1.本发明属于社交网络分析技术领域,尤其涉及一种基于多相似度融合的科研合作者推荐方法。
背景技术:
2.随着计算机科学技术的不断发展,人类随之进入大数据时代,海量的学术数据(论文、专利、期刊会议等)出现在互联网上,大量的学术实体和学术关系构成了复杂而庞大的学术网络,在各个学科领域建立科学有效的合作变得比以往任何时候都更具有挑战,科研人员通常很难找到和自己最匹配的合作者。随着各类学科的发展,科研工作者之间的合作变得越来越重要,学者之间合作的质量往往也决定了最终科研成果的质量,可以说没有科研人员之间的合作就无法取得如今众多的科学成果。但通常科研人员很难在大量的学术数据中找到和自己最匹配的合作者,而且传统的合作方式不仅效率低下,还浪费了学者们大量的时间和精力。因此,近年来对科研合作者的推荐得到了广泛的研究,如果能够帮助学者推荐和自己研究领域相近的其他科研人员,这将会提高最终科研成果的质量,合作的效率也会进一步提高,并且能够加快科研的进度。
技术实现要素:
3.本发明针对现有技术存在的问题与不足,提出了一种基于多相似度融合的科研合作者推荐方法,该方法融合了科研工作者之间的合作关系相似度、研究领域相似度以及学术水平相似度三个学术特征,通过改进的重启型随机游走算法来计算学术网络中各节点间的相似性,使得游走者能够游走到最有价值的合作者节点。本发明能够为目标学者推荐和自己最匹配的科研工作者。
4.本发明的技术方案:
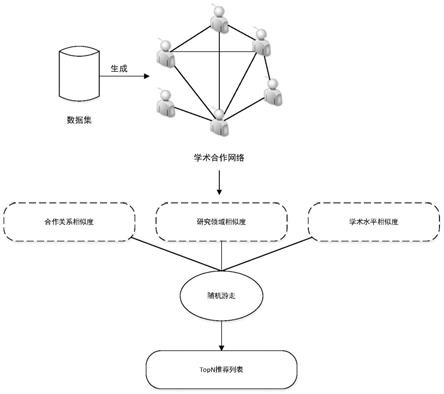
5.一种基于多相似度融合的科研合作者推荐方法,步骤如下:
6.步骤1):获取学者发表论文的数据,并对数据进行预处理操作,从中提取出节点和边的信息,构建出学术合作网络。其中节点为每个学者,只要两个学者之间发生过至少一次的合作关系,他们之间就会用边相连。
7.步骤2):计算合作过的学者之间的合作关系相似度,合作关系相似度综合考虑了学者之间的合作次数和合作年份等因素,其计算公式如下:
[0008][0009]
其中,c(am,an)表示学者am和an之间的合作关系相似度,和分别代表学者am和an发表论文的总数量,是论文pi的发表年份,是两名学者第一篇合著论文的发表年份,tc是当前的年份;是两名学者合著论文的总数量。
[0010]
步骤3):计算学者间的研究领域相似度,首先利用doc2vec模型将学者论文的摘要
转换成向量形式,然后利用余弦相似度计算向量间的相似性,用以表示科研人员之间论文摘要的内容相似度,从而得到科研人员之间的研究领域相似度。包括以下三个步骤:
[0011]
3.1)对论文摘要构成的语料库进行数据预处理,包括大小写转换、拼写错误检查、去停用词等一系列操作,并将标点符号视为无效词,最后保存在文本文件之中,之后将处理后的所有文档数据带入模型进行训练,最后利用训练好的doc2vec模型,把分词后的文本转换成向量形式。
[0012]
3.2)生成向量空间后,利用余弦相似度计算论文摘要对应向量的余弦值,作为论文摘要之间的相似度,计算公式如下:
[0013][0014]
其中,pi和pj为两篇论文摘要所对应的的向量表示形式。
[0015]
3.3)两个学者间的研究领域相似度考虑了两个学者发表的所有论文信息,其计算公式如下:
[0016][0017]
其中,r(am,an)表示学者am和an之间的研究领域相似度,和分别表示学者am和an发表论文的总数,similarity(pi,pj)为论文pi和pj摘要之间的内容相似度。
[0018]
步骤4):根据学术数据统计出每个学者的学术指标信息,包括学者的学术年龄、h-index值、发表论文的数量、总被引次数和合作者数量,将这五个维度信息组合构成学者的学术水平特征向量,利用余弦相似度计算特征向量之间的相似性,从而得到科研人员之间的学术水平相似度,计算公式如下:
