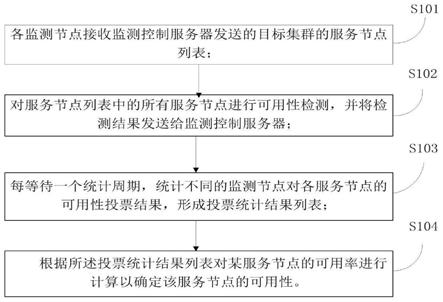
1.本发明涉及信息检索技术领域,尤其涉及一种基于多跳知识推理的信息检索方法及系统。
背景技术:
2.信息检索(information retrieval,ir)是一个根据用户特定的需要在检索库中查找相关信息的过程。随着大数据时代的到来,数据的规模不断的增大,数据的种类也变得更加的多样。如何在海量的数据中进行准确高效的检索是一个重要的问题。传统的信息检索方式,如:布尔逻辑检索,邻近检索,短语检索,截词检索,字段限制检索等,都仅仅是简单的匹配,没有充分发掘大数据背景下数据的之间的关联性。
3.知识图谱(knowledge graph)是通过一种结构化的形式来陈述客观世界中概念、实体(entity)及其之间的关系(relation),将互联网的信息表达成更接近人类认知世界的形式,提供了一种更好地组织、管理和理解信息的方法。知识表示学习是将知识图谱中的各种知识表示成计算机可以存储和计算的一种技术。现在主流的知识表示方法就是将知识图谱中的实体和关系表示为稠密的低维向量。并通过稠密向量在高维空间中的联系进行信息的推理。但是这种基于嵌入式向量进行推理的方式无法给出模型推理的依据。
4.可解释的知识图谱推理方法是近年来被广泛研究的一个方向,其中基于强化学习的多跳知识推理模型更是该研究方向的主流模型。相较于传统的嵌入式模型,这种多跳知识推理模型不但能够提供推理的结果,还能提供一条推理的路径来解释推理的过程。
5.在大数据的背景下,检索库中的信息量也在急速的膨胀,但是现有的信息检索方法并没有利用这些数据建立起知识图谱,因此也无法利用检索库中的信息进行推理和预测。这样就无法充分的利用检索库中的信息,在一些检索条件下,检索结果也会变得不充分、不可靠。
技术实现要素:
6.针对上述现有技术的不足,本发明提供一种基于多跳知识推理的信息检索方法及系统。
7.为解决上述技术问题,本发明所采取的技术方案是:一种基于多跳知识推理的信息检索方法及系统,包括如下步骤:
8.步骤1:建立检索库,并对检索库中的信息进行预处理;
9.所述检索库中的信息包括:数据库信息和多模态信息。其中,多模态信息的预处理方法如下:
10.s1:获取多模态信息中的文本数据;
11.s2:使用已知命名实体识别标注文本中的实体;
12.s3:使用已知关系抽取方法获取实体之间的关系;
13.s4:将非结构化的文本数据转换成(实体,关系,实体)形式的结构化数据。
14.步骤2:针对检索库中的信息,构建知识库文档,过程如下:
15.步骤2.1:针对数据库信息,将每一条(名词,属性,属性值)形式的数据按照(实体,关系,实体)的方式进行重构,得到重构之后的数据,再添加到知识库文档中;
16.步骤2.2:针对多模态信息,将转换后(实体,关系,实体)形式的结构化数据直接按照(实体,关系,实体)的形式将内容添加到知识库文档中;
17.步骤2.3:获得知识库文档相关的实体列表和关系列表,并将知识库文档中出现的数据定义为(h,r,t)形式的三元组,其中h为头实体,r为关系,t为尾实体,具体过程如下:
18.步骤2.3.1:知识库文档中的每一条(实体,关系,实体)形式的数据定义为(e,r,e);
19.步骤2.3.2:将知识库文档中出现过的所有实体整理到一个集合中,并将这个集合定义成e;
20.步骤2.3.3:将各个实体之间的关系整理到一个集合中,并将其定义为r;
21.步骤2.3.4:将出现在第一个位置的实体定义为头实体,记为h,出现在第三个位置的实体定义为尾实体,记为t,其中h,t∈e;r∈r;
22.步骤2.3.5:将知识库文档中出现的数据全部定义为(h,r,t)形式,称为三元组。
23.步骤3:构建多跳知识推理的知识图谱模型,用于发掘检索库中知识之间的关联;
24.进一步的,在构建所述多跳知识推理的知识图谱模型时引入路径选择的先验知识,再将路径选择的先验知识整合到政策网络p中,在政策网络p输出路径选择概率的时候根据先验信息对输出的概率进行调整,随着模型训练次数的提升再逐步减小先验信息的权重。
