1.本发明涉及一种融入词汇信息的嵌套命名实体识别方法,通过文本与外部词典匹配,利用词级别信息为嵌套命名实体识别提供词边界信息,属于自然语言处理中的信息抽取技术领域。
背景技术:
2.作为人类沟通和传递信息的主要工具,自然语言本身蕴含了丰富的非结构化信息。如何从非结构化文本中提取出便于机器处理的结构化数据,是当前面临的一大挑战。
3.命名实体识别任务,旨在从文本中抽取能够表示独立存在的具体事务或实体的文本片段,可用于知识图谱的构建及一些文本分析的下游工作。
4.根据实体的文本片段边界是否存在嵌套结构,可以分为扁平命名实体识别抽取和嵌套命名实体识别抽取。命名实体识别在早期的研究过程中,一般集中于扁平命名实体识别抽取,句中每个单词最多只属于一个实体类型,因而通常将其建模为序列标注任务。近年来,嵌套命名实体识别逐渐得到重视和发展,其采用其他标注方式抽取嵌套实体,但多以英文的研究为主,针对于中文的研究通常是较为简单的语料迁移。
5.由于中文所属的汉藏语系不同于以英语为代表的印欧语系,英语是通过空格来分割句中单词,有比较清晰的分词结构,而中文是连续的字构成的句子,没有在表示基本语义信息的单词维度上进行显示划分,导致中文的词级别信息模糊,而命名实体识别任务对于单词边界划分敏感。随着深度神经网络在自然语言处理领域的广泛应用,模型对句子的语义信息建模能力有所增强,但是,对于词级别知识仍有所欠缺。
技术实现要素:
6.本发明的目的是为了解决现有的机器学习中文嵌套命名实体识别模型缺乏词级别信息的问题,提出了一种融入词边界信息的中文嵌套命名实体识别方法,将文本与外部词典进行匹配并通过匹配词与原始文本共同建模。
7.首先,对有关概念进行说明:
8.定义1:文本序列s
9.指待抽取嵌套实体的一个中文句子,由连续的字构成。
10.符号表示为:s={w1,w2,
…
,wn},其中n表示句子的长度,wi表示句子中第i个字。
11.定义2:外部词典d
12.指独立于训练语料的词典文件,是中文常见词的集合,每个词由一个或多个字组成。
13.符号表示为:d={d1,d2,
…
,d
/d/
},其中,|d|表示词典文件中的单词数量,di表示词典中的第i个词汇。
14.定义3:文本匹配词m
15.指文本序列与外部词典按照贪心算法匹配,根据文本匹配到的词典中的单词的集
合为文本匹配词。
16.s对应的匹配词表示为:m={m1,
…
,mk},其中k表示一个文本序列中匹配出来的词汇个数。
17.定义4:中文嵌套实体识别语料库
18.指针对于中文领域的嵌套实体识别任务的文本和标注信息构成的数据库,其中文本即为文本序列s的集合,而标注信息是记录文本序列中嵌套实体词在原文本的开始位置索引和结束位置索引及实体类型的三元组,符号表示为:(start,end,label)。
19.定义5:中文静态词向量e
20.指根据大规模语料预训练得到开源的中文字、词的静态向量表示。其中,静态字向量表示为ew,静态词向量表示为em。
21.定义6:位置向量pe
22.指对于文本序列中每个字的位置索引pos对应的向量表示。计算方法通过三角函数计算得到,如式1、式2所示:
[0023][0024][0025]
其中,d
model
表示位置向量的维度,pe
(pos,2i)
表示第pos索引位置向量的第i维度上值。
[0026]
定义7:预训练语言模型lm
bert
[0027]
指利用大型无监督语料预训练的深层语言模型bert。
[0028]
定义8:语义信息x
bert
[0029]
指通过计算每个句子中字之间的信息交互得到的句子层面的信息表示。
[0030]
可以通过预训练语言模型lm
bert
做字级别信息交互,获得语义信息x
bert
。
[0031]
定义9:实体类型c
[0032]
指语料库中标注出来的实体类型的集合,符号表示为c={o,c1,c2,
…
,c
|c|
},其中,o类型表示非实体类型,其余为预定义实体类型。
[0033]
本发明采用以下技术方案实现。
[0034]
一种融入词边界信息的中文嵌套命名实体识别方法,包括以下步骤:
[0035]
步骤1:获取中文嵌套实体识别语料库,以及外部词典和开源的中文静态词向量。
[0036]
步骤2:对于语料中的每一个文本序列s,通过贪心算法得到匹配词m。
[0037]
具体地,贪心算法的计算方式为:
[0038]
首先,遍历文本序列中的每个字wi,在外部词典d中查找以wi为开始字且与wi之后的字能够一一对应的尽可能长的所有词汇,并记录每个匹配词对应原始文本的开始索引和结束索引位置。
