1.本发明属于自然语言处理与信息抽取领域,提出一种基于全局指针网络的实体关系联合抽取模型。该模型可用于中文医疗等文本的实体关系抽取任务,能够为知识图谱的构建及其下游领域提供技术支持。
背景技术:
2.随着大数据时代的来临,海量的非结构化数据存储于互联网中,如何利用信息抽取技术挖掘出有价值的信息成为自然语言处理领域中的研究重点。实体关系抽取作为信息抽取的关键子任务,广泛应用于知识图谱的构建及其下游领域中,如信息检索、推荐系统、智能问答等。该任务旨在从非结构化文本中抽取出具有特定语义关系的实体对,表示形式为关系三元组(头实体、关系、尾实体)。
3.目前实体关系抽取方法分为两类:流水线方法与联合方法。流水线方法将实体识别和关系抽取两个子任务独立解决,先利用实体模型识别出句子中的所有实体,再通过关系模型对实体对进行分类。流水线方法忽略了子任务之间的内在联系和依赖关系,存在严重的错误传播问题。联合方法将两个子任务整体进行建模和训练,以实现两个子任务的相互促进。如miwa等人提出的基于lstm的联合模型,用bilstm编码句子并通过tree-lstm建模词之间的语法依赖;zheng等人将实体关系抽取转换为序列标注任务,模型先联合解码出每一个token的实体-关系标签,再根据就近原则匹配得到关系三元组。相较于流水线方法,上述联合方法增强了实体与关系的交互并缓解了错误传播问题,但在建模思路上将关系视作实体对上的离散标签,所以训练过程中模型难以学习到正确的分类特征,因此无法有效抽取出重叠三元组。
4.近年来,有学者提出了基于标注策略的方法解决重叠三元组问题。如yu等人提出的etl-span将实体关系抽取任务分解为头实体提取、尾实体关系提取两个子任务,并设计了融合跨度距离的多序列标注方法实现三元组的抽取;wei等人设计了级联二进制指针标注框架casrel,该模型能学习给定关系下头实体到尾实体之间的映射函数,从而实现三元组整体建模。基于标注策略的方法通过实体边界和关系类别的联合解码,减少了冗余实体的噪声干扰,但该类方法使用常规的指针网络对实体首尾位置分别进行训练,没有考虑到预测阶段评估时所需的实体整体性,即要求首尾位置同时预测正确,导致了模型训练与预测目标不一致性问题。
技术实现要素:
5.针对此问题,本文提出了一种基于全局指针网络的联合抽取方法,全局指针网络将首尾位置视为一个整体,并对首尾位置对应的子序列进行尾实体判别,这意味着模型以实体序列为基本单位进行训练与评估,保证了训练与预测目标的一致性。此外,为了进一步提升三元组抽取效果,本文引入了条件层归一化方法融合头实体信息,相较于传统求和与拼接的特征融合方法,该方法能够更好地指导模型捕捉三元组方向特征;还增添了关系分
类辅助任务,根据句向量抽取出句子中的潜在语义关系,模型可根据此结果过滤掉部分预测错误的三元组。
6.该方法包括以下步骤:
7.步骤1:对输入句子进行特征提取。使用nezha预训练语言模型对输入语句进行全局特征提取,挖掘深层次语义特征,得到上下文信息丰富的编码向量。
8.步骤2:识别出句子中所有的头实体。将步骤2得到的编码向量使用指针网络分别标注出句子中每个字是否为实体的首尾位置,并采用最近匹配原则,即每个首位置标记向后匹配最近尾位置标记,将首位置标记到尾位置标记所对应子序列识别为头实体。
9.步骤3:引入条件层归一化方法融合编码向量与头实体特征。将层归一化结构中对应的偏置和权重设置为头实体特征的函数,将得到的融合向量作为关系与尾实体抽取的输入。
10.步骤4:抽取每个头实体在特定关系下的尾实体。设计了全局指针网络,根据步骤4输出的融合向量在每一种预定义关系下,将句子划分为若干个连续子序列并对子序列打分,根据分数判别出哪些子序列为正确的尾实体。
11.步骤5:经过上述步骤,模型可能抽取出包含错误语义关系的三元组,为了缓解这一问题,本发明将编码向量中具有全局语义信息的[cls]向量作为句向量,对其关系分类以识别出句子中潜在语义关系并以此过滤掉抽取结果中部分不合理三元组。
[0012]
与现有技术相比,本发明具有如下有益效果:
[0013]
