1.本发明涉及一种基于运动前景的场景自适应目标检测方法。
背景技术:
2.在计算机视觉领域,目标检测是一个重要课题,他的任务是找到图像视频中的感兴趣区域,并确定其类别与位置。目前,众多基于深度学习的方法能够在基准数据集上取得良好效果,然而由于域差异的存在,即目标大小、摄像机角度、光照、背景环境发生改变时,该模型的效果均有不同程度的下降。在相同域上训练模型时解决此问题最简单有效的办法,即数据驱动式训练,然而一方面,人工标注数据集花费大量的人力物力,另一方面,很多实际领域并不能人工标注。由此,为了解决由于数据分布不同导致的模型泛化性能下降,基于域自适应的目标检测方法应运而生。
3.目前,基于域自适应的目标检测方法包括基于特征的、基于模型的等方法。其中最为经典的方法(da-fasterrcnn)为,通过嵌套对抗训练模块,最小化特征图的领域差异,使得分类器无法区分候选框特征,后续相关算法都是基于此算法进行改进。另外还有一类算法通过对抗生成,实现像素级别的域对齐。
4.然而上述算法只考虑了分类方面的域差异,没有考虑回归上的域差异,导致其场景变换后效果不理想。另外,对于域差异较大图像,由于数据分布未知,在两阶段目标检测的一阶段提取候选区域rpn阶段,无法有效提取合适的候选框目标,在特征对齐时也无法判别哪些区域的特征需要对齐。
技术实现要素:
5.本发明提出了一种基于运动前景的场景自适应目标检测方法,用以解决现有技术存在的上述技术问题。
6.根据本发明的一个方面,提供了一种基于运动前景的场景自适应目标检测方法,包括以下步骤:
7.a)获取源域数据集与目标域数据集,其中源域数据集包含源域rgb图像、目标检测人工标签、运动前景目标框标签,目标域数据集包含目标域rgb图像、运动前景目标框标签;
8.b)将源域数据集,目标域数据集输入特征提取模块分别获取源域特征与目标域域特征;
9.c)将步骤b)中获取的源域特征与实例域特征输入第一候选框前景框特征聚合模块,分别获得源域实例特征、目标域实例特征;
10.d)将步骤b)中获取的源域特征输入第二候选框前景框特征聚合模块,获得源域分类回归特征;
11.e)将步骤c)中获取的源域实例特征、目标域实例特征输入生成式相似性度量网络模块,计算损失,优化网络,降低域差异;
12.f)将步骤d)中获取的源域分类回归特征输入分类回归模块,计算损失,优化网络;
13.g)将步骤b)中获取的源域特征、目标域特征输入全局特征对齐网络模块,计算损失,优化网络;
14.其中,步骤a)中的运动前景目标框获取方式包括但不限于vibe、混合高斯背景消除、帧差、光流;
15.其中,步骤c)中的第一候选框前景框特征聚合模块包括,在训练过程中,将置信度较高的rpn候选框与运动前景目标框联合,样本均衡化后,进行源域实例特征与目标域实例特征提取;
16.其中,步骤d)中的第二候选框前景框特征聚合模块包括,在训练过程中,将运动前景目标框联合rpn候选框联合,进行源域分类回归特征的提取;
17.其中,步骤e)中的生成式相似性度量网络模块包括,在训练过程中,对提取到的源域实例特征和目标域实例特征,使用解码器重构实例特征获取解码特征,计算解码特征的相似度损失,实现实例特征对齐;
18.其中,步骤f)中的分类回归模块包括,在训练过程中,通过源域目标框真值标签计算源域数据集分类回归损失,从而保证源域目标检测准确性;
19.其中,步骤g)中的全局特征对齐网络模块包括,梯度反转层和分类器,从而实现图像层面特征对齐。
20.与现有技术相比,本发明具有以下有益效果:
21.本发明提出的一种基于运动前景的场景自适应目标检测方法,该方法通过有效利用运动前景的先验知识,同时使用解码器进行特征对齐,从而获得良好的检测效果,有效提升模型在新场景下的泛化性能。
附图说明
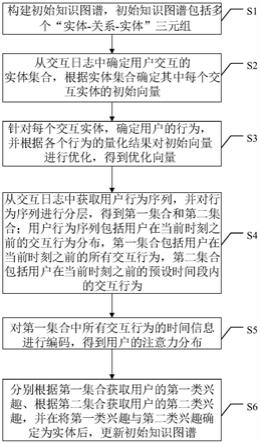
22.图1是根据本发明的一个实施例的基于运动前景的场景自适应目标检测方法的流程图;
23.图2是根据本发明的一个实施例的第一候选框前景框聚合模块的构造示意图;
