一种基于rvnn transformer神经网络模型的代码语义克隆检测方法
技术领域
1.本发明涉及计算机代码克隆领域,特别涉及一种基于rvnn transformer神经网络模型的代码语义克隆检测方法。
背景技术:
2.代码克隆,是指存在于代码库中两个及以上相同或者相似的源代码片段。代码克隆相关问题是软件工程领域研究的重要课题。代码克隆是软件开发中的常见现象,它虽然能够提高开发效率,但是代码克隆也会对系统造成负面影响,包括降低软件稳定性、造成代码库冗余和软件缺陷传播等。
3.代码克隆分为四种类型。类型1是除了空格、注释之外,两个代码片段完全相同的代码对;类型2是除了变量名、类型名、函数名之外都相同的代码对;类型3是有若干语句的增删,或使用了不同的标识符、文字、类型、空格、布局和注释,但是依然相似的代码对;类型4是相同功能的异构代码,在文本或者语法上不相似,但在语义上有相似性。类型1-4的检测难度逐级增加。针对类型4的代码语义克隆检测的工具仍然很少,因此本发明集中于代码语义克隆检测。
4.近年来,出现了许多基于深度学习的代码克隆检测工具。但是它们大部分都是通过lstm或者gru训练代码片段,这些模型经过大部分研究表明适合训练序列输入的情况,但是由于模型的序列输入特性,所以并不能很好地利用gpu并行计算的能力,而且对于过长的序列会出现梯度消失的问题。transformer模型可以一次输入整个序列并结合序列的位置编码,这样就能很好地利用gpu并行计算的能力,且有效减少了梯度消失的问题。transformer模型包含encoder和decoder模块。encoder模块一般是用来生成原始数据的中间向量表示,decoder模块一般是将中间向量转为和原始数据相关的数据,如中英翻译。由于本发明针对的是训练代码的向量表示,所以使用transformer-encoder模块来训练模型。transformer-encoder模块能提高模型的训练速度,融合rvnn和transformer-encoder还能使模型在检测代码语义克隆时有较好的结果。
技术实现要素:
5.本发明旨在提高代码语义克隆检测的准确度和性能,提出了一种基于rvnn transformer神经网络模型的代码语义克隆检测方法。该方法首先将代码转换为抽象语法树表示,然后对抽象语法树按语句级别进行拆分,将拆分后的语句树自底向上输入rvnn模型训练成对应的语句树向量,再将多个语句树向量同时输入带有方向信息的transformer-encoder模块生成新的语句树向量,最后将语句向量通过最大池化层输出代码的向量表示。通过比较两个代码的向量表示的距离来检测是否构成代码语义克隆。
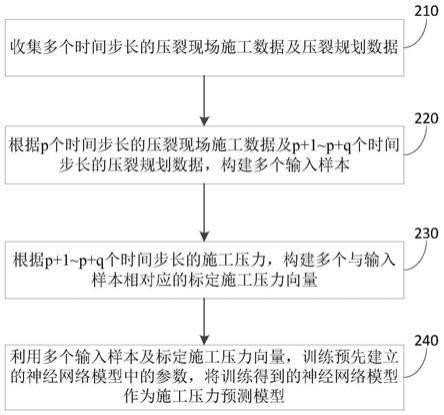
6.本发明的一种基于rvnn transformer神经网络模型的代码语义克隆检测方法,该方法具体包括以下流程:
7.步骤1、代码的预处理。一个代码完整的抽象语法树如果直接输入模型可能会出现梯度消失的问题,所以需要先进行拆分,可以把抽象语法树分割成一组语句树,对于有嵌套结构的语句可以把它的花括号内的代码分割出来,比如if,for,while。然后把每个语句树按顺序存储到本地,语句树是以多级数组的形式存储,第一级的值是第二级的父节点,以此类推。
8.步骤2、代码的预训练。由于深度学习模型必须要传入向量,所以需要先把代码的每个token转化为向量。利用word2vec的skip-gram模型对数据集中代码的所有token进行训练,生成每个token对应的词向量。词向量的维度d为128。
9.步骤3、建立神经网络模型。模型由rvnn语句树编码层,transformer-encoder层和最大池化层组成。以下详细对每个模块进行介绍:
10.为了训练得到语句树上的结构信息,所以需要将语句树自底向上的输入到rvnn模型中。具体转化过程如下:
11.对一个代码的语句树进行深度优先遍历并借助训练好的skip-gram模型将各个节点值转化为d维向量vi。然后对语句树中各节点对应向量公式(1)进行更新,从而使其包含子节点信息。
[0012][0013]
其中,vn表示节点n对应的向量,为权重矩阵,k为编码维度,c为节点n对应的子节点数量,bn为偏差,hi为子节点i更新后的向量,σ为激活函数,本文使用的是恒等函数。
[0014]
为了获得节点向量中最重要的特征,在完成对各节点的向量更新后,使用公式(2)对语句树的所有结点向量hi进行最大池化,以获取语句树的最终向量表示。
[0015]et
=[max(h
i1
),
…
,max(h
ik
)],i=1,
…
,n (2)
[0016]
其中,n为语句树的节点数量。
[0017]
最终一个代码完整的抽象语法树表示为[e1,
…
,ei,
…
,e
t
],i∈[1,t]。其中t表示语句树的数量。
[0018]
