1.本发明涉及农业机器人的研究领域,特别涉及一种用于机器人采摘的密集李子精准检测方法及其系统。
背景技术:
2.与苹果、柑橘、芒果等果实相比,李子果型小且密集分布,易被果实或枝叶遮挡。李子树多数被种植在山坡上,其果实的生长环境充满复杂性和不确定性的。在目前李子果园中,李子的成熟度识别与采摘任务都是由果农完成。而如今人工成本涨幅很大,人工成本在总成本的占比也在加大。据调查2019年人力成本涨幅高达12-15%。在精准农业中,劳动力短缺和老龄化对于水果产业的发展增添了阻力。综上所述,密集李子采摘机械化、智能化是整个水果产业发展中不可或缺的一环。
3.在现代精准果园中,由于复杂噪音的干扰,包括风干扰、变化的光照和枝叶遮挡,小目标水果的识别被认为更具挑战性,许多研究人员更喜欢检测大目标水果。虽然相关学者在李子的检测方面做了研究工作,但李子本身簇状生长和不同成熟度混杂的特点,更加大了小目标的检测难度,导致了现有算法在李子检测过程中表现出不佳的性能。到目前为止,尚没有关于在自然环境中检测密集李子的深度学习方法的研究,致使水果采摘机器人在果园中可利用的技术资源是受限的。因此,从实际出发探索出一种高效、准确的李子识别算法是非常有意义的。
技术实现要素:
4.本发明的主要目的在于克服现有技术的缺点与不足,提供一种用于机器人采摘的密集李子精准检测方法及其系统,实现对密集李子目标果实的快速准确地检测,解决实际果园的需求。
5.本发明的第一目的在于提供一种用于机器人采摘的密集李子精准检测方法;
6.本发明的第二目的在于提供一种用于机器人采摘的密集李子精准检测系统;
7.本发明的第一目的通过以下的技术方案实现:
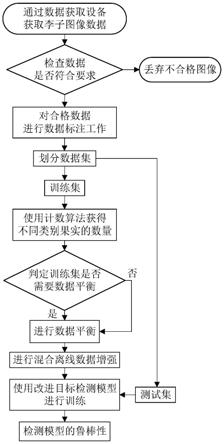
8.一种用于机器人采摘的密集李子精准检测方法,包括以下步骤:
9.通过图像采集设备采集果园果实的图像;
10.对采集图像进行检查处理,得到符合要求的目标检测图像;
11.通过数据标注工具对目标检测图像进行数据标注,获取不同成熟度的标注图像;
12.将标注图像按比例划分训练集,获取训练集中成熟果实个数和未成熟果实个数;
13.根据训练集中果实成熟比例判断是否进行数据平衡处理,数据平衡处理后得到平衡训练集;
14.将平衡训练集数据集进行数据增强处理,得到数据增强训练集;
15.对目标检测模型进行改进,得到改进目标检测模型;
16.通过改进目标检测模型对数据增强训练集进行训练和预测,得到检测结果。
17.进一步地,所述通过图像采集设备采集果园果实的图像,具体为:通过高清晰移动采集设备进行不同方向不同距离地图像采集,获得不同颜色、不同姿态、不同大小、不同背景、不同密集遮挡的rgb图像。
18.进一步地,所述对采集图像进行检查处理,得到符合要求的目标检测图像,具体为:对采集的图像数据进行质量评估,质量评估包括图像的清晰度、背景复杂度,删除模糊图像、未包含果实图像、背景复杂图像,评估合格的图像保留为目标检测图像。
19.进一步地,所述通过数据标注工具对目标检测图像进行数据标注,获取不同成熟度的标注图像,具体为:通过图像注释工具对目标检测图像采用划分成熟度的方式进行数据标注,包含成熟果实和未成熟果实两个标注类别;对完全裸露的果实进行外切矩形框的方式标注,对遮挡和粘连的果实标注其图像裸露部分,对图像边界出现部分果实和遮挡程度小于k的果实不作标注处理,这里 k为10%。
20.进一步地,将标注图像按比例划分训练集,获取训练集中成熟果实个数和未成熟果实个数,具体为:将标注图像按8∶2比例划分训练集和预测集;所述训练集包含验证集,训练集和验证集比例为9∶1;通过计算法获取训练集中果实个数;所述数据标注是根据果园中果实颜色划分不同成熟度,李子果实颜色红色部分占比大于0.5被划分为成熟李子,反之为未成熟李子。
21.进一步地,训练集与测试集的比例一般为8:2数据标注是根据果园中果实颜色划分不同成熟度的,数据标注是真实的数据,是地面验证数据,用于后期评估改进模型输出的iou大小,其中iou是指:测试结果与真实结果标注框的重合程度;训练集与验证集的比例一般为9:1,可以自行在代码中修改,这里用的就是9:1,验证集与训练集一起用在模型训练过程中的;