24.图3是根据本发明的一个实施例的第二候选框前景框聚合模块的构造示意图;
25.图4是根据本发明的一个实施例的生成式相似性计量模块的构造示意图;
26.图5是根据本发明的一个实施例的全局特征对齐模块的构造示意图;
具体实施方式
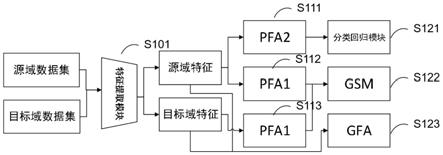
27.图1的实施例中,源域数据集为ns表示源域中真实样本数量,表示源域中的样本i,表示源域中样本i的目标框坐标值集合,表示源域中第i个样本的目标类别。本具体实施例中只有行人单一类别,表示源域中第i个样本的运动前景目标框坐标值集合,集合内目标框数量与集合内目标框数量不一致;目标域数据集用表示,其中nt表示目标域中真实样本数量,表示目标域中的样本i,表示目标域中样本i中包含的运动前景目标框坐标值数据集。
28.根据本实施例的基于运动前景的场景自适应目标检测方法基于源域数据和目标
域的运动前景数据对模型进行训练,使得模型在无目标域(t)标注数据集情况下也拥有良好的检测效果,其包括以下步骤:
29.a)把源域连续帧样本集合和目标域连续帧样本集合输入vibe运动目标检测算法获取源域运动前景目标框和目标域运动前景目标框(其中s代表源域,t代表目标域),因此源域数据集ds与目标域数据集d
t
被获取。
30.b)源域数据集ds与目标域数据集d
t
输入特征提取模块(s101),获取源域特征f1和目标域特征f2,本具体实施例中特征提取模块的主干网络为resnet-101;
31.c)将源域特征f1、源域运动前景目标框输入第一候选框前景框聚合模块pfa1(s112)得到源域实例特征pfs,将目标域特征f2和目标域运动前景目标框输入候选框前景框聚合模块pfa1(s113),得到目标域实例特征pft;
32.d)将源域特征f1与运动前景目标框输入第二候选框前景框聚合模块pfa2(s111),得到源域分类回归特征crs;
33.e)把源域分类回归特征crs输入分类回归模块(s121)。通过源域目标框真值标签计算源域数据集的分类回归损失,通过对源域数据集进行训练优化特征提取模块与分类回归模块网络权重;
34.f)把源域实例特征pfs和目标域实例特征pft输入生成式相似性计量模块gsm(s122),通过对源域数据集、目标域数据集进行训练,使得源域实例特征和目标域实例特征尽可能相似,优化特征提取模块和生成式相似性计量模块gsm的网络权重,进而提升模型的泛化性能;
35.g)将源域特征f1和目标域特征f2通过全局特征对齐模块gfa(s123);通过对源域数据集、目标域数据集进行训练,使得源域和目标域特征尽可能相似,优化特征提取模块、全局特征对齐模块gfa(梯度反转层层(grl)与分类器)网络权重使源域特征f1和目标域特征f2的所属域无法被分辨出。
36.根据本发明的一个进一步的方面,如图2所示,所述第一候选框前景框聚合模块pfa1包括分别执行以下操作步骤的子模块:
37.步骤s201:把源域连续帧样本和目标域连续帧样本输入rpn网络(region proposal network),生成正负候选框集合其中代表源域和目标域第i个图像样本的第j个候选框,c代表rpn网络生成的候选框的数量,本实施例中取值64,表示源域中第i个图像样本,表示目标域中第i个图像样本;
38.步骤s202:在本实施例中,把源域连续帧样本和目标域连续帧样本输入vibe运动目标检测算法,分别获取源域运动前景目标框和目标域运动前景目标框fbi为第i个图像样本的运动前景目标框集合;
39.步骤s211:选取正负候选框集合中置信度大于预设的阈值th的候选框,本实施例中th取值0.7;
40.步骤s212:合并步骤s211得到的候选框与步骤s202获取的运动前景目标框
41.步骤s213:将步骤s212的输出输入样本均衡过滤器filter,获取源域pfa1候选框集合、目标域pfa1候选框集合其中{b
if
}j代表数据集中第i个样本中第j个个pfa1候选框集合,f为标识符代表pfa1模块生成的候选框集合,s代表源域,t代表目标域,c
sf
,c
tf
