栈信息,通过哈希算法计算得到所述第一标签。
24.可选的,所述用户设备为ios设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:
25.通过所述堆栈信息中的符号表的标识和偏移量,以及构建ipa的符号表文件,查询目标函数名;
26.其中,所述偏移量为发生崩溃的地址和预设基准地址之差;
27.其中,所述目标函数名对应的函数用于调用出现崩溃的对象。
28.可选的,所述用户设备为android设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:
29.通过所述堆栈信息中的混淆数据和构建apk的mapping文件,查询混淆前数据;
30.其中,所述混淆数据为程序运行时的类名;
31.其中,所述混淆前数据包括目标函数名,该目标函数名对应的函数用于调用出现崩溃的对象。
32.可选的,还包括:
33.基于第一标签和第二标签,对所述数据库中预设时段的程序崩溃信息进行聚合,得到多个聚合数据;同一个聚合数据中的每条数据具有相同的第一标签和/或相同的第二标签;
34.基于所述多个聚合数据生成分析结果,所述分析结果包括导致程序崩溃的一个或多个问题;及
35.将所述分析报告发送到与所述一个或多个问题关联的一个或多个目标群组中。
36.本技术实施例的又一个方面提供了一种程序崩溃分析聚合装置,包括:
37.接收模块,用于接收用户设备的程序崩溃信息;
38.分发模块,用于过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息;
39.解析模块,用于解析过滤后的程序崩溃信息以得到标签;
40.存储模块,用于将所述过滤后的程序崩溃信息及所述标签存储到数据库中,以供查询、读取和/或聚合分析。
41.本技术实施例的又一个方面提供了一种计算机设备,所述计算机设备包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时用于实现如上所述的程序崩溃分析聚合方法的步骤。
42.本技术实施例的又一个方面提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序可被至少一个处理器所执行,以使所述至少一个处理器执行如上所述的程序崩溃分析聚合方法的步骤。
43.本技术实施例的又一个方面提供了一种程序崩溃分析聚合系统,包括:
44.数据传输层,用于接收用户设备的程序崩溃信息;
45.数据消费层,用于接收和过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息;
46.数据清洗层,用于解析过滤后的程序崩溃信息以得到标签;
47.存储层,用于存储所述过滤后的程序崩溃信息及所述标签,以供查询、读取和/或聚合分析。
48.可选的,所述数据消费层,还用于:
49.根据预先设置的多个字段,过滤所述用户设备的程序崩溃信息;
50.其中,所述多个字段包括基础字段和扩展字段;
51.所述扩展字段包括崩溃类型、堆栈信息、崩溃描述、崩溃页面、崩溃时的设备运行状态信息。
52.可选的,所述标签包括第一标签和第二标签,所述过滤后的程序崩溃信息包括堆栈信息和崩溃描述;
53.所述数据清洗层,还用于:
54.将所述堆栈信息传递至解析层,通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息;
55.根据解析后的堆栈信息生成第一标签;
56.根据所述崩溃描述生成第二标签;
57.将所述第一标签和所述第二标签写入到所述存储层;
58.其中,所述第一标签和所述第二标签在所述存储层均与所述程序崩溃信息相关联。
59.可选的,所述根据解析后的堆栈信息生成第一标签,包括:
60.删除所述解析后的堆栈信息中的无效信息,得到与程序本身关联的有效堆栈信息;其中,所述无效信息至少包括以下一项或多项:与操作系统关联的信息、数字;及
61.根据与所述程序本身关联的有效堆栈信息,通过哈希算法计算得到所述第一标签。
62.可选的,所述用户设备为ios设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:
63.通过所述堆栈信息中的符号表的标识和偏移量,以及构建ipa的符号表文件,查询目标函数名;
64.其中,所述偏移量为发生崩溃的地址和预设基准地址之差;
65.其中,所述目标函数名对应的函数用于调用出现崩溃的对象。
