1.本技术涉及遥感领域和森林火灾模拟研究领域,尤其涉及一种基于元胞自动机的森林火灾蔓延模拟方法。
背景技术:
2.森林与人类的繁衍、生存和发展息息相关,它不仅为人类的生产生活提供丰富的物质资源,而且具有巨大的生态功能与价值,是最重要的陆地生态系统。然而,随着全球变暖和极端天气的增多,世界面临森林火灾的危险性在不断增加,全球已进入森林火灾高发期。林火正成为全球挑战,亟需一个能在短时间内对林火蔓延做出准确预测模型。目前的林火蔓延预测模型往往需要大量精确然而在火灾发生时难以获取的数据,而且计算量巨大,这对实时预测火灾蔓延趋势造成了很大的不便。
3.本发明提出一个可以通过历史火灾的地理信息数据来实现快速预测山林火灾蔓延趋势的计算模型,使用机器学习的方法来寻找各个因素和火势蔓延之间的规律关系。结合元胞自动机对燃烧情况进行模拟,最终可以快速实时预测山林火灾蔓延趋势,给山林火灾的扑救工作提供指导。
技术实现要素:
4.本技术提出一种基于元胞自动机的森林火灾蔓延模拟方法,解决了现有林火蔓延预测精度低,计算量大的问题。
5.本发明的目的是通过以下技术方案实现的:
6.一种基于元胞自动机的林火蔓延预测方法,包括:
7.步骤s1:构建机器学习模型
8.步骤s2:构建元胞网格
9.步骤s3:按照元胞转换规则进行模拟
10.进一步地,所述步骤s1包括以下步骤:
11.步骤s11:机器学习模型包含六个特征,分别为植被覆盖率(evc),植被种类(evt),植被平均高度(evh),坡度(slp),坡向(asp),高程(elev);
12.步骤s12:获取多场历史火灾的步骤s11中所述的六个特征的数据,作为源域数据,将其处理成和元胞边长相等的精度,比如元胞边长为30米*30米,则数据精度也为30米*30米。所需数据分别为每场火灾燃烧范围内随机选取的n1条数据和处在火灾燃烧边界上且未燃烧的n2条数据,n1与n2之比不大于2:1;
13.步骤s13:使用步骤s12中获取的数据训练反向传播神经网络;
14.步骤s14:获取待预测区域的一场历史火灾的地理信息数据,所需数据为火灾燃烧范围内随机选取的n
′1条数据和处在火灾燃烧边界上且未燃烧的n
′2条数据,n
′1与n
′2之比不大于2:1;
15.进一步地,若待预测区域没有有记录的火灾数据,则选取一场与待预测区域地理
条件接近的火灾,以这场火灾的地理信息数据作为替代;
16.步骤s15:冻结除最后一层,即全连接层外的所有网络参数,使用步骤s14中获取的数据对步骤s12中获取的模型进行训练,以适应目标域的数据。
17.进一步地,所述步骤s2包括以下步骤:
18.步骤s21:获取待模拟区域的地理信息数据,分别为植被覆盖率(evc),植被种类(evt),植被平均高度(evh),坡度(slp),坡向(asp),高程(elev);
19.步骤s22:将所有植被覆盖率大于10%的元胞标记为可被点燃,将植被覆盖率小于10%或为荒地、裸岩、水面等地形的元胞标记为不可被点燃;
20.进一步地,所述步骤s3包括以下步骤:
21.步骤s31:获取初始燃烧位置并输入元胞网络
22.步骤s32:获取当前正在燃烧的元胞w
i,j
23.步骤s33:将所有目前正在燃烧的元胞的摩尔邻域内所有状态为可被点燃但仍未燃烧的元胞所处位置的地理信息数据作为步骤s1中获得的机器学习模型的输入,输出即为初步燃烧概率p1。
24.进一步地,元胞w
i,j
的摩尔邻域为:
25.步骤s34:根据实际风速v(单位米/秒)和风向的情况对p1做修正,修正概率p2=μv,修正系数μ见下表:
26.表1
[0027][0028]
步骤s35:若最终燃烧概率p=p1 p2大于阈值θ,则该元胞在下一时间步长状态为燃烧,否则仍然为未燃烧,重复步骤s32到s35,直至没有可燃物或没有正在状态为正在燃烧的元胞为止。
[0029]
进一步地,阈值θ由公式(2)确定,其中权重因子α和β由多次实验迭代比较产生,一般为20次,使用使得预测结果误差最小的参数值作为α和β最终的值;
[0030]
步骤s36:对预测结果进行动态展示
[0031]
进一步地,元胞转换的规则如下:
[0032]
规则1:如果某一个元胞w
i,j
在一个独立的时间步长中状态为不可被点燃,那么该元胞w
i,j
在下一个时间步长的状态仍然为不可被点燃;
[0033]
规则2:如果某一个元胞w
i,j
在一个独立的时间步长中状态为可被点燃但认为燃烧,并且它的摩尔邻居wi±
1,j
±1中存在正在燃烧的元胞,那么该元胞w
i,j
在下一时间步长可能被点燃;
[0034]
规则3:如果某一个元胞w
i,j
在一个独立的时间步长中状态为正在燃烧,那么该元胞w
i,j
在下一个时间步长的状态为燃烧完成;
[0035]
规则4:如果某一个元胞w
i,j
在一个独立的时间步长中状态为燃烧完成,那么该元胞w
i,j
在下一个时间步长的状态为燃烧完成;
[0036]
本发明通过使用机器学习模型去学习各个特征与是否会被点燃之间的关系,使用迁移学习技术进一步提升模型预测的准确度,首先从历史火灾数据中获取足量的训练数据去训练燃烧概率预测模型,然后使用待预测区域的历史火灾数据去训练模型最后一层(全连接层)的参数,使模型在目标区域具有更好的预测能力,提升预测的精度。将机器学习模型结合元胞自动机进行火灾的蔓延模拟,使用机器学习模型来计算元胞被点燃的概率,摆脱传统模型计算量大,需要的数据种类多且难以获取的痛点。
