一种基于word2vec和aspe的高效模糊可搜索加密方法
技术领域
1.本发明涉及机器学习与可搜索加密领域,具体的涉及一种搜索加密方法。
背景技术:
2.随着大数据和云计算的快速发展,越来越多的用户选择将大量电子文档数据外包到云中进行安全存储和处理。电子文档的隐私保护是外包云服务中的一个关键问题。解决这一潜在威胁的简单方法是加密后上传电子文档,并根据用户需要下载和解密它们。但是当文档被转换成基于密文的形式时,它们并没有保留原来的特征。用户和云服务器都无法快速区分哪些文档是用户需要的密文形式。可搜索加密可以在保证文档的隐私性和安全性的同时,为文件搜索提供了有效的解决方案。
3.传统的搜索技术都是基于明文的搜索技术,即不论是搜索网站用户提供的关键字信息或者服务器数据库系统中的数据,都是以明文结构形式进行的。这也就导致了非常严重的个人信息泄露,由于任何的恶意网站服务器都能够窃取查询用户的检索关键字、搜索结果等信息,从而严重危害了个人的信息安全和隐私权。可搜索加密技术就为了破解这种困难,提出了基于密文实现搜索查询信息的基本方法,在这个模型下,可以利用密码学的基本技术,来保证信息使用者的私密信息和生命安全。
4.可搜索加密,就是在加密的情况下实现查询搜索功能。目前许多文档都存储在远程服务器,并且当有需求的时候需要能够搜索文档文以实现文件增、删、改。但有的时候一些文档信息内容又不想被服务器知道,就必须对文件加密处理,怎样将加密文档保存在远程服务器设备上,同时又能够在保密的情况下进行查询搜索和文档编辑,就是可搜索加密的研究内容。
技术实现要素:
5.本发明的目的是提供基于一种基于word2vec和aspe的高效模糊可搜索加密方法。
6.为了实现上述目的,采用以下技术方案:
7.一种基于word2vec和aspe的高效模糊可搜索加密方法,包括训练阶段、索引阶段、陷门阶段、加密阶段和匹配阶段,在训练阶段,通过计算词向量间的空间距离来表示词语间的语义相似度。
8.训练阶段,设置搜索陷门中对应关键字元素位置为1,其余为0;另外,如果数据用户的申请中出现了不在数据拥有者的关键字列表中的词w
′
,那么使用训练后的关键词模型,数据拥有者在训练过的关键词模型中找到一个与w
′
最相似的关键词wi,wi为关键词模型中第i个关键词;关键词w
′
到wi的相似度得分sci,即词向量间的空间距离,计算如下:
9.sci=sim(w
′
,wi)
10.然后,数据用户使用wi·
sci来代替w
′
来构建搜索陷门矩阵q=[q
ij
]m×n,m
×
n为矩阵的维度,即m行n列,q
ij
为矩阵q中的第i行第j列的元素。
[0011]
索引阶段,数据拥有者的密钥设置为sk=(s,m1,m2),一个m
×
n随机矩阵s=
[s
ij
]m×n和两个n
×
n随机矩阵m1,m2用于加密文件,s
ij
∈{0,1},s
ij
为矩阵s中的第i行第j列的元素,其中m
×
n是所有关键字的数量,n要比m大得多;数据拥有者使用提取的关键字构建关键字矩阵w,即w=[w
ij
]m×n,w
ij
为单个文件关键字向量,矩阵w中的第i行第j列的元素;
[0012]
数据拥有者使用矩阵s将文件v的关键字矩阵wv划分为矩阵ia=[a
ij
]m×n和矩阵ib=[b
ij
]m×n,基于密钥s中的每一个s
ij
做如下划分:如果s
ij
=1,令r为随机数,如果s
ij
=0,令a
ij
=b
ij
=w
ij
。
[0013]
陷门阶段,数据用户使用矩阵s划分搜索矩阵q=[q
ij
]m×n到矩阵qa=[x
ij
]m×n和矩阵qb=[y
ij
]m×n,q
ij
为单个查询关键字向量,基于密钥s中的每一个s
ij
做如下划分:如果s
ij
=1,令a
ij
=b
ij
=q
ij
;如果s
ij
=0,令r为随机数,如果s