66.可选的,所述用户设备为android设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:
67.通过所述堆栈信息中的混淆数据和构建apk的mapping文件,查询混淆前数据;
68.其中,所述混淆数据为程序运行时的类名;
69.其中,所述混淆前数据包括目标函数名,该目标函数名对应的函数用于调用出现崩溃的对象。
70.可选的,还包括自动诊断系统,用于:
71.基于第一标签和第二标签,对所述存储层中预设时段的程序崩溃信息进行聚合,得到多个聚合数据;同一个聚合数据中的每条数据具有相同的第一标签和/或相同的第二标签;及
72.基于所述多个聚合数据生成分析结果,所述分析结果包括导致程序崩溃的一个或多个问题;及
73.将所述分析报告发送到与所述一个或多个问题关联的一个或多个目标群组中。
74.本技术提供的程序崩溃分析聚合方法、装置、设备、计算机可读存储介质,以及程序崩溃分析聚合系统,包括以下优势:
75.(1)实现闭环全流程,确保了数据的安全性,尤其是程序敏感数据的安全性;
76.(2)基于闭环全流程,不再依赖外部平台的数据管理,消除外部平台的“系统不可用”隐患;
77.(3)通过解析过滤后的程序崩溃信息以得到标签,并将标签一并存入数据库中,因此,数据库的每条数据可以通过标签进行聚合,从而可以高效且准确地定位出问题并生成分析报告。
附图说明
78.图1示意性示出了根据本技术实施例一的程序崩溃分析聚合系统的架构图;
79.图2示意性示出了自动诊断系统的工作流;
80.图3示意性示出了根据本技术实施例二的程序崩溃分析聚合系统的流程图;
81.图4示意性示出了图3中步骤s302的子流程图;
82.图5示意性示出了图3中步骤s304的子流程图;
83.图6示意性示出了图5中步骤s502的子流程图;
84.图7示意性示出了图5中步骤s500的子流程图;
85.图8示意性示出了图5中步骤s500的另一子流程图;
86.图9示意性示出了根据本技术实施例二的程序崩溃分析聚合方法的新增步骤流程图;
87.图10示意性示出了根据本技术实施例三的程序崩溃分析聚合装置的框图;
88.图11示意性示出了根据本技术实施例四的适于实现程序崩溃分析聚合方法的计算机设备的硬件架构示意图。
具体实施方式
89.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本技术,并不用于限定本技术。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
90.需要说明的是,在本技术实施例中涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本技术要求的保护范围之内。
91.在本技术的描述中,需要理解的是,步骤前的数字标号并不标识执行步骤的前后
顺序,仅用于方便描述本技术及区别每一步骤,因此不能理解为对本技术的限制。
92.本技术人了解到:
93.线上崩溃问题,一般借助第三方平台,如bugly,firbase
…
,并存在以下几个问题:
94.1).权限无法收敛。部分人员离职后,依旧持有权限查看app敏感数据。
95.2).维护力度逐渐变低,会逐渐出现”无法正常解析“的情况。
96.3).无法定制需求,三方平台的数据过于封闭,无法正常消费拓展业务。
97.4).无法业务隔离,崩溃均为大盘问题,无法将不同的问题,划分给不同的业务。
98.本技术旨在提供程序崩溃分析聚合方案,在于闭环流程、堆栈解析和聚合的实现、以及衍生产物系统的实现。所述程序崩溃分析聚合方案具体可以参考下述实施例。
99.实施例一
100.如图1所示,本技术实施例提供了一种程序崩溃分析聚合系统,包括:
101.(1)数据传输层2,用于接收用户设备的程序崩溃信息。
102.数据传输层2可以通过kafka系统或其他消息系统实现,用于接收大量用户终端的程序崩溃信息。其中,kafka系统是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(常见可以用于web/nginx日志、访问日志,消息服务等等。kafka系统主要应用场景包括日志收集系统和消息系统。
103.作为示例,所述用户设备可以被配置为上报程序崩溃信息。其中,用户设备可以包括移动设备,平板设备,膝上型计算机,智能设备(例如,智能手表,智能眼镜),虚拟现实耳机,游戏设备,机顶盒,数字流设备,机器人,车载终端,智能电视,电子书阅读器,mp4(运动图像专家组音频层iv)播放器等。用户设备可以运行windows系统、安卓(android