22.进一步地,所述根据训练集中果实成熟比例进行数据平衡处理,得到平衡训练集,具体为:若训练集中成熟果实和不成熟果实比例大于等于1,则不进行数据平衡处理,若训练集中成熟果实和不成熟果实比例小于1,则进行数据平衡处理,数据平衡处理如下:
23.s601、假设有数据集s=[m1,m2,...,mi][n1,n2,...,nj]
t
,其中mi表示数据集样本的种类,nj表示每一种样本的数量;
[0024]
s602、比较该数据集中所有类的样本数量值minj,找出所有类中最大值 min
jmax
;
[0025]
s603、使用min
jmax
依次除以剩余类的样本数量值minj,得到除数c;
[0026][0027]
s604、选择一种数据量扩增方式,根据除数c对剩余类进行数据量扩增,使得所有类别样本数量向最大值方向扩增,得到min
′j,最终使各类别数量的比值接近于1;
[0028][0029]
s605、最终输出得到扩增后的数据集t=[m1,m2,...,mi][n
′1,n
′2,...,n
′
jmax
]
t
。
[0030]
进一步地,所述将平衡训练集数据集进行数据增强处理,得到数据增强训练集,具体为:利用随机组合方式对训练集进行离线数据增强处理,包含高斯模糊、随机旋转、随机裁掉图像部分区域、直方图均衡化、随机亮度调整、椒盐噪声。
[0031]
进一步地,为了增强数据的多样性,数据增强做的随机组合方式是任意两种方式进行组合,随机组合的目的是模拟在真实果园中数据获取的图像。
[0032]
进一步地,所述对目标检测模型进行改进,得到改进目标检测模型,具体为:
[0033]
以yolov4为改进目标检测模型的基础,改进目标检测模型;
[0034]
s801、使用mobilenetv3代替cspdarknet53作为骨干特征提取网络,并在特征融合阶段使用深度可分离卷积取代标准卷积;
[0035]
s802、构建多尺度融合的网络结构;
[0036]
s803、对来自特征金字塔网络特征融合后输出的4个特征层进行剪枝操作;
[0037]
s804、改进损失函数;使用focal loss替代原有yolov4损失函数中的bce loss,与ciou loss形成联合损失函数平衡难分类样本和易分类样本对总损失的贡献度,其计算公式为:
[0038][0039]
其中,y为样本标签数量;p
t
表示属于李子类别的概率;a
t
为平衡正负样本权重的系数,0<a
t
<1;γ为难易样本的调制参数,(1-p
t
)
γ
被用来调节难易样本的权重。
[0040]
进一步地,所述通过改进目标检测模型对数据增强训练集进行训练和预测,得到检测结果,具体为:
[0041]
s901、运行train.py开始训练训练集;
[0042]
s902、模型训练完毕后,运行test.py检测模型的性能;
[0043]
s903、得到模型的检测结果指标,所述指标包括平均准确度均值、计算某一类别的平均准确度。
[0044]
一种用于机器人采摘的密集李子精准检测系统,其特征在于,包括:
[0045]
图像采集设备,用于采集果园果实的图像;
[0046]
图像处理模块,用于对采集图像进行检查处理,得到符合要求的目标检测图像;
[0047]
数据标注模块,用于对目标检测图像进行数据标注,获取标注图像;
[0048]
标注划分模块,用于将标注图像按比例划分训练集和测试集,获取训练集中熟果实个数和未成熟果实个数;
[0049]
平衡处理模块,根据训练集中果实成熟比例进行数据平衡处理,得到平衡训练集;
[0050]
数据增强模块,将平衡训练集数据集进行数据增强处理,得到数据增强训练集;
[0051]
模型改进模块,对目标检测模型进行改进,得到改进目标检测模型;
[0052]
模型训练和预测模块,通过改进目标检测模型对数据增强训练集进行训练和预测,得到检测结果;
[0053]
检测结果输出模块,用于输出检测结果。
[0054]
本发明与现有技术相比,具有如下优点和有益效果:
[0055]
本发明根据李子果实的生长特性,提出了一种用于机器人采摘的密集李子精准检测方法。在数据集制作方面,本发明考虑到了不同类别数据量悬殊和密集数据集的问题,使用了基于类别平衡的数据增强方法;在模型改进方面,以 yolov4为研究基础,使用mobilenetv3作为骨干特征提取网络,同时在特征融合阶段使用深度可分离卷积来提升模
