1.本发明涉及数据分析及数据挖掘应用领域,更具体地说涉及一种掌银易流失客户促活成功概率预测方法、装置及存储介质。
背景技术:
2.现有技术存在类型类似利用专家经验的方法及应用,用于通过该系统实现基于对现有的客户的过往数据进行分析,从中预测出即将或可能流失的客户,如具体到银行系统中的借记卡客户清单或筛选出各类业务的目标客户。这样银行可针对该预测清单进行有针对性的处理,或根据该预测清单对后续的目标客户数量等具有较准确的预测。这样银行可有针对性的进行人力等资源的提前安排。但是传统的专家系统主要是通过收集的专家经验进行分析预测,其整体预测的准确率较低,且需要耗费大量的人力资源来完成,因此成本高,且其给银行带来的帮助不大,无法为银行提前进行有效的客户关系管理提供有效的支持。容易出现遗漏目标客户或筛选出的目标客户存在大量的误差,保护大量的非真时目标客户,导致人力财力的浪费。
3.目前银行业中使用较多的是通过专家经验对高潜力客户进行预测,预测结果的精确率较低,需要耗费大量的人力来完成,且成功率极低。目前银行业在精准营销及客户维护领域最常用的数据挖掘模型是xgboost模型,考虑算法的运行效率和预测能力,xgboost算法在各个评价标准中普遍优于传统算法。由于掌银客群数量庞大,实际参与活动的客群占比很小,这容易导致模型训练过程中出现过拟合现象。为了解决这个问题,本文将传统专家经验的规则模型与xgboost算法模型相结合,先基于专家经验规则模型筛选全量潜在客户,再使用xgboost模型进一步筛选高潜力精准客群,提高营销转化率。基于此方法的掌银易流失促活精准营销模型的营销成功率提升约7.78倍,有效提升营销效果,缩减营销成本。
技术实现要素:
4.本发明所要解决的技术问题是如何提供提高目标客户预测准确率,满足银行的精细化管理。
5.为了解决以上问题本发明提供了一种掌银易流失客户促活成功概率预测的方法,其特征在于:通过基于专家经验规则模型从当前全量客户集中筛选全量潜在待评估客户集,再进一步将待评估客户集中的各个客户的特征数据输入xgboot模型进行促活成功概率预测计算,并输出各个客户的促活成功概率的预测结果,选择预测促活成功概率的用户开展促活活动;所述xgboot模型预先通过如下步骤进行训练:
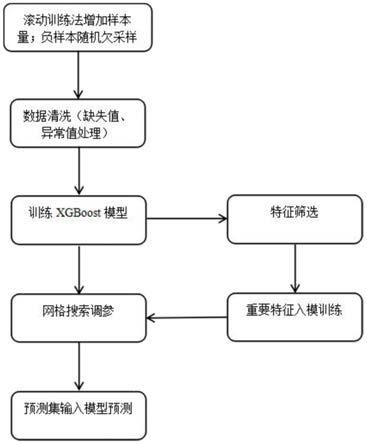
6.根据专家经验建立的规则模型从历史数据中选取第t月为测试区间和第t月的前t个月为训练区间,其中第t月对训练区间中的客户开展了促活活动,第t月被促活的客户为正样本,设flag=1;第t月仍然未被促活的客户为负样本,设标识flag=0;从训练区间中对负样本采取随机欠采样手法提取正样本10倍的训练数据量对xgboot模型进行模型训练;根
据训练输出的各个特征的重要性得分进行特征筛选,获得重要特征重新入模训练,采用网格搜索调参的方法优化xgboot模型参数。
7.所述的掌银易流失客户促活成功概率预测的方法,其特征在于采用滚动训练法增加样本量,对xgboot模型进行滚动训练;具体为在历史数据中,将选取的训练区间的时间逐步逼近到要预测的时间点。
8.所述的掌银易流失客户促活成功概率的预测方法,其特征在于在进行xgboot模型训练过程中,持续监控xgboot模型在训练集上的表现,当监控到表现开始下降时,停止训练。
9.所述的掌银易流失客户促活成功概率的预测方法,其特征在于全量客户预先进行数据清洗处理,将异常值从数据集中剔除,将全列为空或者方差为零的特征剔除,将年龄大于90和小于10岁的客户剔除;同时去除对于模型训练没有意义的特征。
10.一种实现掌银易流失客户促活成功概率预测方法的装置,其特征在于采用了所述的实现掌银易流失客户促活成功概率预测方法。
11.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行所述的实现掌银易流失客户促活成功概率预测方法。