[0019][0020]
其中,a(am,an)表示学者am和an之间的学术水平相似度,lm和ln分别为学者am和an的学术水平特征向量。
[0021]
步骤5):将合作关系相似度、研究领域相似度以及学术水平相似度三个维度进行线性组合,作为学术合作网络中边的权重,其公式如下:
[0022]
w(am,an)=α
×
c(am,an) β
×
r(am,an) γ
×
a(am,an)
[0023]
该公式综合了三个学术特征,其中,c(am,an)表示两个科研工作者和之间论文的合作关系相似度,r(am,an)表示两个科研工作者和之间的研究领域相似度,a(am,an)表示科研工作者和之间的学术水平相似度,α、β、γ为权重参数,且α β γ=1。
[0024]
步骤6):将待推荐学者作为目标节点,在学术网络上进行随机游走,直至各个节点的分数趋于稳定状态,从而得到各节点与目标节点之间的相似性,最后根据随机游走的结果生成top-n推荐列表。
[0025]
本发明的有益效果:本发明融合了学者之间的合作关系相似度、研究领域相似度以及学术水平相似度三个学术特征,将三者进行线性组合作为合作网络中边的权重,并对转移概率矩阵做了修改,利用改进的重启型随机游走算法进行推荐。实验结果表明,本发明提出的方法在科研合作者推荐方面结果更加准确,并且相比于其他的方法,本发明在准确
率、召回率、f1值等指标上更具有优势。本发明提供了科研合作者推荐的一种新方法,解决了学者们寻找其他合作者费时费力的问题。
附图说明
[0026]
图1为本发明中科研合作者推荐方法的流程图。
[0027]
图2为学术合作网络示意图。
具体实施方式
[0028]
为了使本发明的目的、技术方案和优点更加清楚,下面将对本发明的具体实施方式作进一步的详细描述。
[0029]
本发明实例提供了一种基于多相似度融合的科研合作者推荐方法,该方法包括:
[0030]
步骤1:本发明的原始数据集为dblp引文网络数据集,该数据集一共包含400多万计算机领域相关的论文信息以及3000多万论文之间的引用关系,每条记录代表一篇论文,以json的格式进行存储,其中包含论文的标题、作者、年份、摘要等信息。首先对数据集进行预处理操作,提取出学者间的合作关系,构建学术合作网络g(v,e),v表示网络中的节点集合,e表示网络中边的集合,将每个学者添加到合作网络中的节点集合中,两两合作的学者之间用边相连,来代表二者之间的合作关系,关系的强弱以边的权重衡量。
[0031]
步骤2:计算学者间的合作关系相似度。合作关系相似度综合考虑了学者之间的合作次数和合作时间等因素,通过结合这两个主要因素,计算出之前合作过的任何两名学者之间合作关系的强弱。合作关系相似度的值越大,两名学者在不久的将来合作的可能性就越大。合作关系相似度计算公式如下:
[0032][0033]
其中,和分别代表学者am和an发表论文的总数量,是论文的发表年份,是两名学者第一篇合著论文的发表年份,tc是当前的年份。
[0034]
步骤3:计算学者间的研究领域相似度。通常,对同一研究领域感兴趣的科研人员之间更有可能产生合作,因此,科研人员之间的研究领域相似性也是决定他们是否合作的重要因素。通常摘要是一篇论文的核心与缩影,包含了作者的研究内容与方法,能够代表一篇论文的主旨。因此,本发明将使用doc2vec模型来计算论文摘要之间的内容相似度,以此来衡量学者之间的研究领域相似度。具体包括如下步骤:
[0035]
3.1)对论文摘要构成的语料库进行数据预处理,包括大小写转换、拼写错误检查、去停用词等一系列操作,最后保存在文本文件之中,之后将处理后的所有文档数据带入模型进行训练。最后利用训练好的doc2vec模型,把分词后的论文摘要转换成向量形式。