ij
=0,令a
ij
=b
ij
=q
ij
。
[0014]
加密阶段,利用哈达玛乘积将aspe方案从一维扩展到多维运算。
[0015]
加密阶段,利用哈达玛乘积将aspe方案从一维扩展到多维运算的过程如下:
[0016]
使用哈达玛乘积和aspe方案来构建公式如下:
[0017]
针对密钥为文件v的索引为索引加密算法ei如下:
[0018][0019]
针对密钥陷门陷门加密算法eq如下:
[0020][0021]
匹配过程的算法如下:
[0022][0023]
因此,矩阵(ivm)*(m-1qt
)
t
的所有元素的总和计算为的所有元素的总和计算为
[0024]
数据拥有者利用密钥s,并使用扩展后的aspe加密方案ei将文件v的索引矩阵{ia,ib}加密为indexv={i
′a,i
′b},其中i
′a=ei(ia,m1)=iam1,i
′b=ei(ib,m2)=ibm2;
[0025]
数据用户利用密钥s,并使用扩展后的aspe加密方案eq将查询q的陷门矩阵{qa,qb}加密为tdq={q
′a,q
′b},其中},其中
[0026]
匹配阶段,云服务器通过扩展后的aspe方案匹配算法获取匹配文件:
[0027][0028]
设w*q的元素为[w
ijqij
]m×n,云服务器计算矩阵w*q的所有元素之和如下:
[0029]
[0030]
计算索引与搜索陷门之间的tanimoto系数:
[0031][0032]
最后,云服务器根据tanimoto系数值从大到小排序,并选择与数据用户相关度最高的文件。
[0033]
本发明的优势在于:
[0034]
1.利用word2vec机器学习技术实现了可搜索加密的语义模糊搜索功能。通过计算词向量间的空间距离来表示词语间的语义相似度,因此可搜索加密方案能够具有很好的语义特性。
[0035]
2.将aspe进行多维扩展从而保证安全性的同时可以减少不必要的存储空间,从而可以提升搜索效率,进一步得到更广泛的应用。
附图说明
[0036]
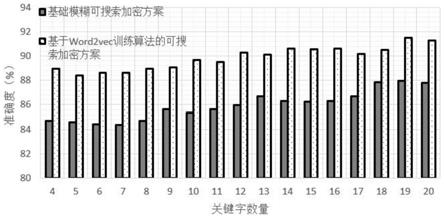
图1为两种方案不同关键字数量时的搜索准确率;
[0037]
图2为两种方案的搜索时间比较图;
[0038]
图3为两种方案的高文档数量下单搜索时间成本比较图;
[0039]
图4为传统意义上的word2vec生成的词向量。
具体实施方式
[0040]
下面结合附图和具体实施例对本发明的实施例做详细的介绍。
[0041]
本发明提出了一种基于word2vec和aspe的高效模糊可搜索加密方法,该方法主要应用于云服务器电子文档加密场景。该算法主要内容如下:为了实现模糊搜索功能,数据所有者使用所有文件作为word2vec的输入来训练语义相关模型并为索引关键字生成关键字向量。随后数据所有者采用非对称向量积保持加密算法(aspe)对文件索引进行加密。
[0042]
在本发明中,为基于多关键字的模糊可搜索加密设计系统模型,主要涉及三个角色:数据所有者、云服务器和数据用户。
[0043]
数据所有者:该实体拥有所有文件的明文。为了保证安全并降低存储成本,数据所有者将所有文件加密并存储到云服务器中。为了实现对加密文件的模糊搜索,数据所有者提取关键字并生成文档作为word2vec算法的输入,然后创建关键字向量。
[0044]
云服务器:云服务器作为外包服务器,负责存储来自所有数据所有者的大量加密文件数据,并进行加密搜索。在系统模型中,云服务器是诚实且好奇的,即半诚实的。执行搜索操作并返回结果将是诚实的,同时它会窥探存储在内部的信息和来自数据用户的查询向量。
[0045]
数据用户:数据用户向云服务器发送请求查询操作,对匹配的密文进行解密,得到实际搜索到的明文数据。
[0046]
