1.本发明属于计算机技术领域,涉及一种基于联邦学习的域泛化方法。
背景技术:
2.随着大数据时代的到来,深度学习领域所需大量数据的要求得到了极大的满足。然而,深度学习任务通常需要携带标签的数据,这对于新的领域,尤其是出现冷启动问题的互联网环境非常困难。因此,需要在已有带标签的数据集上训练一个深度学习模型,该模型用于不参与训练的无标签数据集。为了尽可能的增加训练数据,提高模型的泛化能力,收集的数据常常来自多个数据源。源域数据间存在的分布差异,以及源域和未知目标域数据存在的分布差异,导致模型在未知目标域上不能有很好的效果。如何在多源域上训练一个在目标域有很好性能的模型称为域泛化问题。
3.具体来说,在带标签的多个源域的数据上学习一个在未知目标域有很好泛化能力的模型就是域泛化。为了提升域泛化性能,即模型对目标域数据分类的准确率,通常将多源域的数据上传至中心的服务器进行训练。但是,由于数据涉及隐私或用户不愿直接共享等原因,中心化的域泛化训练方法并不实际。联邦学习可以为域泛化问题中源域的数据隐私提供一定的保护。联邦学习是一种去中心化的学习方法,将多个源域的数据分布在不同的客户端,服务器接收来自客户端的模型参数聚合得到全局的模型。这样,无需将源域的数据泄露给其他不可信第三方,保护了源域数据的隐私。因此,基于联邦学习,如何在带标签的分布式多源域数据上学习泛化模型,来应用到无标签的目标域且得到尽可能高的分类准确率,是本发明的主要研究场景。因为联邦学习仅与客户端交换模型的参数,并未考虑源域之间数据分布的差异,以及源域数据可能和未知目标域数据的分布有所不同,直接应用服务器聚合得到的全局模型至目标域,并不能保证有很好的准确率。因此,如何在联邦学习保护源域数据隐私的场景下,提高全局模型在目标域的泛化能力,是本发明的主要研究问题。
技术实现要素:
4.有鉴于此,本发明的目的在于提供一种基于联邦学习的域泛化方法,在联邦学习保护源域数据隐私的场景下,提高全局模型在目标域的泛化能力。
5.为达到上述目的,本发明提供如下技术方案:
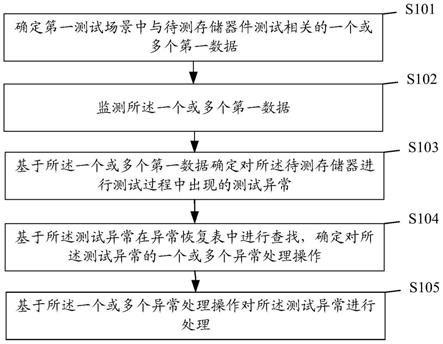
6.一种基于联邦学习的域泛化方法,在联邦学习架构下,基于分布式的多源域的数据跨域学习一个用于未知目标域的泛化模型。该方法具体包括以下步骤:
7.s1:利用对抗学习网络按类别对齐客户端的源域数据的特征分布和参考特征分布,并学习一个在源域特征上能很好分类的分类器;其中,本发明提出使用分布生成器生成参考特征分布,通过对抗学习,生成的参考特征分布按类别靠近源域数据的特征分布,减小了源域特征分布与参考特征分布对齐所需的特征偏移,防止特征失真;
8.s2:利用联邦学习架构将多个客户端的特征提取器、分布生成器和分类器的模型参数在服务器进行平均,使得多个客户端的参考特征分布一致,且靠近所有源域数据特征
分布的中心,特征提取器输出的特征分布一致,且分类器能对该特征分布的特征进行分类;
9.s3:通过多轮的服务器与客户端数据交互,多个源域的特征分布按类别对齐,特征提取器在多个源域数据上输出的特征分布靠近生成的参考特征分布,此时,特征提取器学习了域不变的特征,并且分类器在相同分布的特征上有相似的性能,因此,该特征提取器及分类器可很好地泛化至目标域。
10.进一步,步骤s1具体包括以下步骤:
11.s11:基于本地带标签的源域数据,客户端训练特征提取器和分类器,使得特征提取器提取出用于分类任务的关键数据特征,分类器能对该特征准确地分类;此次分类训练的分类损失函数为为标准交叉熵函数,此外,为了防止过拟合,使用标签平滑正则项来微调该损失函数;
12.s12:给定特征提取器提取的源域数据特征和分布生成器输出的生成特征,两类特征携带真实数据的标签,经过随机映射后输入判别器,判别器将输出该特征作为正样本的概率;
13.s13:特征提取器的参数更新:使用超参数λ0和λ1来平衡对抗损失和分类损失对特征提取器参数的影响;
14.s14:分布生成器的损失函数由判别器判断生成特征h
′
是否为正样本的概率得到;在对抗训练分布生成器的过程中,给定固定参数的判别器,用于更新分布生成器的参数;