分别代表源域中候选框与运动前景目标框的集合中框的个数与目标域中候选框与运动前景目标框的集合中框的个数,其中c
sf
=c
tf
;
42.其中,样本均衡过滤器filter,设置固定样本数量f_num,本实施例中被设置为8,使源域(s)中的第i个样本与目标域(t)的第i个样本中pfa1候选框的数量保持一致,从而消除样本不均衡。
43.根据本发明的一个进一步的方面,如附图3所示,第二候选框前景框聚合模块pfa2包括分别进行如下操作的子模块:
44.步骤s301:将源域连续帧样本通过rpn网络,生成源域正负候选区域集合其中c为一个常量代表rpn网络生成的候选框的数量,本实施例中取值64,为源域第i个样本的第j个候选框;
45.步骤s302:本实施例中,将源域连续帧样本输入vibe运动目标检测算法中,获取源域运动前景目标框fbi为第i个图像样本的运动前景目标框集合;
46.步骤s311:叠加步骤s301中生成的源域正负候选区域集合与步骤s302中生成的源域运动前景目标框生成源域pfa2候选框集合其中{b
ia
}j代表第i个样本中第j个pfa2候选框集合,a为标识符代表pfa2模块生成的候选框集合,s代表源域,c
sa
源域中候选框与运动前景目标框的集合中框的个数.通过运动前景目标框的加入解决了两域在目标尺寸差异过大时无法生成准确的候选框的问题。
47.根据本发明的一个进一步的方面,在分类回归模块s121中,将源域特征f1与pfa2候选框集合输入分类器与回归器对样本进行回归与分类,该部分损失函数如下:
48.l
det
=l
rpn
l
t
49.上式中,l
det
代表源域检测损失函数,由l
rpn
,l
t
两部分组成,l
rpn
是rpn损失函数,l
t
是二阶段分类回归损失函数;其中角标det代指分类回归模块的总损失函数名称,rpn代指二阶段目标检测框架的第一阶段rpn阶段的损失函数名称,t代指二阶段目标检测框架的第二阶段分类回归阶段的损失函数名称。本具体实施例中,分类损失使用交叉熵损失,回归损失使用均方误差(mse)损失。
50.根据本发明的一个进一步的方面,如图4所示,生成式相似性计量模块gsm包括分别进行如下操作的子模块:
51.步骤s401:将pfa1模块生成的pfa1候选框集合输入特征提取模块提取到的源域特征f1、目标域特征f2,生成源域实例特征fs和目标域实例特征f
t
;
52.步骤s402:将源域实例特征fs和目标域实例特征f
t
输入自适应平均池化层输出池化特征f
ss402
,f
ts402
,其输出尺寸为8*8,通道数等于源域实例特征fs特征通道数;
53.步骤s403:将s402中的输出输入第一1*1卷积层,本实施例中通道数为1024,输出源域第一卷积层特征和目标域第一卷积层特征f
ss403
,f
ts403
;
54.步骤s404:将s403中的输出输入第一上采样模块,该第一上采样模块由插值上采样层、卷积层、批标准化层等组成,上采样后的特征尺寸为16*16,本实施例中通道数为256,输出源域第一上采样特征和目标域第一上采样层特征f
ss404
,f
ts404
;
55.步骤s405,将s404的输出输入第二上采样模块,上采样后特征尺寸为32*32,本实施例中通道数为256,输出源域第二上采样特征和目标域第二上采样层特征f
ss405
,f
ts405
;
56.步骤s406,将s405的输出输入上采样模块3,上采样后特征尺寸为64*64,本实施例中通道数为256,输出源域第二上采样特征和目标域第二上采样层特征f
ss406
,f
ts406
;
57.步骤s407,将s406中输出的特征输入第二1*1卷积层,生成特征的通道数为3,生成源域解码特征、目标域解码特征f
sg
,f
tg
。
58.计算源域、目标域解码特征f
sg
,f
tg
的感知损失,得到损失l
ins
;
59.l
ins
=e(g(s),g(t))
60.其中e为感知损失,是一种被用来衡量图像之间的相似性的损失函数;
61.l
ins
为源域解码特征、目标域解码特征f
sg
,f
tg