12.实施本发明具有如下有益效果:将传统专家经验的规则模型与xgboost算法模型相结合,先基于专家经验规则模型筛选全量潜在客户,再使用xgboost模型进一步筛选高潜力精准客群,提高营销转化率。基于此方法的掌银易流失促活精准营销模型的营销成功率提升约7.78倍,有效提升营销效果,缩减营销成本。
附图说明
13.图1是实现掌银易流失客户促活成功概率预测的流程图。
具体实施方式
14.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
15.一:选择xgboost模型来实现预测,xgboost最大的特点,它能够自动利用cpu的多线程进行并行,同时在算法上加以改进,提高了精度。它引入了复合树和增量学习的概念,由多个决策树组合形成一个最终分类器,并对损失函数做了二阶泰勒展开,并在目标函数中加入了正则项,整体求最优解,用以权衡目标函数和模型的复杂程度,防止过拟合。在生成基决策树的时候,每棵树沿着前一棵树误差减小的梯度方向进行训练。
16.xgboost是一种专注于梯度提升的机器学习算法,一般用于解决监督学习问题,利用大量的训练数据来预测目标变量。xgboost选择决策树作为它的弱学习器,在每次训练单个弱学习器时,都将上一次分错的类的数据权重提高一点再进行当前单个弱学习器的学习,然后通过加入新的弱学习器,来纠正前面所有弱学习器的残差,最终把多个学习器加权求和,用来进行最终预测。
17.xgboost基本模型是决策树,首先定义单颗决策树的输出为
[0018][0019]
(1)式中:x是输入向量,q表示树的结构,结构函数q(x)表示把输入映射到叶子的索引号,ω表示对应于每个索引号的叶子的分数,t是树中叶节点的数量,d为特征维数。xgboost算法可以看成是由k颗决策树的集成,则k颗树的集合的输出为
[0020][0021]
由决策树的模型可知,单颗决策树的复杂度计算公式为
[0022][0023]
类似地,集成树的复杂度可表示为
[0024][0025]
(4)式中:t是叶节点的数目,γ是范围在0和1之间的学习速率。γ乘以t等于生成树修剪,防止过度拟合。λ是一个正规化参数,ω是叶子的质量。ω(fk)是xgboost算法的正则项。此外,xgboost算法的目标函数在第t步的迭代可以表示为
[0026][0027]
(5)式包含两个部分:第一部分代表真实值yi和预测值函数,l为误差函数。第二部分代表单颗决策树的复杂度之和。已知:其中f
t
(xi)为第t轮需要学习的决策树。则目标函数可转化为
[0028][0029]
因此,xgboost算法在实际应用中具有一定优势。
[0030]
二、通过以下指标来确定xgboost模型评估指标。
[0031]
1)准确率表示分类器正确分类的样本数占总样本数的比例,计算公式为(tp tn)/(tp fn fp tn)。
[0032]
2)召回率表示所有真实正例中判别结果为正例的比例,即真正例被识别出来的百分比,计算公式为tp/(tp fn)。
[0033]
3)精确率表示分类器判别为正例的结果中真正例的比例,计算公式为tp/(tp fp)。
[0034]
三、词用滚动训练和欠采样方式训练xgboost模型。
[0035]
首先根据专家经验建立的规则模型从历史数据中选取第t月为测试区间(表现期)和第t月的前t个月为训练区间(观察期),其中第t月对训练区间中的客户开展了促活活动,第t月被促活的客户为正样本,设flag=1;第t月仍然未被促活的客户为负样本,设标识flag=0;从训练区间中对负样本采取随机欠采样手法提取正样本10倍的训练数据量对xgboot模型进行模型训练;根据训练输出的各个特征的重要性得分进行特征筛选,获得重
要特征重新入模训练,采用网格搜索调参的方法优化xgboot模型参数。采用滚动训练法增加样本量,对xgboot模型进行滚动训练;具体为在历史数据中,将选取的训练区间的时间逐步逼近到要预测的时间点。