15.s15:基于步骤s12,判别器尽可能地区分被看作负样本的源域数据特征和被看作正样本的生成特征;然而,在步骤s13和步骤s14,固定判别器参数,训练特征提取器使得判别器误判源域特征为正样本,训练分布生成器使得判别器正确判断生成特征为正样本,重复多轮步骤s12~s14的对抗训练,使得判别器将这两类特征都判别为正样本,此时,源域特征分布和生成的参考特征分布按类别对齐,并且,这种生成的参考特征分布通过对抗训练按类别靠近源域特征分布,减小了在对齐过程中源域特征分布所需的特征偏移。
16.进一步,步骤s12中,在特征提取器、分布生成器和判别器的对抗学习过程中,特征提取器提取的特征h被看作负样本,而分布生成器输出的特征h
′
被看作正样本;判别器将这两类输入特征的损失函数定义为:
[0017][0018]
其中,p(h)表示特征h的分布,p(h
′
)表示特征h
′
的分布,d表示判别器模型,y表示特征h对应数据的真实标签,表示期望。
[0019]
进一步,步骤s13具体包括:更新特征提取器和分类器的损失函数为其中,为分类训练过程中的损失函数,表示对抗学习过程中特征提取器的损失函数,定义为:
[0020][0021]
在对抗训练特征提取器的过程中,特征提取器的负样本h将用于欺骗判别器,使得判别器将h判别为正样本。
[0022]
进一步,步骤s14中,分布生成器的损失函数用于更新分布生成器的参数,
定义为:
[0023][0024]
进一步,步骤s2具体包括以下步骤:
[0025]
s21:服务器接收来自客户端上传的模型的参数,这些模型包括:特征提取器、分布生成器和分类器,并暂存,当接收了所有客户端上传的模型参数后,按不同模型对上传的参数进行平均,参数平均运算公式为:
[0026][0027]
其中,w
t
表示在第t周期的模型参数,k表示客户端数量;
[0028]
s22:在服务器对所接收的所有模型参数平均计算后,服务器将得到的新模型参数分发至所有客户端,等待下一次聚合运算。
[0029]
进一步,步骤s3具体包括以下步骤:
[0030]
s31:在客户端,本地分布生成器的输出分布靠近本地源域数据的特征分布,经步骤s21参数全局平均,此时分布生成器输出的参考特征分布靠近所有源域数据分布的中心;经过多轮客户端与服务器参数交互,直至分类器在本地数据集上的较高的准确率收敛,上传模型参数至服务器;
[0031]
s2:服务器对特征提取器和判别器的参数进行平均,此时,特征提取器学习了域不变的特征,能在目标域数据上提取出靠近生成参考特征分布的特征,并且,全局平均的分类器对该特征能准确地分类。
[0032]
本发明的有益效果在于:
[0033]
(1)本发明以分布在多个客户端的源域数据作为训练集,基于联邦学习架构学习在未知目标域具有很好泛化能力的方法。
[0034]
(2)本发明方法可应用于新创互联网冷启动等问题中,在保护源域数据隐私的条件下,无需目标场景数据即可学习在目标域具有很好泛化能力的模型。
[0035]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0036]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0037]
图1为本发明中基于联邦学习的域泛化方法的流程图;
[0038]
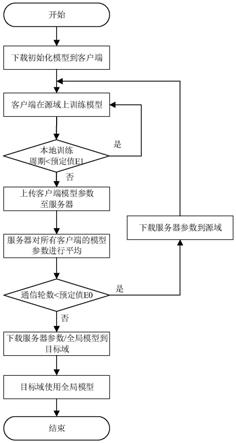
图2为本发明中多源域泛化模型数据交互流程示意图;
[0039]
图3为本发明中客户端本地训练流程示意图。
具体实施方式
[0040]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书
所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0041]
请参阅图1~图3,本发明采用的客户端网络模型包括:
[0042]
第1个本地模型:特征提取器。特征提取器的功能在于,从客户端源域的数据中提取出数据的高维特征向量,并且,该提取的特征向量可用于分类任务。此外,这些提取自同一源域的数据特征组成源域特征分布。
[0043]