由于代码的顺序信息也很重要,所以需要transformer-encoder模型训练代码各个语句树之间的顺序信息。transformer-encoder模型需要使用带有相对位置信息的注意力计算得分公式,公式如下:
[0019][0020][0021][0022]
att(q,k,v)=softmax(a
rel
)v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0023]
其中,h是输入的语句树向量e和位置编码的和,维度为dk,q,v是向量h通过对应的矩阵w映射得到的。k为了增强输入向量h的信息,所以不用矩阵映射。输入向量t是目标
token索引,j是上下文token索引,表示第i个token和第j个token的相似度,u和v是可学习参数,r
t-j
是相对位置编码。将a矩阵经过softmax进行归一化,再乘上v就得到了最终的表示。
[0024]
通过transformer-encoder层变化的语句向量再经过最大池化获取最终的代码表示r。公式如下:
[0025]
r=[max(v1),
…
,max(vi)],i=1,
…
,n
ꢀꢀꢀꢀꢀꢀꢀ
(7)
[0026]
其中,n表示一个语句树对应的节点总数。
[0027]
步骤4、设计siamese架构进行代码语义克隆检测,具体包括:给定的两个代码转换为两个语句树集合作为输入,再把每个语句树自底向上传入到rvnn模型中。然后通过步骤3设计的模型输出最终的向量表示,计算两个代码向量距离来辨别两个代码是否克隆。
[0028]
与现有技术相比,本发明具有以下特点:
[0029]
1、通过transformer-encoder模块能够使模型训练的更快。
[0030]
2、融合rvnn和transformer-encoder能使模型有较高的检测准确度。
附图说明
[0031]
图1是本发明的一种基于rvnn transformer神经网络模型的代码语义克隆检测方法整体流程图;
[0032]
图2是为代码生成语句树多级数组存储表示的示例图;
[0033]
图3是本发明模型的整体架构图。
具体实施方式
[0034]
本发明提出的一种基于rvnn transformer神经网络模型的代码语义克隆检测方法,能将很好地识别出两个代码是否为语义克隆。
[0035]
下面结合具体实施对本发明提出的基于rvnn transformer神经网络模型的代码语义克隆检测方法进行详细描述。如图1所示,为本发明的一种基于rvnn transformer神经网络模型的代码语义克隆检测方法整体流程图。该流程具体包括以下处理:
[0036]
步骤1、代码的预处理。代码通过pyparser工具解析成抽象语法树,然后分割成一组语句树,对于有嵌套结构的语句可以把它的花括号内的代码分割出来,比如if,for,while。然后把每个语句树按顺序存储到本地。
[0037]
如图2所示,一个代码的通过语句级别拆分为多个语句树,每个语句树按层次存储节点值,示例代码生成如下数组:
[0038]
[['funcdef',['decl',['funcdecl',['main',['int']]]]],['compound'],['decl',['n',['int']]],['decl',['a',['int']],['0']],['decl',['b',['int']],['0']],['decl',['c',['int']],['0']],['decl',['t',['int']]],['funccall',['scanf'],['exprlist',['"%d"'],['&',['n']]]],['for',['》',['n'],['0']]],['compound'],['=',['t'],['%',['n'],['10']]],['funccall',['printf'],['exprlist',['"%d"'],['t']]],['/=',['n'],['10']],['end'],['return',['0']],['end']]
[0039]
这个数组是由多个语句树形成的数组组成的。
[0040]
比如第一个数组['funcdef',['decl',['funcdecl',['main',['int']]]]]代表第一个语句树。他的根节点是funcdef(方法定义),他的孩子节点是decl(声明),他的孩子节点是funcdecl(方法声明),他的孩子节点是main(方法名)和int(类型)。
[0041]
步骤2、代码的预训练。本发明使用的数据集是ojclone上,ojclone是一个大型c/c 程序数据集,由104个编程任务组成,每个任务有500个源代码。因为本发明目的是测试代码语义克隆,所以将同一任务的不同源代码视为代码语义克隆。原始数据集太大,所以只从oj中选择前15个编程任务,每个任务有500个源代码。即便如此,它将生成2800多万个克隆对,这非常耗时,因此随机选择了50000个样本。对于数据集,随机拆分三分,包括训练集、验证集、测试集,比例是3:1:1。利用word2vec的skip-gram模型对数据集中代码的所有token进行训练,生成每个token对应的词向量。词向量的维度d为128。