25.所述路径选择的先验知识的获取方法如下:
26.s1:针对每一种关系r找到多条翻译路径进行翻译,每一条翻译路径pi由一个关系序列构成,表示为pi=[ri1,ri2,
…
,rin],ri1为翻译路径pi中的第一个关系,ri2为翻译路径pi中的第二个关系,rin为翻译路径pi中的第n个关系;
[0027]
s2:对于每一条翻译路径pi,使用路径约束资源分配pcra算法计算出借助路径pi进行翻译的时候路径上资源的流失程度,用以反映翻译的可靠程度;
[0028]
s3:从多条翻译路径中剔除掉可靠程度低于阈值的翻译路径,将剩下的翻译路径作为路径选择的先验知识加入到后续多跳推理模型的训练中。
[0029]
步骤4:将用户查询的内容与检索库中的内容进行匹配,如果成功匹配则搜索检索库中对应的全部匹配信息;
[0030]
所述将用户查询的内容与检索库中的内容进行匹配采用的匹配方法包括:布尔逻辑检索,邻近检索,短语检索,截词检索,字段限制检索等。
[0031]
步骤5:使用步骤3构建的多跳知识推理的知识图谱模型对用户查询的内容进行预测,同时得到预测内容的可信度;
[0032]
步骤6:将预测内容根据可信度值的大小进行排序,剔除可信度低的预测内容;
[0033]
步骤7:将步骤6剔除可信度低的预测内容后留下来的预测内容在检索库中查找相应的匹配信息,并与步骤4得到的匹配信息进行聚合,整理成最终的结果反馈给用户。
[0034]
另一方面,本发明还针对上述基于多跳知识推理的信息检索方法设计了一种基于多跳知识推理的信息检索系统,系统包括:检索库信息处理模块、信息检索模块、知识图谱
学习模块和交互界面;
[0035]
所述检索库信息处理模块对检索库中的数据库信息以及多模态信息中的文本数据进行处理,将检索库中的信息处理成用于表示学习的三元组,将其重构成一个内容丰富的知识库文档,并获得相关的实体列表和关系列表,并将其传送至知识图谱学习模块;
[0036]
所述知识图谱学习模块将检索库信息处理模块传输过来的知识库文件作为输入,通过知识表示学习方法学习知识库文件中三元组中的实体和关系之间的分布式结构化信息;同时对多跳知识推理的知识图谱模型进行训练,以提高推理路径选择的准确度;
[0037]
所述交互界面供用户输入想要检索的信息,并将其传输给信息检索模块;
[0038]
所述信息检索模块为用户提供一种高效、全面、可靠的信息检索方式,即采用基于多跳知识推理的信息检索方法中的步骤4至步骤7的方法实现信息检索,并将检索结果展示给用户。
[0039]
采用上述技术方案所产生的有益效果在于:
[0040]
1、本发明提供的方法利用检索库中的信息构建知识库,可以有效的提高检索库中的海量数据的利用价值,借助知识图谱的信息检索方法相较于传统检索方法,可以充分发掘检索库中隐藏的知识。解决了传统检索方法在特定检索条件的检索过程中出现的检索结果不充分,检索依据不可见、不可靠的问题。
[0041]
2、本发明提供的方法针对现有的知识图谱无法给出推理依据的问题,在推理的过程中引入可解释的因素,即引入多跳知识推理模型:在利用知识图谱进行推理之后,还能获得相应的推理路径来解释知识图谱推理的过程。
[0042]
3、本发明还提供了基于多跳知识推理的信息检索系统,用户可以通过此系统准确高效的检索系统的信息。
附图说明
[0043]
图1为本发明实施例中基于多跳知识推理的信息检索方法的流程图;
[0044]
图2为本发明实施例中多跳推理算法流程图;
[0045]
图3为本发明实施例中基于多跳知识推理的信息检索系统的结构示意图。
具体实施方式
[0046]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0047]
如图1所示,本实施例中基于多跳知识推理的信息检索方法如下所述。
[0048]
步骤1:建立检索库,并对检索库中的信息进行预处理;