1.本发明设计了全局指针网络,作为解码器对输入语句进行关系和尾实体的抽取。全局指针网络将实体首尾位置视为一个整体进行判别。这意味着模型以实体序列为基本单位进行训练与评估,从而使得模型更具有全局观,实现了训练与预测目标的一致性,增强了实体关系抽取模型的性能。
[0014]
2.本发明引入了条件层归一化方法,融合头实体特征与编码向量。该方法不仅能有效缓解梯度消失和梯度爆炸问题,还能充分地捕捉到输入语句中的三元组方向信息,增强实体关系特征的表示能力。
[0015]
3.本发明增添了关系分类辅助任务,判别出输入句子中潜在的语义关系。该任务不仅能够指导模型更好地学习句向量特征,模型还能根据分类结果过滤掉部分抽取错误的三元组,提高模型抽取三元组的精确率。
附图说明
[0016]
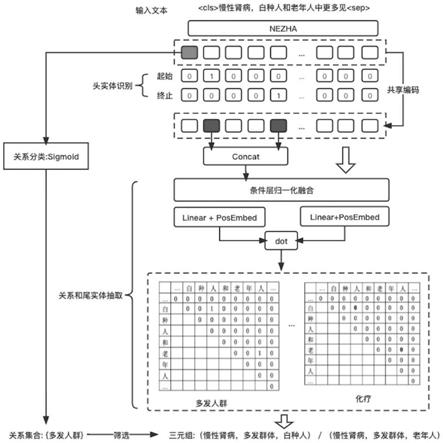
图1为基于全局指针网络的实体关系抽取模型整体架构示意图。
具体实施方式
[0017]
下面结合附图和具体实施方式对本发明做进一步描述。
[0018]
本发明的目标是抽取出句子中所有可能存在的三元组。为了更有效地抽取出重叠三元组,避免冗余实体的噪声干扰,本发明基于标注策略的方法对实体关系抽取任务进行建模和求解,如式(1)所示:
[0019]
[0020]
其中,h、r、t分别表示三元组的头实体、关系、尾实体,x表示输入的句子,ω表示数据集的所有关系构成的集合。
[0021]
基于此方法,本发明将实体关系抽取任务分解为三个子任务:1)识别出句子中所有头实体2)对于每一个头实体,在特定关系下抽取出尾实体3)根据句子语义过滤部分不合理三元组。
[0022]
为了实现上述任务,本发明提出的基于全局指针网络的联合抽取方法整体架构如图1所示,共分为三个模块:1)编码与头实体识别模块,使用nezha对输入句子进行特征提取,得到编码向量并通过指针网络标注出句子中所有的头实体;2)关系和尾实体抽取模块,引入条件层归一化融合头实体特征与编码向量,设计了全局指针网络抽取出在特定关系下的尾实体序列;3)关系分类模块,抽取句子的潜在语义关系并根据抽取结果剔除掉部分预测错误的三元组。
[0023]
一、编码与头实体识别模块
[0024]
步骤1:为了充分捕捉句子的深层次语义特征,本模块采用nezha预训练语言模型对输入语句进行特征提取,并得到相应的编码向量。
[0025]
nezha基于bert预训练语言模型开发,额外使用了函数式相对位置编码、全词掩码、混合精度训练等优化方案,能够增强模型对输入语句上下文信息的表示能力
[0026]
h=nezha(x)
ꢀꢀ
(2)
[0027]
其中,x=(χ1,χ2,
…
,χn)表示输入的句子,n为输入句子的长度,h=[h1,h2,
…
,hn]表示句子各个位置的编码向量。
[0028]
步骤2:直接对编码向量h进行解码以识别出输入语句中所有可能的头实体,本发明训练了两个二元指针标注器,通过为每个字分配二元标签(0/1)分别标注出头实体的首尾位置,其中1表示当前字是某个头实体的首(尾)位置,0表示当前字不是一个头实体的首(尾)位置。标注过程如下所示:
[0029][0030][0031]
其中,w
(
·
)
表示训练参数矩阵,b
(
·
)
表示偏置向量,σ表示sigmoid激活函数。和分别表示句子中第i位置的字为头实体首和尾的概率。
[0032]
模型将根据概率与阈值的大小关系决定每个字的二元标签。对于句子中包含多个头实体的情况,本模块采用最近匹配原则,即每个首位置标记向后匹配最近尾位置标记,将首位置标记到尾位置标记所对应子序列识别为头实体。
[0033]
本步骤采用最小化二分类交叉熵损失函数训练模型参数,如下所示:
[0034][0035]
其中,l表示序列长度,表示第i个字符在起始或结束位置的真实标签。
[0036]
二、关系和尾实体抽取模块
[0037]
步骤3:与步骤2识别头实体不同,除了输入句子的编码向量外,在抽取关系和尾实
体时需要额外考虑头实体特征。目前在联合模型中通常采用简单的相加或拼接方法进行特征之间的融合,这种方式限制了融合特征的表达。
[0038]
