一种基于soc的图形图像叠加显示方法及芯片
技术领域
1.本发明属于电子技术领域,尤其涉及一种基于soc的图形图像叠加显示方法及芯片。
背景技术:
2.高清视频与图形控制界面的叠加显示在很多领域有所应用,如直升机的视频监控中,不仅要求能实时显示侦察目标的状况,还需要显示直升机在飞行过程中的速度、位置、高度等信息,并提供人机操作控制,此时就用到视频图形叠加显示技术。此外,在舰船、海军光电、汽车等领域的显控终端也常会用到。
3.在传统的方案中,显示控制系统在现实高清视频时,会采用专用的图形处理硬件如显卡、gpu或者专用于视频显示的芯片满足高清视频显示的需求。而显示与控制软件通常部署在工控机中,在桌面操作系统环境下开发和运行人机交互界面。这种基于工控机及gpu进行人机交互显示、高清视频叠加显示的方式,通常设备体积较大、芯片功耗高。
技术实现要素:
4.有鉴于此,本发明实施例提供了一种基于soc的图形图像叠加显示方法及芯片,用于解决现有图形图像叠加显示设备体积大、芯片功耗高的问题。
5.在本发明实施例的第一方面,提供了一种基于soc的图形图像叠加显示方法,包括:
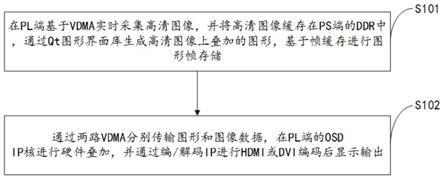
6.在pl端基于vdma实时采集高清图像,并将高清图像缓存在ps端的ddr中,通过qt图形界面库生成高清图像上叠加的图形,基于帧缓存进行图形帧存储;
7.通过两路vdma分别传输图形和图像数据,在pl端的osd ip核进行硬件叠加,并通过编/解码ip进行hdmi或dvi编码后显示输出。
8.在本发明实施例的第二方面,提供了一种芯片,至少包括fpga、arm和axi总线,其中,
9.所述fpga用于基于vdma实时采集高清图像,并将高清图像缓存在ps端的ddr中,并在osd ip核进行硬件叠加,并通过编/解码ip进行hdmi或dvi编码后显示输出;
10.所述arm用于通过qt图形界面库生成高清图像上叠加的图形,基于帧缓存进行图形帧存储;
11.所述axi总线用于fpga与arm之间进行通信。
12.本发明实施例中,通过共享图像采集设备与drm显示设备间的图像帧缓存,并将图像的采集、图像缓存区至硬件显示接口的数据传输、图像编码在soc的pl端完成,不需要cpu过多的参与,大大减轻cpu的负担,提高了高清图像的显示速率,实现高清图像与交互界面的叠加显示,降低了处理芯片的功耗,并减小设备体积,有效提高了视频的显示帧率与人机交互界面的流畅度。
附图说明
13.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单介绍,显而易见地,下面描述的附图仅仅是本发明的一些实施例,对本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获取其他附图。
14.图1为本发明一个实施例提供的一种基于soc的图形图像叠加显示方法的流程示意图;
15.图2为本发明一个实施例提供的一种图形图像叠加显示原理示意图;
16.图3为本发明的一个实施例提供的soc程序设计示意图;
17.图4为本发明的一个实施例提供的芯片设计结构示意图。
具体实施方式
18.为使得本发明的发明目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本发明一部分实施例,而非全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
19.应当理解,本发明的说明书或权利要求书及上述附图中的术语“包括”以及其他相近意思表述,意指覆盖不排他的包含,如包含一系列步骤或单元的过程、方法或系统、设备没有限定于已列出的步骤或单元。此外,“第一”“第二”用于区分不同对象,并非用于描述特定顺序。
20.请参阅图1,本发明实施例提供的一种基于soc的图形图像叠加显示方法的流程示意图,包括:
21.s101、在pl端基于vdma实时采集高清图像,并将高清图像缓存在ps端的ddr中,通过qt图形界面库生成高清图像上叠加的图形,基于帧缓存进行图形帧存储;
22.所述pl端,即progarmmable logic(可编程逻辑器件),可用于实现高清图像采集、编码、图形图像叠加、显示等。
23.vdma(variable destination multiple access,即可变地址多址)是通过axi stream协议对视频数据在ps与pl端进行搬运,无需关注axi stream协议,在blockdesign设计中只需要把相应信号进行连接即可。
24.具体的,基于video in to axi4-stream的ip核将视频图像信息转换为axi总线类型的视频流,并通过axi video direct memory access写入至arm端的缓存地址中。
25.video in to axi4-stream用于将视频源(带有同步信号的时钟并行视频数据,即同步sync或消隐blank信号)转换成axi4-stream接口形式,实现接口转换。axi video direct memory access用于通过axi总线读取某个地址区间的视频数据,并能以数据流的形式传输写入缓存中。
26.其中,所述高清图像上叠加的图形包括基本图形、文字以及人机交互图形界面。在图形界面生成模块中,由arm中qt图形界面库生成对应的人机交互图形界面和图像上叠加的基本图形与文字,并存储在缓存中。
27.进一步的,在所述ps端运行vdma控制驱动vdma driver、内存零拷贝驱动dma-buf、显示设备管理驱动drm以及图形库qt的嵌入式linux操作系统,并通过libdrm应用接口库对多个图层进行管理。