感知损失值,e为感知损失计算函数(该感知损失函数为已有技术),g(s),g(t)分别代指源域实例特征和目标域实例特征fs,f
t
经过步骤s402-s407(共享解码器g)生成的源域解码特征、目标域解码特征f
sg
,f
tg
。该方案可以有效衡量两域(源域和目标域)实例特征之间的相似性。通过对特征提取模块与生成式相似性计量模块gsm的训练,可以使源域实例特征和目标域的实例特征尽可能相似,保证了分类回归模块模块在目标域的准确性;同时解码器的使用增强了模型的泛化性能,降低模型过拟合的风险,减少模型训练失败率。
62.根据本发明的一个进一步的方面,如图5所示,全局特征对齐模块gfa包括分别进行如下操作的子模块:
63.步骤s501:获取上述步骤中生成的源域特征f1和目标域特征f2;
64.步骤s502:将源域特征f1,目标域特征f2输入梯度反转层grl,常规反向传播中将损失(预测值和真实值的差距)逐层向前传递,每层网络根据传递损失计算梯度,进而更新本层网络的参数。grl层将传到本层的误差取反,从而实现grl前后的网络训练目标相反,以实现对抗的效果;
65.步骤s503:把源域特征f1,目标域特征f2输入分类器,以区分源域特征和目标域特征,该分类器包括卷积层、激活层,具体的分别执行步骤s511-s513的操作。
66.其中,全局特征对齐模块gfa的损失函数为分类器的损失函数l
img
。本实施例中,l
img
为交叉熵损失函数:
[0067][0068]
其中,n为源域和目标域所有样本数量的和,i为样本标号,yi为样本实际标签即属于源域还是目标域,pi为经过分类器后属于不同类别的概率。
[0069]
在本发明的一个实施例中,最终的全局损失函数为:
[0070]
l=l
det
λ1l
ins
λ2l
img
[0071]
其中λ1,λ2为经验值,用于衡量三项损失对最终损失的贡献值,均取为1。
[0072]
本发明的优点包括:
[0073]
(1)本发明充分利用了运动前景这一先验,并将其很好的融入训练框架之中。通过使用fpa1候选框前景框聚合模块和fpa2两大候选框前景框聚合模块对rpn网络提取的候选框与运动前景目标框进行有效融合,使两类候选框相互补充相互影响,实现模型效果的优化。
[0074]
(2)在进行实例特征对齐时,为了减少模型过拟合的风险,提升目标框回归准确率,本发明摒弃了已有的通过分类器进行特征对齐的方式,改用解码器降低过拟合,通过感知损失函数计算损失,极大程度了提升了模型在目标域的效果。
[0075]
(3)在rpn网络提取的候选框与运动前景目标框融合中,通过样本均衡过滤器,有效的实现了样本均衡。
[0076]
为了验证本发明方法的有效性和改进效果,本发明人进行了如下实验,其中,测试过程只需按照两阶段检测算法测试过程进行测试,因此在速度上与常规两阶段算法一致。通过在模型训练时添加部分组件,使得训练后的模型在源域与目标域中均能获取良好的效果。
[0077]
该实验的测试实例所采用的源域数据集与目标域数据集均来自于真实场景,分别被命名为dml数据集与zn数据集,其中dml数据集为源域数据集,zn数据集为目标域数据集。
[0078]
实验细节:在该实验中采用的参数与原始da-fasterrcnn算法(经典域自适应检测算法)保持一致,骨干网络使用resnet-50,骨干网络的初始化采用imagenet的预训练权重。训练了70000张图片后,计算目标域的平均精度map。实验是基于pytorch框架的,使用的硬件平台为:nvidiagtx-2080ti。
[0079]
表1为实验结果对比图,其中方法da-fasterrcnn为经典域自适应检测算法,方法pfa1为在经典算法上添加第一候选框前景框聚合模块pfa1,即在rpn候选框的基础上融合运动前景目标框。可以看到,本发明方法显著提升了目标域的检测效果。
[0080]
表1:域自适应检测结果
[0081]
方法map(%)da-fasterrcnn27.45pfa133.97本发明方法63.81
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。