[0049]
所述检索库中的信息包括:数据库信息和多模态信息。其中,多模态信息的预处理方法如下:
[0050]
s1:获取多模态信息中的文本数据;
[0051]
s2:使用已知命名实体识别标注文本中的实体;
[0052]
s3:使用已知关系抽取方法获取实体之间的关系;
[0053]
s4:将非结构化的文本数据转换成(实体,关系,实体)形式的结构化数据。
[0054]
步骤2:针对检索库中的信息,构建知识库文档,过程如下:
[0055]
步骤2.1:针对数据库信息,将每一条(名词,属性,属性值)形式的数据按照(实体,关系,实体)的方式进行重构,得到重构之后的数据,再添加到知识库文档中;
[0056]
步骤2.2:针对多模态信息,将转换后(实体,关系,实体)形式的结构化数据直接按照(实体,关系,实体)的形式将内容添加到知识库文档中;
[0057]
步骤2.3:获得知识库文档相关的实体列表和关系列表,并将知识库文档中出现的数据定义为(h,r,t)形式的三元组,其中h为头实体,r为关系,t为尾实体,具体过程如下:
[0058]
步骤2.3.1:知识库文档中的每一条(实体,关系,实体)形式的数据定义为(e,r,e);
[0059]
步骤2.3.2:将知识库文档中出现过的所有实体整理到一个集合中,并将这个集合定义成e;
[0060]
步骤2.3.3:将各个实体之间的关系整理到一个集合中,并将其定义为r;
[0061]
步骤2.3.4:将出现在第一个位置的实体定义为头实体,记为h,出现在第三个位置的实体定义为尾实体,记为t,其中h,t∈e;r∈r;
[0062]
步骤2.3.5:将知识库文档中出现的数据全部定义为(h,r,t)形式,称为三元组。本实施例中,以文本“巴黎是法国的首都”为例,通过命名实体识别的方式,我们可以将文本中的“巴黎”,“法国”等信息标注为实体,在抽取这两个实体之间的关系,实体“巴黎”和“法国”之间存在一个“位于”的关系,就可以在原来的文本数据中提取出机构化信息(巴黎,位于,法国),并整理进结构化文档,使用结构化的方式进行存储,进一步整理成为知识库文档和关系、实体列表。
[0063]
对于数据库信息,则其本身就是结构化的数据,可以直接添加到检索内容数据库中。如针对如下表1国家地理关系的这条数据,将表格中的数据的内容转化为(巴黎,位于,法国)、(巴黎,邻近,维莱科特雷)这样的三元组(h,r,t)形式。
[0064]
表1 国家地理关系
[0065]
地名关系地名巴黎位于法国巴黎邻近维莱科特雷
………
[0066]
步骤3:构建多跳知识推理的知识图谱模型,用于发掘检索库中知识之间的关联;
[0067]
进一步的,在构建所述多跳知识推理的知识图谱模型时引入路径选择的先验知识,增加了模型预测的准确性,同时增加了推理路径的可靠性。再将路径选择的先验知识整合到政策网络p中,如图2所示,在政策网络p输出路径选择概率的时候根据先验信息对输出的概率进行调整,随着模型训练次数的提升再逐步减小先验信息的权重。
[0068]
所述路径选择的先验知识的获取方法如下:
[0069]
s1:针对每一种关系r找到多条翻译路径进行翻译,每一条翻译路径pi由一个关系序列构成,表示为pi=[ri1,ri2,
…
,rin],ri1为翻译路径pi中的第一个关系,ri2为翻译路径pi中的第二个关系,rin为翻译路径pi中的第n个关系;
[0070]
s2:对于每一条翻译路径pi,使用路径约束资源分配pcra算法计算出借助路径pi进行翻译的时候路径上资源的流失程度,用以反映翻译的可靠程度;
[0071]
s3:从多条翻译路径中剔除掉可靠程度低于阈值的翻译路径,将剩下的翻译路径
作为路径选择的先验知识加入到后续多跳推理模型的训练中。
[0072]