[0039]
然后,将{m1,
…
,mk}的开始索引记为pos
m,start
={pos
m,s1
,
…
,pos
m,sk
},将结束索引记为pos
m,end
={pos
m,e1
,
…
,pos
m,ek
}。
[0040]
{w1,w2,
…
,wn}的开始索引和结束索引,均是从1开始递增,分别记为pos
s,start
={1,2,
…
,n}、pos
s,end
={1,2,
…
,n}。
[0041]
步骤3:通过pos
m,start
、pos
m,end
、pos
s,start
、pos
s,end
计算每两个位置之间的相对位置向量r
ij
,如下所示:
[0042][0043][0044][0045][0046][0047]
其中,pos
start,i
表示pos
m,start
或pos
s,start
中第i个的位置索引,pos
end,i
表示pos
m,end
或pos
s,end
中第i个的位置索引,pos
start,j
、pos
end,j
的定义同理,以此类推。
[0048]
通过体现了字、匹配词之间的边界位置信息,表示利用位置向量pe得到索引为表示利用位置向量pe得到索引为的位置向量,其携带边界信息的相对位置编码;wr为模型需要学习的参数,relu()为深度学习中常用的激活函数。
[0049]
步骤4:从中文静态词向量e中得到文本序列s和匹配词m对应的向量表示e,
[0050]
步骤5:使用两层transformer-xl的编码结构,对步骤4得到的字词向量进行编码计算。再计算attention阶段融合相对位置,得到带有词边界信息的每个字的向量表示。
[0051]
具体地,方法如下:
[0052]
sub_layer_output=layernorm(x (sublayer(x)))
ꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0053]
att(a,v)=softmax(a)v
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0054][0055][0056]
其中,sub
layer_output
表示transformer-xl的子层输出,layernorm()表示层级正则化计算,sublayer()表示transformer-xl的子层结构,att()表示自注意力计算,a表示自注意力计算的注意力权重矩阵,a
ij
表示a矩阵中第i行第j列的元素,v表示transformer-xl前一子层的输出经过线性变换的结果,softmax()、relu()均为激活函数,ffn()表示前馈神经网络,xi、xj表示i、j索引位置的字符,表示xi、xj在中文静态词向量e中的向量表示,w
k,e
、w
k,r
均表示模型待学习的不同参数矩阵,其中是参数矩阵w1、w2、wq的转置矩阵,b1、b2均表示模型待学习的不同参数列向量。
[0057]
在每个transformer-xl层中都包含两个子层,最后一层的输出为融合词边界信息的向量表示,记为x
boundary,i
,式8为子层计算的基本逻辑,x表示子层的输入向量,第一子层
式9是式8的输入,第二子层式10是式8的输入,式9中的权重矩阵a的每位元素计算为式10,当前transformer-xl层的输入为前一层的输出,初始化输出即为e。
[0058]
步骤6:利用lm
bert
得到每个字带有语义信息的向量表示,将字wi的语义信息的向量表示记为x
bert,i
。
[0059]
步骤7:按照式12对两种向量表示进行拼接,得到最终字的向量表示xi。
[0060]
xi=[x
bert,i
;x
boundary,i
]
ꢀꢀꢀꢀ
(12)
[0061]
步骤8:利用双仿射分类器,计算每个开始索引位置为i、结束位置索引为j的文本片段span
ij
对于实体类型为c的概率p(i,j,c),具体如下:
[0062][0063][0064][0065]
p(i,j,c)=softmax(score
ij
)
ꢀꢀꢀꢀꢀꢀ
(16)
[0066]
其中,ffnns、ffnne表示两个维度相同的独立线性映射层,分别表示由步骤7得到的文本片段span
ij
的开始字符以及结束字符的向量表示,softmax()表示常见的归一化层,um、wm表示模型的训练参数矩阵,bm表示模型的训练参数列向量。