word2vec模型是神经网络在nlp领域应用的典型代表,该模型是以无监督方式从海量文本语料中学习富含语义信息的低维词向量的语言模型。通过将单词从原数据空间映射到新的空间,从高维转化为低维,使得同义词在新空间内距离相近,从而可以通过计算空间距离来表示语义相似度。word2vec模型中,每个词都可以用神经网络中的分布权重来抽
象表示。
[0047]
在图4中,word2vec使用词汇表中的词来表示三维数据,即royalty、masculinity和ability。比如king的词向量设置为(0.99,0.94,0.78)。可以得到,词向量之间的关系评估为
[0048]
具体来说,word2vec通常采用哈夫曼树,其中哈夫曼树被定义为由权重构造的二叉树。哈夫曼树中底部的每个叶子节点代表一个单词,有且仅有一条唯一的从根节点到叶子节点的路径,根节点即为该单词通过求和再取平均之后的词向量。word2vec模型中采用逻辑回归的数学方法,向左孩子的边编码为1,向右孩子的边编码为0。通过使用sigmoid函数来判断路径中的前进方向应该选左还是选右。
[0049]
第二种采用的技术是非对称向量积保持加密算法(asymmetric scalar-product-preserving encryption,aspe)近年来,随着数据挖掘领域的迅猛发展,分类器是一种非常重要的对样本进行分类的方法。但是在实验过程中,测试对象的某个特征,不一定能找到与之刚好符合的训练对象。也可能会出现某个测试对象的特征同时对应多个训练对象,导致可以被分到不同的类,为了解决以上这些问题,k最邻近分类算法(k-nearestneighbor,knn)诞生了。
[0050]
一种支持knn的方法是使用距离保持变换来加密数据点,以便加密后任意两个加密点之间的距离与对应原始点之间的距离相同。但是这种转换在实践中并不安全。如果攻击者可以访问距离保持变换加密的数据库并且知道普通数据库中的几个点,他就可以完全恢复原始数据。因此本发明选择对非对称向量积保持加密算法(asymmetric scalar-product-preserving encryption,aspe)进行扩展,同时支持安全准确的knn查询计算,来实现基于关键字的密文检索。
[0051]
aspe是一种向量加密机制。令eq为查询向量的加密算法,ei为索引向量的加密算法。索引向量的密文i
′i和查询向量的密文q
′
创建如下:
[0052]i′i=ei(ii,m)=iim
[0053]q′
=eq(q,m)=m-1qt
[0054]
其中m作为密钥。aspe方案可以保持i向量和q向量的点积为
[0055]i′i·q′
=iim
·
m-1qt
=ii·qt
[0056]
本发明由五个阶段组成,每个阶段中有相应的算法,描述如下。
[0057]
(1)训练:在训练阶段,数据所有者训练word2vec模型并为每个文件创建关键字向量。
[0058]
(2)索引:数据拥有者构建关键字矩阵,生成秘密文件索引。
[0059]
(3)陷门:数据拥有者将对称密钥通过安全信道发送给数据用户,数据用户将搜索请求作为输入,生成搜索陷门。
[0060]
(4)加密:数据拥有者对索引加密,数据用户对陷门加密。
[0061]
(5)匹配:在匹配搜索阶段,云服务器调用该算法对加密文件进行搜索,将最相似的密文发送给数据用户。
[0062]
具体过程如下:
[0063]
(1)训练算法过程:
[0064]
为了满足用户的复杂语义搜索需求,数据拥有者通过word2vec神经网络训练文件
encryption,aspe)是一种向量加密机制。令eq为查询向量的加密算法,ei为索引向量的加密算法。索引向量的密文i
′i和查询向量的密文q
′
创建如下:
[0081]i′i=ei(ii,m)=iim
[0082]q′
=eq(q,m)=m-1qt
[0083]