本实施例中,在训练多跳推理模型之前,首选要使用知识库文档中的数据预训练一个嵌入式的模型,在本实施例中,采用知识表示学习方法transe作为嵌入式模型。通过预训练的嵌入式模型,可以获得实体列表和关系列表中每一个实体和关系在低维稠密空间中的向量。由于已经经过预训练了,这些实体和关系的向量已经融合了知识库中的大量信息。比如对于“巴黎”的向量e1,“位于”的向量r,“法国”的向量e2,e1 r≈e2。
[0073]
对于多跳推理模型推理的过程,本质是一个序列决策的过程,可以通过一个深度强化学习的框架来实现。想要推理e
1q
的rq关系对应的实体,记为(e
1q
,rq,?),需要定义模型的状态states记作s,动作actions记作a,转移transition记作t,奖励rewards记作r。状态states将会包括模型当前到达的节点e
t
,想要推理的头节点e
1q
以及想要推理的问题rq,记作(e
t
,e
1q
,rq)。动作actions包括当前节点所包含的关系(逆关系)以及关系(逆关系)所连接的另一头的节点,除此之外还会包括一个特殊的关系,即当前节点到当前节点自身的动作,作,转移transition则是政策网络p根据当前的状态s和动作as以及先验的路径选择信息来选择其中的一个动作,并根据选择的动作a转移到下一个状态s,记作s
×a→
s。奖励rewards则是根据最后推理出的状态和目标状态之间的关联给模型一个奖励的分数,记作r(s
t
)=rb(s
t
) (1-rb(s
t
))f(e
1q
,rq,e
t
),r(s
t
)=i{et=e
2q
}。其中i{true}=1,{false}=0。f(e
1q
,rq,e
t
)是根据预训练的嵌入式模型对推理出的状态和目标状态之间关联性的评估。深度强化学习的框架会根据最后的奖励来强化获得奖励的路径。
[0074]
对知识库文档中所有的r进行上述的处理借助pcra算法计算可靠程度较高的路径就可以从中筛选出每个关系可靠的翻译路径。
[0075]
本实施例中,根据先验信息对输出的概率进行调整的具体方法如下:
[0076]
~relation_att=clamp(relation_att pa_att*pa_factor,max=1)
[0077]
其中,relation_att为政策网络p预测的结果,pa_att为先验知识,pa_factor为控制先验信息权重的参数,~relation_att为结合了先验知识的预测结果,clamp限制调整后的预测值不超过1的公式。控制先验信息权重的参数pa_factor随着训练次数的增加而逐步降低。
[0078]
本实施例中,在进行多跳推理模型的训练过程中,对于训练数据(维莱科特雷,位于,法国)。多跳推理模型首先会从实体“维莱科特雷”,记为e
维莱科特雷
,开始寻找推理路径并初始化状态s=(e
维莱科特雷
,e
维莱科特雷
,r
位于
),历史选择记录为h=lstm[0,(r0,e
维莱科特雷
)]。根据当前节点(维莱科特雷)在图谱中找到所有可以执行的动作,记为动作空间节点(维莱科特雷)在图谱中找到所有可以执行的动作,记为动作空间节点(维莱科特雷)在图谱中找到所有可以执行的动作,记为动作空间政策网络p根据当前的状态s,历史选择记录h和动作空间a
维莱科特雷
来计算动作空间中每一个动作被选择的可能性a
维莱科特雷~
=[0.1,0.5,0.3,0.01
…
],其中||a
维莱科特雷
~||1=1然后根据统计的先验知识对a
维莱科特雷
~进行调整得到a
维莱科特雷
=[0.05,0.7,0.2,0.01
…
],其中||a
维莱科特雷
||1=1。然后模型根据调整后的概率进行动作采样,因为动作(维莱科特雷,邻近,巴黎)的概率最大,所以这里假设选择了动作(维莱科特雷,邻近,巴黎)
并跳到了下一个状态巴黎。此时状态更新为(e
巴黎
,e
维莱科特雷
,r
位于
)历史选择记录为更新为h=lstm[h,(r
邻近
,e
巴黎
)]。然后根据知识图谱获得动作空间)]。然后根据知识图谱获得动作空间并利用政策网络和先验知识获得当前状态下动作被选择的概率a
巴黎
=[0.8,0.1,0.0.05,0.01
…