tm
)系统或ios系统等。用户可以根据需要安装各种应用程序安装包,从而得到实现各种特定功能的应用程序。所述用户设备中可以预先设置有埋点程序,该埋点程序可以上报程序崩溃信息。
104.以从用户设备a上报程序崩溃信息为例,可以在用户设备a植入埋点程序。埋点又称事件追踪(event tracking),可以针对设备中的行为或事件进行捕获、处理和发送等。在检测用户设备a的程序出现崩溃的情形下,该用户设备a可以将该程序的崩溃信息缓存至本地文件中。待再次启动程序后,将崩溃信息上报至所述数据传输层2。举例来说,可以基于应用性能管理(application performance management,apm)分流到kafka系统中,以按照指定的调用链路执行。
105.(2)数据消费层4,用于接收和过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息。
106.数据消费层4负责消息的过滤和分发。
107.即:从数据传输层2获取崩溃相关的信息,并将过滤得到的“有效数据”传递到数据清洗层6。
108.作为可选的实施例,数据消费层4还用于:根据预先设置的多个字段,过滤所述用户设备的程序崩溃信息;其中,所述多个字段包括基础字段和扩展字段;所述扩展字段包括崩溃类型、堆栈信息、崩溃描述、崩溃页面、崩溃时的设备运行状态信息。所述基础字段可以包括以下字段:崩溃发生时间、设备型号、程序版本、系统版本、程序发行渠道等。崩溃时的设备运行状态信息可以包括以下字段:崩溃的内存信息、cpu信息、磁盘信息等。在本可选的实施例中,通过过滤出可用于崩溃分析的有效信息,可以降低无效信息的干扰和降低系统
负担。
109.(3)数据清洗层6,用于解析过滤后的程序崩溃信息以得到标签。
110.所述过滤后的程序崩溃信息包括堆栈信息、崩溃描述等。
111.其中,所述堆栈信息用于记录和追溯函数调用过程,如程序崩溃时所调用的函数。但是,由用户设备直接提供的堆栈信息不可读,因此需要进行解析以得到可读的堆栈信息。进而,通过该可读的堆栈信息进行异常、问题的归类和标签化。因此,通过标签可以确定同一类问题的各条程序崩溃信息,方便查询和管理。
112.作为可选的实施例,所述标签包括第一标签和第二标签,所述过滤后的程序崩溃信息包括堆栈信息和崩溃描述;
113.所述数据清洗层6,还用于:
114.将所述堆栈信息传递至解析层,通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息;
115.根据解析后的堆栈信息生成第一标签;
116.根据所述崩溃描述生成第二标签;
117.将所述第一标签和所述第二标签写入到所述存储层8;
118.其中,所述第一标签和所述第二标签在所述存储层均与所述程序崩溃信息相关联。
119.在上述可选的实施例中,为每条程序崩溃信息配置第一标签和第二标签,是有如下考虑:在部分情况下,解析后的堆栈信息为空,无法设置有效标签,因此设置第二标签作为补充。另外,在第一标签和第二标签相互印证的情形下,利于有效聚合。
120.需要说明的是,第一标签和第二标签可以为哈希值或基于其他算法得到的值。哈希值是通过哈希算法(如md5、sha-1),将一段较长的数据(string)映射为较短小的数据,这段小数据即是哈希值。哈希值具有唯一性,如不同的崩溃描述各自对应的哈希值不同,相同的崩溃描述对应同一哈希值,因此可以用于后续分类、聚合。
121.不同类型的用户设备的堆栈信息不同,以下提供几种示例性的解析方式。
122.作为可选的实施例,所述用户设备为ios设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:通过所述堆栈信息中的符号表的标识和偏移量,以及构建ipa的符号表文件,查询目标函数名;其中,所述偏移量为发生崩溃的地址和预设基准地址之差;其中,所述目标函数名对应的函数用于调用出现崩溃的对象。
123.ios设备在构建ipa(apple程序应用文件,iphoneapplication)后,会产生一个副文件dsym符号表文件(每个符号表对应一个通用唯一标识码uuid),内部存放函数名 偏移量。在对符号表文件解析后,将映射关系信息 uuid存入数据库(如mysql)中。