其中m作为密钥。aspe方案可以保持i向量和q向量的点积为
[0084]i′i·q′
=iim
·
m-1qt
=ii·qt
[0085]
因为aspe支持安全准确的knn查询计算,同时针对数据拥有者文件中若需要存储更多的关键字数量,那么将索引从一维向量到多维矩阵的转换占用空间更小。所以本发明中利用哈达玛乘积将aspe方案从一维扩展到多维,从而可以支持更广泛的应用。扩展方式如下。
[0086]
在本发明中,索引和查询被编码成两个m
×
n矩阵,即
[0087][0088][0089]
通过使用哈达玛乘积和aspe方案来构建公式如下:
[0090]
针对密钥为文件v的索引为索引加密算法ei如下:
[0091][0092]
针对密钥陷门陷门加密算法eq如下:
[0093][0094]
匹配过程的算法如下:
[0095][0096]
因此,矩阵(ivm)*(m-1qt
)
t
的所有元素的总和计算为
[0097][0098]
本发明的算法设计在保证哈达玛乘积与aspe方案组合的正确性的基础上,将aspe方案从一维扩展到多维,从而可以降低存储空间占用成本和通信成本,显著提高计算效率。
[0099]
数据拥有者利用密钥s,并使用扩展后的aspe加密方案ei将文件v的索引矩阵{ia,ib}加密为indexv={i
′a,i
′b},其中i
′a=ei(ia,m1)=iam1,i
′b=ei(ib,m2)=ibm2。
[0100]
数据用户利用密钥s,并使用扩展后的aspe加密方案eq将查询q的陷门矩阵{qa,qb}加密为tdq={q
′a,q
′b},其中},其中
[0101]
(5)匹配算法过程
[0102]
数据用户为了搜索文件,首先向数据拥有者提出请求,再向云服务器发送一个搜索陷门。由于文件索引和搜索陷门都有加密形式,云服务器在匹配过程中不会泄露文件和查询信息。云服务器通过本发明中扩展后的aspe方案匹配算法获取匹配文件:
[0103][0104]
设w*q的元素为[w
ijqij
]m×n,云服务器计算矩阵w*q的所有元素之和如下:
[0105][0106]
tanimoto系数又称为广义的jaccard相关系数。设a和b为两个样本向量,tanimoto系数表达式为:
[0107][0108]
向量中的每一位代表了可以对样本进行衡量的一个维度,但是不再对取值做出限制。a
·
b表示向量点积,表示向量的模。
[0109]
本发明中通过计算索引与搜索陷门之间的tanimoto系数:
[0110][0111]
最后,云服务器根据tanimoto系数值从大到小排序,并选择与数据用户相关度最高的文件。
[0112]
本发明的优点在于:
[0113]
1)更高的模糊搜索准确率:
[0114]
如图1所示,基于word2vec训练算法的可搜索加密方案可以达到较高的精度,在语义模糊搜索方面展现了优越的性能表现。
[0115]
2)更快的搜索效率:
[0116]
考虑到原始的aspe方案,假设关键字的数量为n,这意味着该方案需要执行o(n2)次点乘运算和o(n-1)次加法运算。本发明中通过通过对aspe方案进行改进,如图2所示,搜索过程只需要o(n)次点乘运算和o(n-1)次加法运算,进一步提高了搜索的效率。
[0117]
原始aspe方案中查询和匹配时间都与文件数量成线性关系,本发明中通过对aspe方案进行改进,极大得降低了高文档数量下搜索时间所需成本,如图3所示,提高了搜索能力。
[0118]
3)降低了通信成本:
[0119]
扩展后的aspe方案针对更多的关键字数量,从一维向量到多维矩阵的转换使得文件的索引占用空间更小。显然,这种方法可以显著提高计算效率并降低通信成本。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