以图1中的正确三元组(慢性肾病,多发人群,老年人)与颠倒头尾实体后得到的错误三元组(老年人,多发人群,慢性肾病)为例,如果对这两组三元组使用上述融合方法,将会得到相同的融合向量,针对这一不合理现象,需要在特征融合时额外考虑三元组的方向信息。对此,本发明参考条件批归一化(conditional batch normalization)的思想,引入了条件层归一化方法cln(conditional layernormalization),将层归一化结构中对应的偏置和权重设置为关于待融合条件的函数。cln的具体计算如下所示:
[0039][0040]
其中,表示cln方法输入的特征信息,μ表示特征信息的均值,σ2表示特征信息的方差,∈是一个趋于0的正数,γ和θ是无条件的训练参数,c
γ
和c
β
分别表示输入的两个待融合的条件信息,w1和w2为待融合条件信息的训练矩阵。
[0041]
从上式可以看出,cln结构不仅通过w1和w2训练矩阵对齐了c
γ
、c
β
、γ、β的维度,还将c
γ
和c
β
映射到不同的向量空间中学习待融合条件的方向信息。
[0042]
如图1所示,本发明使用cln方法对头实体特征和步骤1输出的编码向量进行特征融合,并将cln方法中的c
γ
和c
β
都设置为头实体编码。特征融合过程如下所示:
[0043]
h'=cln(h,h
head
,h
head
)
ꢀꢀ
(7)
[0044]hhead
=concat(h
start
,h
end
)
ꢀꢀ
(8)
[0045]
其中,h'表示用于关系和尾实体抽取的融合编码向量,h
head
表示为头实体编码,由步骤1和步骤2抽取出的实体起始与结束位置对应的编码向量h
start
和h
end
拼接得到。
[0046]
步骤4:在每一个预定义关系下根据融合特征抽取出句子中可能存在的尾实体。对此,本发明设计了全局指针网络将实体首尾位置视作整体进行判别,而不是将实体首尾位置分开标注,从而使得模型更具有全局观,并实现了模型训练与预测目标的一致性。
[0047]
如图1所示,全局指针网络将长度为n的输入句子视为n(n 1)/2个长度不同的连续子序列,表示形式为(i,j),其中i表示起始位置,j表示结束位置。本模块的目标是对每一个子序列打分,根据分数判别出正确的尾实体。假设数据集中共有m种关系类别,模型将分别在m个关系子空间下对子序列进行判别,这意味着本文将关系和尾实体抽取任务转换为m个“n(n 1)/2选k”的多标签分类任务,k表示尾实体的数量。
[0048]
首先,全局指针网络使用了两个线性层对融合编码向量h'做线性变换,得到向量序列和其次,为了增强指针网络对尾实体长度和跨度的敏感性,引入了相对位置编码rope,将满足的变换矩阵r应用到qa和ka向量中;最后,用和的内积s
α
(i,j),表示从i到j的子序列作为完整尾实体的分数,所有分数大于阈值的子序列都被视为当前头实体在第α种关系下的尾实体。全局指针网络标注流程如下所示:
[0049][0050]
[0051][0052]
其中,表示训练参数矩阵,表示偏置向量。对于抽取出的每一个头实体,重复进行上述关系和尾实体抽取的操作,以抽取出句子中所有可能的三元组。
[0053]
对于多标签分类任务,常规思路是将其转换为n(n 1)/2个二分类任务,这将导致严重的类别不平衡问题,对此,本模块引入了circle loss,使得每一个实体子序列的得分都不小于非实体子序列的得分,最终输出分数最高的k个子序列。针对当前任务尾实体数目不固定的场景,本文在其基础上添加了一个s0阈值来确定模块最终输出的尾实体数目,使得实体子序列的分数都大于s0,非实体子序列都小于s0,最终输出所有大于阈值s0的子序列。本步骤通过最小化此损失函数训练模型参数,具体如下所示:
[0054][0055]
其中,p
α
表示当前头实体在第α种关系下的所有非尾实体子序列,q
α
表示当前头实体在第a种关系下的所有尾实体子序列。
[0056]
三、关系分类模块
[0057]