[0067]
式13至式15是双仿射分类器的计算过程。首先通过两个独立的映射层保留字向量表示中带有实体起始位置信息h
start
(i)、实体结尾位置信息的向量表示h
end
(j),经过双仿射分类器计算得到一个文本片段span(i,j)在不同实体类型上的得分score
ij
,将分数经过softmax()层转化成最终的实体分类的概率p(i,j,c),模型选择概率最大的类型作为span(i,j)的实体类型预测结果。
[0068]
模型使用模型预测结果与语料库中的标注结果的交叉熵作为模型训练的损失函数,通过不断优化损失函数值来训练调整模型参数。
[0069]
至此,从步骤1到步骤8,通过匹配词给模型融入词边界信息,完成了中文场景下的嵌套命名实体识别。
[0070]
有益效果
[0071]
本发明方法,对比现有技术,具有以下优点:
[0072]
本方法结合了中文场景特有的语言形态问题,利用外部的词表向模型中融入词级别信息,对于边界敏感的嵌套命名实体识别任务,模型更加关注于词边界问题,并且利用预训练模型抽取丰富的语义信息向量表示,保证模型在词级别和句子级别都能更好地建模,提升了实体识别的准确性。
附图说明
[0073]
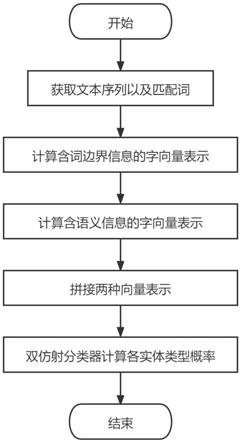
图1为本发明方法的流程图。
具体实施方式
[0074]
下面将结合说明书附图对及实施例对本发明方法作进一步详细说明。
[0075]
如图1所示,本发明包括以下步骤:
[0076]
步骤a:获取文本序列以及匹配词;
[0077]
具体到本实施例中,通过本文序列与外部词典匹配得到匹配词,并记录相关词的位置信息等,具体与发明内容步骤1至2相同;
[0078]
步骤b:计算含词边界信息的字向量表示;
[0079]
具体到本实施例中,通过匹配词与文本序列共享位置信息,利用transformer-xl结构捕获匹配词对应文本的词边界信息,得到带有词边界信息的字向量表示,具体与发明内容步骤3至5相同;
[0080]
步骤c:计算含语义信息的字向量表示;
[0081]
具体到本实施例中,利用预训练模型计算带有语义信息的字向量表示,具体与发明内容步骤6相同;
[0082]
步骤d:拼接两种向量表示;
[0083]
具体到本实施例中,与发明内容步骤7相同;
[0084]
步骤e:双仿射分类器计算各实体类型概率:
[0085]
具体到本实施例中,经过双仿射层计算每个文本片段在各实体类型下的得分,再转化为各实体类型的概率,与发明内容步骤8相同;
[0086]
实施例
[0087]
以文本序列“目前中国代表团共获得26金16银15铜”为实施例,本实施例将以具体实例对本发明所述的融入词边界信息的中文嵌套命名实体识别方法的具体操作步骤进行详细说明;
[0088]
融入词边界信息的中文嵌套命名实体识别方法的处理流程如图1所示;从图1可以看出,融入词边界信息的中文嵌套命名实体识别方法,包括以下步骤:
[0089]
步骤a:获取文本序列以及匹配词;
[0090]
通过贪心算法匹配文本序列的匹配词,对于文本序列长度为19的“目前中国代表团共获得26金16银15铜”,经过词典匹配得到的匹配词有“目前”、“中国”、“代表”、“代表团”、“获得”,匹配词的pos
m,start
={1,3,5,5,9},pos
m,start
={2,4,6,7,10};
[0091]
步骤b:计算含词边界信息的字向量表示;
[0092]
具体到本实施例中,利用transformer-xl计算含词边界信息的100维字向量表示;
[0093]
步骤c:计算含语义信息的字向量表示;
[0094]
利用bert预训练模型计算每个字的包含语义信息512维字向量表示;
[0095]
步骤d:拼接两种向量表示;
[0096]
将步骤b和步骤c的两种字向量拼接,得到612维字向量表示;
[0097]
步骤e:双仿射分类器计算各实体类型概率:
[0098]
具体到本实施例中,通过双仿射层得到一个19
×
19的矩阵,矩阵中的元素就表示文本序列中以矩阵元素位置索引为边界的文本片段的实体类型分类概率,比如识别出“中国”的实体概率是矩阵中的第3行第4列的位置,“中国代表团”的实体概率是矩阵中的第3行第7列的位置。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。