124.当获取到所述堆栈信息时,通过所述堆栈信息的符号表uuid 偏移量(发生异常的地址-基地址计算),从mysql数据库反查目标函数名,即快速地解析出ios设备反馈的目标函数名。
125.作为可选的实施例,所述用户设备为android设备;所述通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息,包括:通过所述堆栈信息中的混淆数据和构建apk的mapping文件,查询混淆前数据;其中,所述混淆数据为程序运行时的类名;其中,所述混淆前数据包括目标函数名,该目标函数名对应的函数用于调用出现崩溃的对象。
126.android设备在构建apk(android application package,android应用程序包)后,会产生一个副产物mapping文件,安装包实际运行时的类名classname为混淆数据,例如:a.b.c.xx,x需要通过mapping里面的内容进行反查解析。在本实施例中,针对mapping文件进行解析,将解析得到的映射关系存入数据库(如mysql)。
127.当获取到所述堆栈信息时,针对混淆后的信息,在mysql数据库中所引出混淆前的数据,以反查得到目标函数名,即快速地解析出android设备反馈的目标函数名。
128.作为可选的实施例,所述根据解析后的堆栈信息生成第一标签,包括:删除所述解析后的堆栈信息中的无效信息,得到与程序本身关联的有效堆栈信息;其中,所述无效信息至少包括以下一项或多项:与操作系统关联的信息、数字;及根据与所述程序本身关联的有效堆栈信息,通过哈希算法计算得到所述第一标签。通过解析后的堆栈信息进行清洗:(1)对一些二进制偏移量,以及一些数字、系统符号表信息等浮动噪音数据过滤,可以确保同一问题导致崩溃的多条程序崩溃信息各自对应的第一标签(哈希值)相同,确保有效聚合。(2)清洗掉与操作系统关联的信息,只保留程序自身关联的信息,快速排查程序本身的问题。
129.需要说明的是,数据清洗层6的数据清洗规则和解析规则等可以通过配置文件定义。且,数据清洗层6内各种功能可以实现插件化,从而实现功能的自动定制和扩展。
130.(4)存储层8,用于存储所述过滤后的程序崩溃信息及所述标签,以供查询、读取和/或聚合分析。
131.存储层8可以是基于elasticsearch、clickhouse、hive、mysql等。
132.其中,elasticsearch是一个基于lucene的搜索服务器,其提供了一个分布式多用户能力的全文搜索引擎,基于restful web接口。clickhouse从olap场景需求出发,定制开发了一套高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据分区、主备复制等功能。hive是基于hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在hadoop中的大规模数据的机制。mysql是关系型数据库管理系统,是rdbms(relational database management system:关系数据库管理系统)应用软件之一。
133.存储层8中的每条数据包括:过滤后的程序崩溃信息,标签(第一标签、第二标签)。
134.基于每条数据的标签,可以对每条数据进行归类,从而具有相同标签的多条数据聚合。
135.所述存储层8可以为第三方服务平台提供数据服务。
136.第三方服务平台可以分析崩溃的变化趋势,以及可以对某一类问题进行查询定位。
137.在具体应用时,可以通过前端页面显示崩溃的变化趋势,以及对某一类问题的查询和定位。该前端页面上还配置有多个组件,如“程序版本”、“系统版本”、“设备型号”、“网络类型”、“崩溃类型”、“崩溃页面”、“进程”、“线程”等组件。以“系统版本”为例,当用户触发该组件,则列出出现崩溃的各个系统版本,并分析和显示各个系统版本的崩溃数量、占比等。且,该前端页面还配置有下载组件,通过该下载组件可以下载被选系统版本的程序崩溃信息。
138.(5)可选的,所述系统还可以定制化自动诊断系统10。
139.自动诊断系统10,用于:根据存储层8中的每条数据的标签进行分类和聚合操作。
140.作为示例,自动诊断系统10用于:
141.基于第一标签和第二标签,对所述存储层中预设时段的程序崩溃信息进行聚合,得到多个聚合数据;同一个聚合数据中的每条数据具有相同的第一标签和/或相同的第二标签;
142.基于所述多个聚合数据生成分析结果,所述分析结果包括导致程序崩溃的一个或多个问题;及