第2个本地模型:分布生成器。分布生成器的功能在于,输入随机向量和真实数据的标签,分布生成器输出生成的特征向量。该生成的特征向量组成一个确定的分布,即参考特征分布。
[0044]
第3个本地模型:判别器。判别器的功能在于,给定带有真实数据标签的源域高维特征和生成特征,经过随机映射,判别器可区分这两类不同的特征。在对抗训练过程中,判别器将尽可能地判别这两类不同的特征。
[0045]
第4个本地模型:分类器。分类器的功能在于,给定特征向量,分类器输出其预测的标签信息。
[0046]
本发明在联邦学习架构下,基于分布式的多源域的数据跨域学习一个用于未知目标域的泛化模型,其主要步骤如下:
[0047]
步骤1:联邦学习架构包括分布式的多个客户端和一个服务器。客户端的功能在于存储源域的数据、在源域的数据上训练本地模型,与服务器交互模型参数,服务器的功能在于聚合、分发模型参数,聚合的全局模型可用于未知目标域的数据。其中,客户端中源域的数据均携带标签,而目标域的数据无标签,并且不参与训练过程。
[0048]
步骤2:将客户端训练的模型参数发送至服务器,服务器计算平均值来得到新的模型参数,并分发新的模型参数至所有客户端,多轮迭代训练,直到客户端的模型在本地数据集上的准确率趋于稳定后,将服务器的全局模型用于目标域。其中,本发明提出了联邦对抗学习的训练方法。在每个客户端,通过本地对抗学习将源域数据的特征分布对齐到相同的参考特征分布,来间接地对齐所有源域数据的特征分布。此时,服务器可学习一个不变特征提取器,该特征提取器在目标域上提取出同样靠近参考特征分布的数据特征,来减小了源域数据和目标域数据的差异,因此,全局模型能很好地从多个源域泛化到目标域。此外,为了更好地预测目标域数据的标签,本发明提出在客户端本地基于提取的特征和真实标签来训练分类器,通过与服务器多轮迭代训练,全局的分类器将用于目标域。
[0049]
对于步骤2,本发明提出了一个分布生成器,它的功能在于参与本地对抗训练来使得其输出的参考特征分布靠近源域数据的特征分布。不同于域泛化问题中常见的固定参考特征分布,该生成的参考特征分布在联邦对抗训练中可以靠近所有源域的数据特征分布的中心,减少了源域的特征分布在对齐过程的偏移和提取损失的关键特征信息。此时,客户端的模型包括特征提取器、分布生成器、判别器和分类器,其中特征提取器、分布生成器和判别器参与联邦对抗训练来对齐所有源域的数据特征分布。
[0050]
步骤3:客户端本地对抗训练将源域的特征分布对齐到参考特征分布,上传本地特
征提取器的模型参数至服务器,通过聚合,使得全局特征提取器提取的数据分布靠近相同的参考特征分布。此时,客户端本地模型包括:特征提取器、判别器和分类器,上传至服务器的模型参数分别来自特征提取器和分类器,而判别器的功能在于判别源域的数据特征和参考特征的差异,因此不上传至服务器。本步骤的意义在于,通过本地对抗训练来减小源域的数据分布和参考特征分布的差异,进一步地,间接减小所有源域数据分布的距离,提高全局模型在目标域的泛化性能。
[0051]
对于步骤3,本发明提出了按类别对齐源域的数据分布策略。一般来说,源域通常包含多个类别的数据,不同类别的数据分布不同。为了更好地对齐所有源域的数据分布,本发明在判别器的输入特征中增加了数据对应的真实标签,以便于判别器更好地按类别判别,在分布生成器的输入随机向量中同样加入了真实数据的标签,旨在生成与真实数据相似的同类别特征。
[0052]
本发明还提出了在判别器输入特征前随机映射高维特征的策略。特征提取器或分布生成器得到的高维特征向量经过随机映射,从高维特征空间映射到低维的特征空间后再进入判别器进行判别。通过随机映射,判别器的输出将有助于分布生成器的参数训练,保证本地对抗学习的稳定。
[0053]
本发明提供了一种基于联邦学习的域泛化方法,以分布在多个客户端的源域数据作为训练集,基于联邦学习架构学习在未知目标域具有很好泛化能力的方法。该方法利用生成的参考特征分布作为中介,通过在客户端本地对齐源域特征分布和参考特征分布来在联邦学习架构中对齐所有源域的特征分布,减小所有源域数据间的差异,以此来学习不变的特征,此时,所有源域的特征分布均靠近参考特征分布。学习的不变特征可由在服务器聚合的全局特征提取器输出,即全局特征提取器可从未知目标域数据中提取出靠近参考特征分布的特征,该特征与源域的特征在同一任务上有相似的性能,因此,该学习的不变特征在目标域上有很好的性能。该学习方法利用联邦学习的架构进行分布式训练,最终达到全局的模型能很好泛化至未知目标域的目的。