型的准确度和轻量化。为解决模型对密集目标特征提取不足问题,本发明引入152
×
152尺寸的特征层以实现细粒度检测;同时使用focal loss与ciou loss的联合损失函数平衡难分类样本和易分类样本对总损失的贡献度。最后再通过不同阶段的迁移学习来训练改进的模型。进一步地,该方法可为后续果园的产量估测和李子采摘机器人研究的提供技术支撑
附图说明
[0056]
图1是本发明所述一种用于机器人采摘的密集李子精准检测方法流程图;
[0057]
图2是本发明所述实施例1中用于机器人采摘的李子检测模型图;
[0058]
图3是本发明所述一种用于机器人采摘的密集李子精准检测系统结构框图。
具体实施方式
[0059]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0060]
实施例1:
[0061]
一种用于机器人采摘的密集李子精准检测方法,如图1所示,包括以下步骤:
[0062]
通过图像采集设备采集果园果实的图像;
[0063]
对采集图像进行检查处理,得到符合要求的目标检测图像;
[0064]
通过数据标注工具对目标检测图像进行数据标注,获取不同成熟度的标注图像;
[0065]
将标注图像按比例划分训练集,获取训练集中成熟果实个数和未成熟果实个数;
[0066]
根据训练集中果实成熟比例判断是否进行数据平衡处理,数据平衡处理后得到平衡训练集;
[0067]
将平衡训练集数据集进行数据增强处理,得到数据增强训练集;
[0068]
对目标检测模型进行改进,得到改进目标检测模型;
[0069]
通过改进目标检测模型对数据增强训练集进行训练和预测,得到检测结果。
[0070]
具体如下:
[0071]
第一步,使用4000万像素的智能手机作为采集设备,设置拍摄分辨率为 3840
×
2160,曝光参数为自动,对焦模式为自动对焦。为了尽可能多地采集自然环境中下李子的果实信息,实验者模拟采摘机器人的操作过程,手持采集设备不断地变换拍摄角度和拍摄距离,以期望能采集到不同颜色、姿态、大小、背景及密集遮挡等情况的rgb图像。
[0072]
对于采集到的李子图像,其像素为3968
×
2976,然而过高的像素会导致难以训练和处理。采取双三次缩放算法将图片像素缩放至1920
×
1440。
[0073]
第二步,使用目测法对采集的图像数据进行质量评估,删除由于相机抖动造成的模糊图像、未包含目标果实的图像和背景复杂的图像,评估合格的图像保留为目标检测图像,评估不合格的图像删除,即删除掉模糊图像、不包含李子的图像和背景过于复杂的图像。
[0074]
背景复杂判断:使用log边缘检测算子对图像进行计算,再使用ostu算法对计算得到的图像进行自动阈值分割,最后统计像素点值为255的像素点数量占总图像的百分比,当大于设定的百分比阈值时,即认为当前图像背景复杂。
[0075]
对于本采集的李子数据,通过多次实验,设定百分比阈值为20%;当大于 20%时,
图像背景复杂,模型训练花费的时间和算力就很大,在对图像进行预测时,检测时间也会增加,对于后期部署在采摘平台上机械臂反应的时间就很长,而这与向往和追求的实时采摘是相悖的;当小于20%时,图像正常。
[0076]
第三步、使用labelimg作为图像注释工具,对完全裸露的李子进行外切矩形框的方式标注,对于遮挡或粘连的李子只标注裸露于图像的部分,对在图像边界出现部分李子或遮挡程度小于10%的李子时不作标注处理。保存标注信息的格式为pascal voc。为了识别不同成熟度的李子果实,在标注过程中人工判断成熟度并标记为成熟(plum)与未成熟(raw_plum)两个类别李子。
[0077]
第四步、按照8:2的比例将数据集划分为训练集(包含验证集)与测试集;使用计数算法获得训练集中成熟果实与未成熟果实的个数。
[0078]
具体为:将标注图像按比例划分训练集,获取训练集中成熟果实个数和未成熟果实个数,具体为:将标注图像按8∶2比例划分训练集和预测集;所述训练集包含验证集,训练集和验证集比例为9∶1;通过计算法获取训练集中果实个数;所述数据标注是根据果园中果实颜色划分不同成熟度,李子果实颜色红色部分占比大于0.5被划分为成熟李子,反之为未成熟李子。
[0079]