[0036]
以下以选取的2020.12~2021.5月期间参与活动的客户数据滚动训练为例进行说明:
[0037]
根据滚动训练的可分别取如下训练区间进行滚动训练:
[0038]
第一次:观察期2020.12.1~2021.2.23,表现期2021.2.24~2021.2.28;
[0039]
第二次:观察期2020.1.1~2021.3.22,表现期2021.3.23~2021.3.31;
[0040]
第三次:观察期2020.2.1~2021.4.25,表现期2021.4.26~2021.4.30;
[0041]
第四次:观察期2020.3.1~2021.5.24,表现期2021.5.25~2021.5.31;
[0042]
根据专家经验建立规则模型,定义全量样本为掌银前三月活跃但本月营销(促活)前未活跃客户。训练集和测试集为2021年2月-5月期间易流失客户,其中正样本为当月营销后参与活动的客户,负样本为当月营销后仍未参与活动的客户。由于本模型中,正样本(flag=1)和负样本(flag=0)分布极度不平衡。与全量掌银易流失客户数量相比,每月参与营销活动的客户数量占比不到1%,因此,模型采用欠采样加滚动训练法进行训练;为了均衡样本比例,提高模型的准确率,建模前先对负样本采取随机欠采样手法提取正样本10倍的数据量。基于掌银易流失客户掌银历史活跃度、掌银行为、账户交易行为、产品持有情况、资产情况、自然属性、历史参与活动情况等,构建客户画像体系,其中特征设计和加工情况(如数量、种类等)为:掌银行为(掌银注册日期距流失日期天数、流失前第n个月掌银登录次数、流失前第n个月交易种类数、流失前第n个月交易金额等)、产品持有情况(持有产品个数、悬空标识、贷记卡标识等)、账户交易行为(月/年有效交易笔数、月/年金融性交易笔数等)、客户属性特征(年龄、性别等)、资产情况(aum、存款等)。通过xgboost算法预测掌银易流失客户的营销成功概率,采用网格调参的方法来优化xgboost模型的参数。由于掌银易流失客群分布的特殊性,很容易出现过拟合的现象:当模型在训练集上表现出色,但在验证集上表现不理想。为获得最好的泛化性能,模型引入了基于xgboost算法的早停法(early stopping),当模型在训练集上的表现开始下降时,停止训练,从而避免模型训练过度。本模型中,设置early_stopping_rounds=150。xgboost模型经过训练以后的特征重要性排序如表1:
[0043]
表1:
[0044]
[0045][0046]
为了验证模型效果,选取了2021年7月掌银易流失客户参与随机立减活动的客户形成验证集,将验证集特征矩阵带入模型,得到较好预测效果。
[0047]
传统的话费立减活动采用全量营销的策略,例如2021年7月27日,全量营销前三月掌银活跃,营销成功率约为0.824%。为节约营销成本,在营销客户选择上,掌银易流失客户促活模型选取2021年8月掌银易流失客户进行预测。8月27日选取预测概率最高的头部1.73万户易流失客户进行批量短信营销话费立减活动,截止8月31日初步验证,模型营销短信短链接的点击率约为8%,与全量客户营销相比,点击率提升约3倍;话费立减活动成功促活1108户,营销成功率为6.41%。与7月份全量易流失客户相比,营销成功率提升约7.78倍,有效提升营销效果,缩减营销成本。
[0048]
本模型通过历史活动数据构建掌银易流失客户的用户画像,预测客户掌银活跃概率,精准促活易流失客户中掌银话费随机立减活动偏好客户,缓解网点营销压力,节约营销成本,提升营销效率。
[0049]
以上所揭露的仅为本发明一种实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解的实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。