[0054]
如图1所示,本发明基于联邦学习的域泛化方法,分为两部分,第一部分在客户端数据上训练对齐源域数据的特征分布和参考特征分布,并学习一个在源域特征上能很好分类的分类器,第二部分在服务器聚合客户端上传的模型参数,得到新的平均的模型参数并分发至所有客户端。
[0055]
第一部分,包括以下六个步骤:
[0056]
s11:客户端与服务器的交互数据如图2所示,若客户端首次训练,则接收来自服务器的初始化模型,并在本地初始化判别器模型,反之,客户端接收来自服务器聚合的模型参数,并使用上一周期训练的判别器模型。此外,在训练时,所有的客户端均要求上传本地训练的模型参数,包括特征提取器、分类器和分布生成器。
[0057]
s12:基于本地带标签的源域数据,客户端训练特征提取器和分类器,使得特征提取器能提取出用于分类的重要数据特征,分类器能对提取的特征进行准确地分类预测。训练的损失函数为是标准交叉熵函数,为了防止过拟合,标签平滑正则项微调该分类损失函数。
[0058]
s13:给定特征提取器提取的源域数据特征和分布生成器输出的生成特征,两类特征均携带来自真实数据的标签,经过随机映射后得到的低维特征向量输入判别器,判别器
将输出特征作为正样本的概率。在对抗学习过程中,特征提取器提取的特征h被看作负样本,而分布生成器输出的特征h
′
被看作正样本。判别器对输入的这两类特征的损失函数定义为:
[0059][0060]
其中,p(h)表示特征h的分布,p(h
′
)表示特征h
′
的分布,d表示判别器模型,y表示特征h对应数据的真实标签。
[0061]
s14:特征提取器的参数更新同时受到对抗损失函数和分类损失函数的影响,因此,本发明使用超参数λ0和λ1来平衡对抗损失和分类损失对特征提取器参数的影响,更新特征提取器和分类器的损失函数为其中,表示对抗学习过程中特征提取器的损失函数,定义为:
[0062][0063]
在对抗训练特征提取器的过程中,特征提取器输出的负样本h将用于欺骗判别器,使得判别器尽可能地将特征提取器输出的负样本h判别为正样本。
[0064]
s15:分布生成器的损失函数由判别器判断生成特征h
′
是否为正样本的概率得到。在对抗训练分布生成器的过程中,给定固定参数的判别器,用于更新分布生成器的参数,的定义为:
[0065][0066]
从步骤s13可知,在对抗学习中,训练判别器使其尽可能地区分作为负样本的源域数据的特征和作为正样本的生成特征,而步骤s14和步骤s15,固定判别器参数,训练特征提取器使得判别器误判源域特征为正样本,训练分布生成器使得判别器正确判断生成特征为正样本,重复步骤s13-s15的对抗训练,使得判别器将这两类特征都判别为正样本,此时,特征提取器输出的源域特征分布和分布生成器输出的参考特征分布对齐。
[0067]
s16:上传模型参数。客户端本地训练结束后,上传特征提取器、分布生成器和分类器的参数至服务器,等待下一次与服务器数据交互。
[0068]
第二部分,包括以下两个步骤:
[0069]
s21:服务器首次参与联邦学习,初始化特征提取器、分布生成器和分类器模型,并分发至所有客户端。
[0070]
s22:在联邦学习的域泛化训练过程中,服务器接收来自客户端上传的模型参数,并对上传的参数进行平均,参数平均运算如下:
[0071][0072]
其中,w
t
表示在第t周期的模型参数,k表示客户端数量。在联邦学习中,若服务器与客户端交互的给定周期数未结束,计算得到的新模型参数将分发至所有客户端,反之,使用新模型参数的特性提取器和分类器模型应用于目标域数据。
[0073]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技
术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。