附图说明
[0037]
此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
[0038]
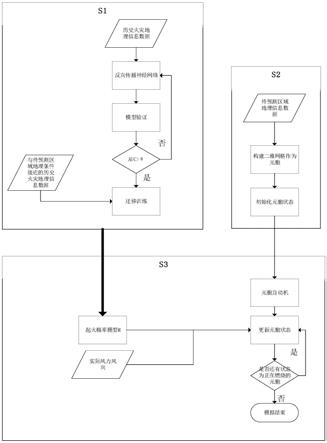
图1为本发明实施例提供的一种基于元胞自动机得森林火灾蔓延模拟方法的流程图;
[0039]
图2为元胞的摩尔邻域及对应下标;
[0040]
图3为元胞状态及元胞转化示意图;
[0041]
图4为本发明实施例提供的训练数据选取区域示意图;
[0042]
图5为本发明实施例提供的在西风条件下燃烧元胞w
i,j
对东北方向相邻元胞w
i-1,j 1
的影响示意图。
具体实施方式
[0043]
下面结合附图及实施例对本发明做进一步说明。
[0044]
本发明实施例提供一种数据驱动的林火蔓延预测方法,如图1所示,其主要包括如下步骤:
[0045]
步骤s1:根据历史火灾数据构建反向传播神经网络;
[0046]
步骤s2:构建元胞自动机模型;
[0047]
步骤s3:根据元胞状态转换规则进行模拟。
[0048]
在本实施例中,所述步骤s1具体包括以下步骤:
[0049]
步骤s11:获取一定数量的历史火灾地理信息数据d1,所需数据为火灾区域和火灾边界未燃烧区域的植被覆盖率(evc),植被种类(evt),植被平均高度(evh),坡度(slp),坡
向(asp),高程(elev),数据精度与元胞边长相等,在本实施例中为30米*30米,将其处理为逗号分隔值文件(csv)格式,其中火灾区域的数据标签为1,火灾边界未燃烧区域的数据标签为0。
[0050]
步骤s12:将步骤s1中获取的数据d1作为反向传播神经网络m1的训练数据,在本实施例中,m1有三个隐藏层,隐藏层1有6个输入,对应火灾数据的6个特征,128个输出,隐藏层2有128个输入,128个输出,隐藏层3有128个输入,1个输出。
[0051]
步骤s13:在训练完成后对m1进行可靠性验证,在本实施例中使用相对工作特征(roc)进行模型验证,使用分层简单随机抽样方法在整个试验区域提取验证样本数据。然后,根据一系列点火概率阈值水平(即0.1-1),这些样本数据可以重新分类为100个细分。对于每个生成的细分,计算真阳性比例和假阳性比例。基于这些比例值,绘制roc曲线,然后计算roc统计量(即曲线下面积-auc)。如果预测概率对着火判别没有影响,则相应的auc值为0.5,在0.7-0.9之间的值表示预测点火可能性具有可靠的性能,而高于0.9或低于0.7的值分别表示最佳或较差的性能。
[0052]
步骤s14:若m1的auc值大于0.7,则进行下一步,否则重复步骤s11-s13。
[0053]
步骤s15:在获得可靠的模型之后再选取一场与待预测区域地理条件接近的火灾,按照步骤s11所述获取其地理信息数据d2。冻结m1除最后一层外的所有隐藏层的参数,使用d2对其神经网络模型进行训练,最终获得模型m2;
[0054]
在本实施例中,所述步骤s2具体包括以下步骤:
[0055]
步骤s21:获取待预测区域的地理信息数据,所需数据为所有待模拟区域内的植被覆盖率(evc),植被种类(evt),植被平均高度(evh),坡度(slp),坡向(asp),高程(elev),数据精度与元胞边长相同,在本实施例中为30米*30米。
[0056]
步骤s22:在计算机上采用规则网格的方式构建二维网格作为元胞,一个元胞对应一块边长为30米的正方形区,每一个元胞都有对应的地理信息数据。
[0057]
步骤s23:使用步骤s21中获取的数据初始化元胞的状态,若一个元胞的evc值为大于等于10%的植被覆盖率,则其状态为可被点燃,否则其状态为不可被点燃;
[0058]
在本实施例中,所述步骤s3具体包括以下步骤:
[0059]
步骤s31:获取初始起火点并输入元胞自动机,将对应元胞的状态变为正在燃烧;
[0060]
步骤s32:获取元胞自动机中所有状态为正在燃烧的元胞w
i,j
,获取其摩尔邻域wi±
1,j
±1内状态为可被点燃但仍未燃烧的元胞w
p,q
;
[0061]
步骤s33:将w
p,q
对应的地理信息数据作为m2的输入,m2的输出即为初步燃烧概率p1;
[0062]
步骤s34:根据w
p,q
与w
i,j
的相对位置和实际风力风向进行修正,修正系数μ如表1所示,比如风力为d,风向为正北风,p=i 1,q=j 1,则修正燃烧概率
[0063]
步骤s35:将p1与p2相加得最终燃烧概率p,若最终燃烧概率p大于阈值θ则元胞w
p,q
的状态在下一时间步长为正在燃烧,否则状态仍为未被点燃;
[0064]
进一步地,在步骤s35中处在w
i,j
对角单元的点燃阈值θ1要大于处于相邻单元的点燃阈值θ2,在本实施例中θ1=0.8,θ2=0.7;
[0065]
步骤s36:重复步骤s32~s35,直到没有状态为正在燃烧的元胞。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。