步骤5:在步骤1至4后,模型可能抽取出包含错误语义关系的三元组。为了缓解这一问题,本文增添了关系分类辅助任务,将编码向量中具有全局语义信息的[cls]向量作为句向量输入本模块中,识别出句子中潜在语义关系并以此过滤掉模型抽取结果中部分不合理三元组,具体如下所示:
[0058][0059]
其中,表示当前句子存在第k种关系的概率,wk表示待训练参数矩阵,bk表示偏置向量,σ表示sigmoid激活函数。
[0060]
在模型的预测阶段,如果某种关系k的概率小于给定阈值,那么视为该句子不存在该种语义关系k,过滤掉模型抽取结果中所有关系为k的三元组。
[0061]
在本步骤中,模型采用二分类交叉熵损失函数训练模型参数,如下所示:
[0062][0063]
其中,表示当前句子第k种关系的真实标签,m表示预定义关系的数量。
[0064]
步骤6:本发明的联合损失函数由步骤2、4、5中的损失相加得到,并通过最小化联合损失学习整体模型的参数,如下所示:
[0065]
loss=loss
subject
loss
object
loss
rel
ꢀꢀ
(14)
[0066]
本发明使用了adam算法训练模型,并采用了指数滑动平均(exponential moving average,ema)来保证训练过程的稳定性。
[0067]
实验数据集介绍
[0068]
本发明使用的是公开数据集cmeie,数据集来源于chip2020学术评测比赛,由“郑州大学”、“北京大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供。数据来源于儿科和百余种常见疾病(其中儿科训练语料来源于518种儿科疾病,常见疾病训练语料来源于
109种常见疾病),共标注了2.8万疾病语句,近7.5万三元组数据和53种关系类型。数据集分为训练集数据14339条,验证集数据3585条,测试集数据4482条,共包含53种schema约束。
[0069]
zeng等人根据三元组的重叠程度将数据集中的句子分为normal、entitypairoverlap(epo)和singleentityoverlap(seo)三类。normal类型表示句子中的任意三元组的头实体或者尾实体与其它三元组的头尾实体没有重叠。epo类型表示句子中的三元组具有重叠的实体对,即两个实体同时存在多种关系。seo类型表示不存在重叠的实体对,但是存在重叠的实体。cmeie数据集样例如表1所示:
[0070]
表1 cmeie数据集样例
[0071][0072]
实验参数介绍
[0073]
本发明实验使用gtx 2080ti显卡运行代码,显存为11g,在linux centos平台上进行实验,使用python3.6/keras 2.2.4/tensorflow 1.1.14,实验参数设置如表2所示:
[0074]
表2模型的超参数
[0075][0076][0077]
实验评价指标
[0078]
本发明抽取的三元组只有当头尾实体边界同时正确以及相应的关系类别正确时
才算抽取正确。任务评价指标有以下三个:精确率(precision)、召回率(recall)、f1值(f1-score)。具体如下所示:
[0079][0080][0081][0082]
其中,tp代表抽取的实体关系三元组正确个数,tp fp则为抽取出的三元组总个数,tp fn表示三元组标签的总个数。
[0083]
实验结果分析
[0084]
为了验证本发明提出的方法对提升三元组抽取效果的有效性,将本发明与其他的联合抽取模型在cmeie中文医疗数据集上进行了对比,如表3所示:
[0085]
1.infoextractor2.0是2020百度信息抽取竞赛的基线模型。设计了一种结构化标记策略来微调预训练语言模型,通过该策略可以在一次过程中提取多个重叠的spo。
[0086]
2.位置辅助分步标记模型首先通过标记头尾位置确定出主实体,接着在逐一预设的关系属性下标记出相应的客实体。为提升抽取效果,在标记过程中引入三重位置辅助信息,并结合自注意力机制来增强特征表示。
[0087]