[0042]
有了每个词向量对应的索引,就可以将示例代码转为词对应的索引,如下:
[0043]
[[30,[1,[29,[40,[2]]]]],[6],[1,[13,[2]]],[1,[12,[2]],[5]],[1,[24,[2]],[5]],[1,[33,[2]],[5]],[1,[43,[2]]],[9,[28],[10,[32],[26,[13]]]],[15,[56,[13],[5]]],[6],[4,[43],[80,[13],[107]]],[9,[27],[10,[32],[43]]],[1656,[13],[107]],[7],[35,[5]],[7]]
[0044]
其中,比如30对应的词向量的名称是funcdef。
[0045]
步骤3、建立神经网络模型,并进行训练。如图3所示,这个模型由rvnn语句树编码层,transformer-encoder层和最大池化层组成。以下详细对每个模块进行介绍。
[0046]
为了训练得到语句树上的结构信息,所以需要将语句树自底向上的输入到rvnn模型中。以示例代码的第一个语句树数组[30,[1,[29,[40,[2]]]]]为例,首先会根据word2vec生成的词向量表将每个索引转为向量再输入到模型中,先输入索引2对应的向量生成隐藏状态h1,再输入40对应的向量生成的隐藏状态并加上h1得出h2,这样就能使父节点40包含节点2的信息。
[0047]
为了获得节点向量中最重要的特征,在完成对各节点的向量更新后,使用公式(8)对语句树的所有结点向量hi进行最大池化,以获取语句树的最终向量表示。
[0048]et
=[max(h
i1
),
…
,max(h
ik
)],i=1,
…
,n
ꢀꢀꢀꢀ
(8)
[0049]
其中,n为语句树的节点数量。
[0050]
最终一个代码完整的抽象语法树表示为[e1,
…
,ei,
…
,e
t
],i∈[1,t]。其中t表示语句树的数量。
[0051]
由于代码的顺序信息也很重要,所以需要transformer-encoder模型训练代码各个语句树之间的顺序信息。transformer-encoder模型需要使用带有相对位置信息的注意力计算得分公式,公式如下:
[0052][0053][0054][0055]
att(q,k,v)=sof tmax(a
rel
)v
ꢀꢀꢀꢀꢀꢀ
(12)
[0056]
其中,h是输入的语句树向量e和位置编码的和,维度为dk,q,v是向量h通过对应的矩阵w映射得到的。k为了增强输入向量h的信息,所以不用矩阵映射。输入向量t是目标token索引,j是上下文token索引,a
i,j
表示第i个token和第j个token的相似度,u和v是可学习参数,r
t-j
是相对位置编码。将a矩阵经过softmax进行归一化,再乘上v就得到了最终的表示。
[0057]
通过transformer-encoder层变化的语句向量再经过最大池化获取最终的代码表示r。公式如下:
[0058]
r=[max(v1),
…
,max(vi)],i=1,
…
,n
ꢀꢀꢀꢀ
(13)
[0059]
其中,n表示一个语句树对应的节点总数。
[0060]
训练参数如下:
[0061]
transformer的头部设置为4,dk设置为128,层数为1,前馈神经网络的维度为256,dropout设置0.5。训练的批大小设置为32,epoch设置为10。本发明使用了标签平滑公式:
[0062][0063]
其中ε=0.05。
[0064]
通过r=|r
1-r2|计算两个代码的距离。模型输出的|计算两个代码的距离。模型输出的使用的损失函数是二元交叉熵,公式如下:
[0065][0066]
其中θ表示模型中所有权重矩阵的参数,y为真的标签。
[0067]
最后本发明使用adamax优化器来训练模型。
[0068]
步骤4、模型训练结果
[0069]
由于代码克隆检测可以看作是一个二分类问题,因此选择常用的精度(p)、召回率(r)和f1度量(f1)作为评估指标。本发明与当前较好的astnn模型进行了实验结果比较。实验结果如表1所示:
[0070]
表1在ojclone上的结果
[0071][0072]
与astnn方法相比,该发明的p值较低,但r值和f1值较高,因此该发明在检测代码语义克隆方面具有更好的效果。并且由于transformer-encoder利用了gpu并行计算的能力,训练模型的速度也比astnn要快。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。