28.其中,图像采集驱动主要通过控制vdma将视频流数据写入缓存中,对vdma的操作在file_operation结构体中实现,通过axicdma_ioctl函数提供对vdma支持的配置。
29.s102、通过两路vdma分别传输图形和图像数据,在pl端的osd ip核进行硬件叠加,并通过编/解码ip进行hdmi或dvi编码后显示输出。
30.由两路vdma组成drm(direct rendering manager)系统的多层planes,分别从对应缓存区中读取图形和图像数据,并在video on screen display(osd)的ip核中进行硬件叠加,并通过hdmi或dvi接口输出显示。
31.在一个实施例中,如图2所示,基于vdma将高清图像缓存在ddr中,在ps(processor system)端的qt图形界面库中生成图形交互界面,并缓存至缓存ddr中。通过两路vdma分别传输图形和图像数据,在osd ip核进行多层硬件叠加,并通过hdmi编码输出至显示界面。
32.其中,在所述ps上运行vdma控制驱动vdma driver、内存零拷贝驱动dma-buf、显示设备管理驱动drm、帧缓冲framebuffer等。
33.可以理解的是,在ddr显示子系统中,drm显示子系统的配置包括:xilinx为drm相关的硬件ip核提供驱动,并集成在了linux内核中。在该soc程序设计的基础上,需要配置drm显示子系统,为linux开发者对多个图层的操作提供支持。drm的配置主要在linux设备树中完成,其中两路vdma对应drm显示系统的planes(图层),xlnx,encoder-slave节点对应encoder(编码器),xlnx,connector-type节点对应connector(连接器)。
34.嵌入式操作系统与运行环境的移植包括:操作系统与运行环境的移植主要包括petalinux,其中包含drm、图像采集驱动的配置编译的linux系统,并在系统中移植qt图形界面库,用以生成人机交互界面和叠加的图形文字等;libdrm库,用于在应用层对drm显示系统进行图层的配置、显示链路的配置、显存管理等。
35.在另一实施例中,soc程序设计如图3所示,通过video into axi4-stream的ip核将视频图像信息转换为axi总线类型的视频流,并通过axi video direct memory access写入至arm端的缓存地址中。在ps上生成叠加图形后,通过axi interconnect多个ip核进行指令和数据传输。通过两路vdma分别传输图形和图像数据,在osd ip核进行硬件叠加,并通过编/解码ip进行显示输出。
36.还需要说明的是,具体程序设计流程包括:打开图像采集设备、打开drm显示设备后,导出显示设备缓存文件描述符,并设置设备间共享内存,配置帧缓存与显示链路,设置各图层全局透明度,设置各图层叠加的前后关系,设置叠加图层的显示属性。设置设备间内存共享,设置图像采集通道,开始图像采集后,运行qt图形界面程序。当程序运行结束,取消图像采集设备的共享内存,停止图像采集并释放连接器。
37.应理解,上述实施例中各步骤的序号大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
38.图4为本发明实施例提供的一种用于图形图像叠加显示的芯片结构示意图,该芯片至少包括fpga 410、arm 420和axi总线430;
39.其中,所述fpga 410用于基于vdma实时采集高清图像,并将高清图像缓存在ps端
的ddr中,并在osd ip核进行硬件叠加,并通过编/解码ip进行hdmi或dvi编码后显示输出。
40.具体的,基于video in to axi4-stream的ip核将视频图像信息转换为axi总线类型的视频流,并通过axi video direct memory access写入至arm端的缓存地址中。
41.所述arm 420用于通过qt图形界面库生成高清图像上叠加的图形,基于帧缓存进行图形帧存储;
42.所述高清图像上叠加的图形包括基本图形、文字以及人机交互图形界面。
43.所述axi总线430用于fpga与arm之间进行通信。
44.其中,在所述arm上运行vdma控制驱动vdma driver、内存零拷贝驱动dma-buf、显示设备管理驱动drm以及图形库qt的嵌入式linux操作系统,并通过libdrm应用接口库对多个图层进行管理。
45.其中,通过axi总线控制fpga软核对高清图像采集、编码及图形图像叠加、显示进行配置。
46.本实施例中,通过dma-buf机制共享图像采集设备与drm显示设备之间的图像帧缓存,且图像的采集、图像缓存区至硬件显示接口的数据传输、图像编码都通过soc的pl端完成,不需要cpu过多的参与,大大减少了cpu的负担,提高了高清图像的显示速率。实测表明,在显示同一分辨率的图像下,通过该叠加方案显示时与通过cpu直接叠加显示时cpu占用率从89%降至13%,帧率从11fps提升至30fps左右,满足常用的显示需求。
47.本实施例提供的芯片可以是适用于zynq系列、国产复旦微系列等arm fpga异构芯片。
48.所述领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置和模块的具体工作过程可以参考前述方法实施例中对应的过程,在此不再赘述。
49.在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
50.以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。