3.multihead selection用bert预训练语言模型替代lstm编码层,并针对nested ner问题,序列标注crf替换为指针标注。该模型将关系分类器视作实体对的一个线性分类器,每一个实体对只选取当前实体片段的最后一个字符进行关系预测。
[0088]
4.biaffine attention使用bert作为共享编码层,将编码向量与实体标签嵌入结合,利用biaffine分类器来预测token之间的关系。
[0089]
5.casrel使用bert作为共享编码层,一种级联二进制标记框架使用指针网络抽取关系和实体,首先抽取头实体,然后根据头实体去抽取尾实体并且判断关系。
[0090]
表3与现有的抽取模型对比实验
[0091][0092]
从表3中可以看出,本发明在cmeie数据集上的表现相比其他联合抽取模型有了明显的提升,从结果分析可得:
[0093]
(1)infoextractor 2.0采用多序列对实体和关系进行联合标注,能有效地识别出三元组中出现的实体对重叠问题,但会存在头尾实体冗余匹配的情况,导致了抽取精确率
偏低。
[0094]
(2)对比multihead selection与biaffine attention结果可以发现,比起简单地将头尾实体序列线性变化,使用双仿射注意力矩阵能更好地捕捉到头实体序列到尾实体序列的映射关系,提高了模型的召回率。
[0095]
(3)对比biaffine attention与casrel结果可以发现,将关系视为头实体映射到尾实体的函数而不是实体对之间的离散标签,能够更好地指导模型训练,提升模型三元组的抽取性能。
[0096]
一般来说,句子中的三元组数量越多,句子结构就越复杂。为了探究模型在复杂程度不同的句子中的抽取性能,本发明在验证集上对不同三元组数量的句子进行了实验。实验结果如表4所示。从实验结果中我们可以发现本发明在五种复杂程度的句子上的抽取性能均优于基线模型casrel,这一证据表明本发明能更有效对包含多个三元组的句子建模并抽取三元组。
[0097]
为了进一步探究重叠类型不同的模型抽取性能,本发明将cmeie的验证集划分normal,epo,seo三种类型,比较了本发明和基线模型casrel在三种句式上的抽取性能。实验结果如表5所示。实验结果表明,本发明模型在三种重叠类型的句子上的抽取性能均优于基线模型casrel,这一证据表明,本发明能够更有效解决重叠三元组问题。
[0098]
表4包含不同数量三元组的句子的实验结果
[0099][0100]
表5在不同重叠类型的句子上的实验结果
[0101][0102]
为了探究模型组件对模型整体性能的影响程度,在控制模型其它结构和整体参数相同的情况下,通过增删或者替换模型组件,来评估每个组件对模型在cmeie数据集中实验结果的贡献,共设置了5组对比实验,分别为:
[0103]
ours:表示保留模型的全部组件
[0104]-nezha:nezha替换为bert预训练语言模型
[0105]-全局指针网络:将全局指针网络替换为多层二元指针网络
[0106]-cln(add):使用传统的相加方法融合头实体向量与编码向量
[0107]-关系分类:去除关系分类辅助任务
[0108]
实验结果见表6:
[0109]
表6模型消融实验结果
[0110][0111]
实验结果的分析如下:
[0112]
·
将nezha替换为bert预训练语言模型,模型的召回率显著明显下降,表明nezha预训练语言模型能捕捉到更丰富的上下文信息。
[0113]
·
将全局指针网络解码器替换为多层指针网络解码器,模型整体性能下降,说明全局指针解码器能够使得模型更好地捕捉到尾实体的整体性信息以及关系与实体之间的映射关系。
[0114]
·
将条件层归一化替换为向量相加的方法,模型整体性能下降,说明条件层归一化方法能够学习到三元组的方向性信息,指导模型更有效地融合头实体特征。
[0115]
·
去掉关系分类模块,模型整体性能有所下降,说明关系辅助任务不仅能够增强模型对句级别特征的学习,还能有效剔除掉错误的三元组。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