[0036]
3.2)生成向量空间后,利用余弦相似度计算摘要对应向量之间的余弦值,作为论文摘要之间的内容相似度,计算公式如下:
[0037][0038]
其中,pi和pj为两篇论文摘要所对应的的向量表示形式。
[0039]
3.3)两个学者间的研究领域相似度考虑了两个作者发表的所有论文信息,其计算公式如下:
[0040][0041]
其中,c(am,an)表示学者am和an之间的研究领域相似度,和分别表示学者am和an发表论文的总数,similarity(pi,pj)为论文pi和pj摘要之间的内容相似度。
[0042]
步骤4:计算学者之间的学术水平相似度。对于大部分普通的学者来说,他们可能更倾向于和自己学术水平相当的学者合作,并且他们在现实中实现合作的可能性也越大。对于学术能力不如自己的那些人员,学者也不太愿意与他们建立合作关系,虽然很多学者都希望能够和领域专家进行合作,但在实际中这种情况也很难实现。假设学者的学术水平特征向量向量中的5个维度分别表示学者的学术年龄、h-index、发表论文的数量、总被引次数和合作者数量。之后采用余弦相似度来计算两个学者学术水平特征向量之间的相似性,来作为两学者之间的学术水平相似度。学者am和an之间的学术水平相似度计算公式如下:
[0043][0044]
其中,a(am,an)表示学者am和an之间的学术水平相似度,lm和ln分别为学者am和an的学术水平特征向量。
[0045]
步骤5:将合作关系相似度、研究领域相似度以及学术水平相似度三个维度进行线性组合,作为学术合作网络中边的权重,其公式如下:
[0046]
w(am,an)=α
×
c(am,an) β
×
r(am,an) γ
×
a(am,an)
[0047]
边的权重综合了三个学术特征,其中,c(am,an)表示两个科研工作者和之间论文的合作关系相似度,r(am,an)表示两个科研工作者和之间的研究领域相似度,a(am,an)表示科研工作者和之间的学术水平相似度,α、β、γ为权重参数,且α β γ=1。
[0048]
步骤6:将待推荐学者作为目标节点,利用改进的重启型随机游走模型在学术网络上进行游走,直至各个节点的分数趋于稳定状态,从而得到各节点与目标节点之间的相似性。具体包括如下步骤:
[0049]
6.1)计算节点之间的转移概率,从节点e到节点f的转移概率计算公式如下:
[0050][0051]
其中,w
e,f
为节点e和节点f之间边的权重,n(pe)为节点e的邻居节点集合;
[0052]
6.2)计算网络中各节点的分数,计算公式如下:
[0053][0054]
其中,ar(pe)是节点pe对应的分数,n是网络中所有节点的个数,α为阻尼因子(dampingfactor),m(pe)表示节点pe的所有邻居节点的集合,s
e,f
是从节点e到节点f的转移概率;
[0055]
6.3)对节点的分值进行迭代更新,直至各节点的分值趋于稳定状态,迭代公式如下:
[0056]
ar
(t 1)
=αs
·
ar
(t)
(1-α)q
[0057]
其中,ar
(t)
表示迭代到第t步时图中各节点的分数向量,表示在第t步时节点e的分数值,q代表重启向量,目标节点的值为1,其他节点设为0,初始状态下,ar
(0)
=q,s为转移概率矩阵,元素s
ij
表示从节点e跳转到节点f的概率。
[0058]
当各个节点的分值趋于稳定状态之后,此时代表学者的各个节点的分值便可看作和目标学者之间的相似度,将所有的分值进行降序排序,然后取top n的学者推荐给目标学者,这样便可帮助学者发现最匹配的科研合作者。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。