143.将所述分析报告发送到与所述一个或多个问题关联的一个或多个目标群组中。
144.自动诊断系统10可以在线诊断,也可以离线诊断。其中,在线诊断是指根据实时增量数据(如,预设时段)进行自动检测和诊断。在线诊断就不会停止,在线诊断的诊断范围大,显示信息的内容也多。离线诊断,是指根据离线数据进行自动检测和诊断。通过离线诊断可以对海量数据异步处理,适用于后台全量分析。
145.如图2所示,自动诊断系统10可以用于包括:
146.当线上发生异常后,触发自动诊断/分析服务;
147.自动诊断/分析服务针对异常时间段,拉取出大量用户数据(全链路监控数据、用户日志或其他数据,其中,全链路监控数据可以包括程序崩溃信息)进行自动分析,得出分析结果;
148.基于分析结果生成分析报告,并将所述分析报告推送至目标群组,如即时通讯群组。
149.示例性,所述分析报告可以如下:“150.崩溃告警:
151.应用:xx设备型号
152.版本:64700100
153.首次触发时间:2021-11-0810:42:21
154.当前触发时间:2021-11-0810:43:36
155.影响范围:
156.最近5分钟,共计影响用户166人,启动总用户数75067人,崩溃率0.22%。
157.问题定位:(最近5分钟数据)
158.按异常类型排序
159.第一类异常占比:90.70%;
160.第二类异常占比:5.81%;
161.第三类异常占比:1.16%;
162.按崩溃信息排序
163.第一类崩溃占比:90.12%;
164.第二类崩溃占比:5.81%;
165.…”
。
166.在上述实施例中,可以根据定位出的问题,将分析报告发送给相应的目标群组,从而实现业务隔离,崩溃均为大盘问题,可以将不同的问题,划分给不同的群组。
167.在示例性的实施例中,基于存储层8还可以定制化业务方告警系统、堆栈解析平台等。其中,堆栈解析平台用于堆栈解析、anr(application not responding,应用程序无响
应)解析、卡顿分析、内存分析、磁盘分析、操作系统分析等。在android上,应用程序有一段时间响应不够灵敏,系统会向用户显示一个对话框,这个对话框称作anr对话框。用户可以选择让程序继续运行或退出。
168.需要说明的是,上述各层通过服务器实现,如机架式服务器、刀片式服务器、塔式服务器或机柜式服务器(包括独立的服务器,或者多个服务器所组成的服务器集群)等。
169.另外,上述各层之间通过一个或多个网络进行连接。其中,所述一个或多个网络可以包括各种网络设备,如路由器,交换机,多路复用器,集线器,调制解调器,网桥,中继器,防火墙,代理设备和/或等。一个或多个网络也可以包括物理链路,如同轴电缆链路,双绞线电缆链路,光纤链路,它们的组合和/或类似物,也可以包括无线链路,如蜂窝链路,卫星链路,wi-fi链路和/或类似物。
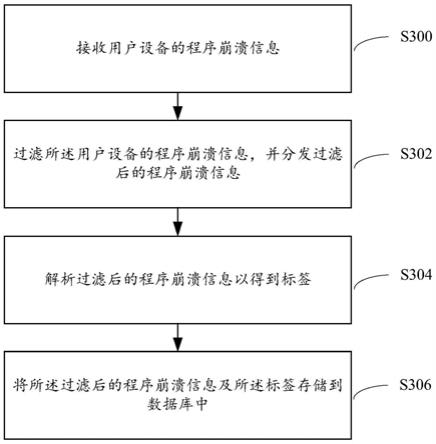
170.上面具体介绍了数据传输层2、数据消费层4、数据清洗层6、存储层8、自动诊断系统10。
171.本技术实施例提供的程序崩溃分析聚合系统,包括如下优点:
172.(1)通过数据传输层2、数据消费层4、数据清洗层6、存储层8的内部链条,实现了闭环全流程,从而确保了数据的安全性,尤其是程序敏感数据的安全性;
173.(2)由于采用上述闭环流程,不再依赖外部平台的数据管理,消除外部平台的“系统不可用”隐患;
174.(3)数据清洗层6实时更新解析规则,通过数据清洗层6确保堆栈数据的清洗和有效解析;
175.(4)可以通过定制化自动诊断系统、业务线自定义规则的监控/告警,拓展数据处理功能;
176.(5)可以通过标签进行聚合,聚合度高且准确,可以高效且准确地定位出问题并生成分析报告;
177.(6)可以根据定位出的问题,将分析报告发送给相应的目标群组,从而实现业务隔离。
178.实施例二
179.本实施例提供了一种程序崩溃分析聚合方法,具体细节可参考实施例一。
180.图3示意性示出了根据本技术实施例二的程序崩溃分析聚合方法的流程图。
181.如图3所示,该程序崩溃分析聚合方法可以包括步骤s300~s306,其中:
182.步骤s300,接收用户设备的程序崩溃信息。
183.步骤s302,过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息。
184.步骤s304,解析过滤后的程序崩溃信息以得到标签。