]。最后模型能够跳到实体法国,此时通过奖励函数r(s
t
)=rb(s
t
) (1-rb(s
t
))f(e
1q
,rq,e
t
),r(s
t
)=i{et=e
2q
}。推理路径[维莱科特雷—
邻近
—》巴黎—
位于
—》法国]将会获得奖励1分,模型会因此而强化这条路径被选择的概率。
[0079]
步骤4:将用户查询的内容与检索库中的内容进行匹配,如果成功匹配则搜索检索库中对应的全部匹配信息;
[0080]
所述将用户查询的内容与检索库中的内容进行匹配采用的匹配方法包括:布尔逻辑检索,邻近检索,短语检索,截词检索,字段限制检索等。
[0081]
步骤5:使用步骤3构建的多跳知识推理的知识图谱模型对用户查询的内容进行预测,同时得到预测内容的可信度;
[0082]
在预测的过程中,使用训练好的多跳模型进行波束搜索beamsearch,可以得到相应问题的预测结果,预测路径以及预测可信度的排名。
[0083]
步骤6:将预测内容根据可信度值的大小进行排序,剔除可信度低的预测内容;
[0084]
步骤7:将步骤6剔除可信度低的预测内容后留下来的预测内容在检索库中查找相应的匹配信息,并与步骤4得到的匹配信息进行聚合,整理成最终的结果反馈给用户。
[0085]
另一方面,本实施例中还针对上述基于多跳知识推理的信息检索方法设计了一种基于多跳知识推理的信息检索系统,系统结构如图3所示,包括:检索库信息处理模块、信息检索模块、知识图谱学习模块和交互界面;
[0086]
所述检索库信息处理模块对检索库中的数据库信息以及多模态信息中的文本数据进行处理,将检索库中的信息处理成用于表示学习的三元组,将其重构成一个内容丰富的知识库文档,并获得相关的实体列表和关系列表,使用文件保存这些信息,并将其传送至知识图谱学习模块;
[0087]
所述知识图谱学习模块将检索库信息处理模块传输过来的知识库文件作为输入,通过知识表示学习方法学习知识库文件中三元组中的实体和关系之间的分布式结构化信息;同时对多跳知识推理的知识图谱模型进行训练,以提高推理路径选择的准确度;
[0088]
所述交互界面供用户输入想要检索的信息,并将其传输给信息检索模块;
[0089]
所述信息检索模块为用户提供一种高效、全面、可靠的信息检索方式,即采用基于多跳知识推理的信息检索方法中的步骤4至步骤7的方法实现信息检索,并将检索结果展示给用户。在展示时,根据推理的可靠程度从大到小进行展示,以便于用户提取相关度更高的信息。
[0090]
本实施例中,如搜索“乔丹的队友”,传统的检索方式会给出检索结果[(皮蓬无疑是乔丹职业生涯最伟大的队友。在这个名单上所有人中,乔丹所有冠军赛季唯一不变的队友就是他。虽然公
…
)、(虽然文森特(vincent)对公牛队最大的贡献可能是他在乔丹短暂的控球后卫生涯,但在乔丹职业生涯早期,他是芝加哥公牛队稳定的首发球员。在)
…
]。
[0091]
除了传统的检索方式之外,本系统将会使用多跳推理模型推理(乔丹,队友,?),并
得到预测结果[库科奇0.4、格兰特0.2,
…
]和预测路径([乔丹—
队员
—》公牛队—
队员-—》库科奇]、[乔丹—
队友
—》阿姆斯特朗—
队友
—》格兰特],
…
),并且依据预测结果去检索库中检索相关信息,并整理出推理结果[(库科奇,1968年9月18日生,2021年入选篮球名人堂
…
)、(格兰特,1992年10月9日生,2016年拉斯维加斯夏季联赛总决赛mvp
…
)]
[0092]
由以上描述可以看出,本发明将检索库中海量的信息利用起来,使用多跳知识推理模型发掘检索库中各种知识之间的关联。在检索过程中使用多跳知识推理模型对检索答案进行推理的同时为使用者提供获得检索结果的推理路径。解决了在一些检索条件下,检索结果不充分,检索依据不可见、不可靠的问题。并提供了相应的信息检索系统应用,为用户提供了一种准确高效的检索方式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。