进一步地,训练集与测试集的比例一般为8:2数据标注是根据果园中果实颜色划分不同成熟度的,数据标注是真实的数据,是地面验证数据,用于后期评估改进模型输出的iou大小,其中iou是指:测试结果与真实结果标注框的重合程度;训练集与验证集的比例一般为9:1,即验证集在训练集中占比10%,可以自行在代码中修改,这里用的就是9:1,验证集与训练集一起用在模型训练过程中的;
[0080]
第五步、根据成熟与否的李子个数比例判定训练集是否需要数据平衡操作。本实施例中成熟李子与未成熟李子数量比例为2.2:1,需要进行数据平衡操作。
[0081]
数据平衡处理如下:
[0082]
s601、假设有数据集s=[m1,m2,...,mi][n1,n2,...,nj]
t
,其中mi表示数据集样本的种类,nj表示每一种样本的数量;
[0083]
s602、比较该数据集中所有类的样本数量值minj,找出所有类中最大值 min
jmax
;
[0084]
s603、使用min
jmax
依次除以剩余类的样本数量值minj,得到除数c;
[0085][0086]
s604、选择一种数据量扩增方式,根据除数c对剩余类进行数据量扩增,使得所有类别样本数量向最大值方向扩增,得到min
′j,最终使各类别数量的比值接近于1;
[0087][0088]
s605、最终输出得到扩增后的数据集t=[m1,m2,...,mi][n
′1,n
′2,...,n
′
jmax
]
t
。
[0089]
第六步、本实施例中所用图像数据为1890张李子图像。为防止训练数据量过少造成的过拟合或不收敛现象,需要对训练数据增强以提高检测模型的鲁棒性。在第五步的基础上,训练集中不同成熟度李子数量相近,趋近于1。
[0090]
所述数据增强处理如下:利用随机组合方式对训练集进行离线数据增强处理,包
含高斯模糊、随机旋转、随机裁掉图像部分区域、直方图均衡化、随机亮度调整、椒盐噪声;为了增强数据的多样性,数据增强做的随机组合方式是两种。
[0091]
第七步、使用改进目标检测模型进行训练。
[0092]
以yolov4为改进目标检测模型的基础,改进目标检测模型,如图2所示;
[0093]
s801、使用mobilenetv3代替cspdarknet53作为骨干特征提取网络,并在特征融合阶段使用深度可分离卷积取代标准卷积;改进后的网络结构,其中, conv表示卷积,dsc表示深度可分离卷积,cbl与cbh表示卷积加批量正则加lekeyrelu或h-swish激活函数的合成模块,bneck表示块,bneckse表示带有se结构的bneck,concat表示堆叠,upsampling表示上采样。
[0094]
s802、构建多尺度融合的网络结构;从主干网络mobilenetv3中输出四个特征层,分别是p1(152
×
152)、p2(76
×
76)、p3(38
×
38)和p4(19
×
19)。其中, p4特征层的感受野最大,适合大尺寸的目标检测,p3特征层的感受野适合中等尺寸的目标检测,对p2进行上采样,将其与p1特征层融合后可获得较为丰富的浅层信息,从而实现对小目标物体细粒度的检测。在特征传播过程中19
×
19 尺度特征层仍然经过空间金字塔池化(spp)结构得到特征层p4。将特征层p4、 p3、p2和p1在fpn结构中通过上采样进行不同金字塔级别的特征图结合,每一个特征层经过卷积和上采样变换,获得与上一个特征层相同的尺度和通道数量,然后经过与上一个特征层堆叠融合可获得信息更加丰富的特征图。
[0095]
s803、对来自特征金字塔网络特征融合后输出的4个特征层进行剪枝操作;为防止网络过于冗余,对来自fpn特征融合后输出的4个特征层进行剪枝操作。具体操作为将fpn输出的152
×
152尺度特征层不再进行yolo head的预测输出,直接在路径聚合网络(panet)结构中上采样,因此改进算法也保持三个尺度的预测输出头,即p2'(76
×
76)、p3'(38
×
38)、p4'(19
×
19)。
[0096]