185.步骤s306,将所述过滤后的程序崩溃信息及所述标签存储到数据库中,以供查询、读取和/或聚合分析。
186.本技术实施例提供的程序崩溃分析聚合方法,包括如下优点:
187.(1)通过上述步骤实现闭环全流程,确保了数据的安全性,尤其是程序敏感数据的安全性;
188.(2)由于采用上述闭环流程,不再依赖外部平台的数据管理,消除外部平台的“系统不可用”隐患;
189.(3)通过解析过滤后的程序崩溃信息以得到标签,并将标签一并存入数据库中,因此,数据库的每条数据可以通过标签进行聚合,从而高效且准确地定位出问题并生成分析报告;
190.(4)可以通过定制化自动诊断系统、业务线自定义规则的监控/告警,拓展数据处理功能。
191.作为可选的实施例,如图4所示,步骤s302可以如下步骤实现:
192.步骤s400,根据预先设置的多个字段,过滤所述用户设备的程序崩溃信息;
193.其中,所述多个字段包括基础字段和扩展字段;
194.所述扩展字段包括崩溃类型、堆栈信息、崩溃描述、崩溃页面、崩溃时的设备运行状态信息。
195.其中,所述基础字段可以包括以下字段:崩溃发生时间、设备型号、程序版本、系统版本、程序发行渠道等。崩溃时的设备运行状态信息可以包括以下字段:崩溃的内存信息、cpu信息、磁盘信息等。在本可选的实施例中,通过过滤出可用于崩溃分析的有效信息,从而可以降低无效信息的干扰和降低系统负担。
196.作为可选的实施例,所述标签包括第一标签和第二标签,所述过滤后的程序崩溃信息包括堆栈信息和崩溃描述;
197.如图5所示,步骤s304可以如下步骤实现:
198.步骤s500,将所述堆栈信息传递至解析层,通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息;
199.步骤s502,根据解析后的堆栈信息生成第一标签;
200.步骤s504,根据所述崩溃描述生成第二标签;
201.步骤s506,将所述第一标签和所述第二标签写入到所述数据库;
202.其中,所述第一标签和所述第二标签在所述数据库均与所述程序崩溃信息相关联。
203.在上述可选的实施例中,为每条程序崩溃信息配置第一标签和第二标签,是以后如下考虑:在部分情况下,解析后的堆栈信息为空,无法设置有效标签,因此设置第二标签作为补充。另外,在第一标签和第二标签相互印证的情形下,利于有效聚合。
204.作为可选的实施例,如图6所示,步骤s502可以如下步骤实现:
205.步骤s600,删除所述解析后的堆栈信息中的无效信息,得到与程序本身关联的有效堆栈信息;其中,所述无效信息至少包括以下一项或多项:与操作系统关联的信息、数字;及
206.步骤s602,根据与所述程序本身关联的有效堆栈信息,通过哈希算法计算得到所述第一标签。
207.上述对解析后的堆栈信息进行清洗:(1)对一些二进制偏移量,以及一些数字、系统符号表信息等浮动噪音数据过滤,可以确保同一问题导致崩溃的多条程序崩溃信息各自对应的第一标签(哈希值)相同,确保有效聚合。(2)清洗掉与操作系统关联的信息,只保留程序自身关联的信息,快速排查程序本身的问题。
208.作为可选的实施例,所述用户设备为ios设备;如图7所示,步骤s500可以如下步骤实现:
209.步骤s700,通过所述堆栈信息中的符号表的标识和偏移量,以及构建ipa的符号表文件,查询目标函数名;
210.其中,所述偏移量为发生崩溃的地址和预设基准地址之差;
211.其中,所述目标函数名对应的函数用于调用出现崩溃的对象。
212.当获取到所述堆栈信息时,通过所述堆栈信息的符号表uuid 偏移量(发生异常的地址-基地址计算),从mysql数据库反查目标函数名,即可有效解析出ios设备反馈的目标函数名。
213.作为可选的实施例,所述用户设备为android设备;如图8所示,步骤s500可以如下步骤实现:
214.步骤s800,通过所述堆栈信息中的混淆数据和构建apk的mapping文件,查询混淆前数据;
215.其中,所述混淆数据为程序运行时的类名;
216.其中,所述混淆前数据包括目标函数名,该目标函数名对应的函数用于调用出现崩溃的对象。
217.具体的,当获取到所述堆栈信息时,针对混淆后的信息,在mysql数据库中所引出混淆前的数据,以反查得到目标函数名,即可有效解析出android设备反馈的目标函数名。
218.作为可选的实施例,如图9所示,所述方法还可以包括:
219.步骤s900,基于第一标签和第二标签,对所述数据库中预设时段的程序崩溃信息进行聚合,得到多个聚合数据;同一个聚合数据中的每条数据具有相同的第一标签和/或相同的第二标签;
220.步骤s902,基于所述多个聚合数据生成分析结果,所述分析结果包括导致程序崩溃的一个或多个问题;及
221.步骤s904,将所述分析报告发送到与所述一个或多个问题关联的一个或多个目标群组中。
222.在上述可选的实施例中,可以根据定位出的问题,将分析报告发送给相应的目标群组,从而实现业务隔离,崩溃均为大盘问题,可以将不同的问题,划分给不同的群组。
223.实施例三
224.图10示意性示出了根据本技术实施例三的程序崩溃分析聚合装置的框图。该程序崩溃分析聚合装置可以被分割成一个或多个程序模块,一个或者多个程序模块被存储于存储介质中,并由一个或多个处理器所执行,以完成本技术实施例。本技术实施例所称的程序模块是指能够完成特定功能的一系列计算机程序指令段,以下描述将具体介绍本实施例中各程序模块的功能。
225.如图10所示,该程序崩溃分析聚合装置1000可以包括:
226.接收模块1010,用于接收用户设备的程序崩溃信息;
227.分发模块1020,用于过滤所述用户设备的程序崩溃信息,并分发过滤后的程序崩溃信息;
228.解析模块1030,用于解析过滤后的程序崩溃信息以得到标签;
229.存储模块1040,用于将所述过滤后的程序崩溃信息及所述标签存储到数据库中,以供查询、读取和/或聚合分析。
230.作为可选的实施例,所述分发模块1020,还用于:
231.根据预先设置的多个字段,过滤所述用户设备的程序崩溃信息;
232.其中,所述多个字段包括基础字段和扩展字段;
233.所述扩展字段包括崩溃类型、堆栈信息、崩溃描述、崩溃页面、崩溃时的设备运行状态信息。
234.作为可选的实施例,所述标签包括第一标签和第二标签,所述过滤后的程序崩溃信息包括堆栈信息和崩溃描述;
235.所述解析模块1030,还用于:
236.将所述堆栈信息传递至解析层,通过所述解析层解析所述堆栈信息,以得到解析后的堆栈信息;
237.根据解析后的堆栈信息生成第一标签;
238.根据所述崩溃描述生成第二标签;
239.将所述第一标签和所述第二标签写入到所述数据库;
240.其中,所述第一标签和所述第二标签在所述数据库均与所述程序崩溃信息相关联。
241.作为可选的实施例,所述解析模块1030,还用于:
242.删除所述解析后的堆栈信息中的无效信息,得到与程序本身关联的有效堆栈信息;其中,所述无效信息至少包括以下一项或多项:与操作系统关联的信息、数字;及
243.根据与所述程序本身关联的有效堆栈信息,通过哈希算法计算得到所述第一标签。
244.作为可选的实施例,所述用户设备为ios设备;所述解析模块1030,还用于:
245.通过所述堆栈信息中的符号表的标识和偏移量,以及构建ipa的符号表文件,查询目标函数名;
246.其中,所述偏移量为发生崩溃的地址和预设基准地址之差;
247.其中,所述目标函数名对应的函数用于调用出现崩溃的对象。
248.作为可选的实施例,所述用户设备为android设备;所述解析模块1030,还用于:
249.通过所述堆栈信息中的混淆数据和构建apk的mapping文件,查询混淆前数据;
250.其中,所述混淆数据为程序运行时的类名;
251.其中,所述混淆前数据包括目标函数名,该目标函数名对应的函数用于调用出现崩溃的对象。
252.作为可选的实施例,所述装置还包括分析模块,用于:
253.基于第一标签和第二标签,对所述数据库中预设时段的程序崩溃信息进行聚合,得到多个聚合数据;同一个聚合数据中的每条数据具有相同的第一标签和/或相同的第二标签;
254.基于所述多个聚合数据生成分析结果,所述分析结果包括导致程序崩溃的一个或多个问题;及
255.将所述分析报告发送到与所述一个或多个问题关联的一个或多个目标群组中。
256.实施例四
257.图11示意性示出了根据本技术实施例四的适于实现程序崩溃分析聚合方法的计
算机设备的硬件架构示意图。本实施例中,计算机设备10000是一种能够按照事先设定或者存储的指令,自动进行数值计算和/或信息处理的设备,例如,移动设备,平板设备,膝上型计算机,智能设备(如,智能手表,智能眼镜),虚拟现实耳机,游戏设备,机顶盒,数字流设备,机器人,车载终端,智能电视,电子书阅读器,mp4(运动图像专家组音频层iv)播放器等。如图11所示,计算机设备10000至少包括但不限于:可通过系统总线相互通信链接存储器10010、处理器10020、网络接口10030。其中:
258.存储器10010至少包括一种类型的计算机可读存储介质,可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,存储器10010可以是计算机设备10000的内部存储模块,例如该计算机设备10000的硬盘或内存。在另一些实施例中,存储器10010也可以是计算机设备10000的外部存储设备,例如该计算机设备10000上配备的插接式硬盘,智能存储卡(smart media card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡(flash card)等。当然,存储器10010还可以既包括计算机设备10000的内部存储模块也包括其外部存储设备。本实施例中,存储器10010通常用于存储安装于计算机设备10000的操作系统和各类应用软件,例如程序崩溃分析聚合方法的程序代码等。此外,存储器10010还可以用于暂时地存储已经输出或者将要输出的各类数据。
259.处理器10020在一些实施例中可以是中央处理器(central processing unit,简称为cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器10020通常用于控制计算机设备10000的总体操作,例如执行与计算机设备10000进行数据交互或者通信相关的控制和处理等。本实施例中,处理器10020用于运行存储器10010中存储的程序代码或者处理数据。
260.网络接口10030可包括无线网络接口或有线网络接口,该网络接口10030通常用于在计算机设备10000与其他计算机设备之间建立通信链接。例如,网络接口10030用于通过网络将计算机设备10000与外部终端相连,在计算机设备10000与外部终端之间的建立数据传输通道和通信链接等。网络可以是企业内部网(intranet)、互联网(internet)、全球移动通讯系统(global system of mobile communication,简称为gsm)、宽带码分多址(wideband code division multiple access,简称为wcdma)、4g网络、5g网络、蓝牙(bluetooth)、wi-fi等无线或有线网络。
261.需要指出的是,图11仅示出了具有部件10010-10030的计算机设备,但是应理解的是,并不要求实施所有示出的部件,可以替代的实施更多或者更少的部件。
262.在本实施例中,存储于存储器10010中的程序崩溃分析聚合方法还可以被分割为一个或者多个程序模块,并由一个或多个处理器(本实施例为处理器10020)所执行,以完成本技术。
263.实施例五
264.本实施例还提供一种计算机可读存储介质,计算机可读存储介质其上存储有计算机程序,计算机程序被处理器执行时实现实施例二中的程序崩溃分析聚合方法的步骤。
265.本实施例中,计算机可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、
电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,计算机可读存储介质可以是计算机设备的内部存储单元,例如该计算机设备的硬盘或内存。在另一些实施例中,计算机可读存储介质也可以是计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smart media card,简称为smc),安全数字(secure digital,简称为sd)卡,闪存卡(flash card)等。当然,计算机可读存储介质还可以既包括计算机设备的内部存储单元也包括其外部存储设备。本实施例中,计算机可读存储介质通常用于存储安装于计算机设备的操作系统和各类应用软件,例如实施例中的程序崩溃分析聚合方法的程序代码等。此外,计算机可读存储介质还可以用于暂时地存储已经输出或者将要输出的各类数据。
266.显然,本领域的技术人员应该明白,上述的本技术实施例的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本技术实施例不限制于任何特定的硬件和软件结合。
267.以上仅为本技术的优选实施例,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。