s804、改进损失函数;由于李子果实体型较小,并且在图像中占据的像素点较少的缘故,当一张图像中同时存在单个、遮挡和密集堆叠的李子果实时,模型会自动关注并训练单个或易识别的简单样本,忽视粘连等难分类的样本。因此寻找合适的损失函数去平衡难分类和易分类样本对总损失的贡献度是很有必要的。而focal loss函数的作用是在不影响原检测速度的情况下,在训练过程中将一些注意力转移到难分类的样本上;使用focal loss替代原有yolov4损失函数中的bce loss,与ciou loss形成联合损失函数平衡难分类样本和易分类样本对总损失的贡献度;其计算公式为:
[0097][0098]
其中,y为样本标签数量;p
t
表示属于李子类别的概率;a
t
为平衡正负样本权重的系数,0<a
t
<1;γ为难易样本的调制参数,(1-p
t
)
γ
被用来调节难易样本的权重。
[0099]
进一步地,使用改进后的检测模型训练制作好的训练集,并用在测试集上进行预测。具体为:为了加快模型收敛,通过不同阶段的迁移学习来训练改进的模型,并使用评估指标在测试集上评估改进模型的鲁棒性情况。为了客观衡量模型对密集李子的目标检测效果,使用准确率(precision,p)、召回率(recall, r)、调和均值f1值(f1-score)、平均精度ap、均值平均精度map、网络参数量、权重大小和检测速度(fps)来评价训练后的模型,iou取
值推荐使用0.5。
[0100]
本实施例选择的模型图像尺寸是608
×
608时,负责密集小目标进行预测的特征层为76
×
76,每个特征网格对应的感受野尺寸为8
×
8。当输入图片大小为 1920
×
1080时,通过yolo网格压缩对应长边为25,即当目标特征尺寸小于 25
×
25像素时将无法有效学习到目标的特征信息。用于模型训练的硬件平台配置为cpu为amd r5-5600x 3.7ghz,内存为32gb,存储ssd为512gb,显卡为nvidia rtx2060s,显存为8gb,操作系统为windows10,cuda版本为 10.1,python版本为3.7,pytorch版本为1.6。
[0101]
本实施例输入图像分辨率为1920
×
1440,随机选择10%训练集图像数据作为验证集,使用k-means算法迭代生成anchors坐标框,使用adam优化器,采用改进的损失函数对模型进行训练。除了使用离线增强方法外,在训练过程中使用mosaic数据增强,进一步丰富检测物体的背景,强化网络模型对于李子果实特征的认知,增强模型的鲁棒性和泛化性能。学习率初始值设置为10^(-4),使用余弦退火学习率在训练过程中进行优化更新。
[0102]
采取迁移学习的方式进行训练。将训练分为两个阶段,整个阶段训练100 轮次(epoch)。对于前半个阶段,加载mobilenetv3系网络的预训练权值,对模型主干特征提取网络使用冻结训练50轮次,将模型的学习率初始值设置为1
ꢀ×
10^(-3),批大小设置为16。这种操作可以加快收敛速度,并避免预训练权值被破坏。对于后半个阶段,对主干特征提取网络进行解冻,以1
×
10^(-4)的初始学习率对整个模型进一步训练50轮次,批大小设置为8。通过两个阶段加快整个模型的收敛,缩短了模型的训练时间。
[0103]
第八步、使用改进后的检测模型训练制作好的训练集,并用在测试集上进行预测。经试验,该改进算法在密集李子上的map为88.56%。
[0104]
实施例2
[0105]
一种用于机器人采摘的密集李子精准检测系统,如图3所示,包括:
[0106]
图像采集设备,用于采集果园果实的图像;
[0107]
图像处理模块,用于对采集图像进行检查处理,得到符合要求的目标检测图像;
[0108]
数据标注模块,用于对目标检测图像进行数据标注,获取标注图像;
[0109]
标注划分模块,用于将标注图像按比例划分训练集和测试集,获取训练集中熟果实个数和未成熟果实个数;
[0110]
平衡处理模块,根据训练集中果实成熟比例进行数据平衡处理,得到平衡训练集;
[0111]
数据增强模块,将平衡训练集数据集进行数据增强处理,得到数据增强训练集;
[0112]
模型改进模块,对目标检测模型进行改进,得到改进目标检测模型;
[0113]
模型训练和预测模块,通过改进目标检测模型对数据增强训练集进行训练和预测,得到检测结果;
[0114]
检测结果输出模块,用于输出检测结果。
[0115]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
